1860
Magnetic Resonance Spectroscopy Data Generation Using Physics-informed Autoencoders1Biomedical Engineering, Eindhoven University of Technology, Eindhoven, Netherlands
Synopsis
Keywords: Spectroscopy, Modelling, Data synthesis
Motivation: MRS data can be accurately simulated in terms of metabolite signals, but contributions from macromolecules, lipids, and scan-related imperfections are more challenging to simulate, leading to realism gaps between in-vivo and simulated spectra.
Goal(s): The goal is to bridge the realism gap between in-vivo and simulated MRS spectra for developing downstream deep learning applications.
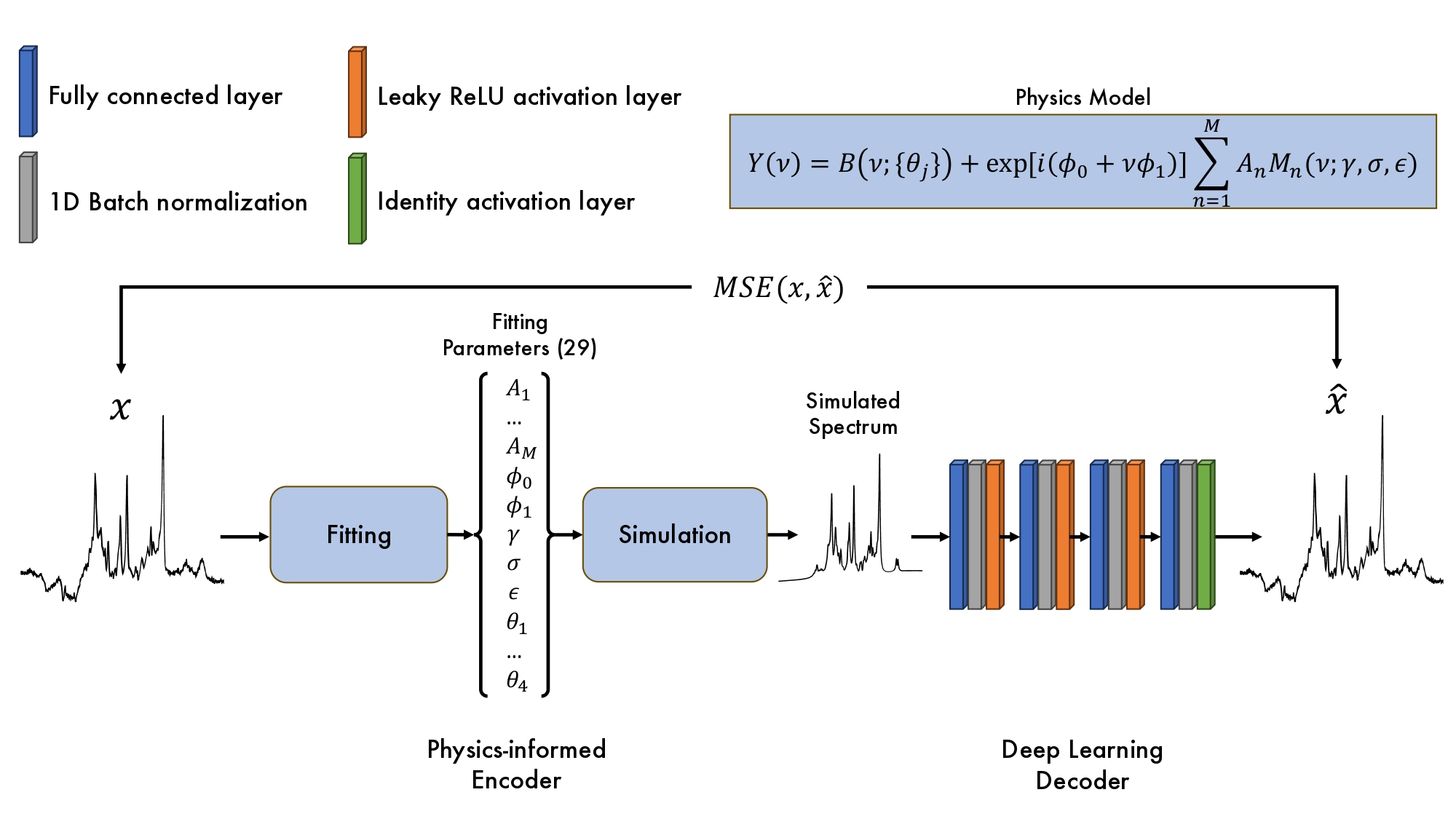
Approach: We propose a physics-informed autoencoder which uses signal-based modules in the encoder and a deep learning-based decoder to generate spectra with in-vivo characteristics.
Results: Our physics-informed method effectively narrows the realism gap between in-vivo and simulated spectra with reduced reconstruction scores and increased overlap in spectral feature space.
Impact: Our research lays the foundation for a robust hybrid MRS data generation framework which generates realistic MRS data while maintaining the interpretability of physics-based simulations. It will help to generate data for developing downstream deep learning applications for MRS.
Introduction
Deep learning (DL) has become a valuable tool to process and analyze proton Magnetic Resonance Spectroscopy (MRS) data1. A key challenge in developing DL methods for MRS is the limited availability of high-quality training data due to restricted access, high acquisition costs, and privacy concerns. Therefore, physics-based simulation of MRS data, involving the linear combination modelling of metabolite basis sets, is a vital tool to artificially generate training data. While metabolite signals are accurately simulated using the matrix density formulation2, contributions from macromolecules (MM), lipids, artefacts, scan-related imperfections, water residuals, and noise are more challenging to simulate, leading to a realism gap between in-vivo and simulated spectra.Data-driven generative models have proven useful for augmenting small datasets with synthetic samples to train other DL applications3. These models learn the generation of complex data structures from the training data but lack direct control over the generative process and interpretability.
This work develops a hybrid data generation method that produces realistic synthetic spectra using data-driven modeling and a physics-based model. Specifically, we propose an autoencoder with a physics-based encoder and DL-based decoder. The decoder is trained to introduce artifacts and imperfections on artifact-free spectra. The goal is to bridge the gap between in-vivo and simulated spectra and improve the realism of the generated MRS data for developing downstream DL applications.
Materials and Methods
Single-voxel MRS spectra from 104 healthy subjects are taken from the Big-GABA dataset4. All spectra are acquired on Philips scanners using PRESS. Preprocessing is performed using FSL-MRS5, involving the removal of water signals, phase and frequency correction, and spectral normalization. To increase the number of spectra, data augmentation is performed by applying random frequency shifts (±8 Hz), zero-order phase shifts (±15°), line broadening (0-7 Hz), and noise addition (0-1.5e-5 standard deviation). Following data augmentation, the dataset contains 20,904 spectra, and is divided into training (16,884), validation (2,010), and testing (2,010) sets, while maintaining augmentations from the same healthy subject within the same split.Figure 1 illustrates the proposed physics-informed autoencoder model. The physics-based encoder uses the FSL-MRS5 fitting and simulation modules with the Osprey6 basis set to generate artifact-free input for the decoder. The DL-based decoder learns to transform this spectrum into one with in-vivo characteristics. The model is trained using a mean squared error (MSE) loss and the real and imaginary part of the spectra. A random search is performed to find the optimal hyperparameters and fitting and simulation is done offline to enhance computational efficiency.
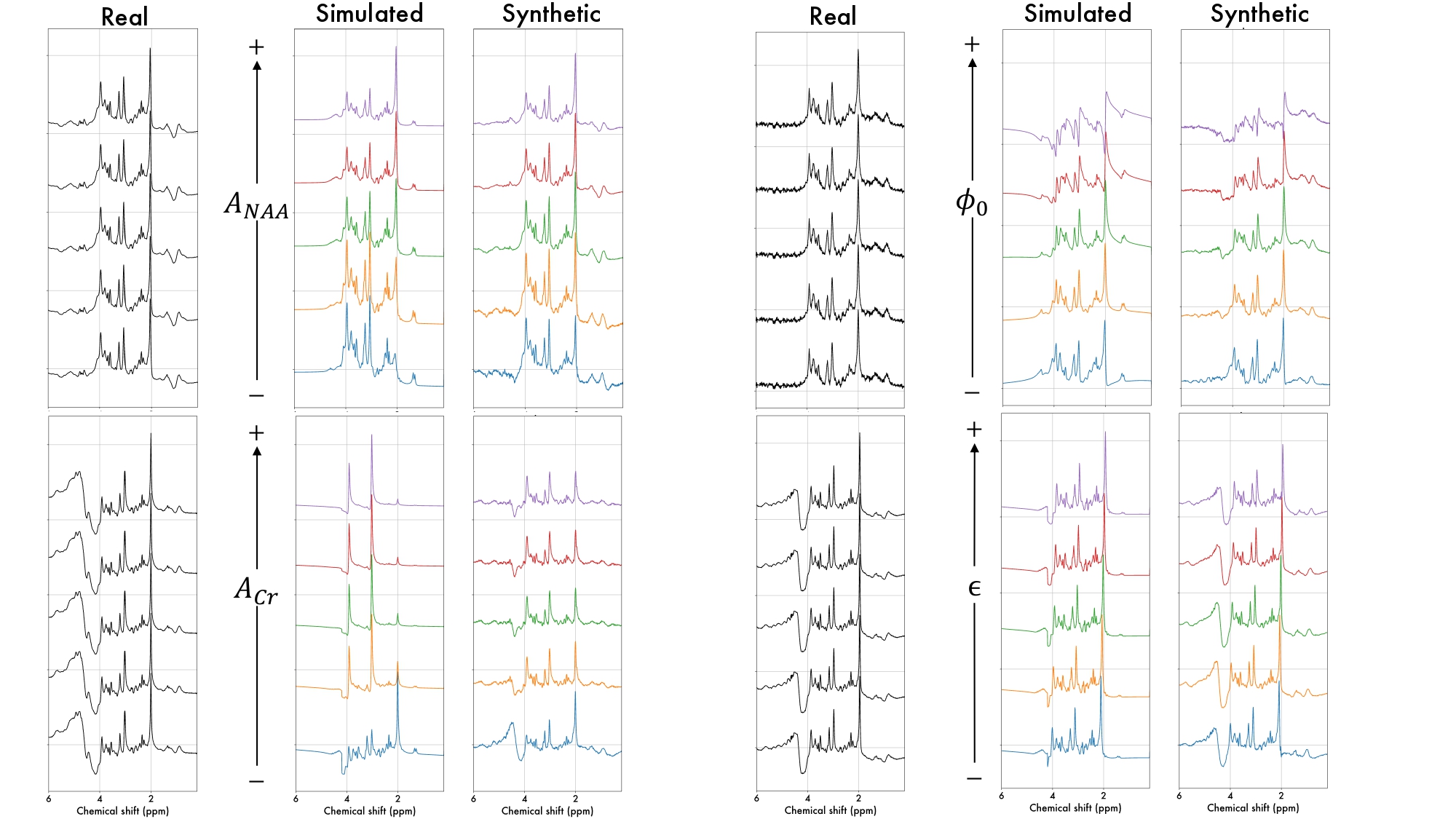
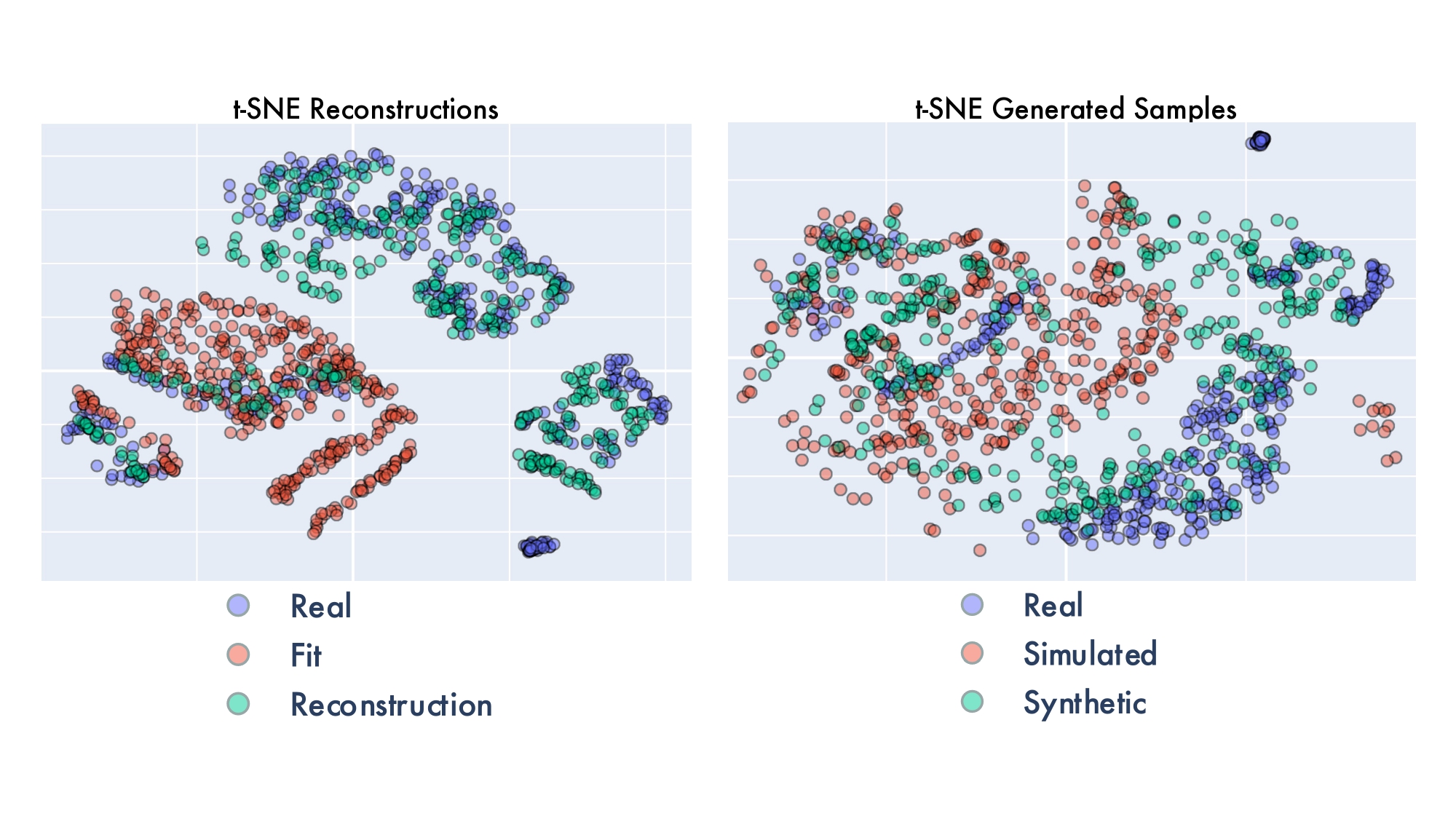
The model's generative capability is evaluated by calculating the reconstruction error on the test set, visualizing the generated samples, and comparing the features of the real, simulated, and synthetic data using t-distributed stochastic neighbor embedding (t-SNE). New simulated spectra are generated by selecting a random subset (400) of the test set and augmenting those by random sampling the concentration of N-Acetylaspartate (NAA), Creatine (Cr), the zero-order phase shift, or the frequency shift parameters. The minimum and maximum range of this uniform sampling are determined according to the minimum and maximum values of these fitting parameters found in the full dataset. The clean simulated spectra are fed to the decoder to produce realistic in-vivo features.
Results
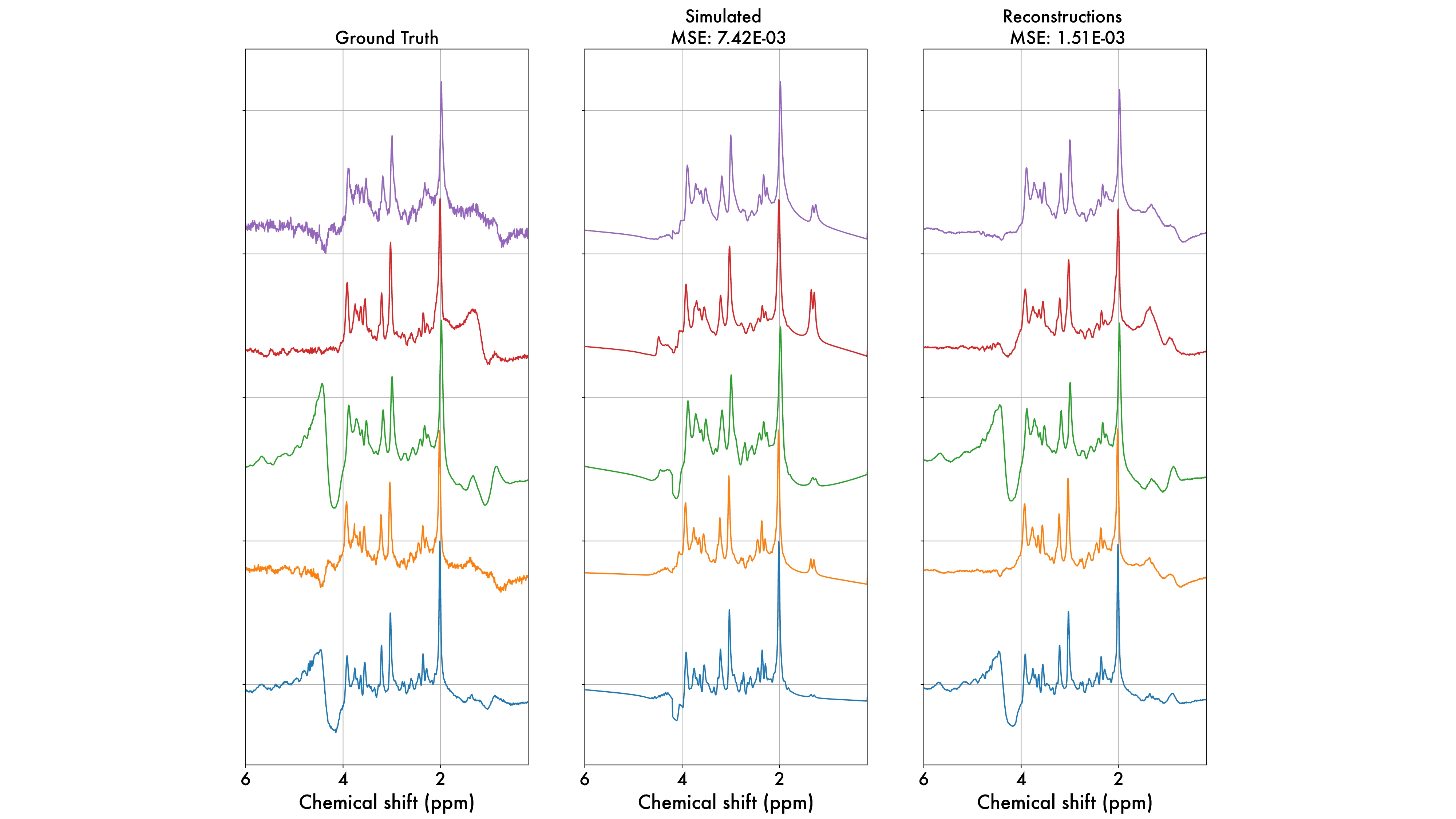
Figure 2 displays the reconstruction results for the complete test set with their respective MSEs. Notably, the autoencoder-generated synthetic data show lower MSE values compared to the simulated spectra, indicating a closer resemblance to in-vivo data. Figure 3 presents newly generated data samples, showing clear variations in the simulated spectra when adjusting fitting parameters, particularly for metabolites like NAA and Cr. This is not shown for the synthetic data, illustrating the autoencoder's limited ability to handle larger parameter deviations. Nevertheless, some in-vivo characteristics persist, especially in residual water (~4.5 ppm) and macromolecules and lipids (~1-2 ppm). Figure 4 illustrates t-SNE plots for the test subset, revealing a more significant overlap between real spectra and synthetic data in contrast to fitted (or simulated) spectra. Concerning the newly generated data, simulated spectra exhibit a broader range of features, while synthetic spectra continue to mimic real spectra.Discussion and Conclusion
Our physics-informed autoencoder effectively narrows the realism gap between in-vivo and simulated spectra, as shown by the reduced MSE reconstruction score and increased overlap in t-SNE plots. While the method's performance relies on prior knowledge provided to the physics model, potential enhancements through more advanced baseline and MM models are a focus of future research. Additionally, we plan to explore the incorporation of a learnable latent space to enhance generative process control. In summary, our research lays the foundation for a robust hybrid MRS data generation framework.Acknowledgements
This work was (partially) funded by Spectralligence (EUREKA IA Call, ITEA4 project 20209).References
1. van de Sande DMJ, Merkofer JP, Amirrajab S, et al. A review of machine learning applications for the proton MR spectroscopy workflow. Magn Reson Med. 2023;90(4):1253-1270. doi:10.1002/mrm.29793
2. Mulkern R, Bowers J. Density matrix calculations of AB spectra from multipulse sequences: Quantum mechanics meetsIn vivo spectroscopy. Concepts Magn Reson. 1994;6(1):1-23. doi:10.1002/cmr.1820060102
3. Kazeminia S, Baur C, Kuijper A, et al. GANs for medical image analysis. Artif Intell Med. 2020;109:101938. doi:10.1016/j.artmed.2020.101938
4. Mikkelsen M, Barker PB, Bhattacharyya PK, et al. Big GABA: Edited MR spectroscopy at 24 research sites. NeuroImage. 2017;159:32-45. doi:10.1016/j.neuroimage.2017.07.021
5. Clarke WT, Stagg CJ, Jbabdi S. FSL-MRS: An end-to-end spectroscopy analysis package. Magn Reson Med. 2021;85(6):2950-2964. doi:10.1002/mrm.28630
6. Oeltzschner G, Zöllner HJ, Hui SCN, et al. Osprey: Open-source processing, reconstruction & estimation of magnetic resonance spectroscopy data. J Neurosci Methods. 2020;343:108827. doi:10.1016/j.jneumeth.2020.108827
Figures