1955
Cross-Attention Mechanism and Vision Transformer-Enhanced Multimodal Medical Imaging Fusion for Nasopharyngeal Carcinoma Segmentation1Lauterbur Research Center for Biomedical Imaging, Shenzhen Institute of Advanced Technology, Shenzhen, China, 2Department of Nuclear Medicine, Sun Yat‐sen University Cancer Center, Guangzhou, China, 3Key Laboratory of Biomedical Imaging Science and System, Chinese Academy of Sciences, Shenzhen, China
Synopsis
Keywords: Diagnosis/Prediction, Data Analysis
Motivation: The segmentation of nasopharyngeal carcinoma (NPC) is vital for diagnostic and prognostic processes. NPC segmentation is challenging due to its intricate anatomy, variability, and closeness to essential structures.
Goal(s): This study aims to improve NPC segmentation accuracy by leveraging multiple modalities, such as DCE-MRI and PET-CT. However, it is worth noting that previous research has not fully harnessed the potential of cross-modal features through cross-attention mechanisms.
Approach: This paper introduces a new approach, integrating cross-attention with the Vision Transformer structure, enabling efficient interaction between features from various modalities.
Results: The experiments show that the proposed model offers superior performance and state-of-the-art results.
Impact: The proposed method aims to enhance NPC segmentation results by utilizing multimodal medical imaging fusion, such as DCE-MRI fusion and PET-CT fusion. This approach has the potential to benefit other segmentation tasks involving multimodal medical image data.
Introduction
Accurate segmentation of nasopharyngeal carcinoma (NPC) lesions is pivotal for refining diagnostic and prognostic evaluations [1]. NPC segmentation poses distinct challenges due to its intricate anatomy, varied presentations, and close association with critical structures, such as the skull base, cranial nerves, and major blood vessels [2]. While prior research indicates that segmentation precision can be enhanced by merging information from multiple imaging modalities—such as CT-MRI fusion, dynamic contrast-enhanced MRI (DCE-MRI), and PET-CT fusion [3-5]—few studies have exploited the potential of cross-modal feature extraction. Such mechanisms have demonstrated significant promise in facilitating informed decision-making, culminating in superior outcomes in natural image processing [6,7]. This paper introduces innovative cross-attention techniques tailored for NPC segmentations. These techniques synergize cross-attention mechanisms with the robust Vision Transformer architecture, promoting efficient interactions between features from disparate modalities. The outcome is a highly efficient model offering superior generalization, as evidenced by state-of-the-art results.Materials and methods
Patient studies:The proposed method is designed for multimodal cross-fusion, which can be implemented in MR, CT, and PET fusion. PET-CT is used herein for method validation due to data availability. Data from 51 patients (range of 23-66 years old) were acquired to validate the performance of the proposed method. Whole-body PET scans (uEXPLORE, United Imaging Healthcare, Shanghai) were executed in a single bed position, covering the entire body from head to toe. The PET image was reconstructed using the ordered subset expectation maximization algorithm and a series of setting parameters: 150×150 matrix under 600 mm FOV, thickness of 2.89 mm, time-of-flight (TOF), and point spread function (PSF) modeling, two iterations, 20 subsets, and a Gaussian postfilter with 3 mm. We obtained CT images with a size of 512×512 and PET images with a size of 256×256. Before the experiment, we interpolated the dimensions of the CT images to match the 256×256 resolution of the PET images. The total number of axial slices for all images was 673, and the slice thickness was 1.443 mm.
Method Implements:
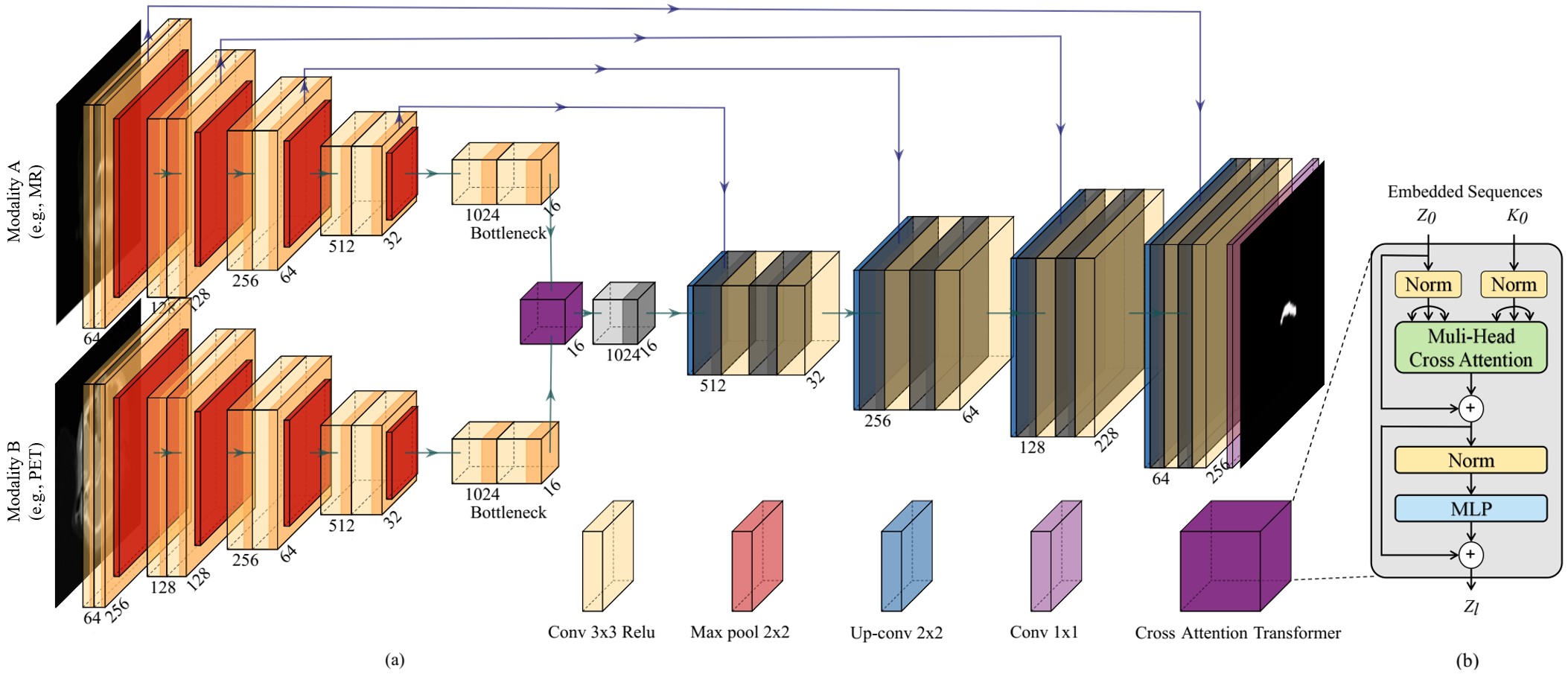
The proposed method incorporates skip connections for gradient preservation and comprises shallow and deep feature extraction components for efficient feature extraction. We use a modified U-Net architecture to extract shallow features and a cross-attention transformer to derive deep features. The input images from both modalities are initially encoded separately by the U-Net and passed through the cross-attention transformer for cross-modal deep feature extraction. Subsequently, the U-Net decoder integrates shallow and deep features to generate segmentation masks. The skip connection ensures the conveyance of gradients through the PET modality. An illustration of the proposed architectures is presented in Figure 1.
Data analysis:
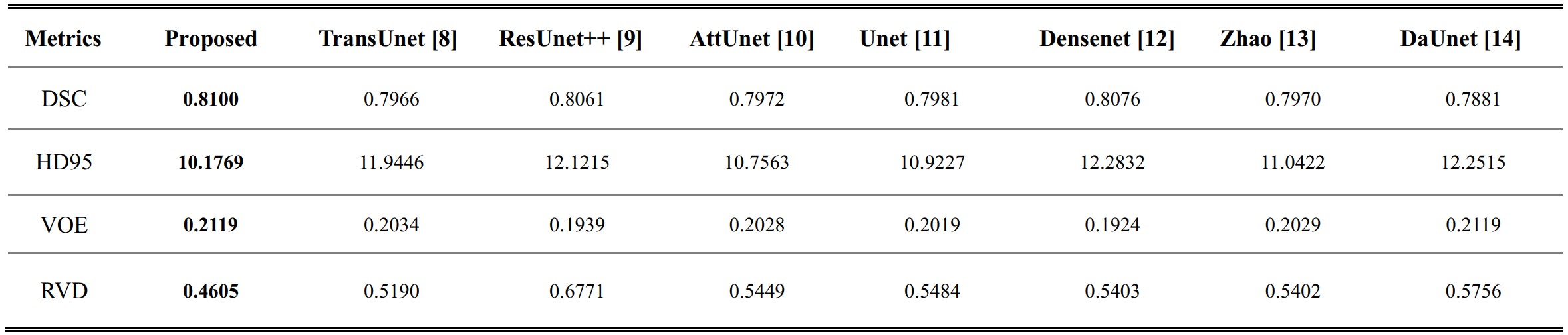
To compare the segmentation quality, we choose several indices, such as the DSC (Dice similarity coefficient), the 95% Hausdorff distance (HD95), voxel overlap error (VOE), and relative volume difference (RVD), to quantify the segmentation effectiveness. We evaluate the reasonability and robustness of the proposed method by comparing it with several state-of-the-art model-based methods, such as TransUnet [8] ResUnet++ [9] AttUnet [10] Unet [11] Densenet [12] Zhao [13] DaUnet [14].
Results
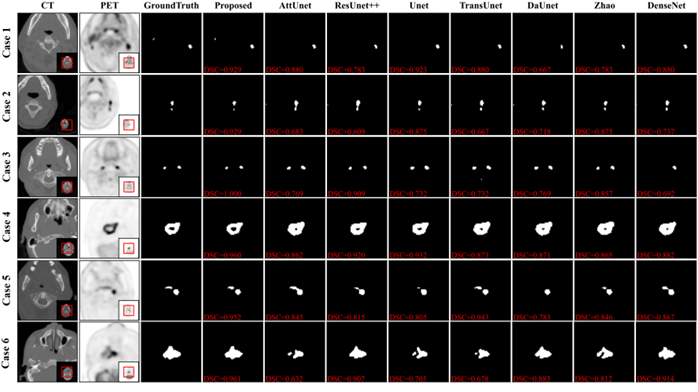
Figure 2 presents the visual comparison results for different methods. These results display a few representative cases of the segmentation outcomes for each method. Case 1 to Case 3 depict scenarios with small tumors, and Case 4 to Case 6 showcase the situation with large tumors. A close inspection of these results reveals that the proposed methods exhibit the best performance among the compared techniques, regardless of tumor size, position, and distribution variations. This robustness is an indication of the effectiveness of the proposed methods. Moreover, we also calculate the evaluation metrics for the test datasets, as shown in Table 1. Our method offers superior performance compared with the other methods.Discussion and conclusion
In summary, our study introduces innovative cross-attention techniques tailored for NPC segmentations. By synergizing cross-attention strategies with the robust Vision Transformer architecture, we facilitate seamless interactions between features across various modalities. This synthesis results in a model characterized by heightened efficiency and superior generalization, as underscored by state-of-the-art results. Our empirical findings highlight the enhanced performance and robustness of the method proposed. Given the focus of our approach on multimodality fusion, we plan to evaluate its applicability to PET-MR and DCE-MRI modalities in future studies.Acknowledgements
This work was supported by the National Natural Science Foundation of China (82372038 and 62101540), the Shenzhen Excellent Technological Innovation Talent Training Project of China (RCJC20200714114436080), the Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2023B1212060052) and the Shenzhen Science and Technology Program (JCYJ20220818101804009 and RCBS20210706092218043).References
[1] T. Xu, G. Shen, Chunyingand Zhu, and C. Hu, “Omission of chemotherapy in early stage nasopharyngeal carcinoma treated with imrt: A paired cohort study,” Medicine, vol. 94, no. 39, 2015.
[2] L.-L. Tang, W.-Q. Chen, W.-Q. Xue, Y.-Q. He, R.-S. Zheng, Y.-X. Zeng, and W.-H. Jia, “Global trends in incidence and mortality of nasopharyngeal carcinoma,” Cancer Letters, vol. 374, no. 1, pp. 22–30, 2016.
[3] J. Huang, S. Yang, L. Zou, Y. Chen, L. Yang, B. Yao, Z. Huang, Y. Zhong, Z. Liu, and N. Zhang, “Quantitative pharmacokinetic parameter ktrans map assists in regional segmentation of nasopharyngeal carcinoma in dynamic contrast-enhanced magnetic resonance imaging (dce-mri),” Biomedical Signal Processing and Control, vol. 87, p. 105433, 2024.
[4] Z. Huang, X. Liu, R. Wang, Z. Chen, Y. Yang, X. Liu, H. Zheng, D. Liang, and Z. Hu, “Learning a deep cnn denoising approach using anatomical prior information implemented with attention mechanism for low-dose ct imaging on clinical patient data from multiple anatomical sites,” IEEE Journal of Biomedical and Health Informatics, vol. 25, no. 9, pp. 3416–3427, 2021.
[5] A. Patel, P.-D. Tudosiu, W. H. L. Pinaya, G. Cook, V. Goh, S. Ourselin, and M. J. Cardoso, “Cross attention transformers for multimodal unsupervised whole-body pet anomaly detection,” in Deep Generative Models, A. Mukhopadhyay, I. Oksuz, S. Engelhardt, D. Zhu, and Y. Yuan, Eds. Cham: Springer Nature Switzerland, 2022, pp. 14–23.
[6] P. Xu, X. Zhu, and D. A. Clifton, “Multimodal learning with transformers: A survey,” 2023.
[7] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in International Conference on Learning Representations, 2021.
[8] J. Chen, Y. Lu, Q. Yu, X. Luo, E. Adeli, Y. Wang, L. Lu, A. L. Yuille, and Y. Zhou, “Transunet: Transformers make strong encoders for medical image segmentation,” 2021.
[9] D. Jha, P. H. Smedsrud, M. A. Riegler, D. Johansen, T. D. Lange, P. Halvorsen, and H. D. Johansen, “Resunet++: An advanced architecture for medical image segmentation,” in 2019 IEEE International Symposium on Multimedia (ISM), 2019, pp. 225–2255.[10] O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, K. Mori, S. McDonagh, N. Y. Hammerla, B. Kainz, B. Glocker, and D. Rueckert, “Attention u-net: Learning where to look for the pancreas,” 2018.
[11] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, N. Navab, J. Hornegger, W. M. Wells, and A. F. Frangi, Eds. Cham: Springer International Publishing, 2015, pp. 234–241.
[12] Y. Li, G. Han, and X. Liu, “Dcnet: Densely connected deep convolutional encoder;decoder network for nasopharyngeal carcinoma segmentation,” Sensors, vol. 21, no. 23, 2021.
[13] L. Zhao, Z. Lu, J. Jiang, Y. Zhou, Y. Wu, and Q. Feng, “Automatic nasopharyngeal carcinoma segmentation using fully convolutional networks with auxiliary paths on dual-modality pet-ct images,” Journal of Digital Imaging, vol. 32, no. 3, pp. 462–470, Jun 2019.
[14] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY, USA: Curran Associates Inc., 2017, p. 6000–6010.
Figures