1950
Self-Supervised Pre-Training Based Hybrid Network for Deep Gray Matter Nuclei Segmentation1Department of Electronic Science, Xiamen University, Xiamen, China, 2Institute of Artificial Intelligence,Xiamen University, Xiamen, China
Synopsis
Keywords: Analysis/Processing, Segmentation
Motivation: Vision Transformers (ViTs) have the potentiality to outperform convolutional neural networks (CNNs) in the task of deep gray matter nuclei segmentation. However, Transformer-based models require large labeled datasets for training.
Goal(s): Our goal is to design a Transformer-based model and alleviate the model's dependence on labeled data.
Approach: We present a CNN-Transformer hybrid Network (CTNet) for deep gray matter nuclei segmentation. Moreover, a novel self-supervised pre-training approach that combines rotation prediction and masked feature reconstruction is proposed to pre-train the CTNet.
Results: Our method achieves better performance than other comparison models on human brain MRI datasets.
Impact: This is the first study that utilizes self-supervised learning methods for deep gray matter nuclei segmentation. Our method can achieve outstanding segmentation performance and effectively assist clinical doctors in the diagnosis and treatment of neurodegenerative diseases.
Introduction
For the task of deep gray matter nuclei segmentation, existing methods1,2,3,4 are variant UNets5 based on convolutional neural network (CNN). Due to the difficulty of building an explicit long-distance dependence with CNN, the performance of these methods is suboptimal. Vision Transformers (ViTs)6 utilize self-attention mechanism to model global information. However, Transformer-based models require a large amount of labeled data for training, which is challenging and time-consuming to obtain for medical image analysis. Therefore, we attempt to tackle this challenge by employing self-supervised learning (SSL). SSL7,8 has achieved remarkable success in alleviating the issue of insufficient data annotation through two-stage training (i.e., pre-training and fine-tuning).Methods
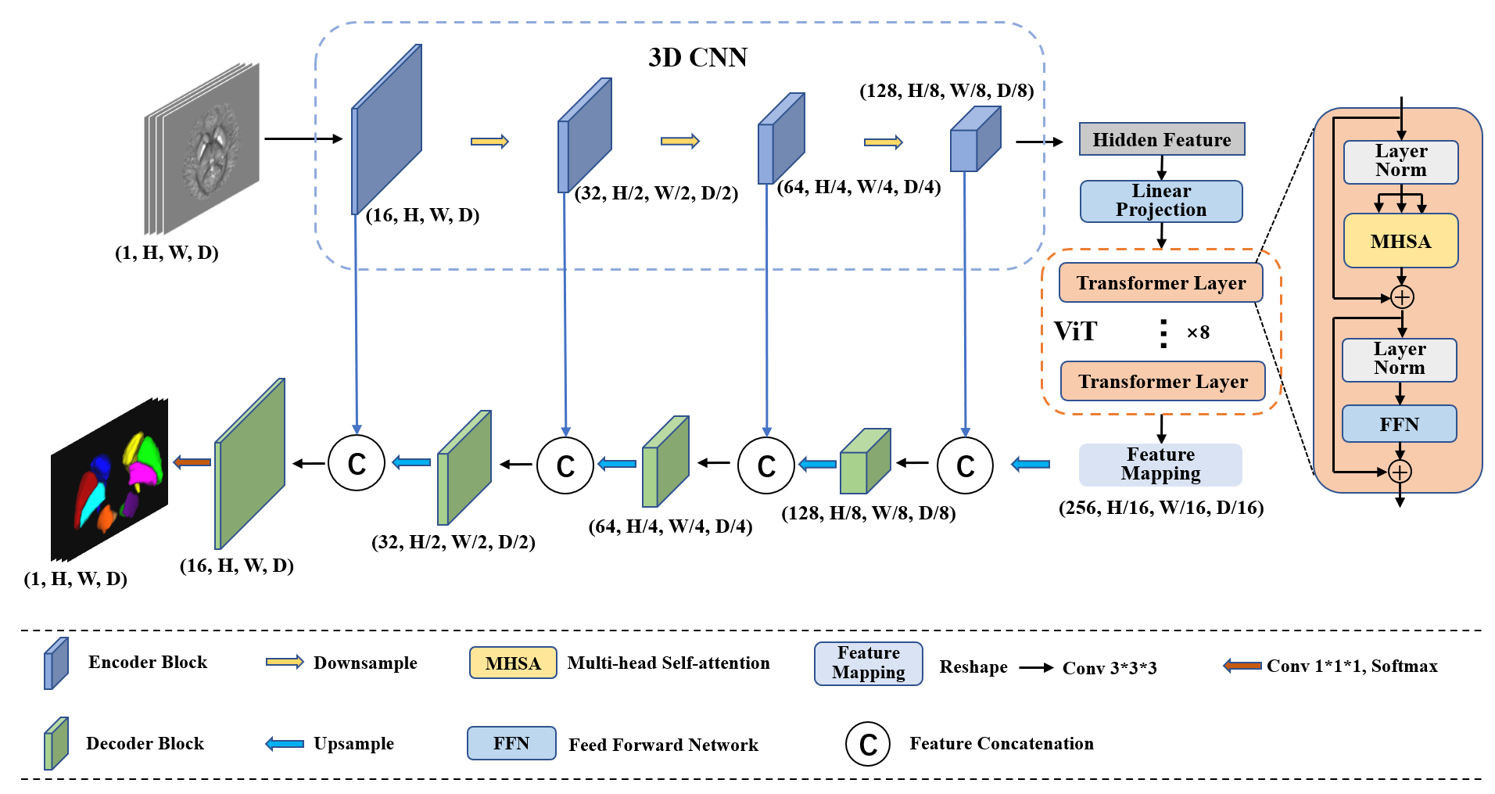
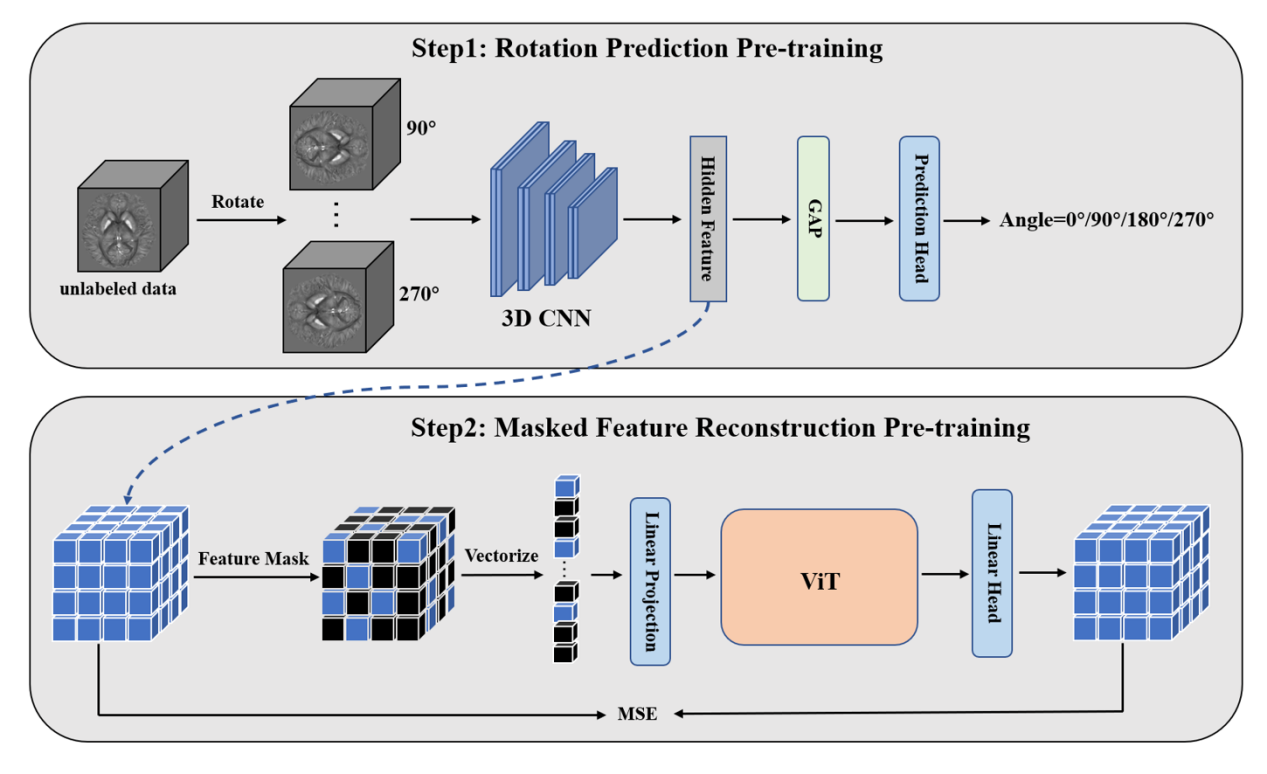
In this work, we present a CNN-Transformer hybrid Network (CTNet) for deep gray matter nuclei segmentation. An overview of CTNet is shown in Figure 1. Its encoder consists of 3D CNN and ViT, which effectively combines the strengths of CNN and Transformer to extract collaborative local and global feature representations. Furthermore, we propose a novel self-supervised learning approach for CTNet, and its pre-training stage is divided into two steps. The pre-training framework is illustrated in Figure 2. In step1, the 3D CNN is pre-trained by predicting the rotation angles of input images, capturing the semantic information of objects in the images. The learned hidden features are passed to the ViT. In step2, we apply masking to the hidden features, allowing ViT to be pre-trained by reconstructing the masked features. In the fine-tuning stage, we employ CTNet as the segmentation model and initialize its encoder with the weights obtained from the pre-trained 3D CNN and ViT. The decoder is randomly initialized. Afterwards, the model is fine-tuned using labeled data.Results
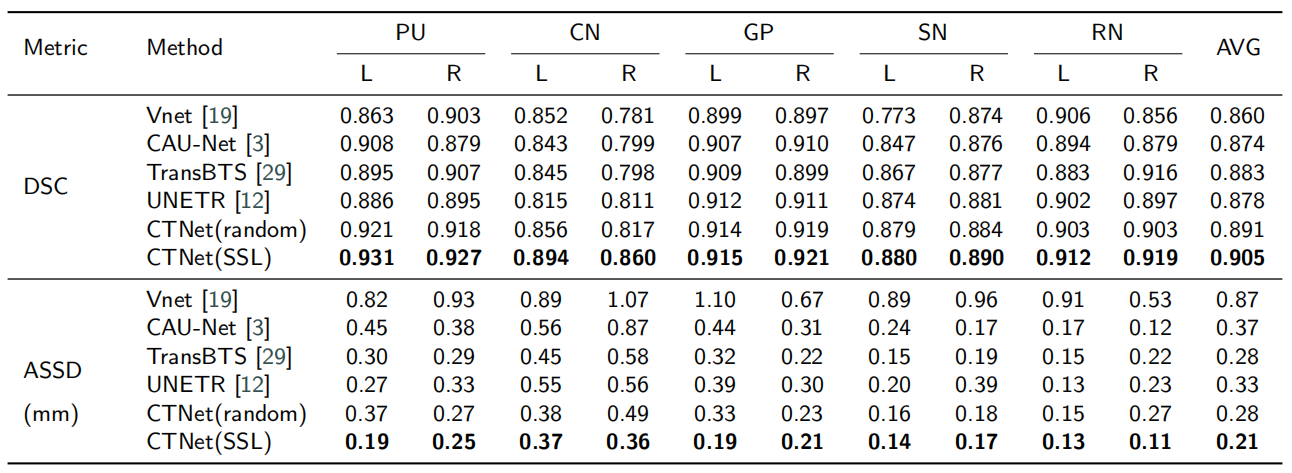
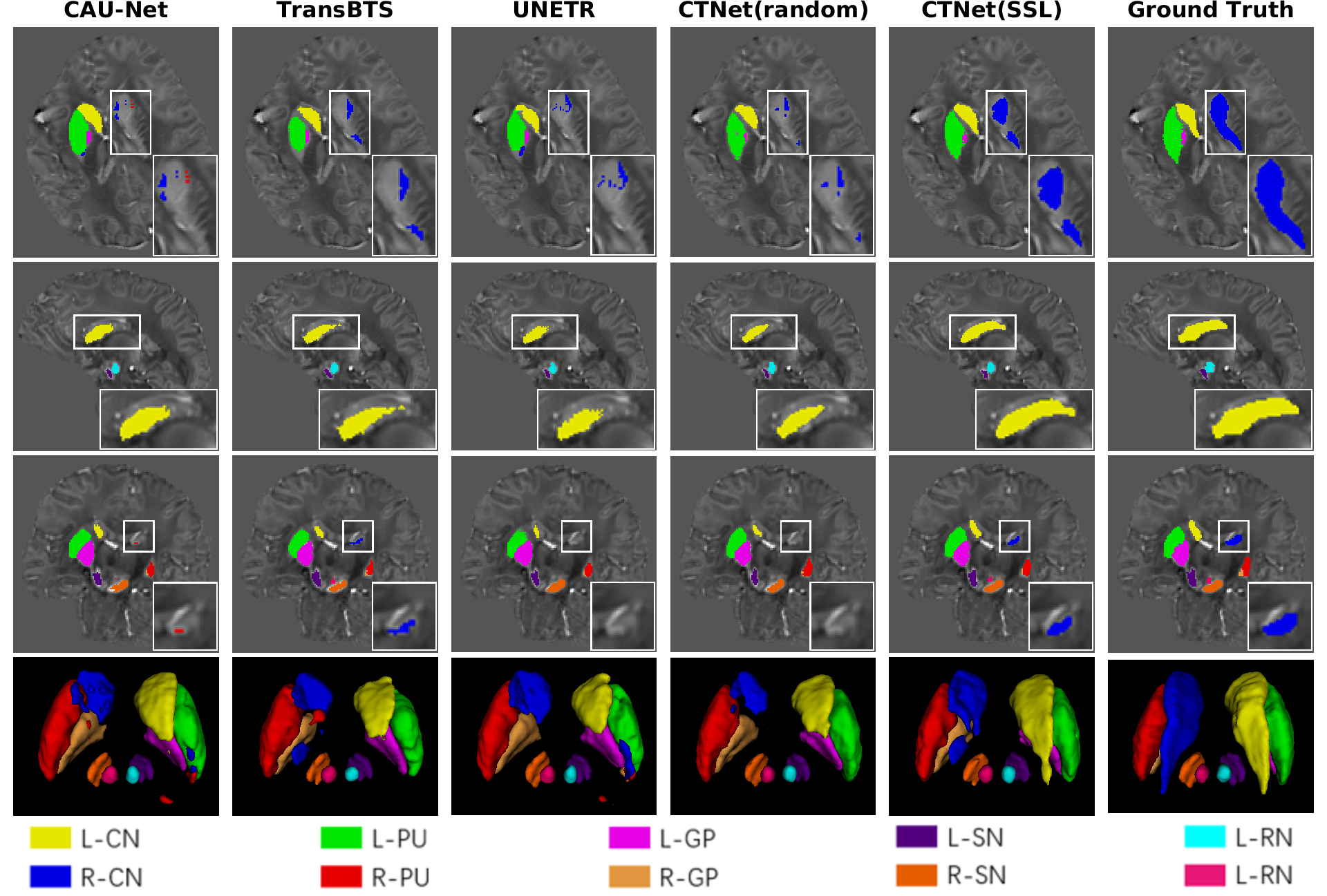
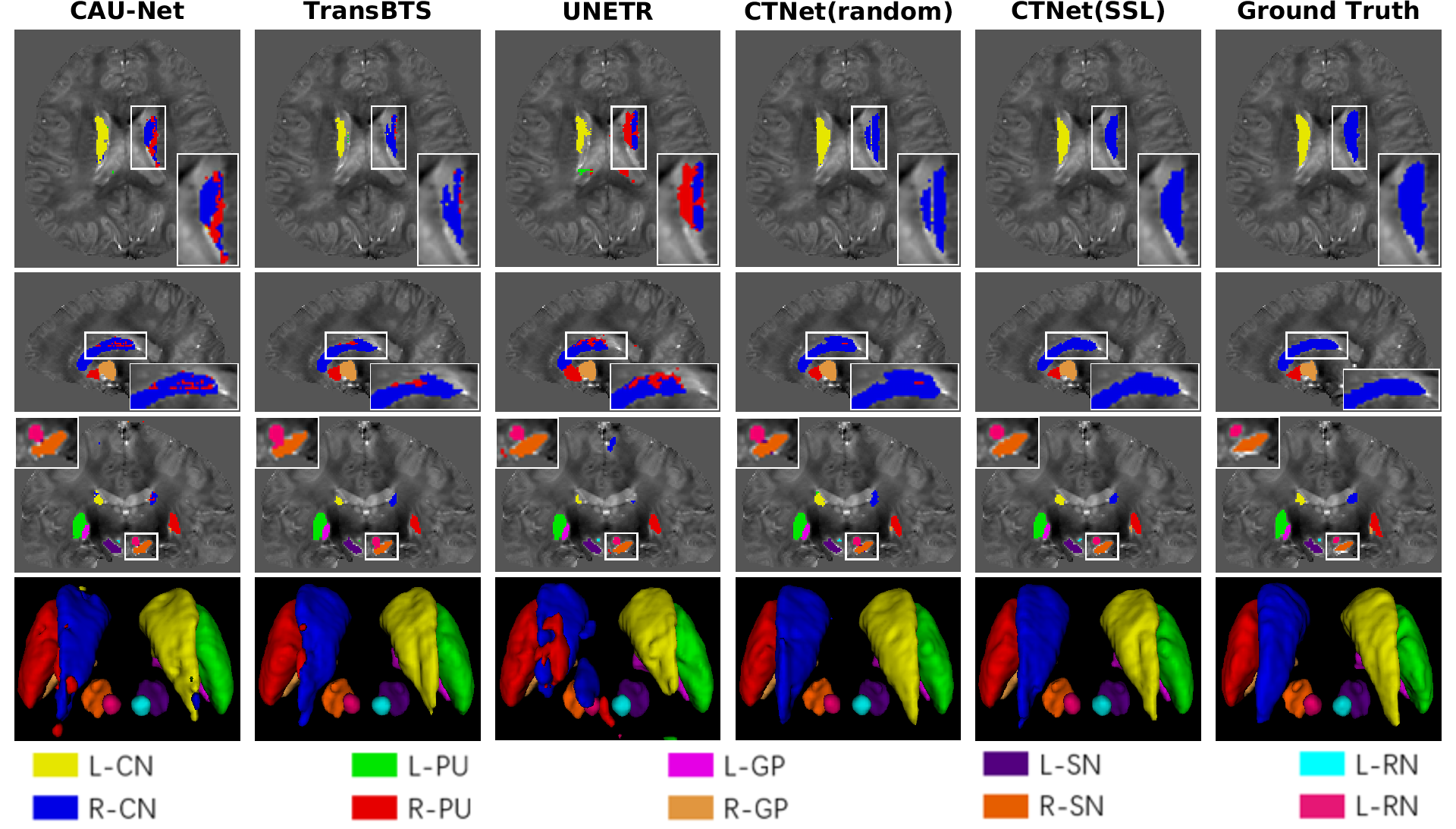
Multi-orientation Gradient-echo MRI Dataset9 contains the susceptibility maps and the labeled maps of deep gray matter nuclei. The susceptibility maps are used to pre-train our proposed CTNet. Deep gray matter nuclei include putamen (PU), globus pallidus (GP), caudate nucleus (CN), red nucleus (RN), and substantia nigra (SN). Each nucleus has two parts, left and right. Experts optimized 52 labeled maps as the segmentation labels (3T Dataset) for fine-tuning.We apply Vnet10, CAU-Net3, TransBTS11 and UNETR12 as comparison models. From Table 1, it can be observed that our method CTNet(SSL) achieves better segmentation performance than other models on the 3T Dataset, with an average dice similarity coefficient (DSC) of 0.905 and an average symmetric surface distance (ASSD) of 0.21mm. We conduct a comparison of CTNet under two training settings: randomly initialized CTNet(random) and pre-trained using our self-supervised learning CTNet(SSL). Our pre-training method significantly improves the segmentation performance of CTNet, resulting in a 1.4% increase in DSC. Especially, it leads to 3.8% and 4.3% increase in DSC for L-CN and R-CN, respectively. It is easily noted from the first and third rows of Figure 3 that other methods produce a large number of missing segmentation regions for R-CN. But our method is able to successfully segment these regions. By comparing the fourth and fifth columns, we can see that the pre-trained CTNet significantly outperforms the randomly initialized CTNet, which fully validates the effectiveness of our pre-training method.
Our brain data was collected from 10 healthy volunteers in a 7T Philips MRI scanner. The segmentation labels were annotated and cross-validated by two experienced experts using ITK-SNAP13 (7T Dataset). We use the 3T dataset to train the model and test on the 7T dataset. The visualization segmentation results of different methods are shown in Figure 4. From the first and second rows, we can see that CAU-Net and UNETR misclassify many regions of R-CN as R-PU. The segmentation results in the third row show that the background region between R-RN and R-SN is misclassified as R-RN by other methods. Our method can address the above-mentioned issues.
Conclusion and Discussion
In this work, we present a CNN-Transformer hybrid Network (CTNet) for deep gray matter nuclei segmentation. It effectively combines the advantages of both CNN and Transformer. To address the issue of insufficient annotated data, we design a novel self-supervised learning method for CTNet, whose pre-training stage includes two steps: rotation prediction pre-training and masked feature reconstruction pre-training. This work is the first study that utilizes self-supervised learning method for deep gray matter nuclei segmentation. It can achieve excellent segmentation even when the labeled data is insufficient. The experimental results on human brain MRI datasets demonstrate the superiority of our method.Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant 62071405.References
- Chai C, Qiao P, Zhao B, et al. Brain gray matter nuclei segmentation on quantitative susceptibility mapping using dual-branch convolutional neural network. Artificial Intelligence in Medicine. 2022;125: 102255.
- Chai C, Wu M, Wang H, et al. CAU-Net: A deep learning method for deep gray matter nuclei segmentation. Frontiers in Neuroscience. 2022;16: 918623.
- Guan Y, Guan X, Xu J, et al. DeepQSMSeg: a deep learning-based sub-cortical nucleus segmentation tool for quantitative susceptibility mapping. 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). IEEE, 2021: 3676-3679.
- Wu M, Zhao B, Chai C, et al. Reverse Attention U-Net for Brain Grey Matter Nuclei Segmentation. Artificial Intelligence in China: Proceedings of the 3rd International Conference on Artificial Intelligence in China. 2022: 55-62.
- Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Part III 18. 2015: 234-241.
- Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Taleb A, Loetzsch W, Danz N, et al. 3d self-supervised methods for medical imaging. Advances in Neural Information Processing Systems. 2020; 33: 18158-18172.
- Tian Y, Xie L, Wang Z, et al. Integrally Pre-Trained Transformer Pyramid Networks. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 18610-18620.
- Shi Y, Feng R, Li Z, et al. Towards in vivo ground truth susceptibility for single-orientation deep learning QSM: A multi-orientation gradient-echo MRI dataset. NeuroImage. 2022;261: 119522.
- Milletari F, Navab N, Ahmadi S A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. 2016 fourth International Conference on 3D Vision (3DV). IEEE, 2016: 565-571.
- Wang W, Chen C, Ding M, et al. TransBTS: Multimodal brain tumor segmentation using transformer. Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Part I 24. 2021: 109-119.
- Hatamizadeh A, Tang Y, Nath V, et al. UNETR: Transformers for 3d medical image segmentation. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022: 574-584.
- Yushkevich P A, Gao Y, Gerig G. ITK-SNAP: An interactive tool for semi-automatic segmentation of multi-modality biomedical images. 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2016: 3342-3345.
Figures