1765
Joint Multi-Contrast Image Reconstruction with Self-Supervised Learning1Medical Biophysics, University of Toronto, Toronto, ON, Canada, 2Physical Sciences Research Platform, Sunnybrook Research Institute, Toronto, ON, Canada, 3FMRIB, Wellcome Centre for Integrative Neuroimaging, Oxford, United Kingdom
Synopsis
Keywords: AI/ML Image Reconstruction, Image Reconstruction
Motivation: Self-supervised learning via data undersampling (SSDU) uses single contrast images in reconstruction, but a typical protocol contains multiple contrasts that provide additional information.
Goal(s): Our goal is to improve self-supervised image reconstruction fidelity by jointly reconstructing multi-contrast images.
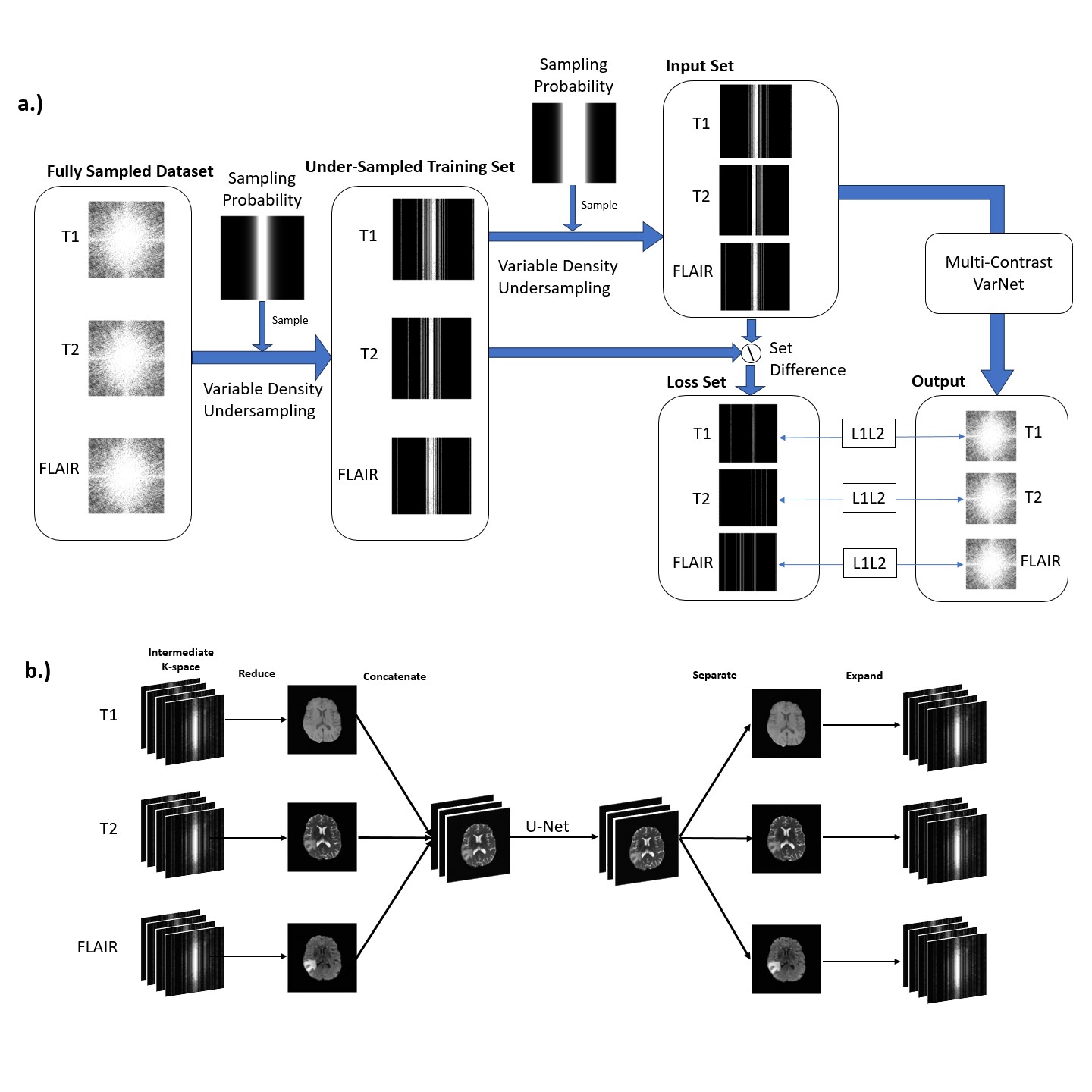
Approach: We modify SSDU by concatenating independently under-sampled contrasts along the channel dimension in a VarNet architecture.
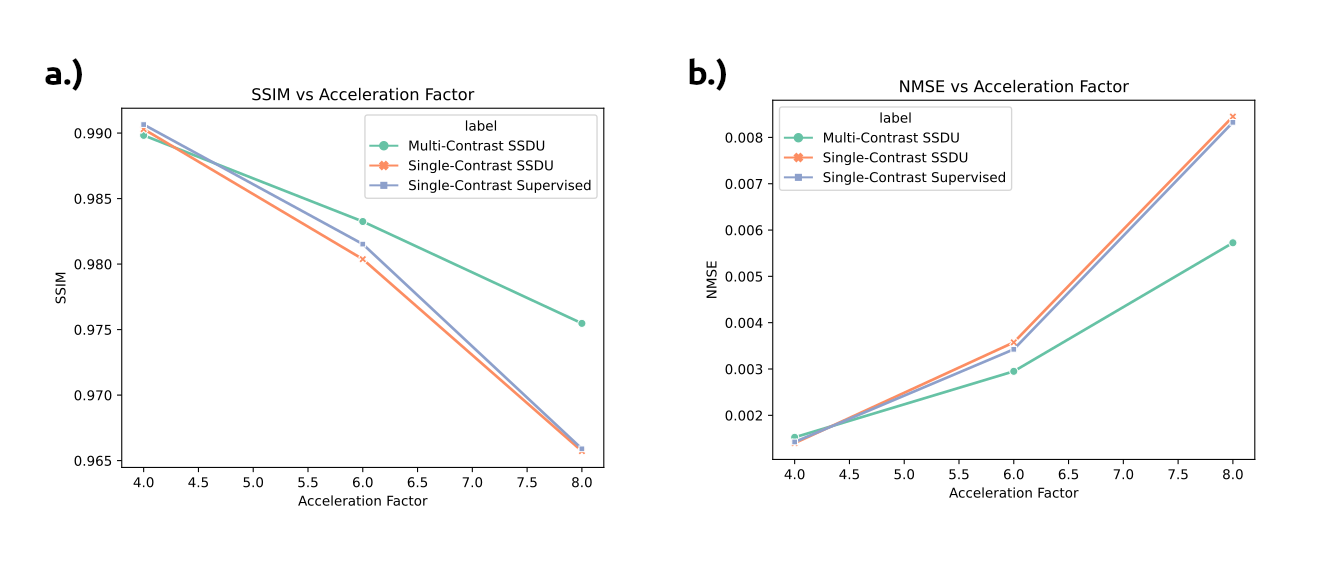
Results: Joint multi-contrast SSDU reconstructs with higher SSIM and lower NMSE than single contrast supervised and self-supervised methods.
Impact: Joint multi-contrast SSDU produces higher quality reconstructions than single-contrast methods, without fully-sampled training data. Accelerated multi-contrast imaging protocols will benefit from higher diagnostic quality or higher acceleration factors.
Introduction
Deep learning (DL) image reconstruction has shown promise for producing high fidelity images from under-sampled measurements1–3. However, most DL-based methods are trained in a supervised manner, which requires fully sampled data for learning. In contrast, self-supervised methods have been gaining interest, alleviating the need for fully sampled data by learning directly from under-sampled data, while producing reconstruction quality comparable to supervised training4,5.One approach to self-supervised learning is self-supervised learning via data undersampling (SSDU). SSDU partitions the acquired k-space into two disjoint sets and trains a network to map from one set to the other4,without the network ever seeing fully-sampled data. While the original SSDU method operates on single contrast images, MRI protocols often acquire multiple contrasts of the same anatomy that provide complementary information. Here, we introduce a joint multi-contrast reconstruction framework using SSDU that builds upon single contrast SSDU and supervised multi-contrast methods6–8. We show that joint multi-contrast SSDU improves reconstruction fidelity compared to conventional single-contrast SSDU and fully-supervised reconstructions.
Methods
We used 2D slices from the BraTS 20219 (T1, T1 contrast enhanced, T2, FLAIR) and M4Raw10 (T1, T2, FLAIR) datasets to train our multi-contrast reconstruction network. The BraTS dataset is provided as magnitude coil-combined DICOM images, so we synthesize k-space data by adding synthetic coil sensitivities, random phases, and additive noise prior to Fourier transform. We additionally use the M4Raw dataset to validate our proposed method on real, acquired k-space data.We use a modified 2D Variational Network (VarNet) unrolled for 6 cascades1,11 as the baseline architecture for both single and multi-contrast SSDU. For the multi-contrast variant, we modify the U-Net by concatenating input image contrasts along the channel dimension (Figure 1b). Our U-Net has 4 downsampling layers with 32 initial convolutional filters, resulting in a full network size of 47M parameters. We use variable density column wise undersampling with a R=4 and polynomial order 8 to generate our undersampling masks, sampled independently across contrasts. We further partition our training k-space data into two sets based on the same distribution at R=24,12, and we additionally randomly re-partition our data after every epoch5. We used the Adam optimizer with a learning rate of 10−3, a normalized L1-L2 loss, and trained for 50 epochs. We also train single-contrast models using fully supervised and self-supervised SSDU VarNets with the same parameters as above for comparison. We use structural similarity index (SSIM)13 and normalized mean squared error (MSE) for image evaluation.
Results
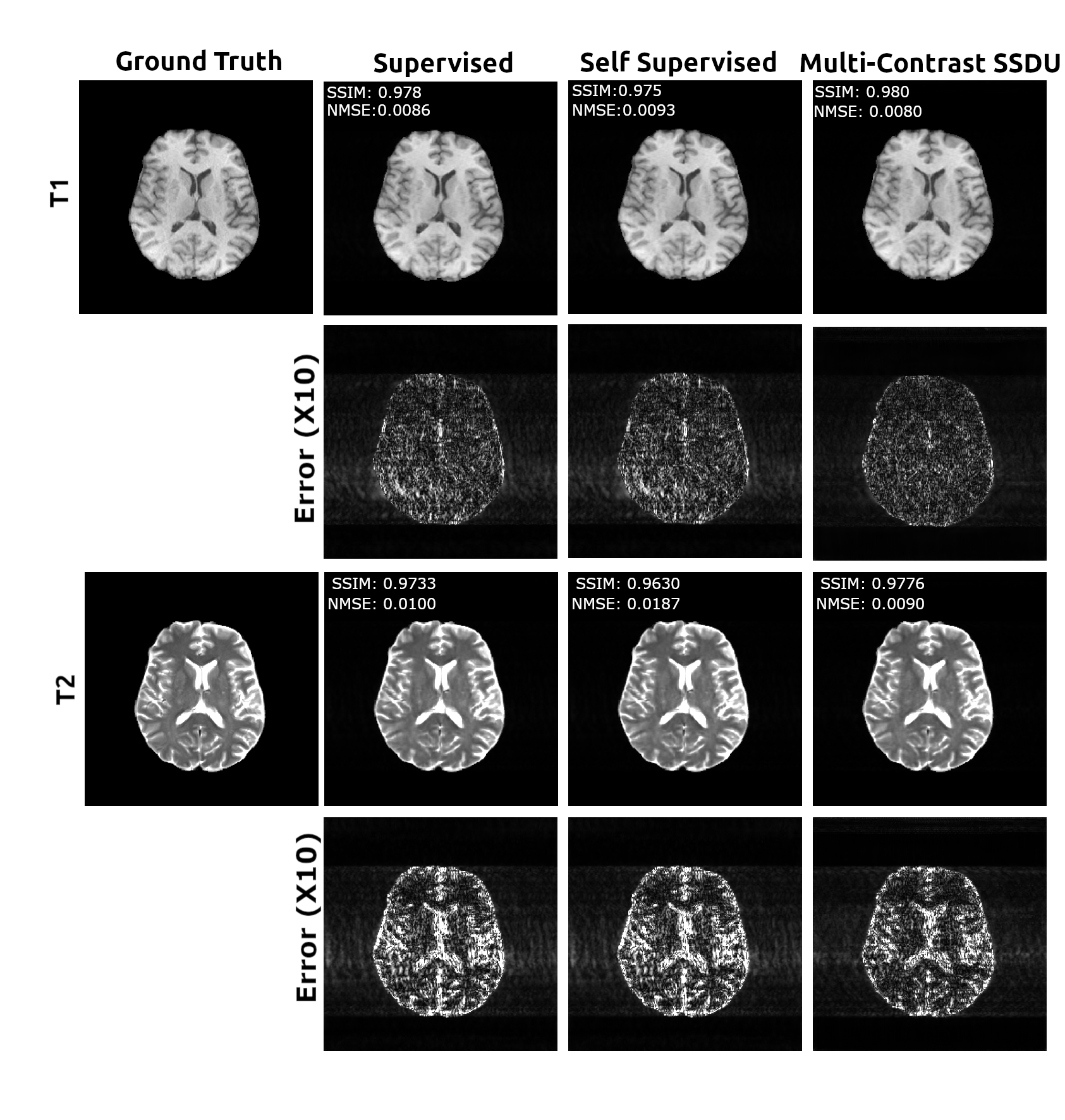
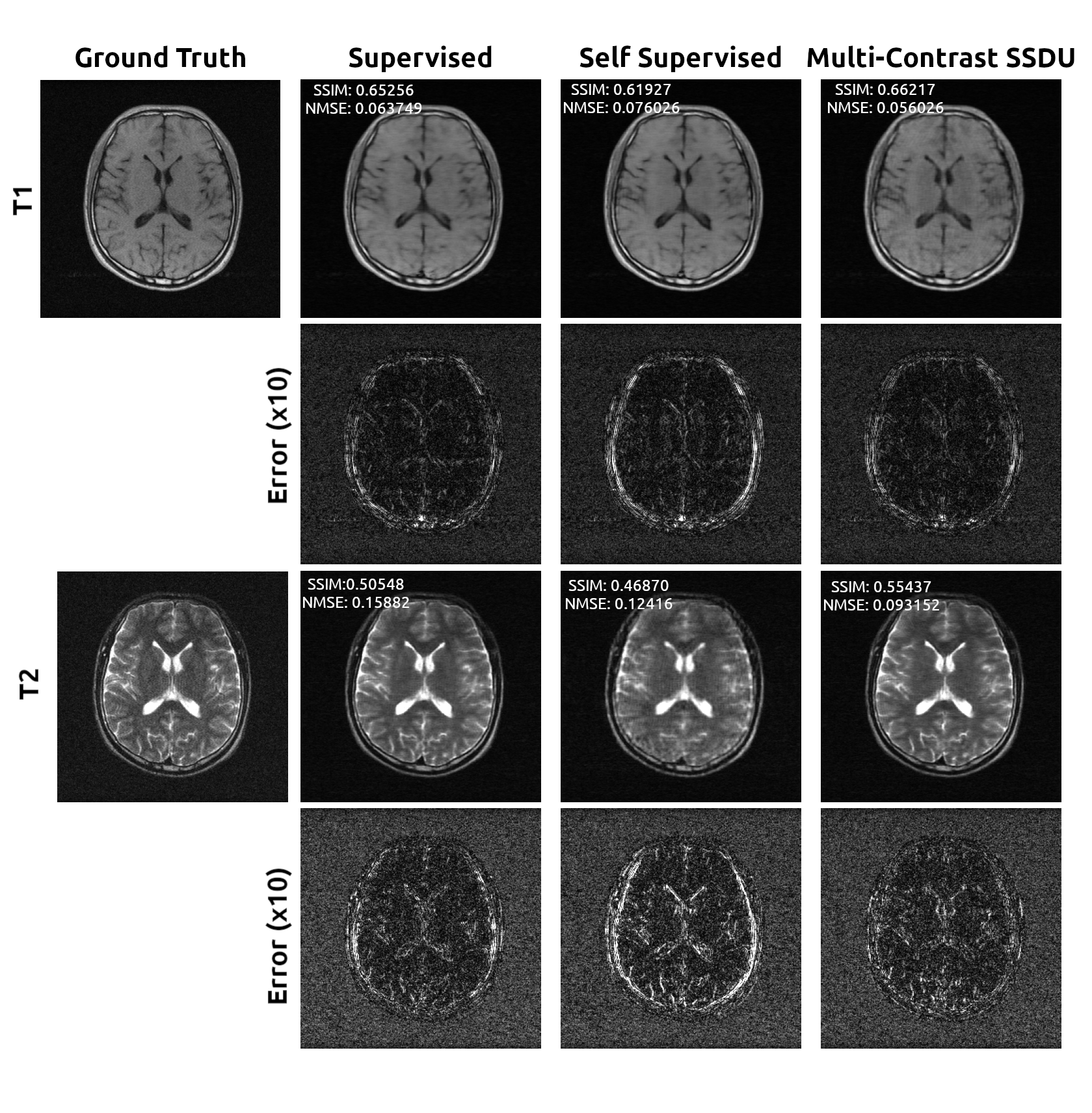
Figure 2 shows that multi-contrast SSDU improves the MSE and SSIM of self-supervised reconstruction across a range of acceleration factors compared to single-contrast approaches. At high acceleration factors, there is a greater discrepancy between multi- and single-contrast SSDU fidelity shown in Figure 3. In all cases, error map distributions are similar, but joint multi-contrast SSDU has lower peak errors and reduced aliasing errors. In Figure 4 we trained joint multi-contrasts SSDU models with all combinations of 2, 3, or all 4 contrasts to study the impact of the number of input contrasts. Image fidelity monotonically increases with the number of contrasts used. The proposed multi-contrast SSDU method additionally achieves high-quality image restoration on actual, acquired low-SNR k-space data shown in figure 5.Discussion and Conclusions
We show that joint multi-contrast SSDU reconstruction improves reconstruction fidelity over single-contrast SSDU. At high acceleration factors, multi-contrast SSDU performs better than supervised single-contrast methods, highlighting the benefit of sharing information across scans or contrasts in self-supervised methods. This approach can be used to improve diagnostic quality or acceleration of multi-contrast imaging protocols without the need for fully-sampled training data.Future work will explore optimized multi-contrast network architectures and inter-contrast sampling patterns for self-supervised multi-contrast image reconstruction, as well as accommodating for inter-scan misalignment and unmatched image resolutions.
Acknowledgements
This work was supported in part by NSERC, Canada research chairs program, and the UK EPSRC.References
1. Sriram, A. et al. End-to-End Variational Networks for Accelerated MRI Reconstruction. Preprint at http://arxiv.org/abs/2004.06688 (2020).
2. Yang, Y., Sun, J., Li, H. & Xu, Z. ADMM-Net: A Deep Learning Approach for Compressive Sensing MRI. Preprint at http://arxiv.org/abs/1705.06869 (2017).
3. Aggarwal, H. K., Mani, M. P. & Jacob, M. MoDL: Model Based Deep Learning Architecture for Inverse Problems. IEEE Trans. Med. Imaging 38, 394–405 (2019).
4. Yaman, B. et al. Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data. Magn. Reson. Med. 84, 3172–3191 (2020).
5. Yaman, B. et al. Multi-mask self-supervised learning for physics-guided neural networks in highly accelerated magnetic resonance imaging. NMR Biomed. 35, e4798 (2022).
6. Sun, L. et al. A Deep Information Sharing Network for Multi-Contrast Compressed Sensing MRI Reconstruction. IEEE Trans. Image Process. 28, 6141–6153 (2019).
7. Xiang, L. et al. Deep-Learning-Based Multi-Modal Fusion for Fast MR Reconstruction. IEEE Trans. Biomed. Eng. 66, 2105–2114 (2019).
8. Zhou, B. et al. DSFormer: A Dual-domain Self-supervised Transformer for Accelerated Multi-contrast MRI Reconstruction. in 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 4955–4964 (IEEE, 2023). doi:10.1109/WACV56688.2023.00494.
9. Baid, U. et al. The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification. Preprint at http://arxiv.org/abs/2107.02314 (2021).
10. Lyu, M. et al. M4Raw: A multi-contrast, multi-repetition, multi-channel MRI k-space dataset for low-field MRI research. Sci. Data 10, 264 (2023).
11. Hammernik, K. et al. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 79, 3055–3071 (2018).
12. Millard, C. & Chiew, M. A Theoretical Framework for Self-Supervised MR Image Reconstruction Using Sub-Sampling via Variable Density Noisier2Noise. IEEE Trans. Comput. Imaging 9, 707–720 (2023).
13. Wang, Z., Simoncelli, E. P. & Bovik, A. C. Multiscale structural similarity for image quality assessment. in The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003 1398–1402 (IEEE, 2003). doi:10.1109/ACSSC.2003.1292216.
Figures