1952
Breast tumor segmentation network based on local attention1Southern University of Science and Technology (SUSTech), Shenzhen, China, 2Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 3Faculty of Robot Science and Engineering, Northeastern University, Shenyang, China, 4National Cancer Center/National Clinical Research Center for Cancer/Cancer Hospital & Shenzhen Hospital, Chinese Academy of Medical Sciences and Peking Union Medical College, Shenzhen, China, 5MR Research, GE Healthcare, Beijing, China, 6Key Laboratory of Biomedical Imaging Science and System, Chinese Academy of Sciences, Shenzhen, China, 7United Imaging Research Institute of Innovative Medical Equipment, Shenzhen, China
Synopsis
Keywords: Analysis/Processing, Cancer, Breast
Motivation: Accurate segmentation of the lesion region is the first step toward early diagnosis. The transformer, on the other hand, has very competitive performance but also extremely high computational complexity.
Goal(s): Finding an efficient and computationally inexpensive method is currently a great challenge for the application of transformers in medical image segmentation.
Approach: We adopt the shift local self-attention method to extract features, which reduces the computational complexity while obtaining very high segmentation accuracy.
Results: Experimental results on a dataset comprising 130 breast tumor cases demonstrate that the proposed network accurately segments breast tumors, surpassing the accuracy of many other convolution-based or transformer-based networks.
Impact: This study may inspire scientists to create simpler, efficient components for reduced self-attention computational cost while preserving long-range modeling. The achievement in high-precision segmentation can ease clinicians' workload by reducing image annotation.
Introduction
DCE-MRI is currently the best choice for clinical breast diagnosis. Due to abnormal vascular perfusion within the lesion area, DCE-MRI exhibits significantly high contrast between diseased and normal tissue. This technology provides strong support for accurate diagnosis and early detection of breast tumors[1]. Segmentation remains a challenging initial step in clinical diagnosis. On the one hand, tumor sizes usually exhibit different shapes. On the other hand, tumor sizes may vary significantly from case to case[2]. In addition, issues such as noise, artifacts and data imbalance pose significant challenges in the field of medical image segmentation. DCE-MRI segmentation tasks usually utilize self-attention or convolution-based methods to segment enhanced images.Convolution networks struggle with contextual information capture due to limited receptive fields.Self-attention networks exhibit high complexity, with computational demands quadratically increasing with the number of image patches[3]. Therefore, we have developed a shift local self-attention approach that not only incorporates the advantages of convolution (e.g. local inductive bias and translation equivariance) but also offers the high flexibility of the transformer. The additional shift operations significantly preserve its long-range modeling capability.Methods
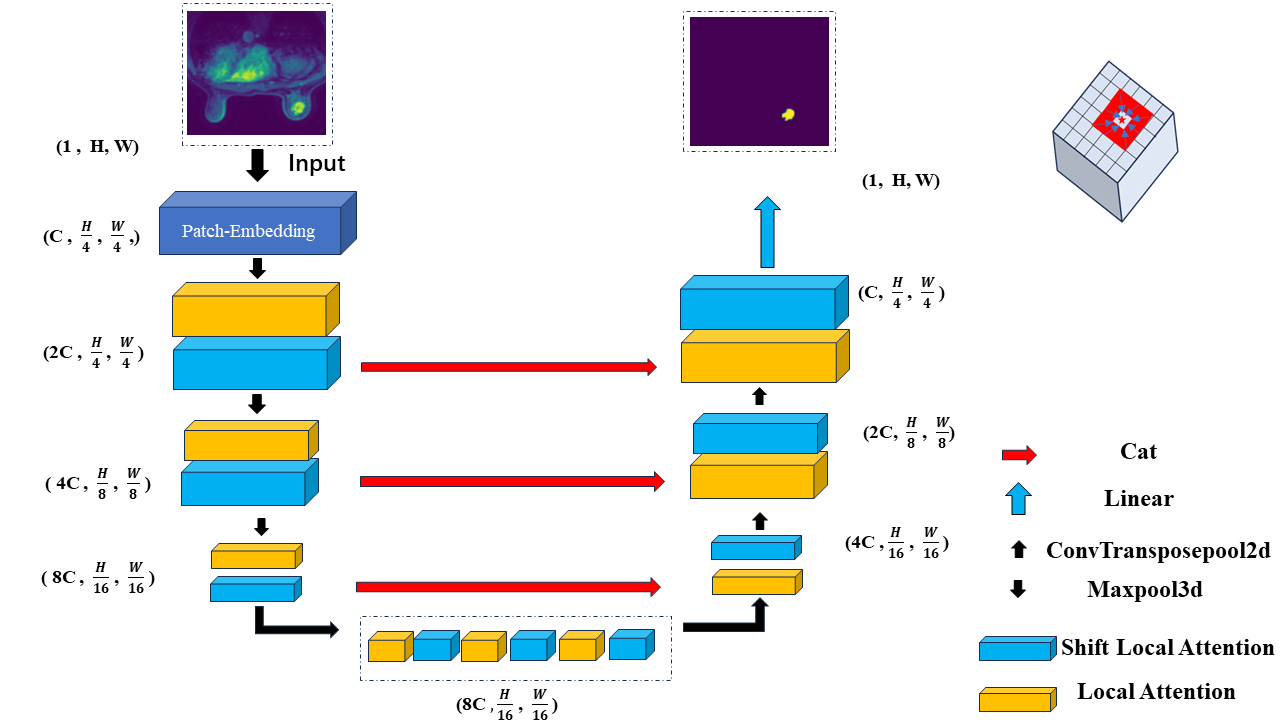
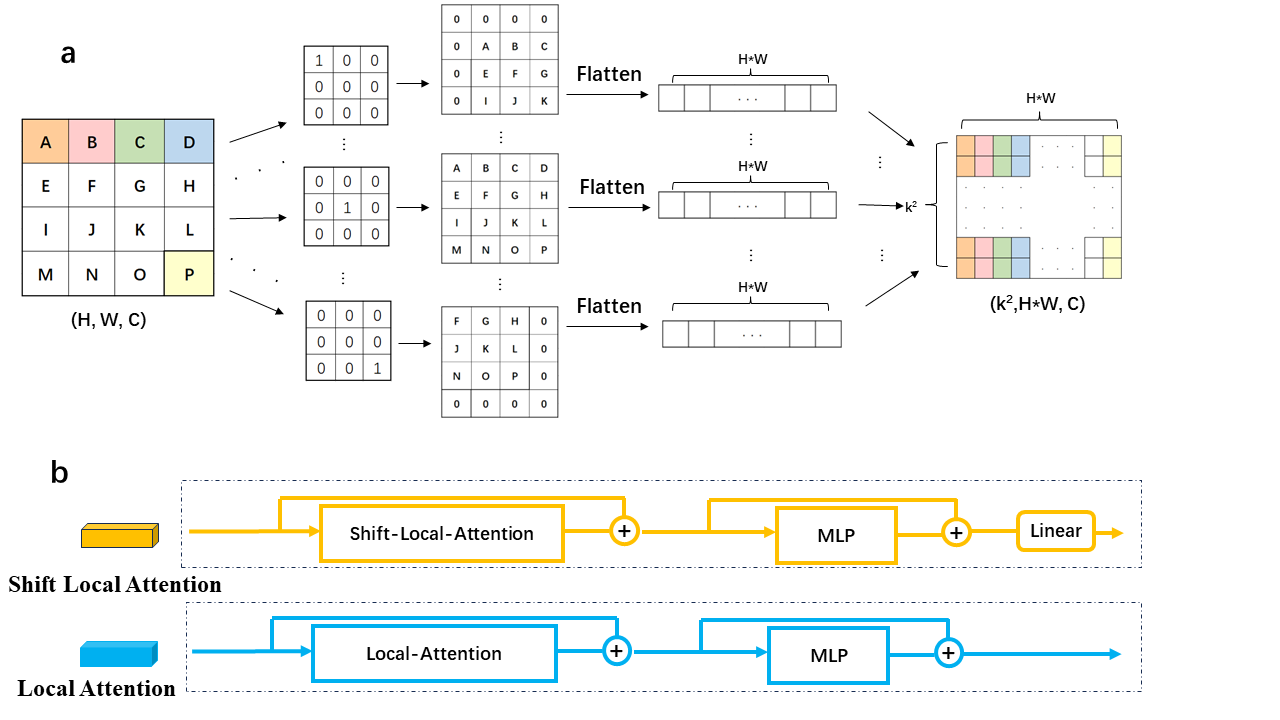
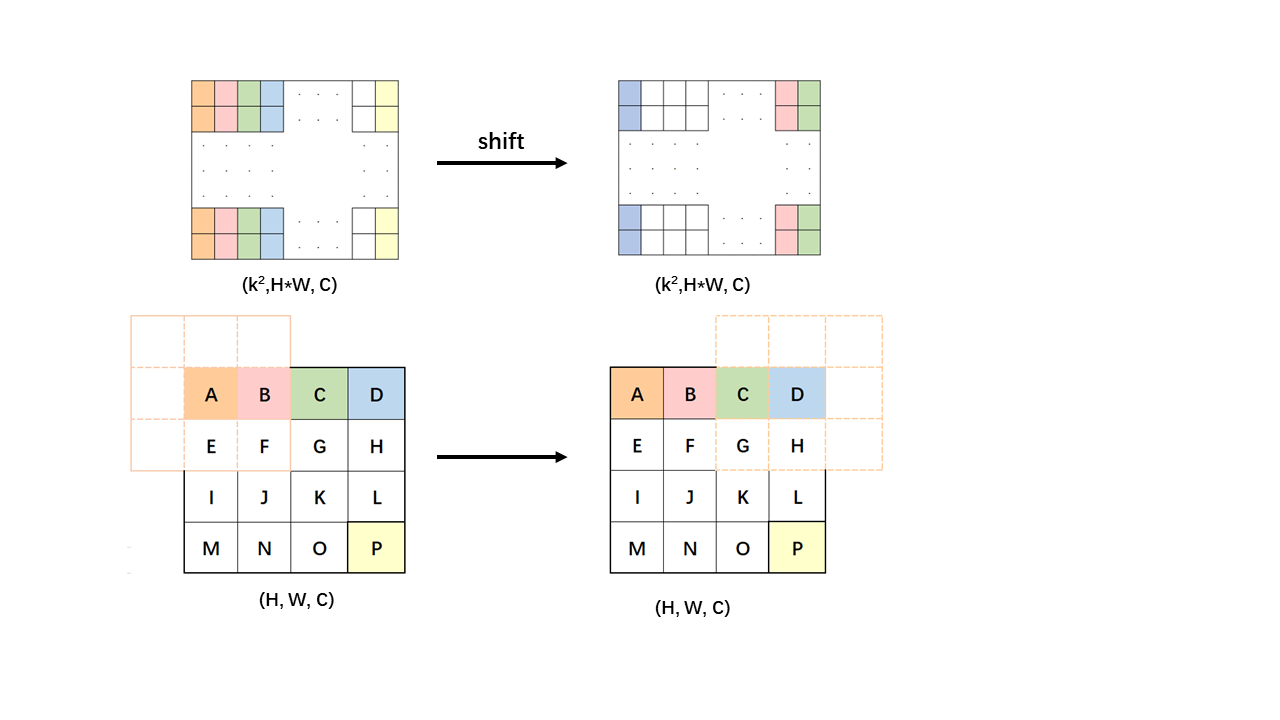
Data: In this experiment,a total of 22,440 2D slices were collected from 130 cases.The tumor annotations were performed by professional radiologists.The data were split into training and testing sets in a 7:3 ratio at the case level.Model: In this work,we utilized a backbone featuring a local self-attention mechanism,which constrains the keys and values of each query within a specific local range centered around it,as opposed to computing correlations with the entire image.The entire proposed network architecture is shown in Fig.1. Local self-attention offers the advantages of reducing computational complexity while retaining the benefits of traditional convolution,such as local inductive bias and translation equivariance[4].We efficiently obtained a local receptive field window for each patch through depthwise convolutions with fixed kernels[5] , thus improving the computational efficiency of local self-attention.Specifically, for feature maps $$$\{\mathcal{F}\}\in\chi^{H^{\prime}*W^{\prime}*\mathcal{C}}$$$ ($$$H^{\prime}$$$ and $$$W^{\prime}$$$ representing the height and width of the feature maps,respectively,and C denoting the dimension),the mappings $$$(q,k,v)\in R^{H^{\prime}*W^{\prime}*C}$$$ were obtained.For $$$(k, v)$$$, a depthwise convolution with $$$(kernel\_size * kernel\_size)$$$ fixed convolution kernels(e.g. if kernel_size=3, $$$\{W_1=\begin{bmatrix}1&0&0\\0&0&0\\0&0&0\end{bmatrix},W_2=\begin{bmatrix}0&1&0\\0&0&0\\0&0&0\end{bmatrix}\ldots,W_9=\begin{bmatrix}0&0&0\\0&0&0\\0&0&1\end{bmatrix}\}$$$was employed for convolution calculations, as indicated in Equation (1,2). The resulting outputs $$$\{(K_i,V_i)\text{,i=1,2,...,kernel_size}^2\}$$$ were flattened into rows and concatenated along the column dimension, yielding a domain matrix with dimensions of $$$(\text{kernel_size}^2,H^{\prime}*W^{\prime})$$$, denoted as $$$\{O^m,m=k,v\}$$$, which is shown in Fig.2. Each column of the matrix represents the pixels within a kernel_size * kernel_size neighborhood of each pixel in (k, v), and each row represents the pixels in different directions within each pixel in (k, v). Subsequently, matrix multiplication was performed between q and $$$O^{k}$$$, the value of which was softmaxed and then multiplied by $$$O^{v}$$$. Additionally, we introduced a shift operation for domain matrices $$$\left\{O_{n}^{m} \epsilon\left.\lambda^{(kernel\_size^2,H^{\prime}\ast W^{\prime})},\left \langle m=k,v \right \rangle,\left \langle n=1,2,...,H^{\prime}\ast W^{\prime} \right \rangle \right\}\right. $$$. As shown in Fig. 3, by shift along the dimension of pixel count, the original domain matrix $$$\{\left ( O_{n}^{k} , O_{n}^{v} \right ) ,k=1,2,...,H^{\prime}*W^{\prime}\}$$$ that performs the attention computation with$$$ q_n $$$will be changed to a domain matrix $$$\left ( O_{n\pm shift\_size}^{k} , O_{n\pm shift\_size}^{v} \right ) $$$ with the same shift distance $$$q_{n\pm shift\_size}$$$ in the same shift direction. This method enhances long-range modeling capabilities that are partially lost due to local computation. The corresponding calculation changes from Equation (3) to Equation (4).
$$K_i=W_i\otimes k~~~~~~~~~~~~~~~~~~~ i=1,2,...,\mathrm{kernel}\_{\mathrm{size}}^2 ~~~~\left ( 1 \right )$$
$$V_i=W_i\otimes v~~~~~~~~~~~~~~~~~~~ i=1,2,...,\mathrm{kernel}\_{\mathrm{size}}^2 ~~~~\left ( 2 \right )$$
$$Attention(Q,K,V)=softmax\left(\frac{q_{n}\cdot {O_{n}^{k}}^{T}}{\sqrt{d_{k}}}\right)O_{n}^{v} ~~~~~~n=1,2,...,H^{\prime}*W^{\prime}~~~~\left ( 3 \right ) $$
$$Attention(Q,K,V)=softmax\left(\frac{q_{n}\cdot {O_{n\pm shift\_size}^{k}}^{T}}{\sqrt{d_{k}}}\right)O_{n\pm shift\_size}^{v}~~~~~~ n=1,2,...,H^{\prime}*W^{\prime}~~~~~~~\left ( 4 \right ) $$
Results
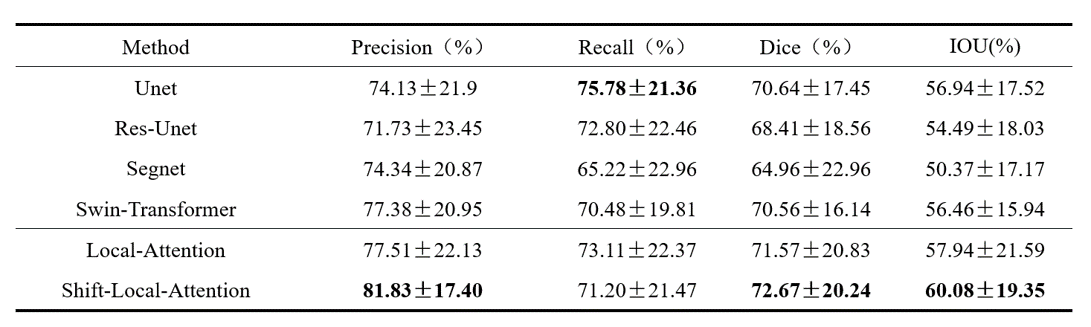
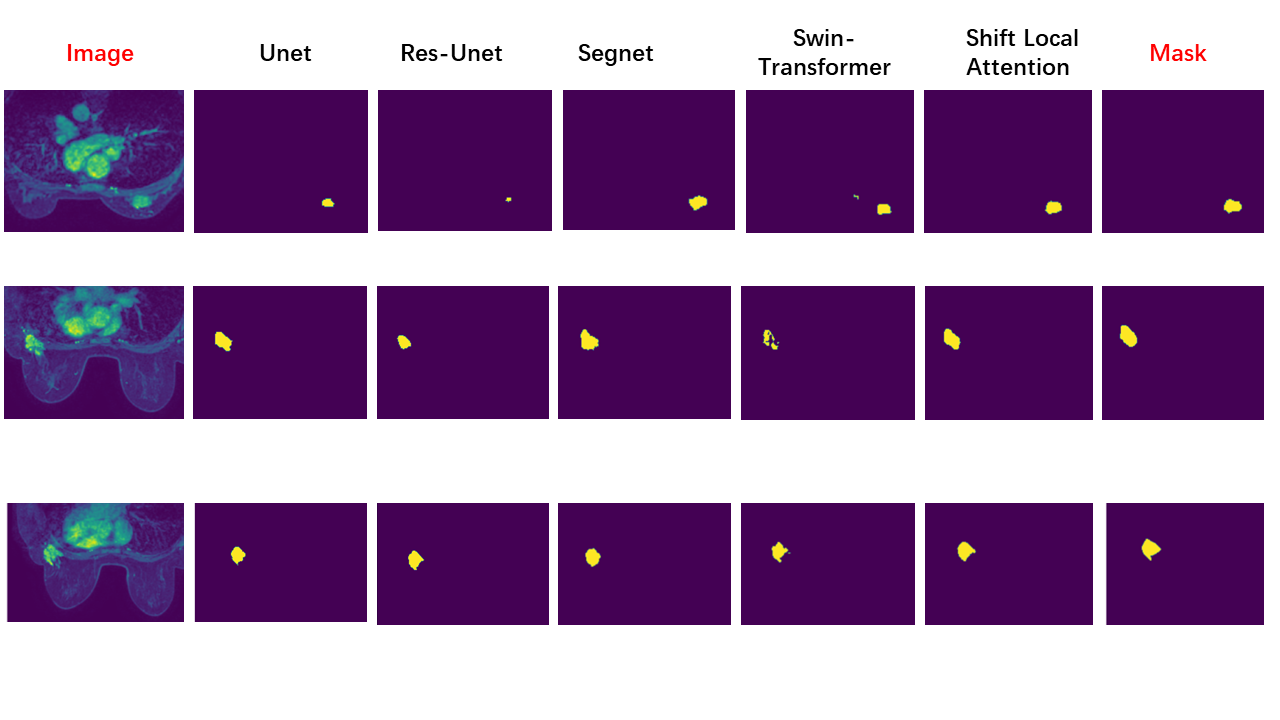
We use Precision, Recall, DICE, and IOU as evaluation metrics and calculate the average and standard deviation of these metrics across all cases. The results of the calculations are presented in Fig. 4. Fig. 5 shows examples obtained from different algorithmic segmentation networks that outperform the majority of networks. Performance evaluations and graphical visualizations indicate that our approach is optimal.Dicussion
Tregardless of whether the shift operation is used, the local attention method tends to have a higher precision compared to other models and a lower recall, indicating a bias toward predicting false negatives while reducing false positives. This may be due to the 4x upsampling in the final layer. However, in terms of the overall results, our method still achieves a high degree of accurate segmentation,outperforms the majority of networksConclusion
In this work, we propose a local attention-based segmentation network for breast tumor DCE-MRI, incorporating a novel shift operation, which performs well in various performance evaluations.Acknowledgements
The study was partially supported by the Natural Science Foundation of Guangdong Province-Outstanding Youth Project (2023B1515020002), National Key Technology Research and Development Program of China (2021YFF0501502), Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2023B1212060052), and Central Guidance for Local Science and Technology Development Project (ZYYD2023D02).
References
[1].Cheng Q, Huang J, Liang J, et al. The diagnostic performance of DCE-MRI in evaluating the pathological response to neoadjuvant chemotherapy in breast cancer: a meta-analysis[J]. Frontiers in Oncology, 2020, 10: 93.
[2].Zhang Y, Chen J H, Lin Y, et al. Prediction of breast cancer molecular subtypes on DCE-MRI using convolutional neural network with transfer learning between two centers[J]. European radiology, 2021, 31: 2559-2567.
[3].Yuan F, Zhang Z, Fang Z. An effective CNN and Transformer complementary network for medical image segmentation[J]. Pattern Recognition, 2023, 136: 109228.
[4]. Vaswani A, Ramachandran P, Srinivas A, et al. Scaling local self-attention for parameter efficient visual backbones[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12894-12904.
[5]. Pan X, Ye T, Xia Z, et al. Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 2082-2091.
Figures