1877
Characterizing laryngeal dynamics during voicing and breathing with real-time multi-slice variational manifold learning1Roy J. Carver Department of Biomedical Engineering, The University of Iowa, Iowa City, IA, United States, 2Department of Otolaryngology, The University of Iowa, Iowa City, IA, United States, 3Department of Communication Sciences and Disorders, The University of Iowa, Iowa City, IA, United States, 4Department of Neurosurgery, The University of Iowa, Iowa City, IA, United States, 5Janette Ogg Voice Research Center, Shenandoah University, Winchester, VA, United States, 6Department of Electrical and Computer Engineering, The University of Iowa, Iowa City, IA, United States, 7Department of Radiology, The University of Iowa, Iowa City, IA, United States
Synopsis
Keywords: Image Reconstruction, Image Reconstruction
Motivation: Visualizing the movement of laryngeal muscles during voicing and breathing is important for understanding the mechanics of speech production.
Goal(s): The goal is to improve our understanding of speech production by visualizing gross-vocal fold movements due to laryngeal muscle contractions.
Approach: We proposed a multi-slice non-gated spiral sparse sampling strategy, and variational manifold based reconstruction scheme for dynamic laryngeal MR imaging at high spatio-temporal resolution.
Results: Our proposed method can capture gross vocal fold motions (e.g., adduction, abduction, elongation, shortening) during various voicing and breathing at both high spatial (1.5 mm2) and high temporal resolutions (36 ms/frame).
Impact: Otolaryngologists, voice and neuroscientists interested in larynx physiology and disorders pertaining to breathing and phonation.
Introduction
Speech production involves modulating the human breath through a rapid and dexterous interaction amongst various structures including a) laryngeal muscles that control the glottic configuration, and b) supraglottic structures that modulate the shape of the vocal tract, such as the soft and hard palates, tongue, jaw, and the lips. Over the past decade, several sparse sampling and constrained reconstruction methods have been applied to enable imaging the dynamics of supraglottic structures at high spatio-temporal resolutions (e.g., upto 1.5 mm2 and 10 ms/frame)1–4. In this work, we evaluate the utility of non-gated spiral sparse sampling and variational manifold regularization to visualize gross changes in glottic configuration related to activation of the intrinsic laryngeal muscles, including the thyroarytenoid, lateral cricoarytenoid, posterior cricoarytenoid, and cricothyroid. Since our goal is to visualize gross vocal-fold movements (adduction, abduction, elongation, shortening) which are affected by specific muscle contractions rather than actual vocal-fold vibrations, we target to achieve a spatio-temporal resolution of the order of 1.5 mm2/pixel and 36 ms/frame with 3 concurrent axial slice coverage.Methods
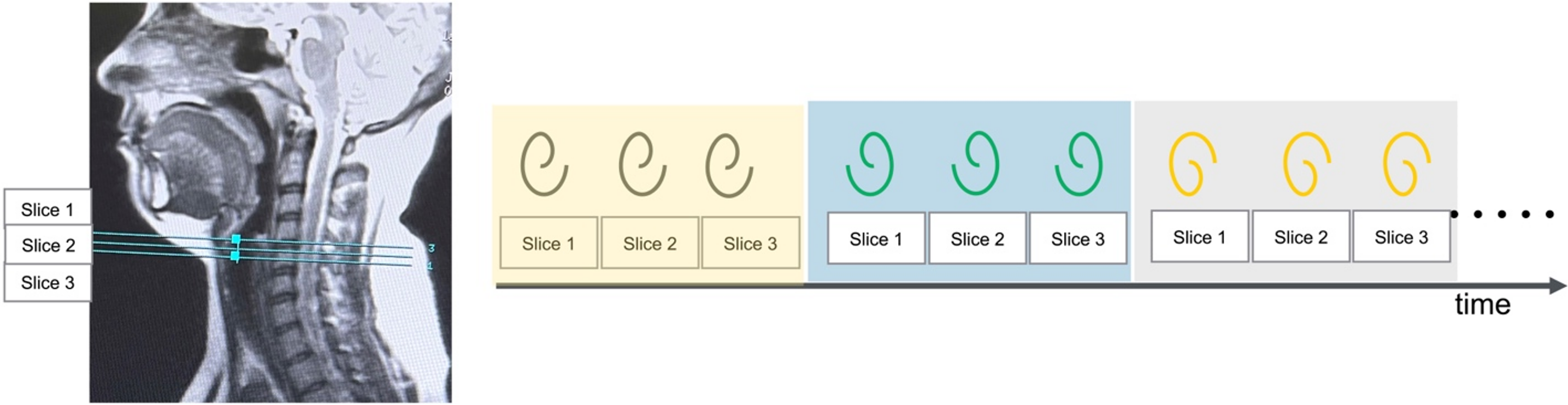
Experiments were performed on a 3T GE Premier scanner equipped with high performance gradients (80 mT/m amplitude and 150 mT/m/ms slew rate) using a 21 channel head-neck coil. A variable density spiral based gradient echo scheme with golden angle view ordering was used to concurrently acquire three 2D axial slices. A spiral arm for a specified angle was acquired for all three slices before proceeding to next angle increment (see Fig. 1). The axial slices were localized such that the mid-slice was at the mid-cross section of the vocal folds. Three slices were used to ensure capturing of the imaging plane that best visualizes vocal folds in the presence of subtle neck movements, that can occur during phonation. Sequence parameters were: FOV was 20 cm x 20 cm; spatial resolution was either 1.5 mm x 1.5 mm or 1.76 mm x 1.76 mm; flip angle: 5 degrees; TR = 6 ms; slice thickness = 6 mm; 335 readout points; readout duration = 1.3 ms. Two expert voice professional users (1:1 male-female) were imaged, where they produced a variety of breathing and voicing tasks. These tasks were designed where expected motion was rapid, or fine to respectively evaluate both our proposed high temporal resolution, and high spatial resolution. The tasks included a) breathing maneuvers at either (quiet/, deep/rapid) rates through either (nose/mouth) b) producing repeated sniffs through nose to emphasize complete vocal fold ab-/adduction; c) sustained phonation of /eee/ at low/comfortable/high pitch. Reconstructions were performed by the variational manifold regularization scheme by combining 2 spirals arms/frame (or equivalently 36 ms/frame) 5,6.Results
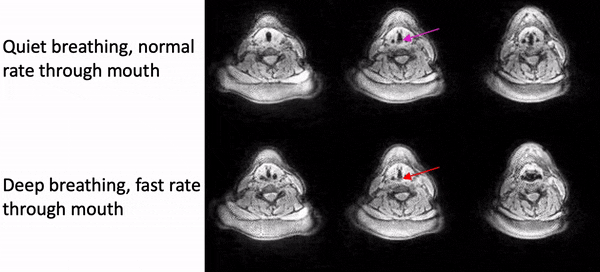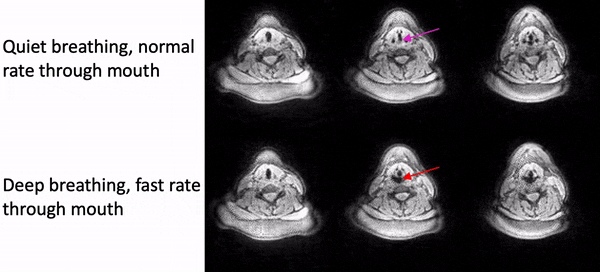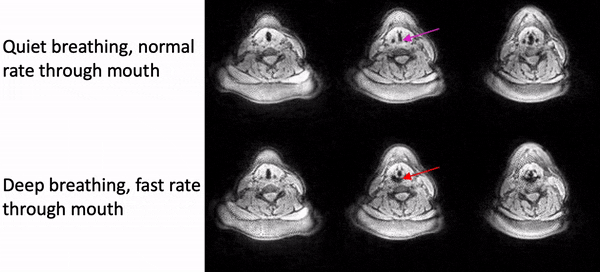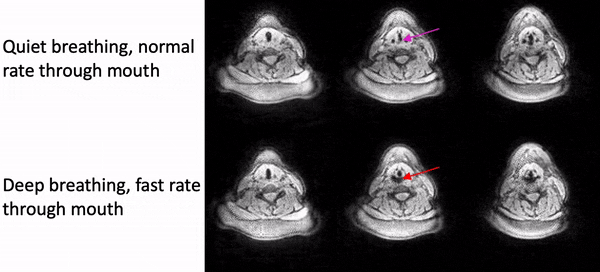
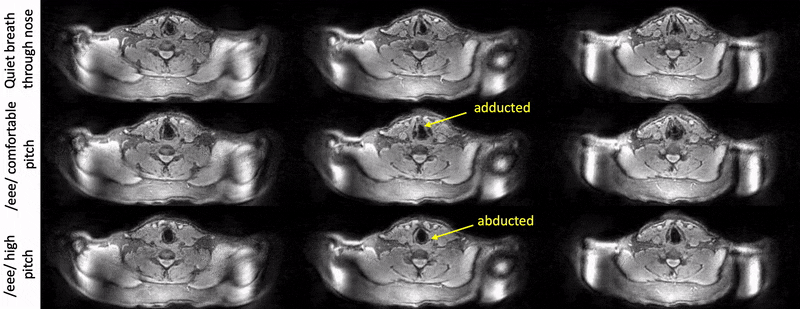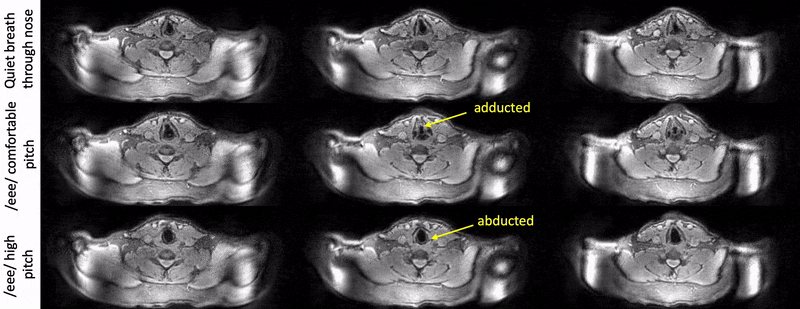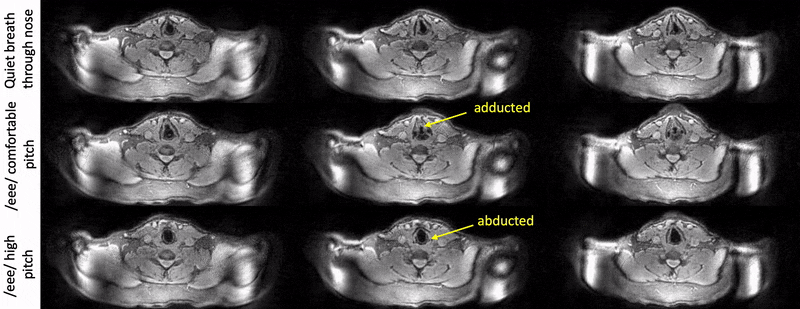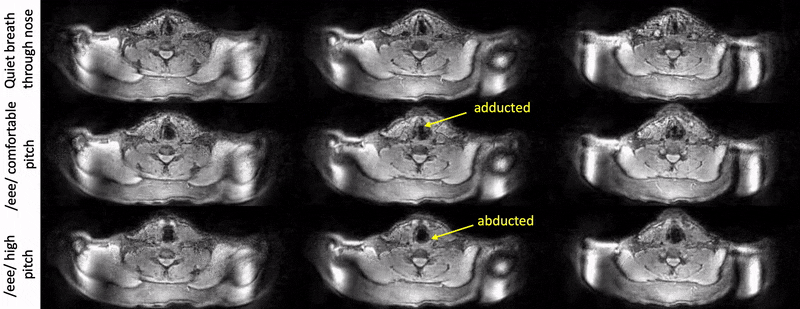
Fig. 2 shows example reconstructions from the female volunteer comparing quiet breathing (normal rate) and deep breathing (fast rate) through the mouth. While we observe adduction/abduction in both the tasks, the deep breathing fast rate emphasizes elongation and shortening of the vocal folds (see yellow arrows).Fig. 3 shows example reconstructions from the male volunteer comparing quiet breathing (normal rate) through the nose, and sustained production of /eee/ at comfortable pitch and high pitch. Similar to Fig. 2, in the top row, we observe the dynamic abduction/adduction movements during quiet breathing. In the middle and bottom rows, we observe the expected differences in vocal fold configuration during production of /eee/ at comfortable pitch, and high pitch, where the vocal folds were respectively adducted and abducted.
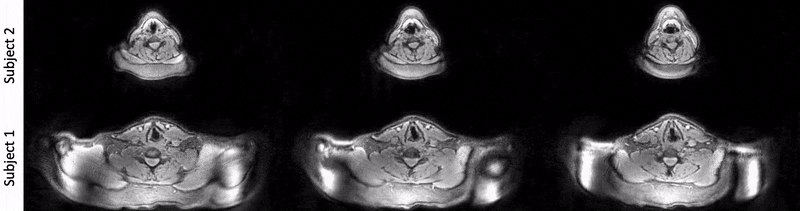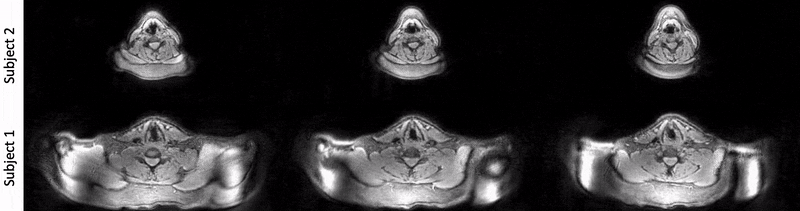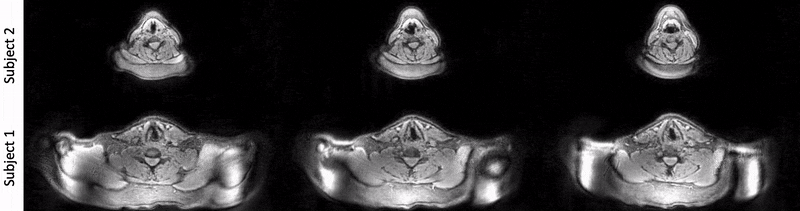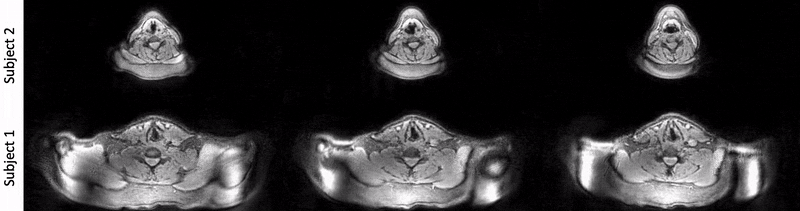
Fig. 4 shows comparison of repeated sniffs through nose between the two volunteers. Note the high time resolution ensures capture of expected dynamic adduction and abduction movements.
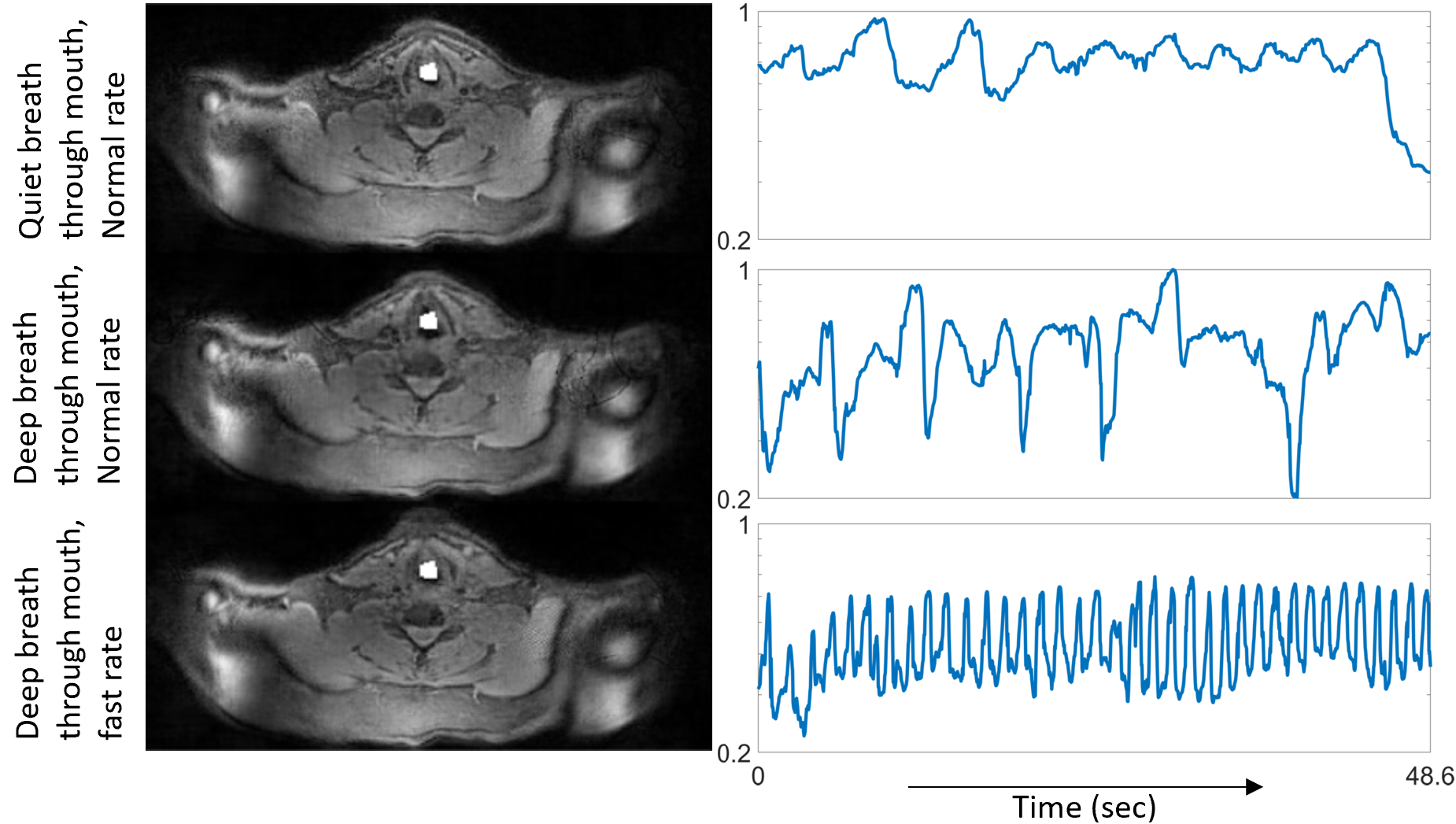
Fig. 5 finally depicts region of interest (ROI) analysis to compare motion patterns across tasks. The averaged intensity of pixels in the white ROI are plotted as a function of time. The intensity variations are proportional to the rate at which the neighboring soft-tissue enter and exit the ROI. In Fig. 5, we observe such analysis can distinguish the subtle differences between various breathing maneuvers.
Conclusion
In this work, we showed preliminary feasibility of dynamic laryngeal MRI in the axial view at both high spatial (up to 1.5 mm2) and high temporal resolutions (up to 36 ms/frame). Our approach showed efficient imaging of typical gross vocal fold configuration changes during various voicing and breathing tasks. Future work includes evaluation of multiple subjects, and extensions to three-dimensional imaging.Acknowledgements
This work is funded by National Institutes of Health Predoctoral Training Grant T32 HL 144461, PI’s Eric A. Hoffman and Joseph M. Reinhardt. This work was conducted on an MRI instrument funded by NIH-S10 instrumentation grant: 1S10OD025025-01.References
[1] Lim Y, Zhu Y, Lingala SG, Byrd D, Narayanan S, Nayak KS. 3D dynamic MRI of the vocal tract during natural speech. Magn Reson Med. 2019;81(3):1511-1520. doi:10.1002/MRM.27570
[2] Feng X, Wang Z, Meyer CH. Real-time dynamic vocal tract imaging using an accelerated spiral GRE sequence and low rank plus sparse reconstruction. Magn Reson Imaging. 2021;80:106. doi:10.1016/J.MRI.2021.04.016
[3] Lingala SG, Zhu Y, Kim YC, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magn Reson Med. 2017;77(1):112-125. doi:10.1002/mrm.26090
[4] Jin R, Shosted RK, Xing F, et al. Enhancing linguistic research through 2-mm isotropic 3D dynamic speech MRI optimized by sparse temporal sampling and low-rank reconstruction. Magn Reson Med. 2023;89(2):652-664. doi:10.1002/MRM.29486
[5] Rusho RZ, Zou Q, Alam W, Erattakulangara S, Jacob M, Lingala SG. Accelerated Pseudo 3D Dynamic Speech MR Imaging at 3T Using Unsupervised Deep Variational Manifold Learning. In: Annual Meeting of the Medical Image Computing and Computer Assisted Intervention Society (MICCAI). Vol 13436. Springer, Cham; 2022:697-706. doi:10.1007/978-3-031-16446-0_66
[6] Zou Q, Ahmed AH, Nagpal P, Kruger S, Jacob M. Dynamic Imaging Using a Deep Generative SToRM (Gen-SToRM) Model. IEEE Trans Med Imaging. 2021;40(11):3102-3112. doi:10.1109/TMI.2021.3065948
Figures