1767
Weak supervision in multi-coil accelerated MR image reconstruction1Center for Data Science, New York University, New York, NY, United States, 2Courant Institute of Mathematical Sciences, New York University, New York, NY, United States, 3Bernard and Irene Schwartz Center for Biomedical Imaging, Department of Radiology, New York University Grossman School of Medicine, New York, NY, United States, 4Center for Advanced Imaging Innovation and Research (CAI2R), Department of Radiology, New York University Grossman School of Medicine, New York, NY, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence
Motivation: In training-data-limited settings, weak supervision –cooperatively utilizing under-sampled and fully-sampled datasets– can be advantageous.
Goal(s): To compare weakly-supervised multi-coil Magnetic Resonance (MR) image reconstruction against reconstruction using only under-sampled or fully-sampled datasets in high- and low-data regimes.
Approach: Pretrain a Variational Network (VarNet) in a self-supervised manner by minimizing L1 loss in k-space using a 4x under-sampled dataset. Transfer the pre-trained weights to another VarNet and fine-tune it using a smaller, fully sampled dataset by optimizing MS-SSIM loss in image space.
Results: We demonstrate improvements in reconstruction quality in the high-data regime as well as enhanced robustness of reconstruction in the low-data regime.
Impact: Multi-coil MR image reconstruction exploiting both under-sampled and fully-sampled datasets is achievable with transfer learning and fine-tuning. Our proposed methodology can provide improved reconstruction quality and robustness.
Introduction
Deep learning (DL) methods represent the current state of the art in accelerated MR image reconstruction1-3. Most DL reconstruction methods are trained in a fully-supervised manner using fully-sampled k-space data as ground-truth. In practice however, obtaining large-scale fully-sampled raw data can be challenging or outright infeasible. Accordingly, there has been significant progress in developing unsupervised and self-supervised MR image reconstruction methods in recent years4,5.We investigate the prospect of multi-coil MR image reconstruction, which involves combining self-supervised and supervised DL methods. We contrast weak supervision against utilizing the respective under-sampled and fully-sampled datasets alone. We illustrate that weak supervision allows superior reconstruction quality when plentiful training data is available (the high-data regime), and can enhance the robustness of reconstruction when training data is limited (the low-data regime).
Methods
Our methodology as illustrated in Fig. 1, consists of two stages, namely the self-supervised pre-training stage and the fully supervised fine-tuning stage. In each stage, we use VarNet2 with U-net8 backbone solving the reconstruction optimization problem2 with ADMM9. We use fastMRI7 multi-coil knee MR data with two custom dataset splits for the two stages as shown in Fig. 2, corresponding to high- and low-data regimes, respectively.Stage 1: Self-supervised pre-training
In this stage, we train a VarNet2 in a self-supervised manner4,5 that reconstructs 4x under-sampled k-space data from an 8x under-sampled data. We train and evaluate VarNets at 8x acceleration with random masks, while making sure the 8x under-sampling masks are subsets of the available 4x under-sampling masks.
Let $$$\mathbf{k}$$$ denote the under-sampled MRI measurement. That is, $$$\mathbf{k} \triangleq M\, \mathbf{k}^{full}$$$ for a binary mask $$$M$$$ and fully-sampled k-space $$$\mathbf{k}^{full}$$$. Let $$$\mathbf{k}^T\triangleq \text{VarNet}(\mathbf{k}; \mathbf{\theta})$$$ denote the output of VarNet with parameters $$$\mathbf{\theta}$$$ and number of cascades $$$T$$$. We follow the SSDU framework4,5 and at each iteration $$$i$$$ of training, we generate a random subset of $$$M$$$, which is denoted by $$$M_{\Lambda_i}$$$. During training, we update $$$\mathbf{\theta}$$$ by minimizing the L1 loss in k-space.
\begin{align} \widehat{\mathbf{\theta}}_{SS} &= \arg\min_{\mathbf{\theta}} \lVert \, M_{\Lambda_i}\left(\mathbf{k} - \mathbf{k}^T\right)\rVert_1\\ &= \arg\min_{\mathbf{\theta}} \lVert \,M_{\Lambda_i}\left(\mathbf{k} - \text{VarNet}(\mathbf{k}; \mathbf{\theta})\right)\rVert_1.\end{align}
Validation was performed similarly with L1 loss in k-space.
Stage 2: Fully-supervised fine-tuning
In this stage we transfer the learned parameters from Stage 1 into another VarNet with the same architecture as above and fine-tune its parameters using a smaller, fully-sampled dataset by optimizing MS-SSIM loss in the image domain. Let $$$\mathbf{x}_{gt}$$$ denote the ground-truth image corresponding to the center-cropped, root sum-of-squares of inverse Fourier transform of fully-sampled k-space measurements. Assuming we obtain a VarNet with parameters $$$\widehat{\mathbf{\theta}}_{SS}$$$ from the self-supervised learning, we initialize the weights of the VarNet with $$$\widehat{\mathbf{\theta}}_{SS}$$$, and minimize the MS-SSIM loss6 in image domain.
\begin{align}
\widehat{\mathbf{\theta}}_{TL} = \arg\min_{\mathbf{\theta}}\, &\text{MS-SSIM}\left(\mathbf{x}_{gt}, \,\text{CenterCrop}\circ\text{RSS}\circ\mathcal{F}^{-1}\left( \text{VarNet}(\mathbf{k}; \mathbf{\theta})\right)\right)\\
&\text{ subject to } \mathbf{\theta}_0 = \widehat{\mathbf{\theta}}_{SS}.
\end{align}
Results
We compared the reconstruction performance of the proposed weakly supervised methodology to the self-supervised reconstruction (using under-sampled training data), supervised reconstruction using a smaller set of fully-sampled data, and supervised reconstruction using the entire fastMRI dataset (baseline). SSIM, NMSE, and PSNR were computed for each case, with background regions masked and removed from consideration. We repeated these experiments in high-data and low-data regimes, with dataset details provided in Fig. 2.Quantitative results using SSIM, NMSE, and PSNR as quality metrics are illustrated in Fig. 2. In the high-data regime, self-supervision can still fall short of full-supervision. However, our proposed approach improves performance and bridges the gap between self-supervised and baseline reconstructions. In the low-data regime, we observe minor performance improvements as measured by the mean values of quantitative metrics. However, as seen in Fig. 5, our methodology appears to improve quality in selected cases for which self-supervised reconstruction falls short.
For qualitative comparison, we illustrate example reconstructions for high- and low-data regimes in Fig. 3-5. In Fig.3, we observe that weak supervision performs on par with the baseline in the high-data regime, surpassing the others.
Discussion and conclusion
Our experiments indicate that employing weak supervision in the high-data regime enhances the quality of reconstruction and yields performance that closely approaches that of supervised reconstruction using the entire FastMRI dataset. In the low-data regime, we notice improved robustness in certain cases. Further exploration is required to identify precise circumstances under which self-supervised reconstruction falls short of expected performance and weakly-supervised strategy adds robustness.Weak supervision in single-coil reconstruction was proposed recently using contrastive learning pre-training10. However, that work used multiple under-sampling masks on a per-patient basis, which implicitly incorporates some degree of fully-sampled information. Our method is designed to be implemented in a multi-coil setup using a single under-sampling mask for each patient.
Acknowledgements
This work was supported in part by the NIH P41 EB017183, and was performed under the rubric of the Center for Advanced Imaging Innovation and Research (CAI2R, www.cai2r.net), an NIBIB National Center for Biomedical Imaging and Bioengineering.References
1. Hammernik, K., Klatzer, T., Kobler, E., Recht, M. P., Sodickson, D. K., Pock, T., & Knoll, F. (2018). Learning a variational network for reconstruction of accelerated MRI data. Magnetic resonance in medicine, 79(6), 3055-3071.
2. Sriram, A., Zbontar, J., Murrell, T., Defazio, A., Zitnick, C. L., Yakubova, N., ... & Johnson, P. (2020). End-to-end variational networks for accelerated MRI reconstruction. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part II 23 (pp. 64-73). Springer International Publishing.
3. Aggarwal, H. K., Mani, M. P., & Jacob, M. (2018). MoDL: Model-based deep learning architecture for inverse problems. IEEE transactions on medical imaging, 38(2), 394-405.
4. Yaman, B., Hosseini, S. A. H., Moeller, S., Ellermann, J., Uğurbil, K., & Akçakaya, M. (2020). Self‐supervised learning of physics‐guided reconstruction neural networks without fully sampled reference data. Magnetic resonance in medicine, 84(6), 3172-3191.
5. Yaman, B., Gu, H., Hosseini, S. A. H., Demirel, O. B., Moeller, S., Ellermann, J., ... & Akçakaya, M. (2022). Multi‐mask self‐supervised learning for physics‐guided neural networks in highly accelerated magnetic resonance imaging. NMR in Biomedicine, 35(12), e4798.
6. Wang, Z., Simoncelli, E. P., & Bovik, A. C. (2003, November). Multiscale structural similarity for image quality assessment. In The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003 (Vol. 2, pp. 1398-1402). Ieee.
7. Zbontar, J., Knoll, F., Sriram, A., Murrell, T., Huang, Z., Muckley, M. J., ... & Lui, Y. W. (2018). fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv preprint arXiv:1811.08839.
8. Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 (pp. 234-241). Springer International Publishing.
9. Boyd, S., Parikh, N., Chu, E., Peleato, B., & Eckstein, J. (2011). Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends® in Machine learning, 3(1), 1-122.
10. Ekanayake, M., Chen, Z., Egan, G., Harandi, M., & Chen, Z. (2023). Contrastive Learning MRI Reconstruction. arXiv preprint arXiv:2306.00530.
Figures
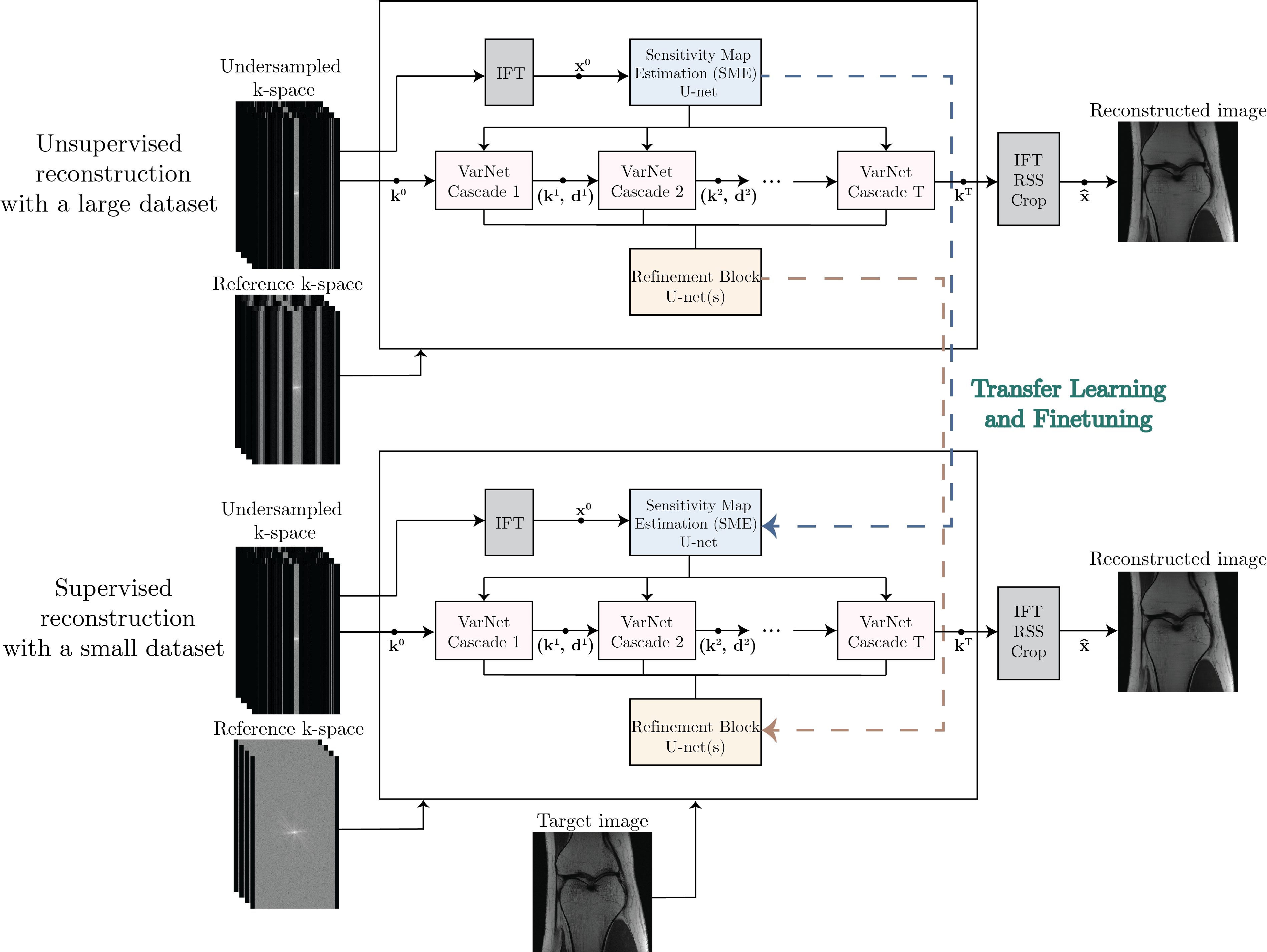
Figure 1
Block diagram of the proposed weakly-supervised reconstruction pipeline
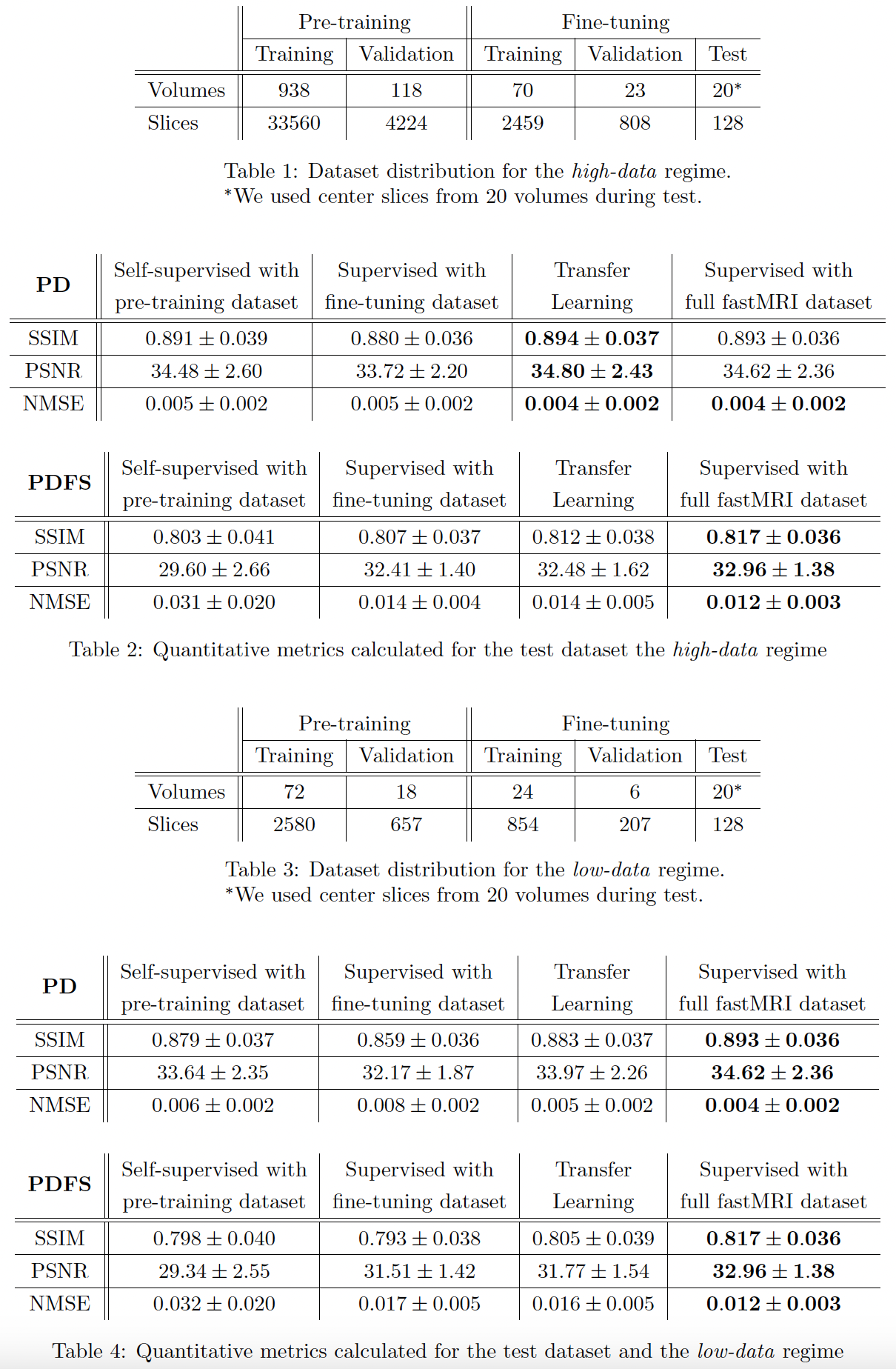
Figure 2
Table 1 and 2: Dataset distribution and quantitative metrics for the test dataset in the high-data regime. The metrics are calculated for 128 selected center slices (rather than for entire volumes over which reconstruction quality metrics can vary nontrivially).
Table 3 and 4: Dataset distribution and quantitative metrics for the test dataset in the low-data regime. Once again, the metrics are calculated for 128 selected center slices.
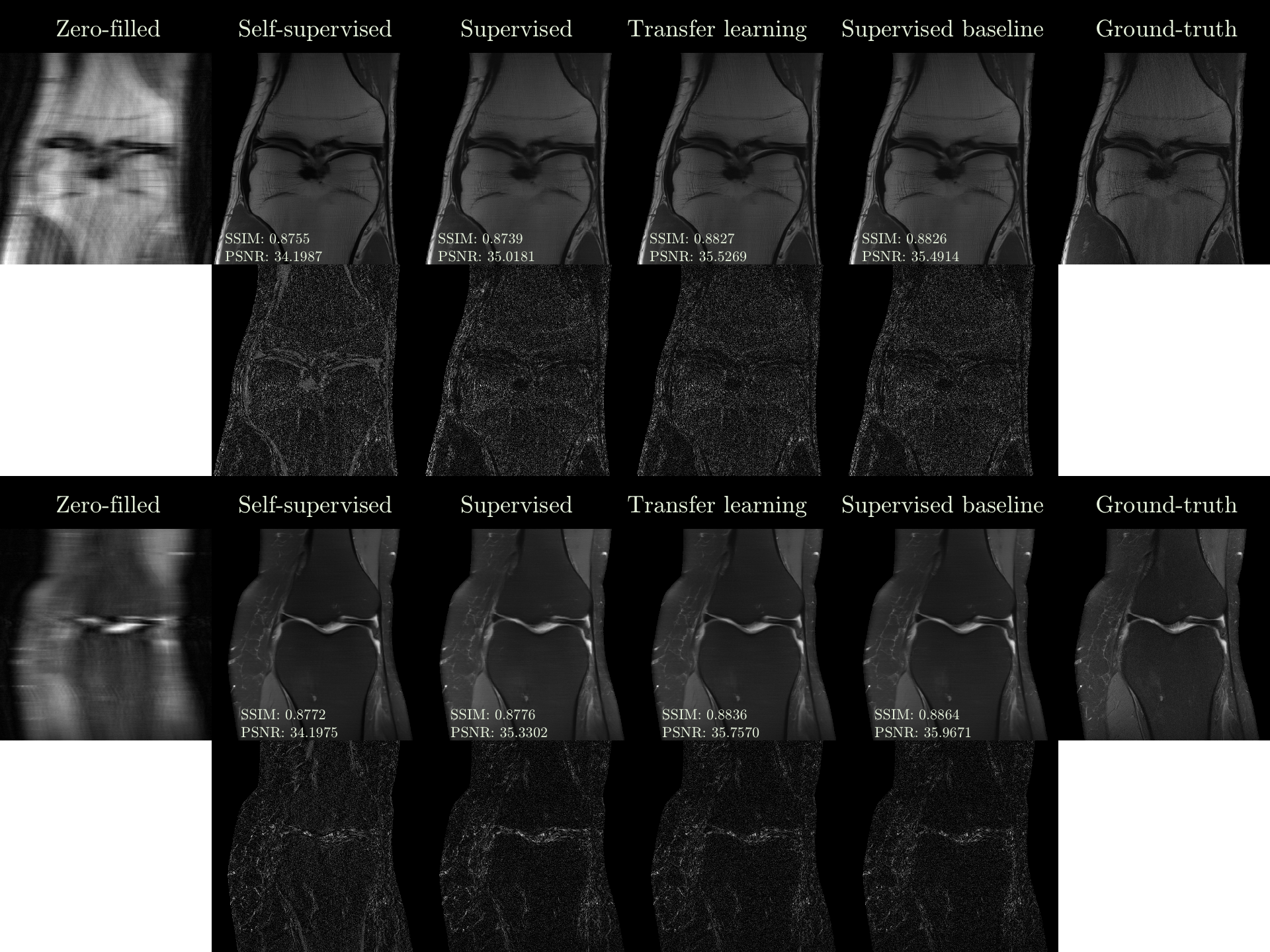
Figure 3
Top: Zero-filled image, reconstructions, and the ground-truth in the high-data regime
Bottom: Difference images computed by subtracting corresponding reconstructions from ground truth, displayed with joint normalization
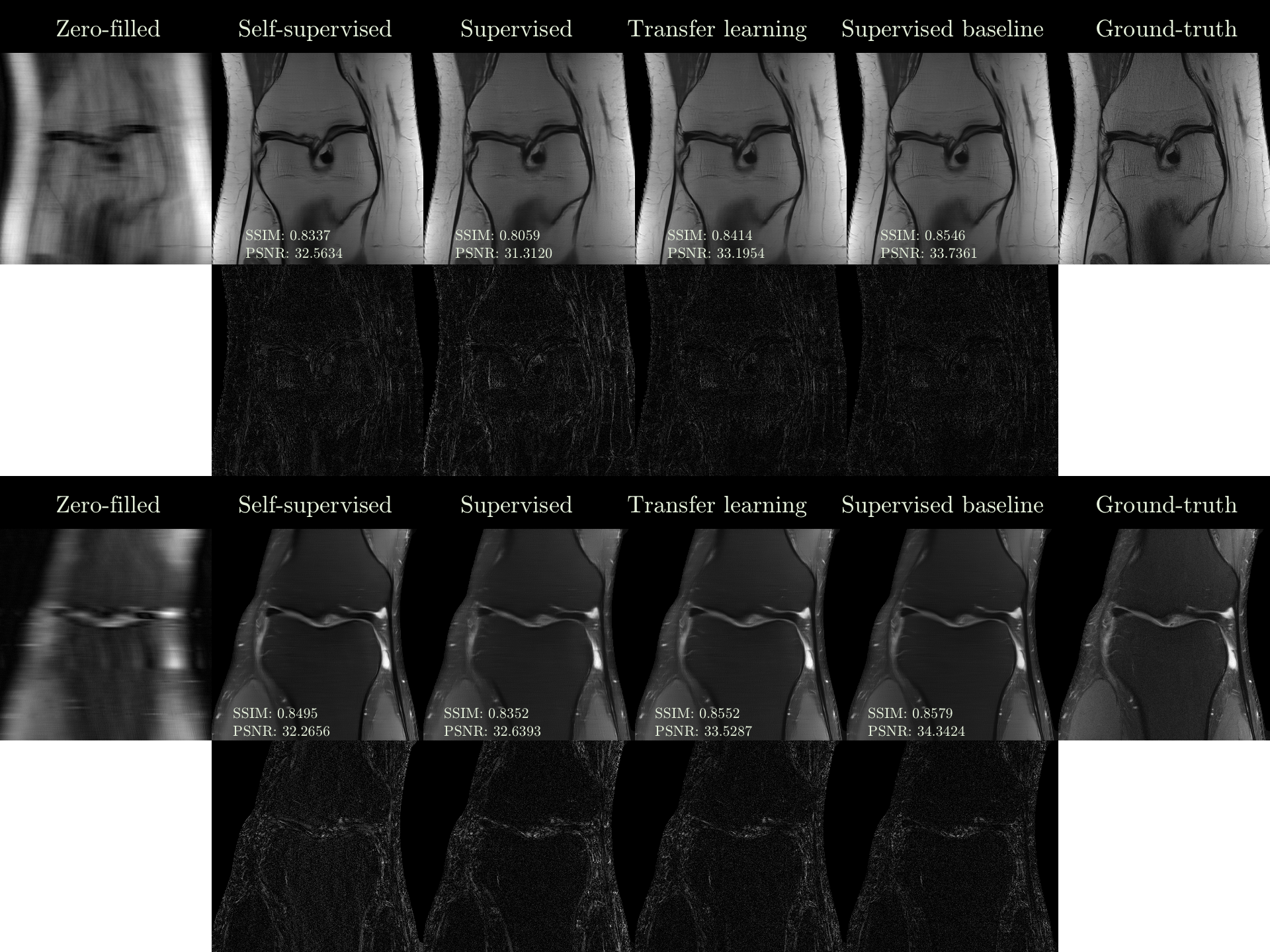
Figure 4
Top: Zero-filled image, reconstructions, and the ground-truth in the low-data regime
Bottom: Difference images displayed with joint normalization
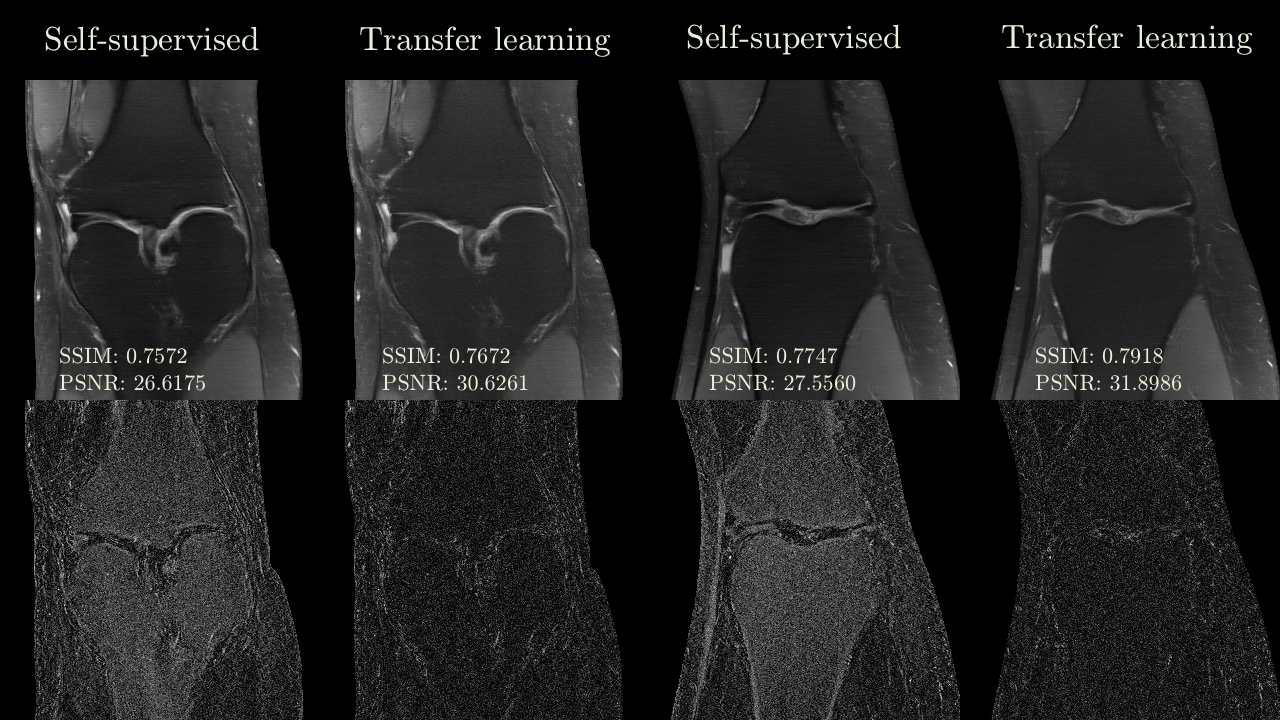
Figure 5
Robustness of transfer learning vs. self-supervised learning in the low-data regime