1773
TransGRAPPA: Self-supervised Transformer Network for k-Space Interpolation1Klinikum rechts der Isar, Technical University of Munich, Munich, Germany, 2School of Computation, Information and Technology, Technical University of Munich, Munich, Germany, 3Institute of Machine Learning in Biomedical Imaging, Helmholtz Munich, Munich, Germany, 4Department of Computing, Imperial College London, London, United Kingdom
Synopsis
Keywords: AI/ML Image Reconstruction, Image Reconstruction, Self-supervised learning
Motivation: Addressing limitations in parallel imaging, particularly GRAPPA’s challenges like noise amplification and dependence on linear k-space value combinations.
Goal(s): To enhance k-space interpolation accuracy with a transformer network, thereby improving the quality of clinical imaging.
Approach: We employ a novel self-supervised transformer network with an attention mechanism - TransGRAPPA, exploiting latent features for nonlinear interpolation of missing k-space points.
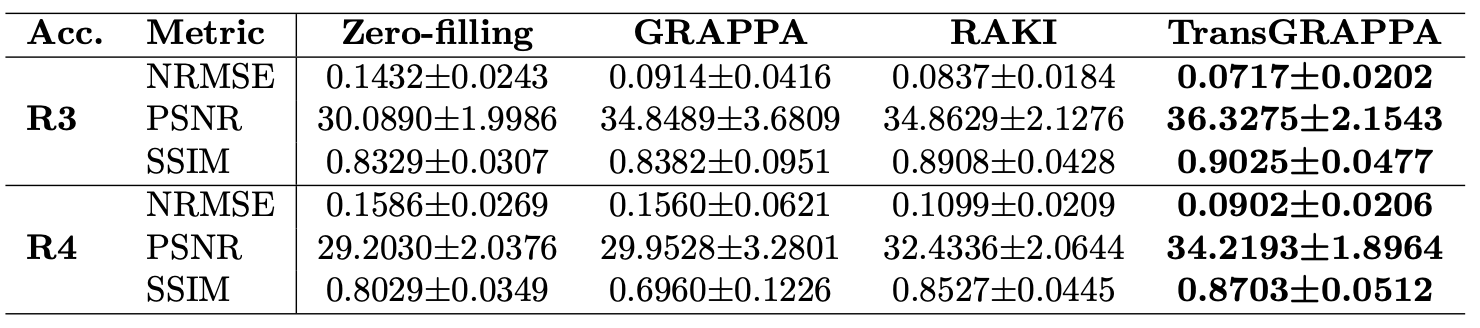
Results: TransGRAPPA outperforms GRAPPA and RAKI in terms of NRMSE, PSNR, SSIM, and noise reduction, showcasing enhanced capabilities on fastMRI’s multi-coil knee dataset.
Impact: The study presents a innovative reconstruction method using transformer network to explore k-space point relationships with limited training data, offering potential improvements in MR image quality and scan speed, and more efficient and accurate diagnostics in medical imaging.
Introduction
GRAPPA1 has pioneered the clinical use of parallel imaging, employing auto-calibration signals (ACS) to interpolate missing k-space points by linear combinations of sampled neighbors. However, GRAPPA reconstructions often suffer from noise amplification at higher acceleration factors, due to the noisy measurements and the simplistic linear combination of sampled k-space points2,3. Recently, the linear combination has been replaced by a non-linear convolutional network known as RAKI4 trained on the ACS. However, its efficacy often hinges on the availability of more auto-calibration lines (~40) than in practical cases.We introduce a self-supervised transformer network tailored for k-space local information extraction and missing point interpolation. Leveraging the strengths of transformer networks and their attention mechanisms5,6,7, our method innovatively applies these capabilities to the realm of k-space. Unlike existing methods, our multi-layer self-attention network is capable of learning the implicit relationships between missing k-space points and their neighbors, and all it need for training is a 20 auto-calibration signals (ACS).
Our contributions are as follow: First, we propose the use of a self-supervised transformer network for k-space interpolation. Second, we demonstrate the efficacy of our approach on the fastMRI multi-coil knee dataset. Finally, our results show that the proposed method outperforms GRAPPA and RAKI and has lower noise level.
Methods
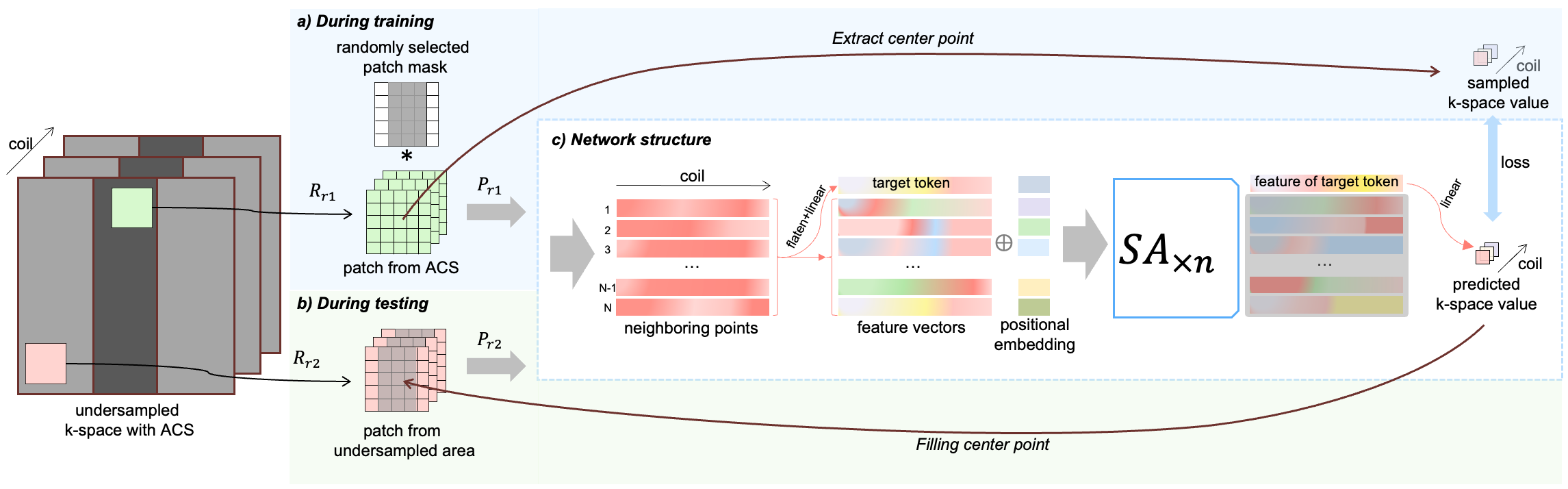
Consider $$$y$$$ as the multi-coil k-space data, with $$$R_ry$$$ representing the patch around point $$$r$$$ in $$$y$$$, extracted using the patch operator $$$R_r$$$. In GRAPPA, the k-space local relationship is modeled as$$ y_r=W\cdot P_rR_ry, $$where $$$P_r$$$ represents a local sampling pattern extracted from k-space sampling mask, $$$W$$$ is the linear weights for recovering the missing k-space points $$$y_r$$$ from the sampled neighbors $$$P_rR_ry$$$. This relationship is considered to be universal in the whole k-space, no matter the fully sampled ACS or the undersampled area. Thus the linear weights can be estimated by solving the overdetermined linear system$$ y_r=W\cdot P_rR_ry,\quad r\in ACS. $$The linear weights $$$W$$$ for a specific $$$P_r$$$can be applied to patches with same local sampling pattern. However, this formulation relies on simplistic linear combinations, which are insufficient for modeling complex relationships in k-space. Furthermore, higher-dimensional feature relationships are missed as the operations are performed explicitly on k-space intensities.We use an attention mechanism on latent features of missing points and neighbors, a nonlinear alternative to linear k-space value combinations. Neighboring points are embedded into the feature space using a linear layer $$$W_{in}$$$ and treated as transformer tokens. A target token $$$t$$$, representing the missing center point, is formed with another linear layer $$$W_t$$$. Multi-layer self-attention[3] $$$SA_{\times n}$$$ then uncovers relationships between these tokens, extracting their latent features $$$z=[z_0, z_1,...z_N]$$$. The feature corresponding to the target token $$$z_0$$$ is remapped to the k-space value dimension with linear layer $$$W_{out}$$$:$$ y_r=W_{out}z_0, \quad z=SA_{\times n}(E_{pos}(W_{t}\cdot R_ry\oplus (W_{in}\cdot P_rR_ry)).$$Here $$$\oplus$$$ represents concatenation, and $$$E_{pos}$$$ is positional embedding, concatenating relative position to features. See Figure 1 for the method's diagram.
Network training is self-supervised, using retrospectively undersampled patches from fully sampled ACS, similar to GRAPPA. After training, undersampled areas are reconstructed by the network in a patch-wise way.
Experiments
Experiments were conducted on 40 random slices from FastMRI's8 multi-coil knee dataset at 4x acceleration, using retrospective equal-spaced undersampling with 20 ACS lines. Our model comprises 8-layer self-attention blocks, each with 8 heads and a 512-dimensional embedding. We adapted a 5x5 patch size, the real and imaginary part of each sampled points are concatenated and considered as a input token. Training involved a smoothed L1 loss and AdamW optimizer (learning rate: 2e-5, weight decay: 1e-4, batch size: 1024), spanning 300 epochs. Implemented in PyTorch and run on a NVIDIA A6000 GPU, training and reconstruction per slice took approximately 10 minutes.Results
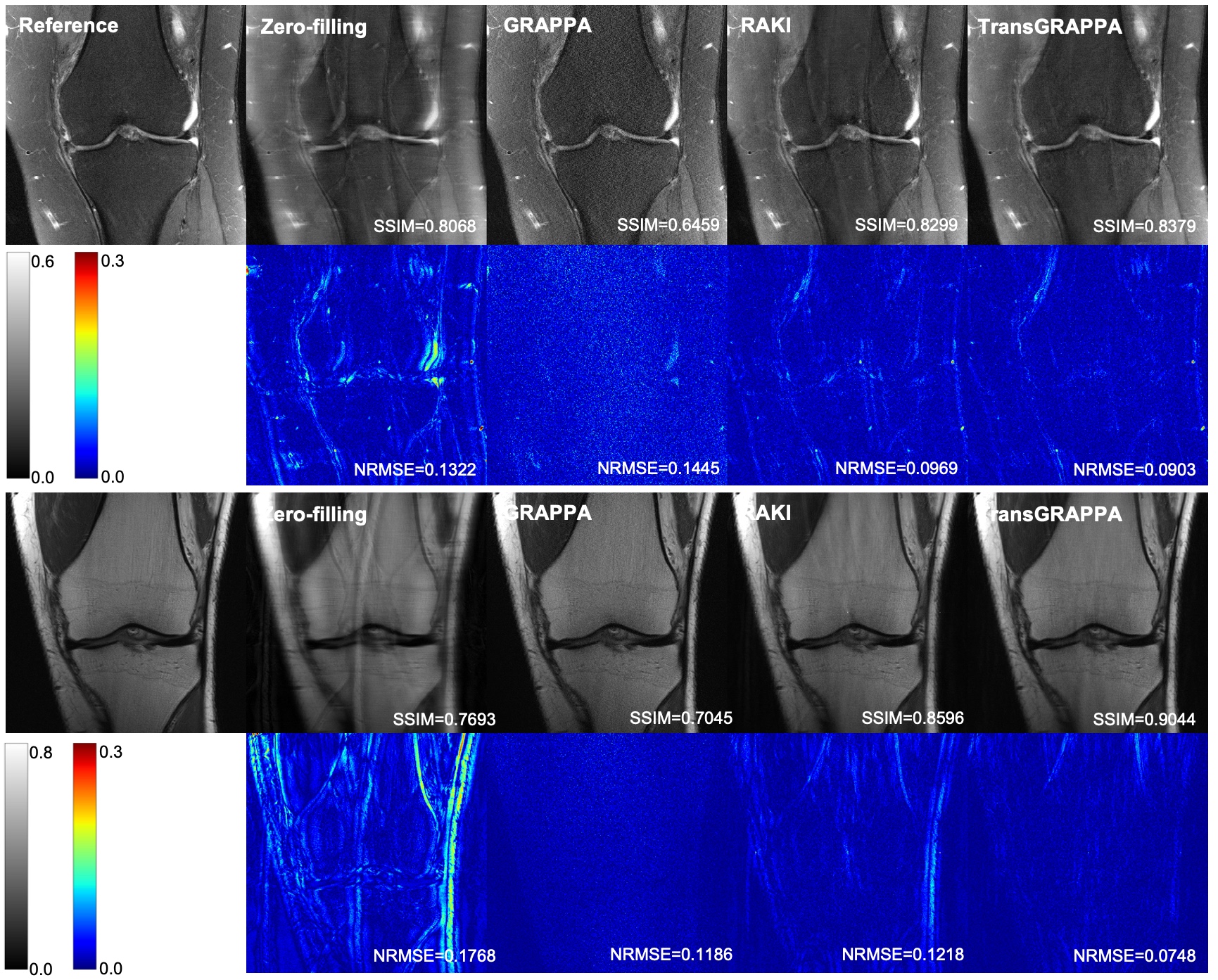
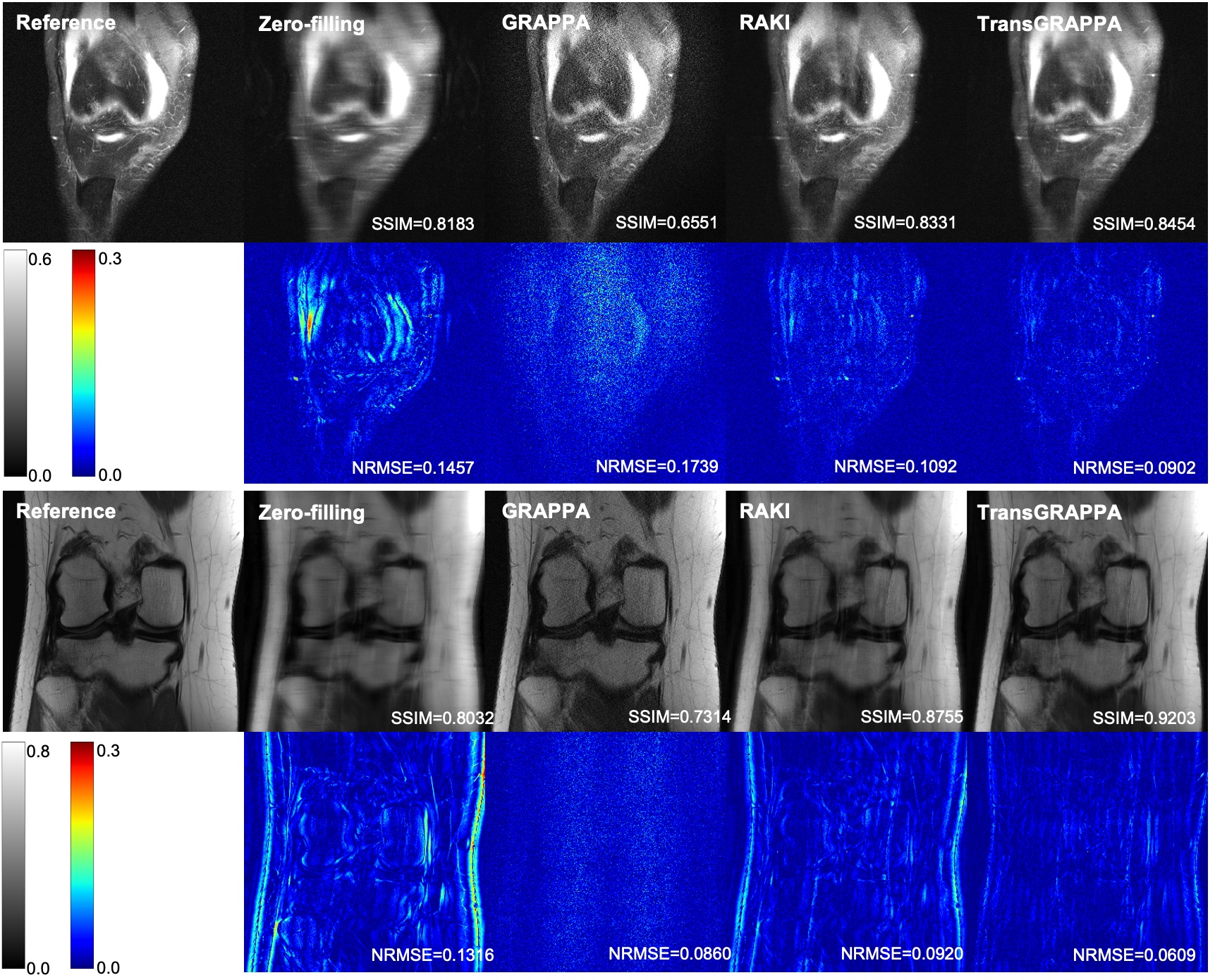
Table I shows the quantitative results, and Figures 2 and 3 illustrate the visual outcomes. The NRMSE and error maps reveal GRAPPA's significant noise amplification, especially at R=4. RAKI, utilizing merely 20 ACS lines, which much less than its original paper, suffers from pronounced aliasing artifacts. Conversely, the proposed TransGRAPPA model achieves the best metrics, exhibiting the lowest noise levels and substantially reduced artifacts compared to RAKI.Discussion and Conclusion
The proposed TransGRAPPA model enhances k-space interpolation with self-attention, surpassing GRAPPA and RAKI in NRMSE, PSNR, SSIM, and noise reduction. Current limitations include time-consuming model training, occasional artifacts that probably caused by imbalanced k-space signal scales, and limited direct generalization to new slices. Future efforts aim to integrate GRAPPA weights into the attention mechanism and employ cross-subject priors to improve generalization of TransGRAPPA.Acknowledgements
This work was supported in part by the European Research Council (Deep4MI project, Grant Agreement Nr.884622).References
- Griswold, Mark A., et al. "Generalized autocalibrating partially parallel acquisitions (GRAPPA)." Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine 47.6 (2002): 1202-1210.
- Chang, Yuchou, Dong Liang, and Leslie Ying. "Nonlinear GRAPPA: A kernel approach to parallel MRI reconstruction." Magnetic Resonance in Medicine 68.3 (2012): 730-740.
- Aja-Fernández, Santiago, Gonzalo Vegas-Sánchez-Ferrero, and Antonio Tristán-Vega. "Noise estimation in parallel MRI: GRAPPA and SENSE." Magnetic resonance imaging 32.3 (2014): 281-290.
- Akçakaya, Mehmet, et al. "Scan‐specific robust artificial‐neural‐networks for k‐space interpolation (RAKI) reconstruction: Database‐free deep learning for fast imaging." Magnetic resonance in medicine 81.1 (2019): 439-453.
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
- Pan, Jiazhen, et al. "Global k-Space Interpolation for Dynamic MRI Reconstruction Using Masked Image Modeling." International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland, 2023.
- Zbontar, Jure, et al. "fastMRI: An open dataset and benchmarks for accelerated MRI." arXiv preprint arXiv:1811.08839 (2018).
Figures