1964
A deep learning based approach to generate synthetic CT images from multi-modal MRI data1F.M. Kirby Research Center for Functional Brain Imaging, Kennedy Krieger Institute, Baltimore, MD, United States, 2Department of Biomedical Engineering, Columbia University, New York City, NY, United States, 3Department of Neuroscience, Columbia University, New York City, NY, United States, 4Neurosection, Division of MRI Research, Russell H. Morgan Department of Radiology and Radiological Science, Johns Hopkins University School of Medicine, Baltimore, MD, United States, 5Department of Biomedical Engineering, Johns Hopkins University, Baltimore, MD, United States
Synopsis
Keywords: Analysis/Processing, Machine Learning/Artificial Intelligence, multi-modal MRI
Motivation: Synthetic CT is a useful technique to generate CT images from MR images. Most existing methods exploit only one single MRI modality such as T1-weighted (T1w) images.
Goal(s): We aim to develop a synthetic CT method integrating dual-channel T1w+FLAIR input images.
Approach: A dual-channel, multi-task deep learning approach based on the 3D Transformer U-net was tested using a public human brain MRI-CT dataset. Its performance was compared to single-modal T1w-based CT synthesis.
Results: Our results indicate that dual-modal T1w+FLAIR images can provide richer details, particularly in pixel-level predictions compared to single-modal synthetic CT. The improvement in morphology was moderate.
Impact: The proposed framework may be used to integrate two or more MRI modalities to improve the performance of CT image synthesis.
INTRODUCTION
Synthetic CT is a useful technique to generate CT images from MR images. The application of synthetic CT has seen an increased interest in areas such as focused ultrasound (FUS) therapy aberration correction1,2 and PET/MRI-CT attenuation correction3,4. It leverages CT's bone tissue contrast and MRI's soft tissue precision5,6, which help to reduce cost, acquisition time, radiation exposure, and registration errors7-9. Existing synthetic CT methods using generator-based methods or generative adversarial network10,11 primarily focused on pixel-to-pixel modal transformation. In this work, the MRI-to-CT transformation was divided into two sub-tasks: skull segmentation and Hounsfield Unit (HU) pixel prediction, and a versatile Transformer U-net framework, capable of multi-task processing to enhance cross-modal translation and reconstruction was incorporated. In addition, existing methods often employ 2D-training12 or pseudo-3D10 methods to circumvent large 3D image sizes, leading to slice discontinuity and biased evaluations. Our framework addresses these issues through 3D-patch extraction and sequential image restoration, preserving 3D structural continuity, strengthening model generalizability, and enabling flexibility in input image size. Finally, most existing methods exploit single MRI modality such as T1-weighted (T1w), T2-weighted (T2w), FLAIR13-16, and ultra-short- or zero-TE (UTE or ZTE)17-19 MRI images. Synthetic CT approaches based on multi-modal MRI data are still limited. In this study, we propose a synthetic CT method integrating dual-channel T1w+FLAIR input images and compared its performance to single-modal T1w-based CT synthesis.METHODS
The publicly available CERMEP-IDB-MRXFDG dataset20 acquired in 37 healthy subjects (age38.11±11.36yr, 23–65yr, 20female) was used. The dataset includes T1w MPRAGE and FLAIR MRI, and CT images for each subject. We randomly divided the dataset into training, validation, and test sets in an 8:1:1 ratio. A normalization process was applied to MRI and CT images to scale their values within the range of 0 to 1. Skull labels were generated from CT images using a thresholding method to remove foreground and background information. Our framework, as depicted in Fig.1, divides the MRI to CT skull transformation into two components: mask segmentation and regional pixel value prediction determined by geometric morphological dilation algorithms. The model is an enhanced Transformer U-net21, leveraging position encoding and multi-head attention mechanisms. The global image is partitioned into 3D-patches, facilitating localized structural learning. The patches obtained from the pipeline predictions are sequentially integrated back into the large image, enhancing prediction stability by averaging overlapping regions. Image dimensions are standardized to 207x243x226, with a patch size of 128 cubic units. We randomly selected 100 patches from each subject's images in the training and validation sets, yielding a training set of 3000 samples and a validation set of 300 samples. For pixel prediction tasks, 100% of patch samples were extracted from skull centers, while for segmentation tasks, 80% were centered on the skull, and the remaining 20% covered areas near the skull and within the brain.RESULTS
Fig.2 demonstrates the framework's performance on subtasks, including skull mask segmentation and post-processing CT pixel-to-pixel predictions. Fig.3 shows the main task results and residual values along three anatomical directions. From the images, it is evident that even after geometric mask thresholding, there are still foreground and background regions showing residuals in CT pixel prediction subtasks in the single T1w modality (Figs.2g,h), emphasizing the need for post-processing when segmentation masks are not used. However, for the synthetic CT images generated by the integrated dual-modal approach, no additional post-processing was required.Tables 1 and 2 summarize quantitative performance evaluation for the respective tasks. In all four test subjects, the dual-modal approach outperformed the single T1w-modality training, especially in pixel prediction and image similarity (paired t-tests in pixel prediction subtask all p<0.01). However, the improvement in morphological evaluation for the segmentation task only showed a trend (p<0.1). The synthetic CT images generated from the proposed dual-modal approach outperformed the single-modality methods in all performance metrics (p<0.05), including overall peak-Signal-to-Noise-Ratio and Hounsfield-Unit value error within the real CT skull.
DISCUSSION & CONCLUSION
In this study, we have explored the use of multi-modal MRI data for synthesizing CT images and compared its performance with the single-modality method. The results indicate that dual-modal T1w+FLAIR images can provide richer details, particularly in pixel-level predictions, as evidenced by metrics such as Pearson’s correlation and Mean-average-error. However, the improvements in morphology, such as image segmentation, were relatively moderate. While this could be partly attributed to our relatively small test dataset, it might also be due to the similarity of the morphological information that can be extracted from T1w and FLAIR images. Subsequent work is ongoing to use the multi-modal framework to incorporate additional MR images to improve its performance.Acknowledgements
This work is supported by Johns Hopkins University and Kennedy Krieger Institute. The author has no conflict of interest to disclose.References
1. Vyas U, Kaye E, Pauly KB. Transcranial phase aberration correction using beam simulations and MR-ARFI. Med Phys. 2014 Mar;41(3):032901. doi: 10.1118/1.4865778.
2. Wintermark M, et al. T1-weighted MRI as a substitute to CT for refocusing planning in MR-guided focused ultrasound. Phys Med Biol. 2014 Jul 07;59(13):3599-614. doi: 10.1088/0031-9155/59/13/3599.
3. Gong K, Han PK, Johnson KA, El Fakhri G, Ma C, Li Q. Attenuation correction using deep learning and integrated UTE/multi-echo Dixon sequence: evaluation in amyloid and tau PET imaging. Eur J Nucl Med Mol Imaging. 2021 May;48(5):1351-1361. doi: 10.1007/s00259-020-05061-w.
4. Wagenknecht G, Kaiser HJ, Mottaghy FM, Herzog H. MRI for attenuation correction in PET: methods and challenges. MAGMA. 2013 Feb;26(1):99-113. doi: 10.1007/s10334-012-0353-4.
5. Prabhakar R, Haresh KP, Ganesh T, Joshi RC, Julka PK, Rath GK. Comparison of computed tomography and magnetic resonance based target volume in brain tumors. J Cancer Res Ther. 2007;3(2):121-3. doi: 10.4103/0973-1482.34694.
6. Karlsson M, Karlsson MG, Nyholm T, Amies C, Zackrisson B. Dedicated magnetic resonance imaging in the radiotherapy clinic. Int J Radiat Oncol Biol Phys. 2009 Jun 01;74(2):644-51. doi: 10.1016/j.ijrobp.2009.01.065.
7. Edmund JM, Nyholm T. A review of substitute CT generation for MRI-only radiation therapy. Radiat Oncol. 2017 Jan 26;12(1):28. doi: 10.1186/s13014-016-0747-y.
8. Beavis AW, Gibbs P, Dealey RA, Whitton VJ. Radiotherapy treatment planning of brain tumors using MRI alone. Br J Radiol. 1998 May;71(845):544-8. doi: 10.1259/bjr.71.845.9691900.
9. Hyun CM, Kim HP, Lee SM, Lee S, Seo JK. Deep learning for undersampled MRI reconstruction. Phys Med Biol. 2018 Jun 25;63(13):135007. doi: 10.1088/1361-6560/aac71a.
10. Oulbacha R, Kadoury S. MRI to CT Synthesis of the Lumbar Spine from a Pseudo-3D Cycle GAN. 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI). 2020:1784-1787.
11. Hsu SH, Han Z, Leeman JE, Hu YH, Mak RH, Sudhyadhom A. Synthetic CT generation for MRI-guided adaptive radiotherapy in prostate cancer. Front Oncol. 2022;12:969463. doi: 10.3389/fonc.2022.969463.
12. Han X. MR-based synthetic CT generation using a deep convolutional neural network method. Med Phys. 2017 Apr;44(4):1408-1419. doi: 10.1002/mp.12155.
13. Nijskens L, van den Berg CAT, Verhoeff JJC, Maspero M. Exploring contrast generalisation in deep learning-based brain MRI-to-CT synthesis. Phys Med. 2023 Aug;112:102642. doi: 10.1016/j.ejmp.2023.102642.
14. Wang Y, Liu C, Zhang X, Deng W. Synthetic CT Generation Based on T2 Weighted MRI of Nasopharyngeal Carcinoma (NPC) Using a Deep Convolutional Neural Network (DCNN). Front Oncol. 2019;9:1333. doi: 10.3389/fonc.2019.01333.
15. Li Y, et al. CT synthesis from multi-sequence MRI using adaptive fusion network. Comput Biol Med. 2023 May;157:106738. doi: 10.1016/j.compbiomed.2023.106738.
16. Lei Y, et al. MRI-based synthetic CT generation using semantic random forest with iterative refinement. Phys Med Biol. 2019 Apr 05;64(8):085001. doi: 10.1088/1361-6560/ab0b66.
17. Chang EY, Du J, Chung CB. UTE imaging in the musculoskeletal system. J Magn Reson Imaging. 2015 Apr;41(4):870-83. doi: 10.1002/jmri.24713.
18. Robson MD, Gatehouse PD, Bydder M, Bydder GM. Magnetic resonance: an introduction to ultrashort TE (UTE) imaging. J Comput Assist Tomogr. 2003;27(6):825-46. doi: 10.1097/00004728-200311000-00001.
19. Kaushik SS, et al. Region of interest focused MRI to synthetic CT translation using regression and segmentation multi-task network. Phys Med Biol. 2023 Sep 18;68(19). doi: 10.1088/1361-6560/acefa3.
20. Mérida I, et al. CERMEP-IDB-MRXFDG: a database of 37 normal adult human brain. EJNMMI Res. 2021 Sep 16;11(1):91. doi: 10.1186/s13550-021-00830-6.
21. Rao VM, et al. Improving across-dataset brain tissue segmentation for MRI imaging using transformer. Front Neuroimaging. 2022;1:1023481. doi: 10.3389/fnimg.2022.1023481.
Figures
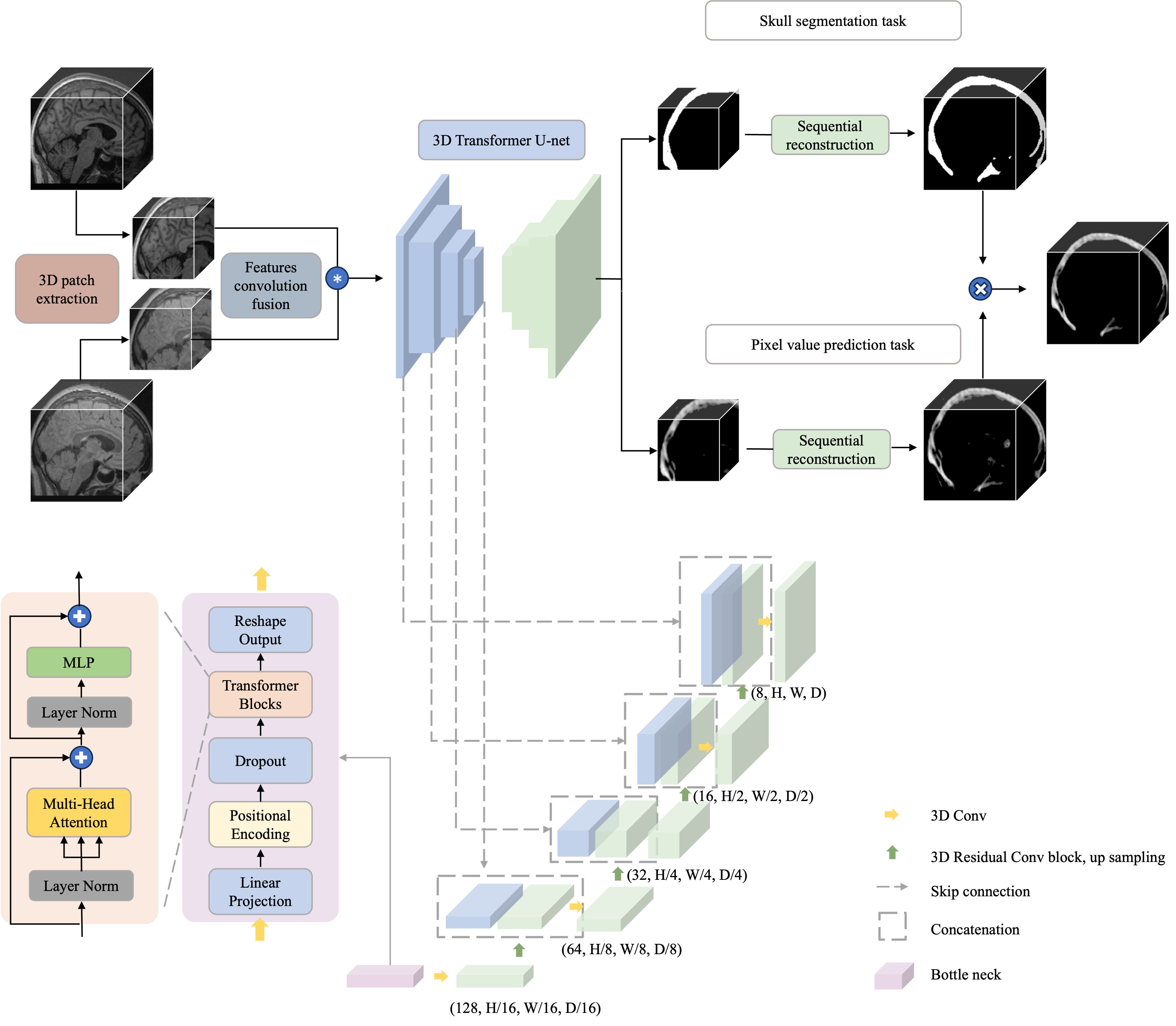
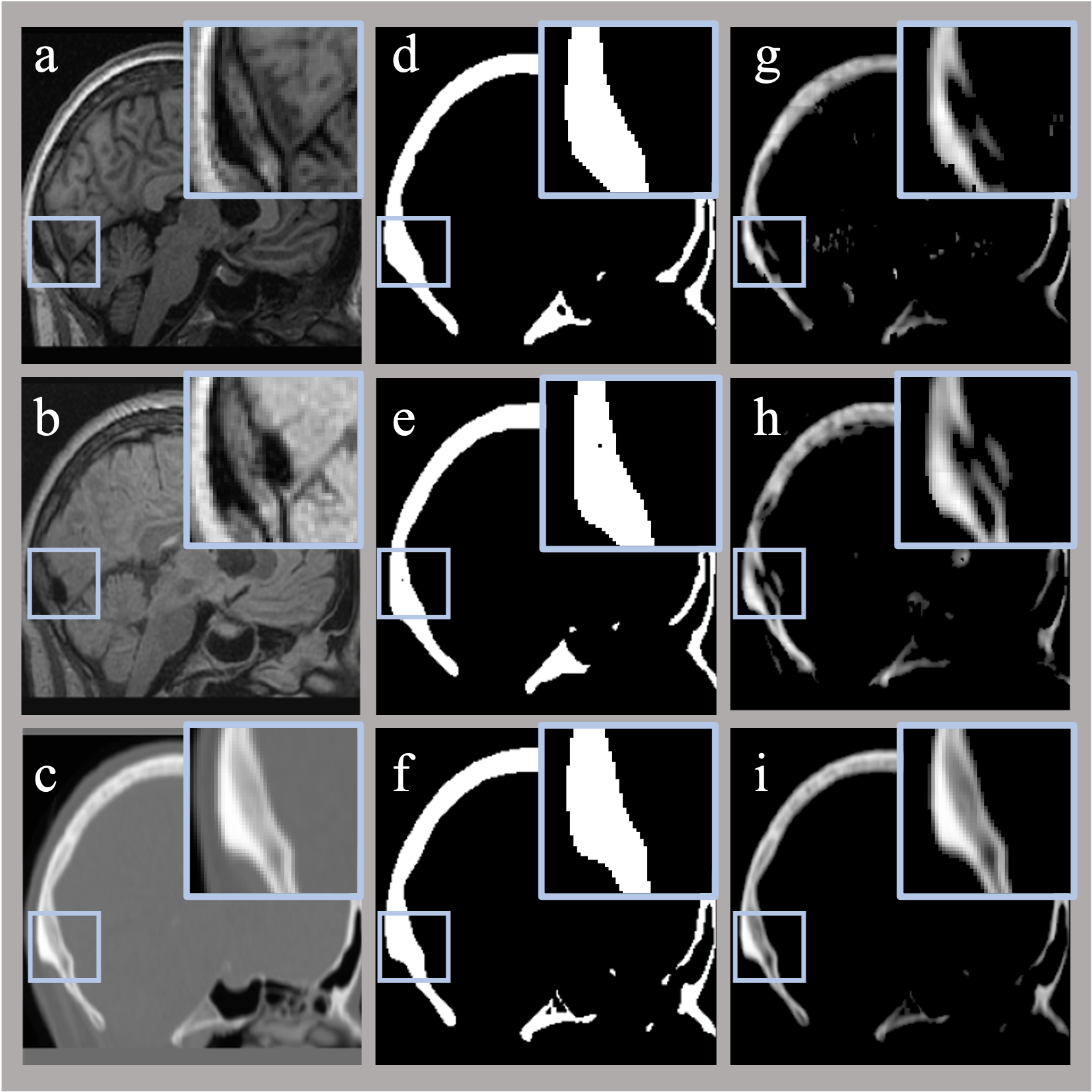
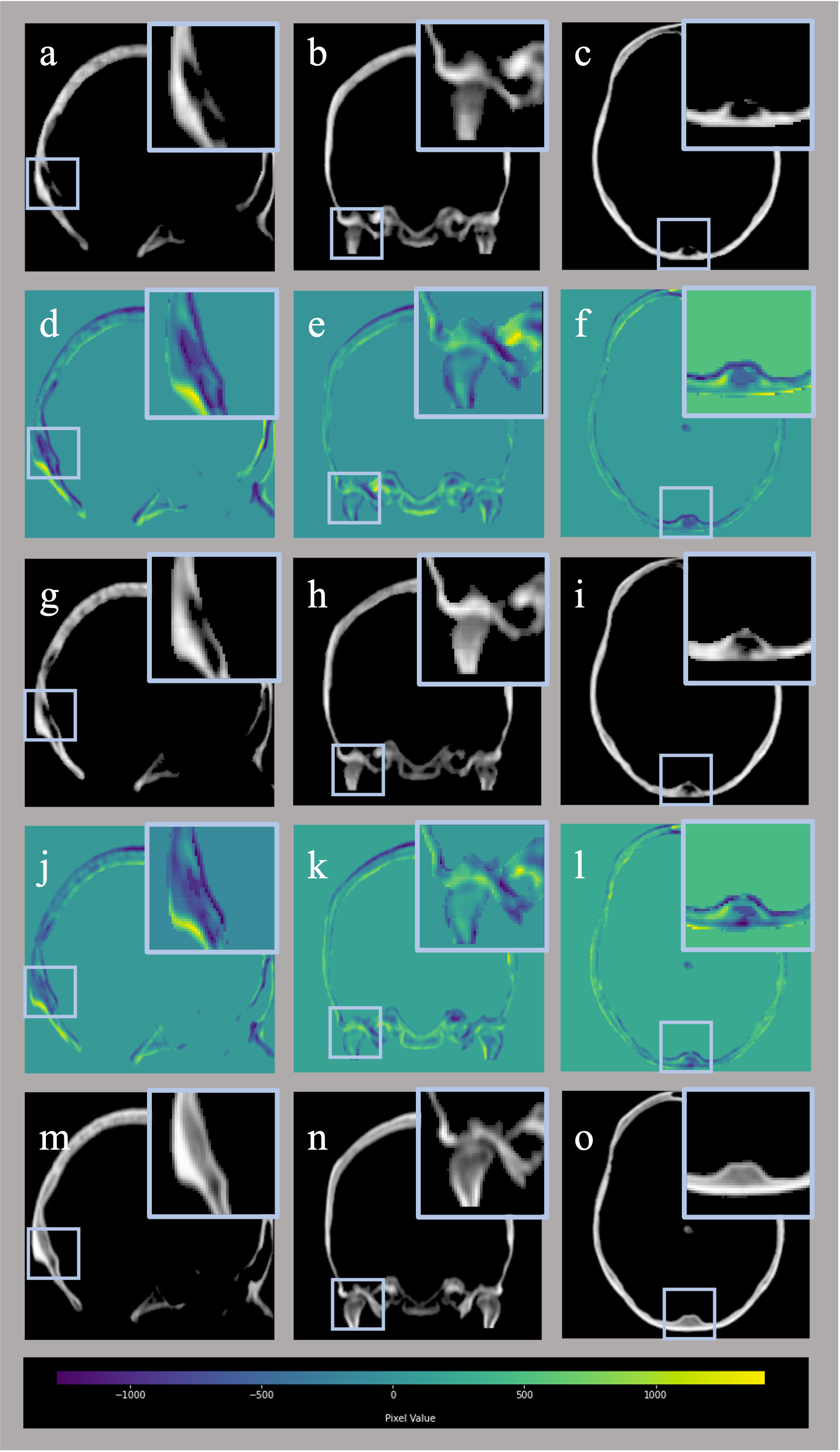

Table1. Performance on sub-tasks in the test data set.
* SSIM = Structural similarity index, Pearson = Pearson’s correlation, Spearman = Spearman’s rank correlation, Dice = Sørensen–Dice coefficient, Jaccard = Jaccard similarity coefficient.
