1962
Generalizable Transformer-based Automatic MRI Quality Control for Infant Brain Imaging1School of Biomedical Engineering, ShanghaiTech University, Shanghai, China, 2Shanghai Clinical Research and Trial Center, Shanghai, China, 3Shanghai Clinical Research and Trial Center, Shanghai, Shanghai, China
Synopsis
Keywords: Analysis/Processing, Brain, Quality Control, Infant
Motivation: Manual quality control (QC) for infant brain MRI is time-consuming and labor-intensive. The implementation of automatic QC is necessary for clinical scenarios.
Goal(s): To develop a generalizable, highly accurate, automatic tool for infant brain T1w-MRI quality control.
Approach: We design a generalizable automatic model with Residual Network (ResNet) and Vision transformer (ViT) modules for infant brain T1w-MRI QC. Our model is trained and validated on two large-scale multi-site infant MRI datasets (including Baby Connectome Project and China Baby Connectome Project).
Results: Based on our method, we can automatically classify the data quality with the accuracy of over 95% for BCP and CBCP datasets.
Impact: Our automatic MRI quality control tool can consider both local and global image features and shows excellent performance and efficiency, specifically on the infants' 3D brain T1w-MRI. It considerably reduces the requirement of labor in the traditional QC process.
Introduction
Infants and young children are prone to head motion during magnetic resonance imaging (MRI) scans, which can result in motion artifacts. This can lead to data acquisition failures and even introduce statistical errors or erroneous conclusions in subsequent research. Currently, the quality of MRI data is ensured through manual visual quality control (QC), which is a time-consuming process and subject to individual variability. Therefore, it is necessary to develop automated QC tools for scientific research.Traditional machine learning methods have been employed in automated QC1,2. However, the accuracy of these methods relies on the performance of manually designed image quality metrics1,2. Deep learning, without the need of complex feature engineering, provides an end-to-end method for automatic QC, achieving superior performance compared to machine learning2. Convolutional neural networks stand as the primary method in current QC3,4,5,6. Recently, Transformer has been demonstrated to outperform CNN in certain classification tasks7.
In this work, We've developed a network that combines convolutional and Transformer module for T1w-MRI QC in early brain development studies.
Methods
The datasets for this experiment were obtained from Baby Connectome Project (BCP) and Chinese Baby Connectome Project (CBCP). BCP's data is sourced from American children aged 0-5, whereas CBCP is derived from Chinese children aged 0-6.These two datasets share a resolution of 0.8*0.8*0.8mm3, but their MR protocols are distinct. Additionally, CBCP data represents a population with rounder head shapes, while BCP exhibits longer head shapes. And images from BCP were acquired with fat suppression technique while CBCP were not, which would result in a lower contrast for CBCP data. Three experts labeled 3D infant T1w MRI images as either pass or fail. Fig. 1 displays the several labeling results of different images qualities. To maintain the balance between labels, in total 506 3D infant T1w MR images were included. CBCP contributed 206 cases (106 pass, 100 fail), and BCP contributed 300 cases (158 pass, 142 fail). We randomly selected 50 'pass' instances and 50 'fail' instances for the test set, while the remaining instances were allocated to the training set.The combination of the muti-head attention mechanism and MLP in the Transformer empowers the model to adeptly grasp global features. However, due to the high-dimension and high-resolution of brain MRI data, Transformer faces a massive number of parameters. Therefore, we introduced a deep residual convolutional module8, which extracts local information from the data while simultaneously reducing the data dimensionality. Our network comprises a local feature extraction encoder and a global information extractor, enabling the capture of diverse features while ensuring the model remains lightweight.
Our method’s pipline is illustrated in Fig. 2, we initially input the 3D image into four ResBlocks for downsampling and feature extraction. Each ResBlock comprises 3D convolution, 3D batch normalization, ELU layer, and 3D max-pooling. Subsequently, the features are flattened, transformed into patches, and a cls token is added for global information. These features pass through 12 Transformer blocks, including attention and MLP, to capture patch relationships. Finally, the cls token is processed through a Linear layer for classification results.
Subsequently, we performed experiments utilizing ResNet6, CNN6, and ViT networks7. To undertaking a comparative analysis against our method, all models train with learning rate : 1e-4 , batch size : 2, optimizer : AdamW and crossentropy loss.
Results
Fig. 3 illustrates eight classification outcomes, encompassing age groups, varying scalp fat levels, and pass/fail distinctions in two datasets, where confidence exceeding 0.9 indicates stable classification capability.As illustrated in the Table 1, our approach achieved 95% accuracy with a cross-entropy loss of 0.15. The AUC is 0.95, sensitivity is 0.98, and specificity is 0.92, which is sufficient to demonstrate the strong classification capability of our model. CNN has minimal parameters yet approaches the performance of ResNet. On the other hand, ViT exhibits subpar accuracy and slow training efficiency.
Discussion
In our approach, the deep residual convolutional module not only reduces the model's computational complexity but also facilitates Transformer blocks in learning local features. This enhancement makes our method superior to classical convolutional methods. It should be mentioned that the consistency of the labels from experts was not examined and our dataset is relatively smaller compared to some other QC studies, making it challenging to address overfitting comprehensively. There is still room for improvement in the model's performance.Conclusion
In this study, we proposed a Transformer based method to automatically conduct the quality assessment of infants' T1w MRI. Our research presents a viable method for future studies on automatic QC for MRI. This innovative approach enables MR technicians to assess the image quality during the data acquisition.Acknowledgements
This work is partially supported by the STI 2030—Major Project (2022ZD0209000, 2021ZD0200516), Shanghai Pilot Program for Basic Research—Chinese Academy of Science, Shanghai Branch (JCYJ-SHFY-2022-014), Open Research Fund Program of National Innovation Center for Advanced Medical Devices (NMED2021ZD-01-001), Shenzhen Science and Technology Program (No. KCXFZ20211020163408012), and Shanghai Pujiang Program (No. 21PJ1421400).References
1. Alfaro-Almagro F., Jenkinson M., Bangerter N. K., et al. Image processing and Quality Control for the first 10,000 brain imaging datasets from UK Biobank. Neuroimage. 2018; 166: 400-424.
2. Hendriks J, Mutsaerts H J, Joules R, et al. A systematic review of (semi-) automatic quality control of T1-weighted MRI scans[J]. medRxiv, 2023: 2023.09. 07.23295187. doi: https://doi.org/10.1101/2023.09.07.23295187.
3. Sujit S. J., Coronado I., Kamali A., et al. Automated image quality evaluation of structural brain MRI using an ensemble of deep learning networks. J Magn Reson Imaging. 2019; 50(4): 1260-1267.
4. Samani Z. R., Alappatt J. A., Parker D., et al. QC-Automator: Deep Learning-Based Automated Quality Control for Diffusion MR Images. Front Neurosci. 2019; 13: 1456.
5. Sophie L., Simona B, Aurélien M, et al. Automatic motion artefact detection in brain T1-weighted magnetic resonance images from a clinical data warehouse using synthetic data. 2022. ⟨hal-03910451⟩.
6. Simona B, Ninon B, Aurélien M, et al. Automatic quality control of brain T1-weighted magnetic resonance images for a clinical data warehouse,Medical Image Analysis,Volume 75, 2022, 102219; doi: https://doi.org/10.1016/j.media.2021.102219.
7. Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
8. He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
Figures
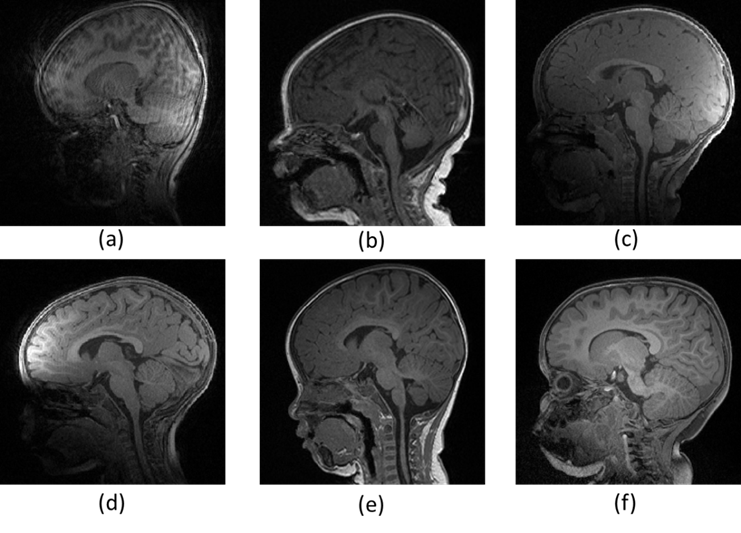
Fig. 1 Examples of T1w images of different qualities. (a) Labeled as "fail" due to severe motion artifacts; (b) Labeled as "fail" due to noticeable motion artifacts; (c) Labeled as "fail" due to the effect of a bias field; (d) Labeled as "fail" due to the motion artifacts and the effect of bias field; (e) Labeled as "pass" though exists minor motion artifacts; (f) Labeled as "pass", and of good image quality.
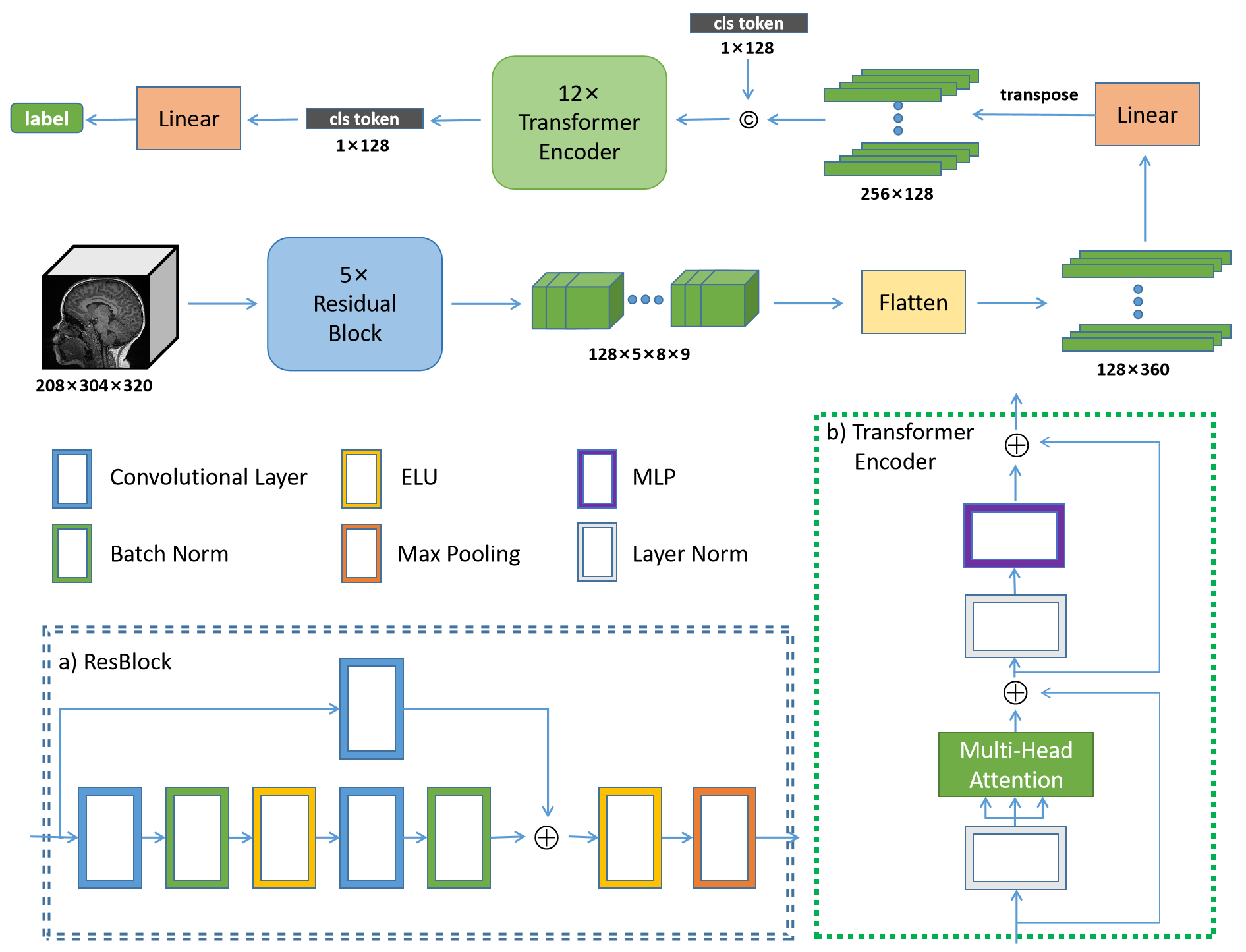
Fig. 2 The overall network architecture. The content within the blue dashed boxes and green dashed boxes represents the specific implementation details of the ResBlock and Transformer Encoder, respectively. The ELU is Exponential Linear Units active function, MLP is Multilayer Perceptron and cls token represents class token.
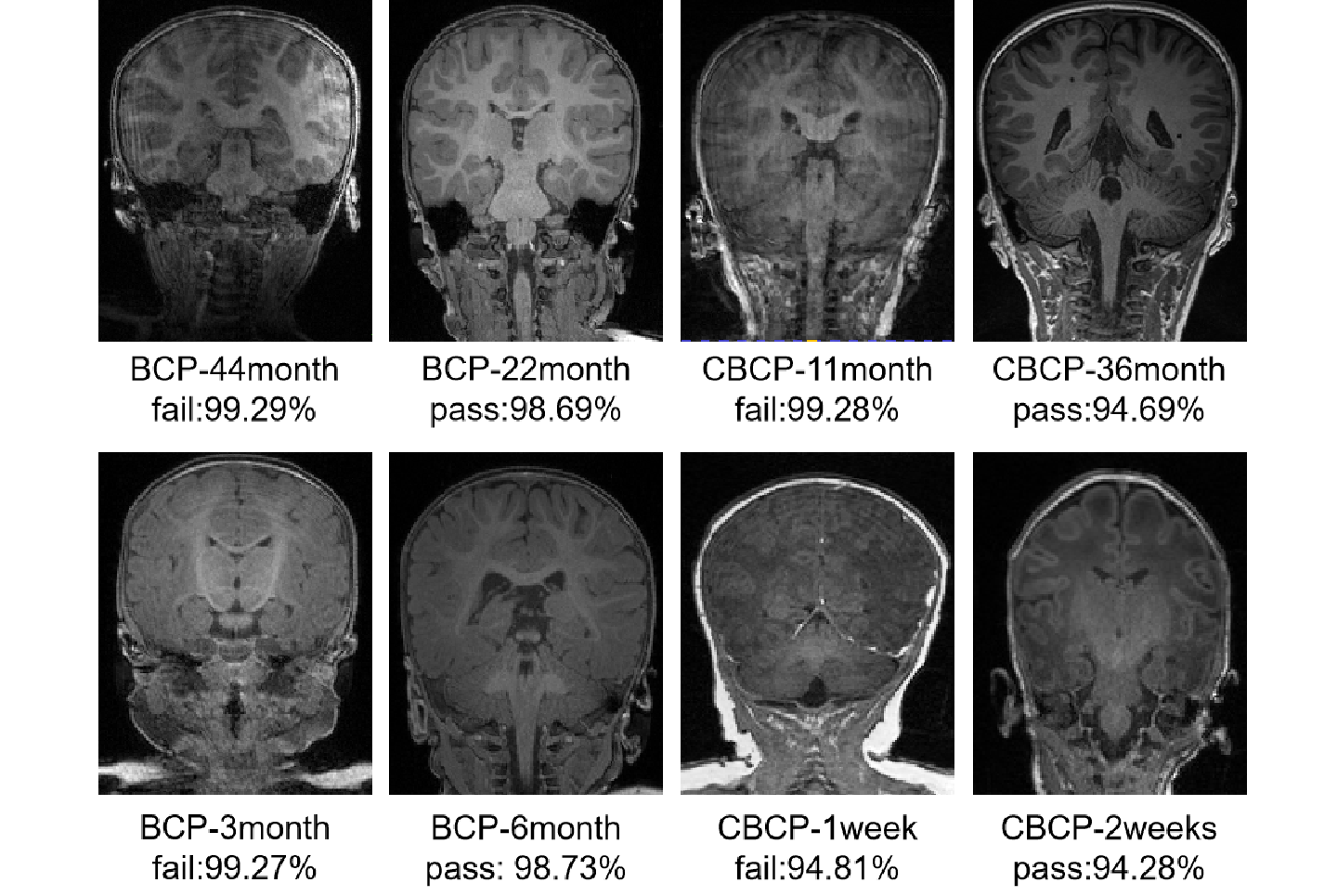
Fig. 3 Our model's confidence in classifying data with different labels across various age groups in both BCP and CBCP datasets.
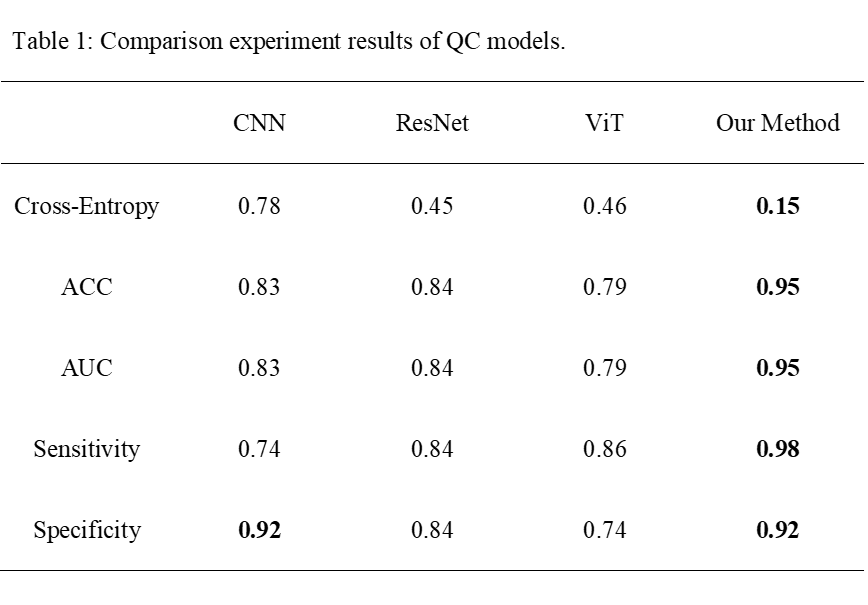
Performance comparison of the proposed model and other models in previous research for quality control evaluation. Our method performs best on all indicators, indicating that the our method has strong discrimination capabilities for positive and negative instances.