1956
Multi Complex-valued Spatio-temporal Fusion Networks for Robust MRF Reconstruction1The University of Queensland, Brisbane, Australia, 2Central South University, Changsha, China
Synopsis
Keywords: AI/ML Image Reconstruction, MR Fingerprinting
Motivation: Motivated by the prevalent use of basic deep learning architectures in MRF image reconstruction, and their heavy reliance on conventional dictionary matching methods for ground truth or paired in vivo acquisitions, we sought to innovate.
Goal(s): Our specific intent was to determine whether novel architectures could surpass traditional ones in MRF reconstruction.
Approach: To this end, we introduced the MRF-Mixer, blending complex-valued MLP with U-Net, and the more advanced MRF-TransMixer, integrating complex-valued MLP, Transformer, and U-Net.
Results: Leveraging our purely simulated training dataset, we methodically assessed their performance, endeavoring to highlight advancements with potential to transform MRF reconstruction in practice.
Impact: The MRF-Mixer and MRF-TransMixer offer enhanced MRF image reconstruction, potentially boosting diagnostic accuracy for clinicians. This advancement could lead to safer imaging for patients and motivate researchers to further explore SOTA network architecture applications in MRF.
Introduction
Magnetic Resonance Fingerprinting (MRF) enables simultaneous measurements of multiple tissue parameter maps, such as T1 T2 and B0, holding great potential for clinical applications1. Recently, deep learning (DL) MRF methods, e.g., MLP-based DRONE2 and CNN-based SCQ-Net3, are emerging as alternatives to the traditional dictionary matching (DM) based MRF reconstruction methods. However, current DL MRF methods have primarily been developed using real-valued neural networks, utilizing only the magnitude component of the signal evolution, and they do not fully explore the spatio-temporal nature of the MRF signal. In this work, we proposed a new complex-valued spatio-temporal fusion network, MRF-TransMixer for MRF, and results from our simulated data and an in vivo subject acquired at 3T were demonstrated.Methods
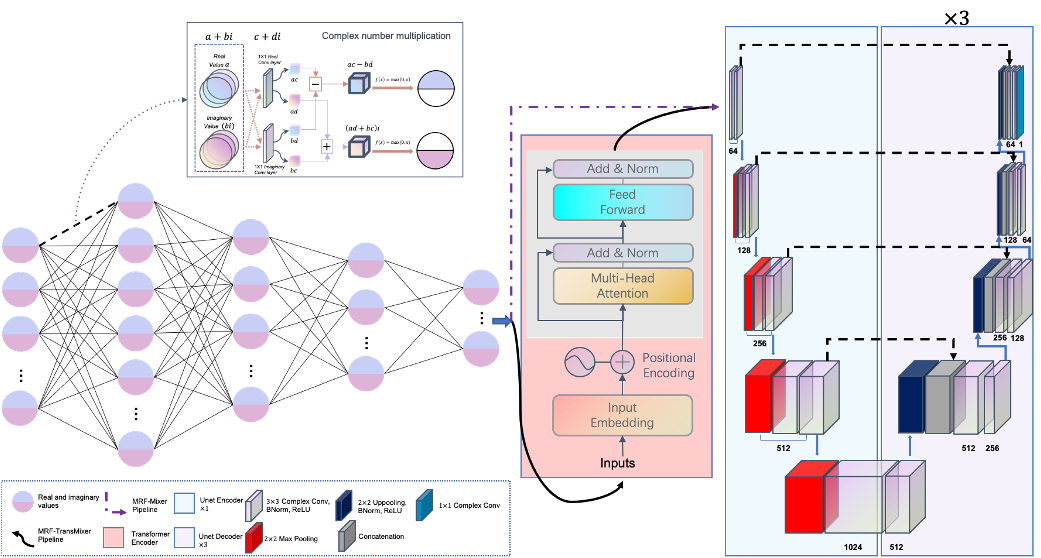
Figure 1 shows the proposed complex-valued network architectures, MRF-Mixer4 and MRF-TransMixer. MRF-Mixer consists of a complex-convolution based Multilayer Perceptron (cMLP) and a complex-valued Unet (followed by dashed purple arrow). MRF-TransMixer consists of a cMLP, a transformer encoder and a complex-valued Unet (followed by solid black arrow). The cMLP operates the MRF input data pixel-wisely along the temporal dimension, the transformer encoder operates the processed complex value from cMLP to get more long-range features along the temporal dimension, and the Unet is designed to capture the features on the spatial dimension and a shared encoder and three difference decoder will applied to predict T1, T2 and B0 separately. The main difference between MRF-Mixer and MRF-TransMixer is that we add the transformer encoder inside our network. The self-attention mechanism of the Transformer has the ability to capture long-range signal dependencies5. This feature may help the network more effectively grasp the temporal dynamics of the MRF signals.Training data
In this study, the proposed complex MRF networks were trained on a retrospective dataset (MRF-dataset) generated through this equation: $$S_k = U × F × Bloch(T1, T2, B0, FAs, TRs),$$ where T1, T2 and B0 are the training ground truths, while the $$$S_k$$$ represents the k-space MRF raw data. The $$$U$$$ and $$$F$$$ represent the under-sampling and Fourier transform matrix, respectively. $$$Bloch$$$ denotes the Bloch Equation simulating the signal evolution process based on an IR-bSSFP sequence with 1000 pseudo-random Flip Angles and TRs, which is also the dictionary generator for traditional DM methods. In this work, we used the singular value decomposition (SVD) to downsize the time series from 1000 time points to 200-time points, then using the SVD version dataset as our training data. In this work, the dictionary matching method was based on a dictionary of 643200 elements (T1: 100-4000ms, with 100ms steps; T2: 10-800ms, with 10ms steps; B0: -200-200 Hz, with 2 Hz step).
Validation
The proposed MRF-TransMixer, and MRF-Mixer were compared with traditional DM method, single value magnitude MLP on the training data validation set, and two invivo MRF scans (1, and 6 radial sampling arms, respectively) from a healthy volunteer at 3T with 1mm isotropic resolution.
Results
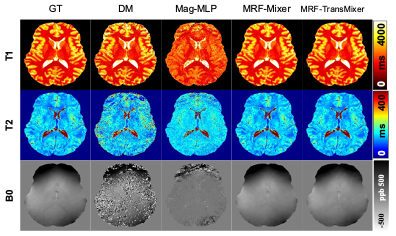
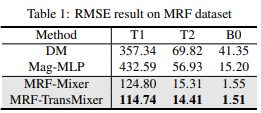
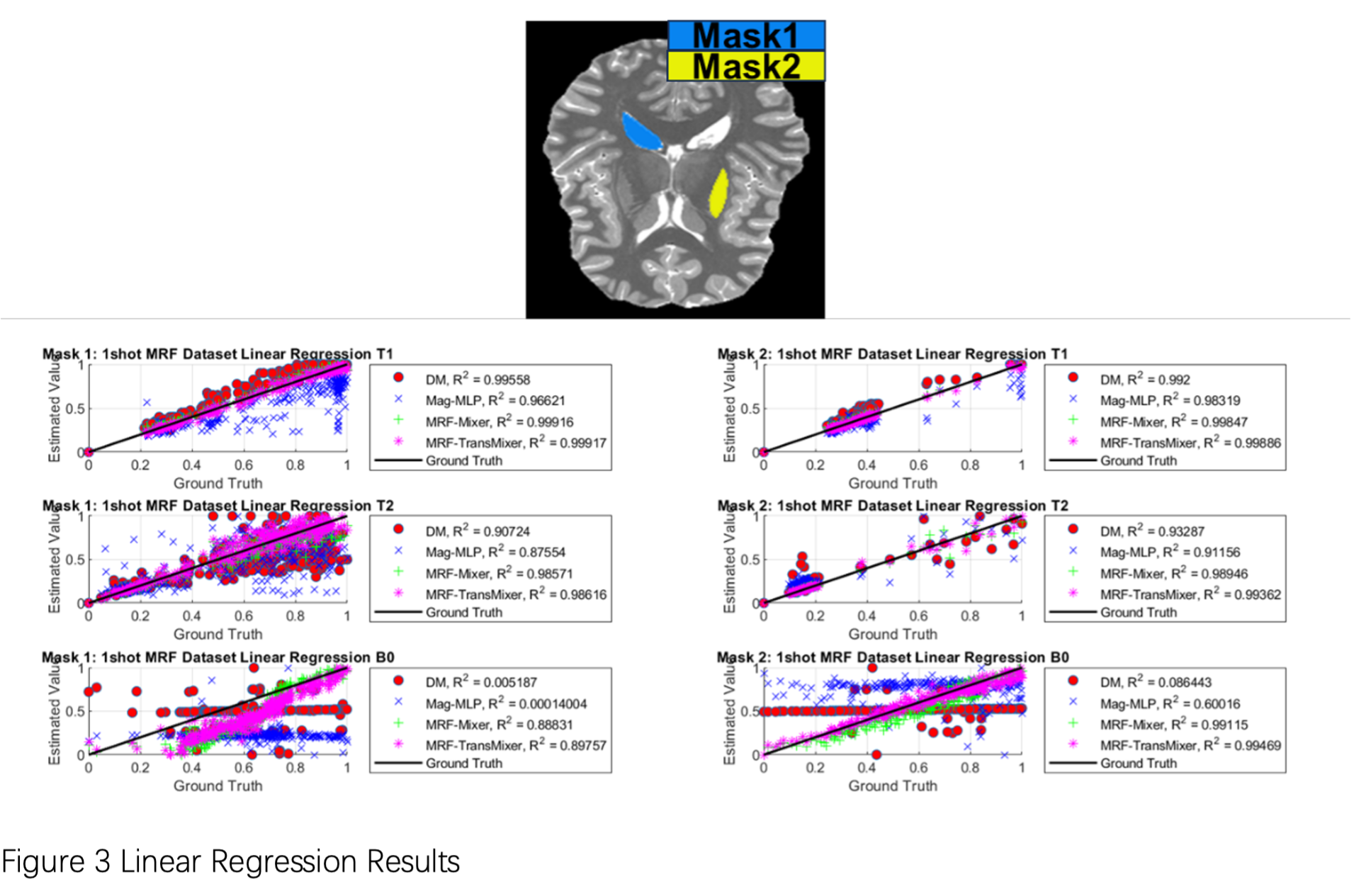
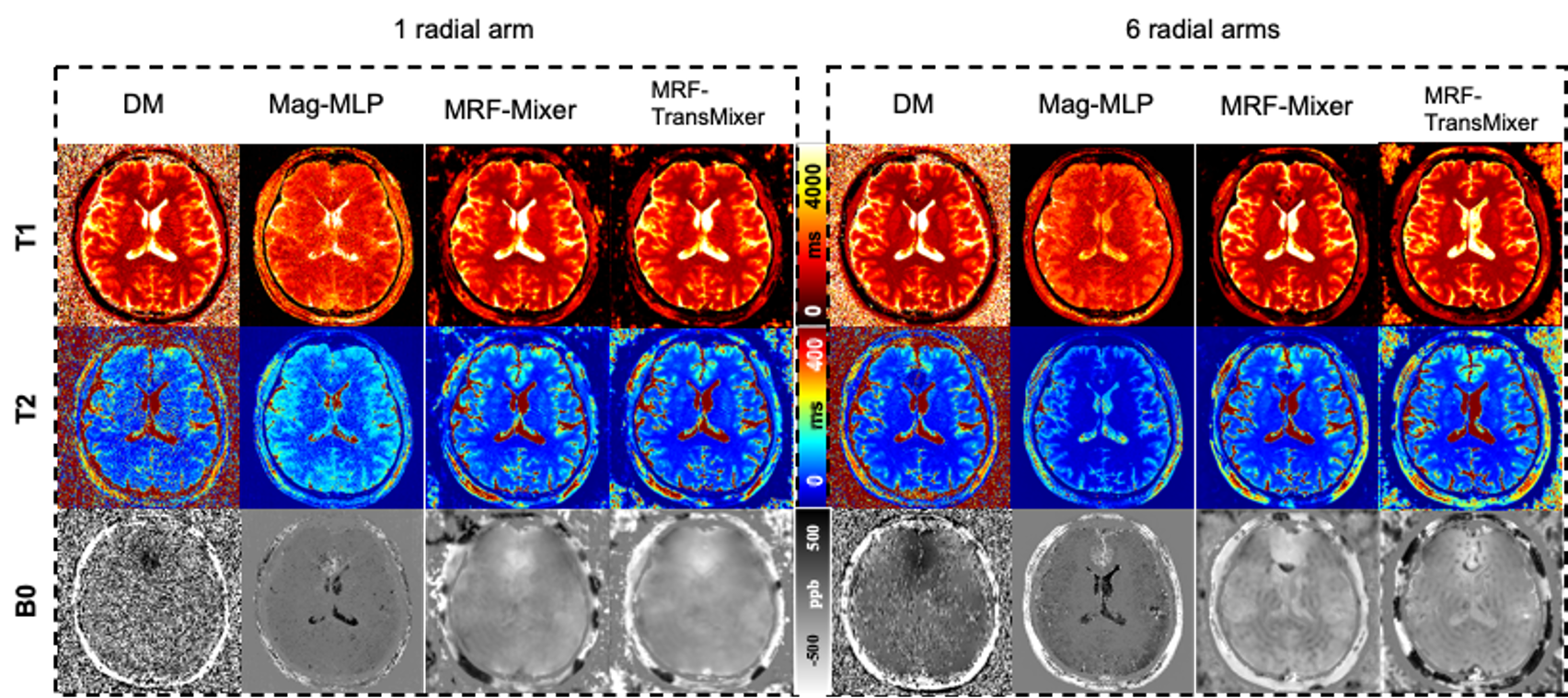
Figure 2 shows the results from various methods applied to the MRF dataset using a single radial arm. Figure 3 shows the linear regression results for the MRF Dataset. It is evident that our introduced models, MRF-Mixer and MRF-TransMixer, generally perform well across the T1, T2, and B0 image. In comparison, the DM and Mag-MLP methods appear to exhibit some noisy artifacts in certain conditions. Table 1 and Figure 3 further quantifies these observations, indicating that, on average, MRF-TransMixer tends to achieve better metrics than both DM and Mag-MLP across T1, T2 and B0.In terms of the in vivo results, Figure 3 compares the proposed DL-based methods with traditional DM methods on an in vivo brain acquired at 3T. The proposed MRF-Mixer and MRF-TransMixer models showed superior performances over the DM results and Mag-MLP results, especially on T2 reconstruction, with the appended transformer encoder and U-net significantly improving the image quality, particularly at 1 radial arm. It is also found that the complex-convolution based MLP showed better T1 and T2 images with clearer structural delineation, compared with Mag-MLP. Besides, the complex-MLP-based methods showed consistent results on both 1- and 6-radial arms MRF data, while DM’s results dramatically degraded on the 1-radial arm data.
Conclusion and Discussion
This study introduced complex-valued DL-MRF methods that surpassed traditional DM and prior mag-DL-MRF techniques in terms of reconstruction performance, notably in T2 reconstruction. By appropriately adapting advanced network architectures, we enhanced the model's performance. This suggests that the application of advanced network designs can elevate the robustness of DL-MRF, rendering it more dependable for prospective clinical applications. Subsequent research should delve into refined network architectures for MRF reconstruction and assess alternative acquisition sequences.Acknowledgements
HS acknowledges support from the Australian Research Council (DE210101297, DP230101628).References
1. D. Ma et al., “Magnetic resonance fingerprinting,” Nature, vol. 495, no. 7440, pp. 187–192, Mar. 2013, doi: https://doi.org/10.1038/nature11971.
2. O. Cohen, B. Zhu, and M. S. Rosen, “MR fingerprinting Deep RecOnstruction NEtwork (DRONE),” Magnetic Resonance in Medicine, vol. 80, no. 3, pp. 885–894, Apr. 2018, doi: https://doi.org/10.1002/mrm.27198.
3. Z. Fang et al., "Deep Learning for Fast and Spatially Constrained Tissue Quantification From Highly Accelerated Data in Magnetic Resonance Fingerprinting," in IEEE Transactions on Medical Imaging, vol. 38, no. 10, pp. 2364-2374, Oct. 2019, doi: 10.1109/TMI.2019.2899328.
4. Y. Gao et al., “MRF-mixer: a self-supervised deep learning MRF framework,” presented at the ISMRM, Jun. 07, 2023.
5. A. Vaswani et al., “Attention Is All You Need,” arXiv.org, 2017. https://arxiv.org/abs/1706.03762
Figures