1953
Intracranial Large Vessel Severe Stenosis and Occlusion Detection Based on Vision Transformer Fusion Model from Multi-parametric MRI1Institute of Research and Clinical Innovations, Neusoft Medical Systems Co., Ltd, BeiJing, China, 2Institute of Research and Clinical Innovations, Neusoft Medical Systems Co., Ltd, Shanghai, China, 3Radiology, Tongji Hospital, Tongji Medical College, Huazhong University of Science and Technology, WuHan, China
Synopsis
Keywords: Diagnosis/Prediction, Stroke
Motivation: Traditionally, large vessel severe stenosis and occlusion (LVSSO) detection based on CTA needs contrast agent exposure. It is important to develop a LVSSO detection approach using contrast agent-free MR images that can achieve results comparable to clinical doctors.
Goal(s): To develop a new fusion algorithm that can achieve the accuracy comparable to clinical diagnostic levels.
Approach: A new fusion algorithm model based on vision transformer was developed. A total of 380 patients were enrolled in the current study.
Results: The proposed model achieved an AUC of 0.963 and an accuracy of 94.7%.
Impact: The proposed model achieved satisfactory accuracy for LVSSO detection, i.e. 94.7%, indicating that the performance of the proposed model has reached the clinical diagnosis level.
Introduction
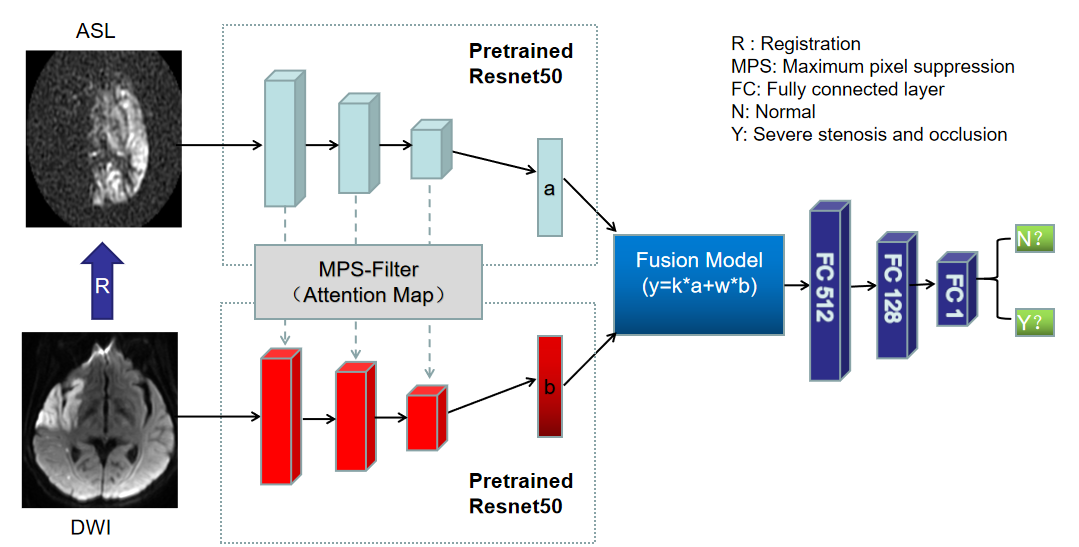
In previous work1, a deep learning Model (Figure1) that combines ASL and DWI to detect large vessel severe stenosis and occlusion(LVSSO) was proposed. Compared with CTA, it avoids the hazards of contrast agents and ionizing radiation exposure, but the accuracy, sensitivity, and specificity are not comparable to the diagnostic performance based on CTA, and, therefore, there is still room for improvement. While the transformer model2 has been widely used in medical image recognition and diagnosis, most of them are used as feature extractors to achieve tasks such as segmentation and detection of medical images3,4. In this study, we develop a new fusion model based on vision transformer (ViT)5 to fuse the features extracted from the two modalities, reaching the diagnostic level of clinicians.Materials and methods
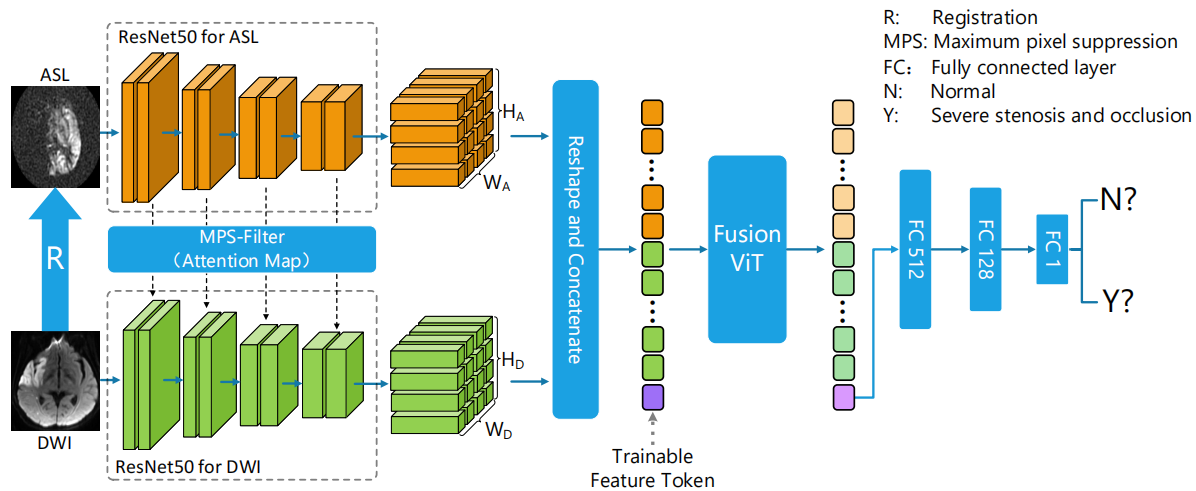
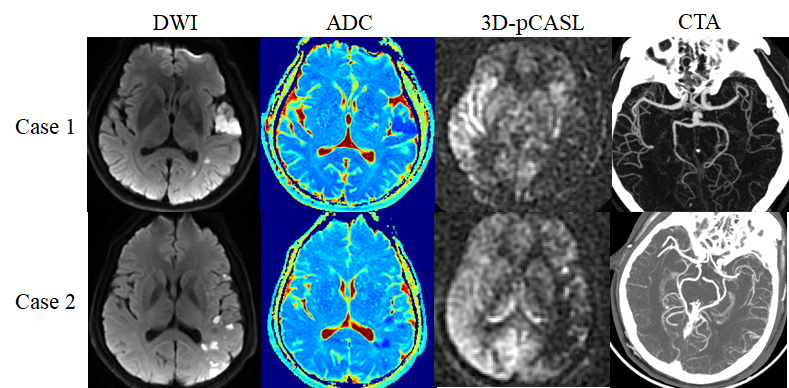
Data acquisition: Three hundred and eighty patients (256 males, 67.4%; mean age: 55 years) who were suspected of ischemic stroke and acquired routine DWI, ASL, time-of-flight MR angiography (TOF-MRA) and CTA scans were included in this study. All images were field-corrected and DWI (ADC) was registered to ASL. Clinical data analysis: Percent stenosis of large intracranial vessels was measured on CTA and TOF-MRA using WASID method6. The diameter of the intracranial internal carotid artery (ICA) and the M1 segment of the middle cerebral artery (MCA) reducing by more than 70% is considered severe stenosis. Occlusion is defined as 100% stenosis of the intracranial ICA or M1/M2 segment of MCA. Deep learning model construction: The model is mainly divided into four modules (Figure 2): 1. Data preprocessing module: The experimental data is divided into train set (80%) and test set (20%). 2. Feature extraction module: the pretrained resnet507 was used to extract deep features and adds an attention suppression module8 in the middle to make the interaction between the two groups of features better integrated. 3. ViT fusion module: The two feature vectors obtained after feature extraction are respectively extracted 4*4 (ASL map) patch and 8*8 patch (DWI or ADC map). ViT fusion model calculates the similarity of those patches through the multi-head attention mechanism1,3. Finally, a trainable token is used as the output feature map. 4. Result prediction: Feature maps were finally compressed to one-dimensional number through the fully-connected layer9, which was a probability ranged from 0 to 1. The output was assigned either 0 (less than threshold) or 1 (greater than or equal to threshold) with a preset threshold of 0.5.Result
The proposed method based on the ViT fusion model outperformed the approach based on the concatenated fusion model, achieving consistently higher AUC, accuracy, sensitivity, and specificity for the ViT fusion model than the concatenated fusion model regardless of the kind of data combinations employed (see Tables 1&2). Further comparisons of the model performance between two types of data combinations showed that the fusion of ASL and DWI images was more capable of detecting LVSSO than the fusion of ASL and ADC images (see Tables 1&2).Disussion
In this study, a deep learning approach for detecting LVSSO has been proposed, in which a ViT fusion module has been employed for achieving more accurate results. The yielded results have demonstrated that the employment of the ViT fusion model has greatly improved the performance comparing to the approach based on the concatenated fusion model. The outperformance of the proposed approach may be attributed to the fact that the ViT model divides the feature vector into multiple patches and calculates the similarity score between the features of each patch, where a higher score means that the patch feature is more important to the result and is retained to the corresponding proportion; however, the concatenated fusion method is to concatenate two feature vectors directly in the feature dimension, which does not make further feature reorganization of the two feature vectors, so there is much redundant information upon direct concatenation. Notably, our results have also demonstrated that the combination of ASL with DWI outperforms the combination of ASL with ADC, which is likely due to the fact that the contrast between tissues has been reduced (due to log change), according to the ADC calculation formula10. Actually, from a clinician's perspective, it is also more difficult to identify LVSSO on ADC than DWI. Importantly, it has been shown that the proposed approach is able to achieve accuracy that is comparable to the results yielded by clinical doctors based on CTA, which, therefore, provides a safer approach (i.e. no ionizing radiation exposure) for the detection of LVSSO.Acknowledgements
No acknowledgement found.References
1. Pro. Soc. Mag. Reson. Med., 2023(31), 0702. At: Montreal, CAN
2. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
3.Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., ... & Zhou, Y. (2021). Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306.
4. Shamshad, F., Khan, S., Zamir, S. W., Khan, M. H., Hayat, M., Khan, F. S., & Fu, H. (2023). Transformers in medical imaging: A survey. Medical Image Analysis, 102802.
5.Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
6.Samuels OB, Joseph GJ, Lynn MJ, et al. A standardized method for measuring intracranial arterial stenosis. AJNR American journal of neuroradiology 2000; 21: 643-646.
7.He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
8.Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
9. Mihailescu RC. A weakly-supervised deep domain adaptation method for multi-modal sensor data. 2021 Ieee Global Conference on Artificial Intelligence and Internet of Things (Gcaiot) 2021: 45-50. DOI: 10.1109/GCAIoT53516.2021.9693050.
10. Rosenkrantz, A. B., Padhani, A. R., Chenevert, T. L., Koh, D. M., De Keyzer, F., Taouli, B., & Le Bihan, D. (2015). Body diffusion kurtosis imaging: basic principles, applications, and considerations for clinical practice. Journal of Magnetic Resonance Imaging, 42(5), 1190-1202.
Figures