1960
Hybrid attention SwinV2 transformer cascade design for Accelerated Multi-Coil MRI Reconstruction1Electrical and Computer Engineering, The University of Texas at El Paso, El Paso, TX, United States, 2Electrical and Computer Engineering, University of Arizona, Tucson, AZ, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence, Transformer, Swin, Attention
Motivation: Shifted window (Swin) Vision Transformers are increasingly outperforming CNNs in computer vision tasks, particularly if adequate GPU resources are available for training.
Goal(s): In this work, we investigate cascaded Swin transformers with hybrid attention for accelerated MRI reconstruction.
Approach: Our proposed Hybrid SwinV2-MRI-cascade architecture incorporates multi-coil data and k-space consistency constraints while offering a high degree of flexibility in network choice depending on performance requirements and compute capabilities.
Results: Experiments show that both hybrid attention and longer cascades can be used in a granular manner to improve MRI reconstruction performance in Swin transformer networks.
Impact: A highly configurable cascaded hybrid attention SwinV2 transformer architecture for MRI reconstruction is proposed. Its modular nature offers the ability to create transformer networks that fully leverage available training compute resources while producing high quality output.
Introduction
MRI acceleration involves undersampled k-space acquisition followed by algorithmic reconstruction through Parallel Imaging (PI)1,2,3 , Compressed Sensing (CS)4,5 , or more recently, using Deep Learning (DL) based approaches, such as Convolutional Neural Networks (CNNs)6,7,8 or Vision Transformers (ViTs)9. Shifted window (Swin) transformers10,11, specifically, have been shown to be effective at single channel12 and multi-channel13 MRI reconstruction. Cascaded networks with alternating reconstruction and data consistency stages have also been shown to be superior to purely model-based approaches14.Swin and SwinV2 transformers divide input images into linearized patches and utilize Self-Attention between patches within non-overlapping local windows to extract image features, allowing them to maintain linear computational complexity to image size. Previously, we proposed the SwinV2-MRI architecture13 that enables the use of SwinV2 Transformers with complex multi-coil MRI data combined with k-space data consistency constraints. Recently, Swin Hybrid Attention15 comprising of channel attention and overlapping attention blocks has been shown to be more effective than the base architecture for natural image restoration15 and MRI super-resolution16. In this work, we have evaluated cascaded SwinV2 transformer structures with and without hybrid attention to identify ideal combinations of Transformer block strength vs cascade length for a variety of GPU memory availability scenarios.
Methods
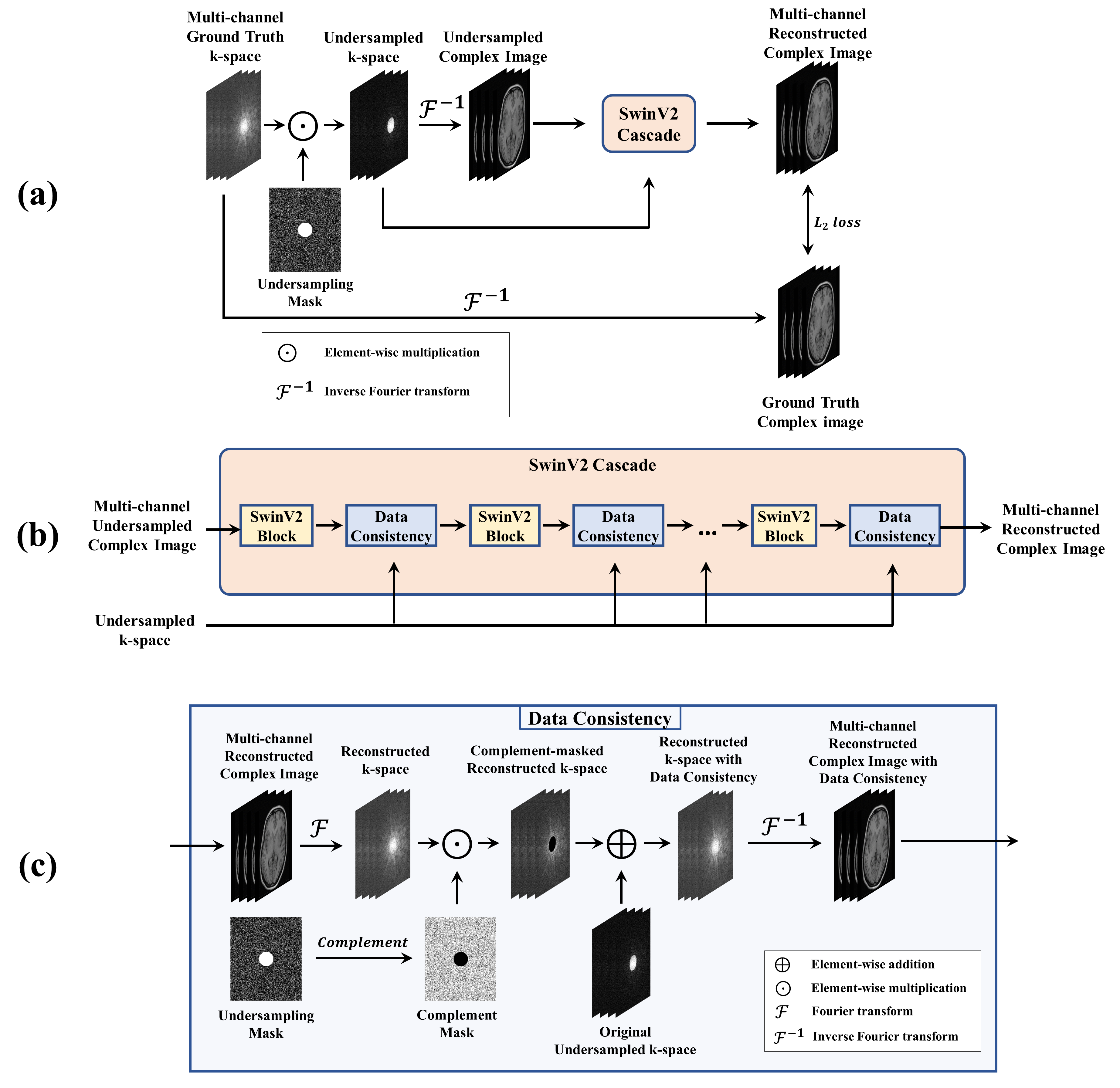
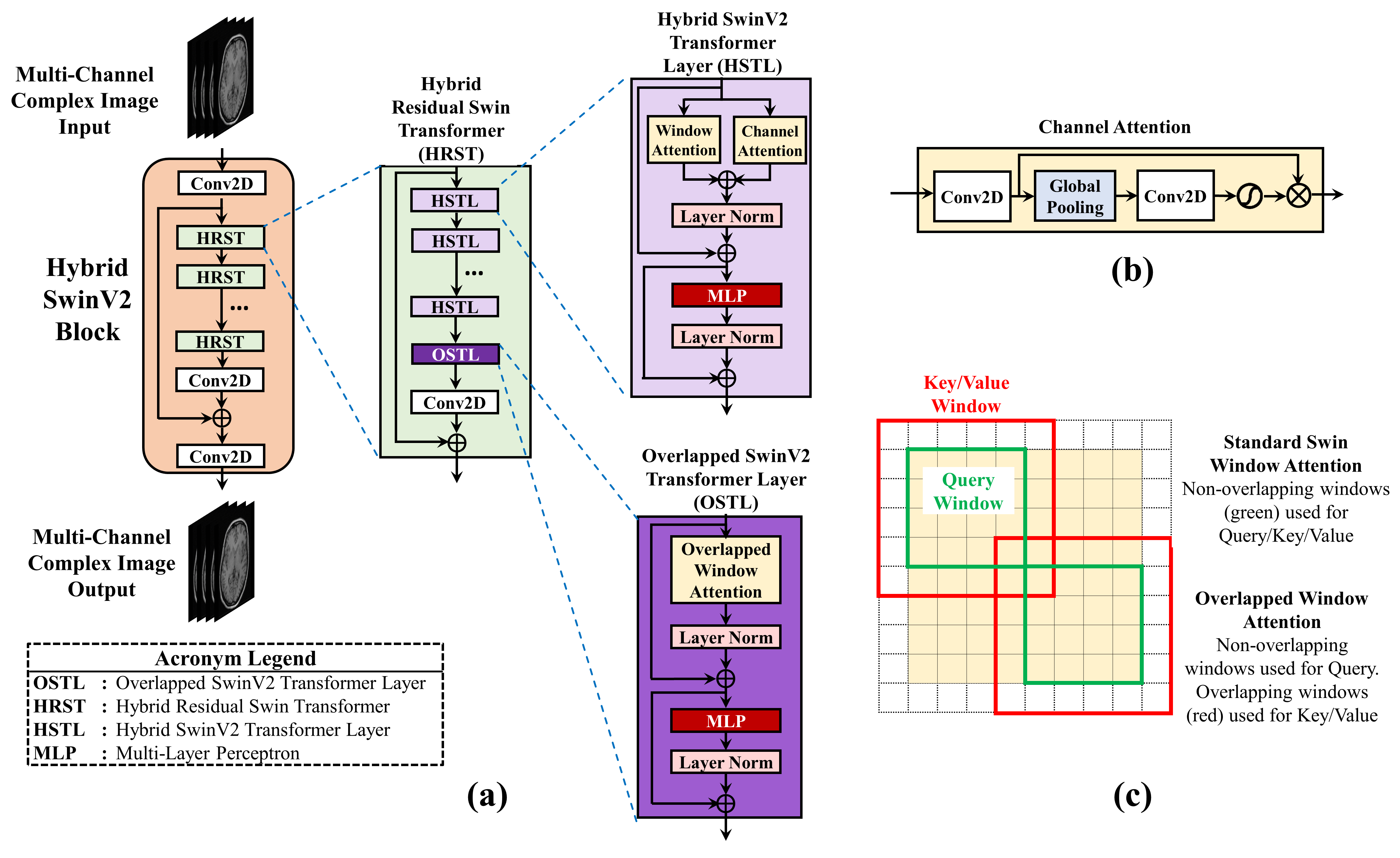
The proposed SwinV2-MRI-cascade reconstruction pipeline is shown in Figure 1(a). During network training, fully-sampled multi-channel 2D k-space slices are first undersampled using a binary sampling mask and converted to complex images, which are then reconstructed using a SwinV2 cascade (Figure 1(b)) to produce the output image. The SwinV2 cascade is composed of alternating stages of SwinV2 blocks and Data Consistency (DC) steps which replace output k-space data points present in the original undersampled k-space as shown in Figure 1(c).The Hybrid SwinV2 Block (HSB) shown in Figure 2(a) follows the general residual structure of the earlier SwinV2-MRI network. In this version, we have additionally introduced the Hybrid and Overlapped Attention SwinV2 layers which feature channel attention (Figure 2(b)) and overlapping windows for key-value generation in SwinV2 attention (Figure 2(c)) respectively. One or more SwinV2 Blocks in the SwinV2 cascade can be hybridized with the remaining blocks using standard non-overlapping SwinV2 attention. This allows for increased flexibility in selecting optimum combinations of network features based on output quality targets vis-à-vis compute resource constraints.
The public Calgary Campinas brain MRI dataset17 was used for all experiments. 2D axial complex k-space slices were extracted from the 67 fully-sampled 12-coil 3D T1-weighted k-space data volumes and 5x undersampling was simulated using a 2D Poisson Disc pattern.
As reference, a standard four stage U-Net18 was used for comparison. The SwinV2 Block is modeled after the original SwinV2-Tiny configuration with 4 residual blocks containing 2-2-6-2 SwinV2 transformer layers and 3-6-12-24 attention heads respectively with embed dimension of 96. Adam optimizer was used for training with L2 loss and batch size of 1. Training was performed for 250,000 iterations with an initial learning rate of 7×10-3 which was decreased following a cosine decay schedule. The trained networks were used to reconstruct unseen undersampled test data (n=2247 slices). PSNR and SSIM were calculated using the Root-Sum-of-Squares RSS reconstructions of the predicted complex images and the ground truth data.
Results
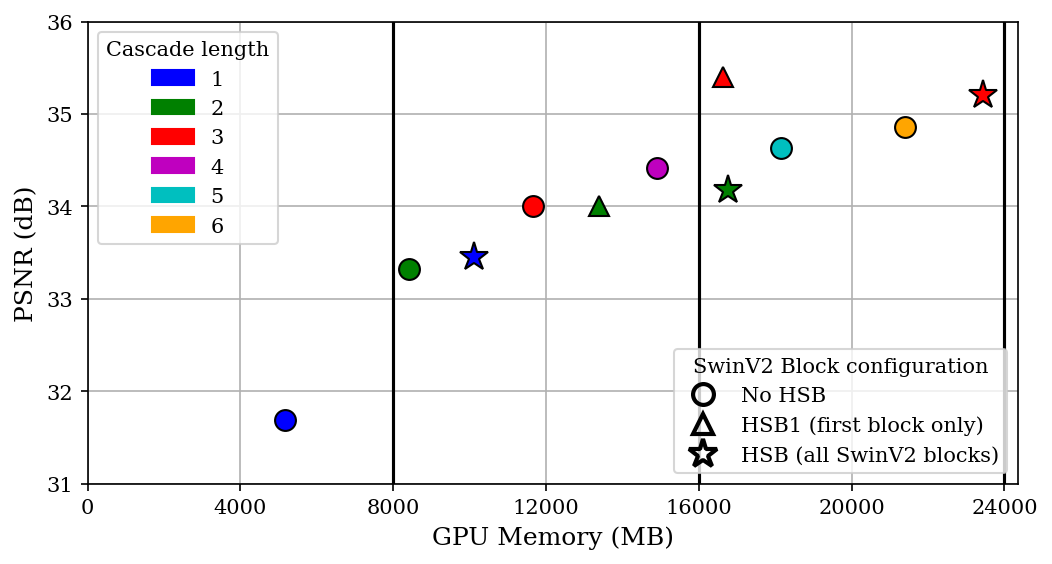
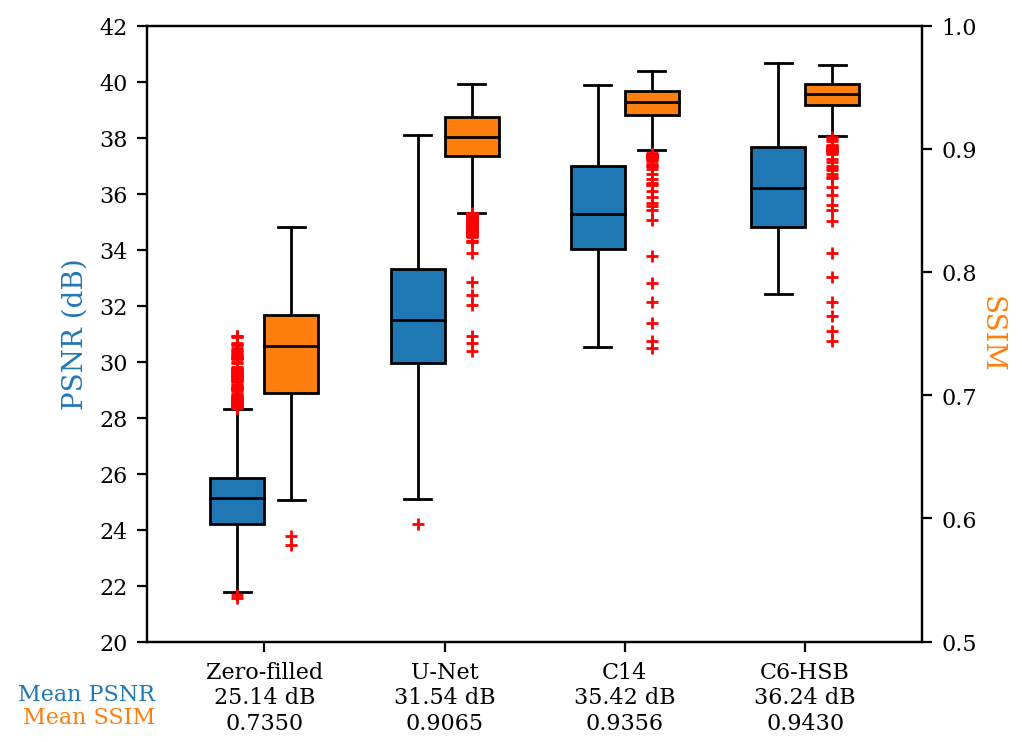
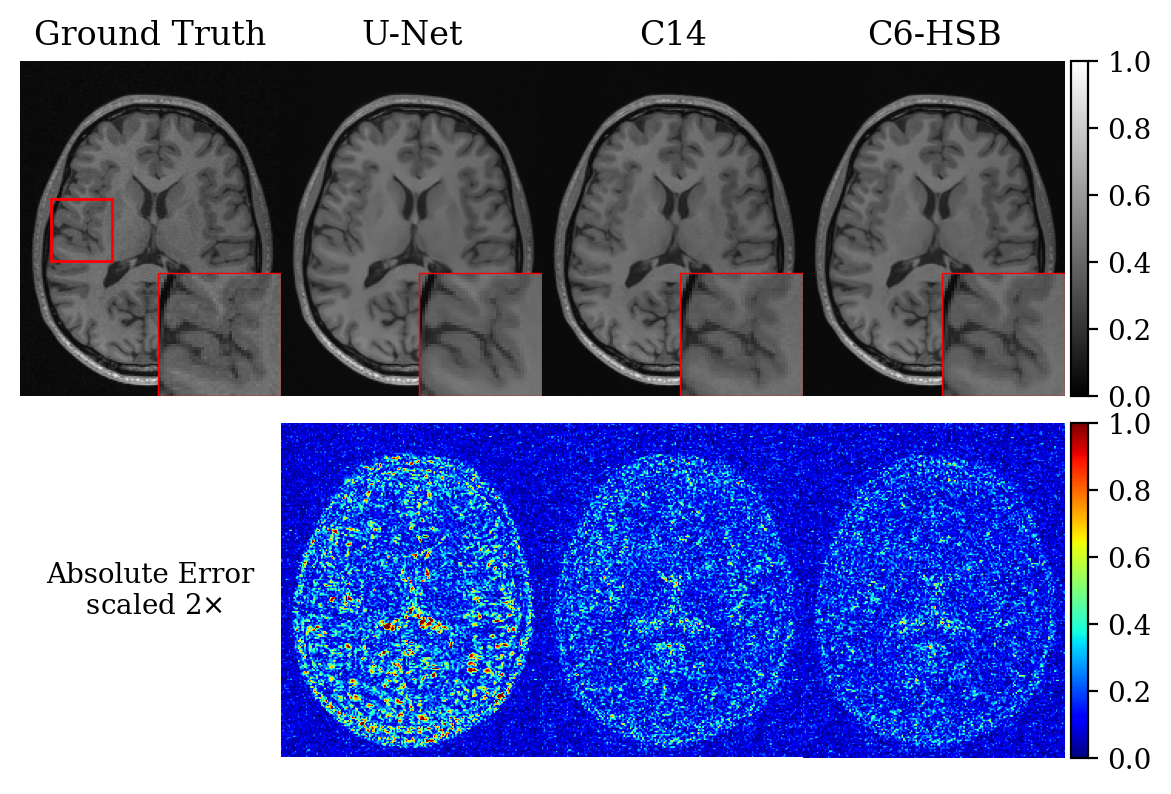
Figure 3 shows the impact of cascade length and HSB on training GPU memory and output test PSNR for network configurations that can be trained with less than 24GB GPU memory. While both parameters have sizable memory impacts, either can be used to improve network performance. Using HSB even in the first SwinV2 Block in the cascade (HSB1) can lead to a performance improvement over strictly non-overlapping attention.Figure 4 shows a quantitative comparison of PSNR and SSIM for two high GPU memory configurations, Cascade 6 with HSB (C6-HSB) requiring 43GB and Cascade 14 (C14) requiring 47GB training memory respectively. Both transformers outperform a standard U-Net and the C6-HSB produces higher average PSNR and SSIM compared to the C14 indicating the increased effectiveness of HSB at scale over very long cascades. The comparison images in Figure 5 show improved edge detail recovery by the C6-HSB with smaller reconstruction errors.
Conclusions
We have shown that a Hybrid SwinV2-MRI-cascade for undersampled MRI reconstruction can produce results superior to CNNs while being highly customizable to fit compute and performance targets. Detailed investigation into the trade-off between cascade length and hybrid attention for longer cascades can potentially lead to further improved performance and better generalization over larger datasets due to the superior scalability of the Transformer architecture.Acknowledgements
We would like to acknowledge support from the Texas Instruments Foundation Endowed Graduate Scholarship Program at the University of Texas at El Paso and the Technology and Research Initiative Fund (TRIF) Improving Health Initiative at The University of Arizona.References
1. Pruessmann, K. P., Weiger, M., Scheidegger, M. B. & Boesiger, P. SENSE: sensitivity encoding for fast MRI. Magn Reson Med 42, 952–962 (1999). PMID: 10542355.
2. Griswold, M. A., Jakob, P. M., Heidemann, R. M., Nittka, M., Jellus, V., Wang, J., Kiefer, B. & Haase, A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn Reson Med 47, 1202–10 (2002). doi: 10.1002/mrm.10171. PMID: 12111967.
3. Uecker, M., Lai, P., Murphy, M. J., Virtue, P., Elad, M., Pauly, J. M., Vasanawala, S. S. & Lustig, M. ESPIRiT - An eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magn Reson Med 71, 990–1001 (2014). doi: 10.1002/mrm.24751. PMID: 23649942.
4. Lustig, M., Donoho, D. & Pauly, J. M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn Reson Med 58, 1182–1195 (2007). doi: 10.1002/mrm.21391. PMID: 17969013.
5. Lustig, M., Donoho, D. L., Santos, J. M. & Pauly, J. M. Compressed Sensing MRI. IEEE Signal Processing Magazine 72–82 (2008).
6. Hyun, C. M., Kim, H. P., Lee, S. M., Lee, S. & Seo, J. K. Deep learning for undersampled MRI reconstruction. Phys. Med. Biol 63, (2018).
7. Sriram, A., Zbontar, J., Murrell, T., Defazio, A., Zitnick, C. L., Yakubova, N., Knoll, F. & Johnson, P. End-to-end variational networks for accelerated MRI reconstruction. in International Conference on Medical Image Computing and Computer-Assisted Intervention 64–73 (Springer, 2020).
8. Rahman, T., Bilgin, A. & Cabrera, S. Asymmetric decoder design for efficient convolutional encoder-decoder architectures in medical image reconstruction. in Multimodal Biomedical Imaging XVII 11952, 7–14 (SPIE, 2022). doi: https://doi.org/10.1117/12.2610084.
9. Lin, K. & Heckel, R. Vision Transformers Enable Fast and Robust Accelerated MRI. in Medical Imaging with Deep Learning (2021).
10. Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S. & Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. in Proceedings of the IEEE International Conference on Computer Vision (2021). doi: 10.1109/ICCV48922.2021.00986.
11. Liu, Z., Hu, H., Lin, Y., et al. Swin transformer v2: Scaling up capacity and resolution. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 12009–12019 (2022).
12. Huang, J., Fang, Y., Wu, Y., Wu, H., Gao, Z., Li, Y., Ser, J. Del, Xia, J. & Yang, G. Swin transformer for fast MRI. Neurocomputing 493, 281–304 (2022). doi: https://doi.org/10.1016/j.neucom.2022.04.051.
13. Rahman, T., Bilgin, A. & Cabrera, S. SwinV2-MRI: Accelerated Multi-Coil MRI Reconstruction using Shifted Window Vision Transformers. in Proc. of the 2023 Annual Meeting of the ISMRM (2023).
14. Yiasemis, G., Sonke, J.-J., Sánchez, C. & Teuwen, J. Recurrent variational network: a deep learning inverse problem Solver applied to the task of accelerated MRI reconstruction. in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 732–741 (2022).
15. Chen, X., Wang, X., Zhang, W., Kong, X., Qiao, Y., Zhou, J. & Dong, C. HAT: Hybrid Attention Transformer for Image Restoration. arXiv preprint arXiv:2309.05239 (2023).
16. Grigas, O., Maskeliūnas, R. & Damaševičius, R. Improving Structural MRI Preprocessing with Hybrid Transformer GANs. Life 13, (2023). doi: 10.3390/life13091893.
17. Souza, R., Lucena, O., Garrafa, J., Gobbi, D., Saluzzi, M., Appenzeller, S., Rittner, L., Frayne, R. & Lotufo, R. An open, multi-vendor, multi-field-strength brain MR dataset and analysis of publicly available skull stripping methods agreement. Neuroimage 170, 482–494 (2018). doi: 10.1016/j.neuroimage.2017.08.021. PMID: 28807870.
18. Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. in International Conference on Medical image computing and computer-assisted intervention 234–241 (Springer, 2015).
Figures