1954
Cerebral Artery Segmentation with Limited Data: Using Hierarchical Transformers1CTS, Philips Healthcare, Beijing, China, 2Department of Radiology, and Functional and Molecular Imaging Key Laboratory of Sichuan Province, West China Hospital of Sichuan University, Chengdu, China
Synopsis
Keywords: Analysis/Processing, Machine Learning/Artificial Intelligence
Motivation: Transformer networks have demonstrated their effectiveness in both large-scale natural language processing and 2D image analysis tasks. However, their potential in 3D medical image analysis, particularly on small training datasets, remains unexplored.
Goal(s): Leveraging transformer-based models to attain highly accurate cerebral artery segmentation in 3D TOF-MRA images.
Approach: SwinUNETR with a hard example mining loss function to perform cerebral artery segmentation on the public dataset CAS2023.
Results: We obtained an average Dice score of 0.844 and 0.889 for the stenosis area, a normalized Hausdorff distance of 0.888 and 0.8444 for the stenosis area, along with a weighted Dice and Hausdorff score of 0.867.
Impact: We used fewer than 100 cases to train a transformer model for artery segmentation, indicating that transformers have the potential to replace CNNs in the processing of 3D TOF-MRA medical images, even with a small training dataset.
Introduction
Accurate assessment of cerebral vasculature is important in neuroimaging, impacting the diagnosis and treatment of cerebrovascular diseases, including ischemic stroke, artery stenosis, and artery occlusion1. Deep learning segmentation holds potential to replace manual vessel delineation, relieving radiologist workloads and ensuring consistent delineation. In 3D medical imaging, CNNs have dominated both MR and CT images2,3, while transformers excel in other data modalities, such as language and 2D vision4. The training data volume plays a central role in this discrepancy, with collecting substantial annotated 3D medical images often proving challenging. Transformers have shown superior performance with larger training datasets, offering a distinct advantage over CNNs due to their capacity to handle multimodal data and share knowledge5,6. As a result, researchers have focused on enhancing the accuracy of transformers with limited training data. Hierarchical transformers, when combined with a UNet head, can effectively segment 3D medical images7-10. Transformers' ability to handle diverse modalities within a single architecture makes them more efficient in practice than using multiple task-specific CNN models. This study aims to introduce the transformer architecture to 3D cerebral MR images and incorporate techniques like hard example mining to improve vessel segmentation accuracy with limited training data.Methods
We used the public dataset CAS202311 from MICCAI2023 cerebral artery segmentation challenge, including 100 scans with ground truth. We used 80 cases for training and 20 cases for internal validation.Our data preprocessing consists of three steps. Initially, we standardized all the scans by ZNormalization with mean of 0 and std of 1. Following that, we used a patch-training technique inspired by NIFTYNET12. The third step involves data augmentation. We employed efficient and fast algorithms, including random affine and flipping for spatial augmentation, random gamma adjustment, random blurring and random bias for intensity augmentation.
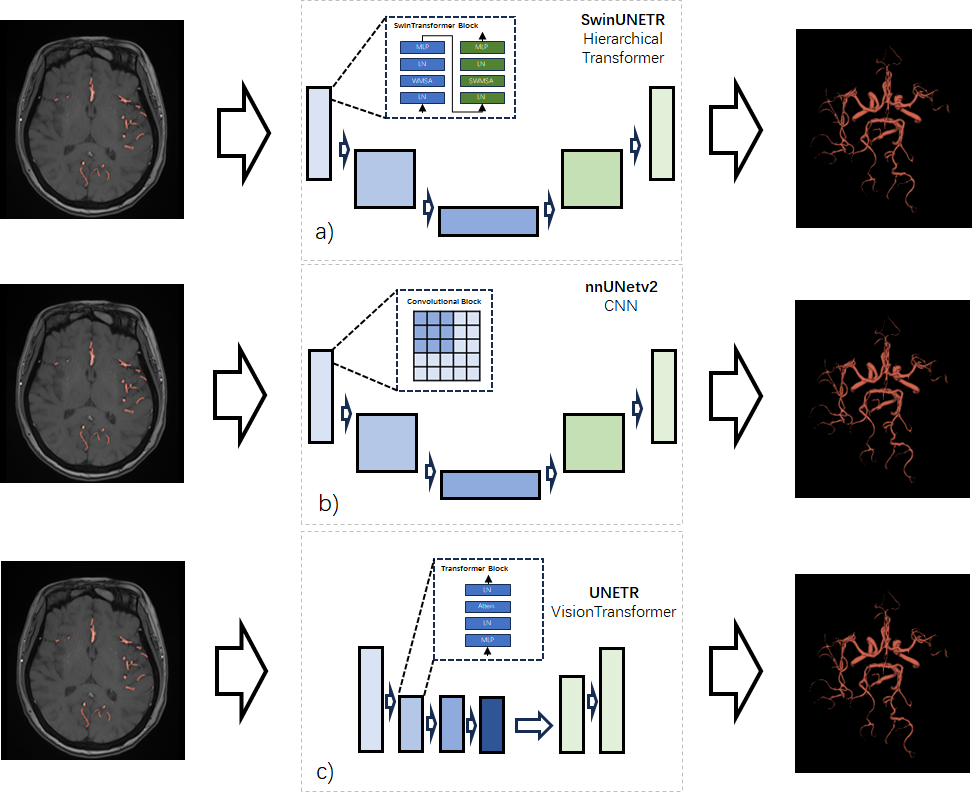
We trained three different types of networks – SwinUNETR, nnUNetv2, and UNETR, as depicted in Figure 1, in order to compare their performance. We adjusted our CrossEntropy loss by excluding the contribution of background voxels with prediction scores greater than 0.9, indicating that those voxels were well-trained. As a result, the model began to focus more on the challenging examples, specifically the foreground. This adjustment in the loss function ultimately led to increased sensitivity in the model's predictions.
Results
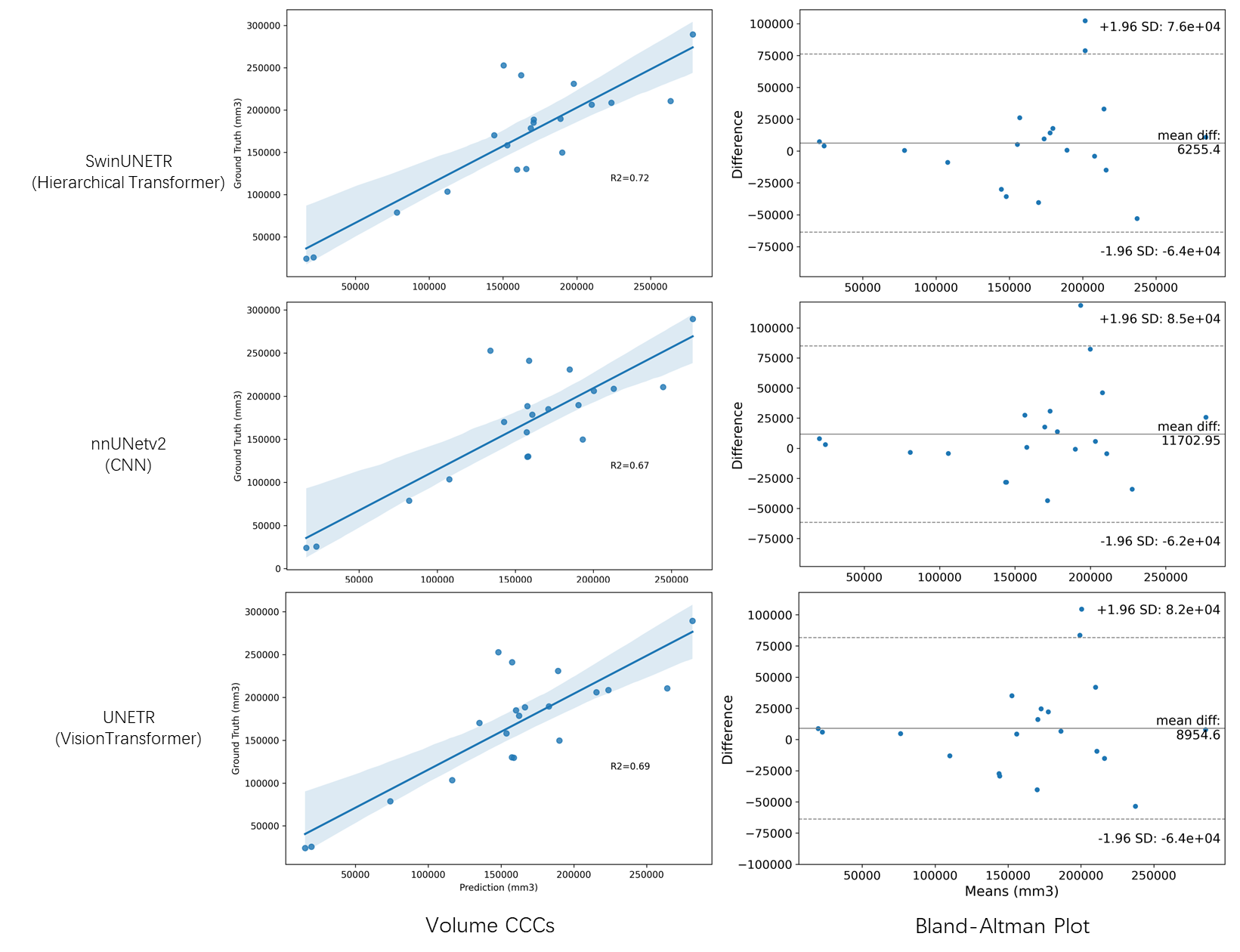
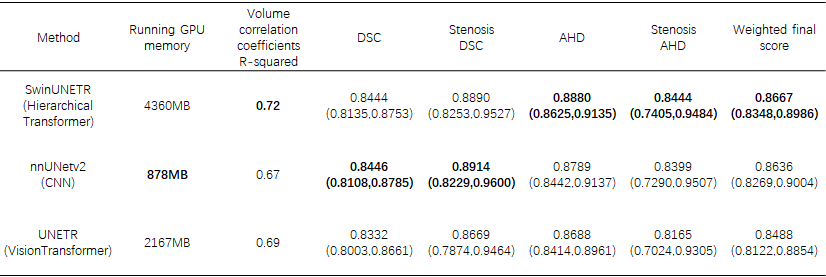
We employed an evaluation methodology that incorporated a weighted final score from the CAS2023 challenge. The majority of the validation data consisted of stenosis cases. In the validation set, for nnUNetv2, UNETR, and SwinUNETR, as depicted in Table 1, the Dice Similarity Coefficients (DSC) were 0.8446, 0.8332, and 0.8444, respectively. The DSC values for stenosis were 0.8914, 0.8669, and 0.8890, while the normalized Average Hausdorff Distances (AHD) were 0.8688, 0.8789, and 0.8880, with stenosis-specific AHD values of 0.8399, 0.8165, and 0.8444. The weighted final score was computed as 35% × DSC + 35% × AHD + 15% × DSC_stenosis + 15% × AHD_stenosis. SwinUNETR achieved a final score of 0.8667, slightly surpassing nnUNetv2 with a score of 0.8636 and UNETR with a score of 0.8488. Regarding the vessel volume coefficients, as shown in Figure 2, the R-squared values were 0.72 for SwinUNETR, 0.69 for UNETR, and 0.67 for nnUNetv2. However, in terms of computational efficiency, SwinUNETR demanded 4360MB of GPU memory during execution, which was greater than UNETR's 2167MB and nnUNetv2's 878MB. Inference time per patch was 0.027s for SwinUNETR, 0.012s for UNETR, and 0.001s for nnUNetv2.Discussion & Conclusion
In analyzing the weighted score of DSC, it becomes evident that Swintransformer, as a hierarchical transformer, can be trained effectively with a limited volume of 3D cerebral artery data and still achieve a voxel overlap performance comparable to that of convolutional networks. The AHD results further indicate that SwinUNETR's predictions exhibit greater stability when compared to CNNs. Moreover, when it comes to volumetric assessment, the transformers offer a more robust predictions compared to CNNs. Even though the transformer requires more computational resources, it has been proven to be superior to CNN on numerous large datasets. Additionally, the transformer possesses the capability for cross-modal learning. Therefore, based on our experimental results, the transformer has the potential to replace CNN networks in various scenarios for 3D medical imaging including vessel segmentation.Acknowledgements
No acknowledgement found.References
1. Chen H, Pan Y, Zong L, Jing J, Meng X, Xu Y, Yan H, Zhao X, Liu L, Li H, Johnston SC, Wang Y, Wang Y. Cerebral small vessel disease or intracranial large vessel atherosclerosis may carry different risk for future strokes. Stroke Vasc Neurol. 2020 Jun;5(2):128-137. doi: 10.1136/svn-2019-000305. Epub 2020 Apr 15. PMID: 32606085; PMCID: PMC7337361.
2. Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing, 2015.
3. Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211.
4. K. Han et al., "A Survey on Vision Transformer," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 87-110, 1 Jan. 2023, doi: 10.1109/TPAMI.2022.3152247.
5. Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
6. Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
7. Nawrot, Piotr, et al. "Hierarchical transformers are more efficient language models." arXiv preprint arXiv:2110.13711 (2021).
8. Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
9. Bojesomo, Alabi, Hasan Al Marzouqi, and Panos Liatsis. "SwinUNet3D--A Hierarchical Architecture for Deep Traffic Prediction using Shifted Window Transformers." arXiv preprint arXiv:2201.06390 (2022).
10. He, Yufan, et al. "SwinUNETR-V2: Stronger Swin Transformers with Stagewise Convolutions for 3D Medical Image Segmentation." International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland, 2023.
11. Chen, Huijun, Zhao, Xihai, et al. (2023). Cerebral artery segmentation Challenge, doi:10.5281/zenodo.7839970
12. Gibson, E., Li, W., Sudre, C., Fidon, L., Shakir, D. I., Wang, G., ... & Vercauteren, T. (2018). NiftyNet: a deep-learning platform for medical imaging. Computer methods and programs in biomedicine, 158, 113-122.
Figures