1764
Multi-Contrast Low-field MR Image Enhancement via Self-supervision1Subtle Medical, Menlo Park, CA, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Low-Field MRI
Motivation: Restoring the structure that is barely visible on the MR images is a major challenge for self supervised enhancement using one input, especially in low-field MR imaging applications.
Goal(s): To improve the image quality and the visibility of some clinically relevant structure in certain contrast in MR images
Approach: We proposed a self-supervised learning framework using the shareable information from other image contrasts. More specifically, two mutual modulations with a cyclic consistency constraint are introduced to guide the training.
Results: Preliminary results on 0.25T spine MR images suggest that our method can achieve superior results compared to other self-supervised methods.
Impact: The work shows the feasibility of adopting the multiple contrast information to improve the MR images with poor quality without acquiring low resolution/high resolution pairs. It leads to more accurate diagnoses.
Introduction
Self-supervised methods can improve image quality without acquiring paired high-quality and low-quality training data. However, most self-supervised learning methods are based on single image modality/contrast, and when the structural information is not fully acquired, it is hard to accurately recover those structures to a similar level as shown in the clinical standard image. This limitation is more pronounced for the low-field MR image enhancement when the structure is hardly visible in the acquired image. Inspired by the mutual modulation super-resolution (MMSR)1, we utilize the shareable information across multiple image modalities/contrasts to improve the low-field MR image quality in a self-supervised manner.Methods
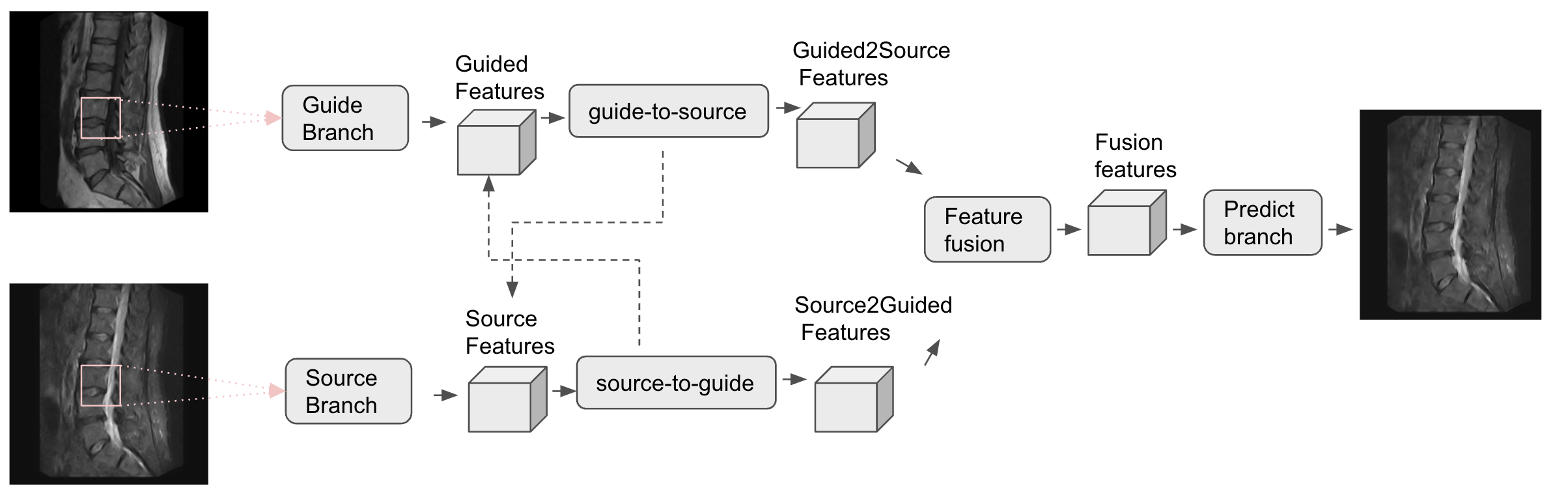
The proposed methods were validated on 0.25T spine MR cases. Specifically, we used sagittal T1 and/or sagittal T2 as the guide image and low-resolution sagittal STIR as the source image for sagittal STIR super-resolution image enhancement. Image registration using SimpleElastix2 was applied as a pre-processing step to align both sagittal T1 and T2 with the sagittal STIR. The guide images were interpolated to 512x512, while the source images were interpolated to 256x256. The target STIR image shape is 512x512 (i.e., 2x super-resolution in each dimension). The acquisition matrix for the T1, T2, and STIR images corresponds to 256x248, 320x238, 256x208, respectively.Self-supervised framework. The source and guide images are passed through two separate feature extraction branches each consisting of three residual blocks. The network has two mutual modulations: the source-to-guide, and the guide-to-source. The source-to-guide module aims to upscale the spatial resolution of source image features learned from the guide images, while the guide-to-source module aims to align the guide image contrast-related features with the source image. A 1x1 convolution kernel is applied to fuse the two output features from the mutual modulations. The optimization function minimizes the L1 loss between the 2x downsampled synthetic high-resolution STIR and the low-resolution input STIR for self-supervised learning. Also, this optimization process enforces the source image to achieve similar spatial resolution as guide images (sagittal T1 or sagittal T2) without changing the contrast of the source images. The detailed framework can be found in Figure 1. The model was trained with PyTorch on an NVIDIA V100 GPU for 700 epochs.
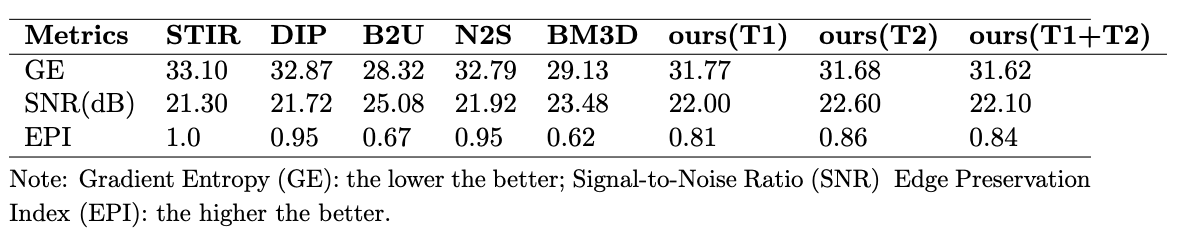
Evaluation metrics. Given the whole process is based on the acquired low-field MR cases without ground truth, some non-reference metrics were applied to evaluate the image quality, including the gradient entropy (GE)3 to measure the sharpness of the images, the signal to noise ratio (SNR) to measure the noise level. A reference-based metric, the edge preservation index (EPI)4, is also used to measure the preservation on the edge with the acquired STIR. We compared our results with other traditional and self-supervised methods, including BM3D5, deep image prior (DIP)6, noise2self (N2S)7, Blind2Unblind (B2U)8.
Results
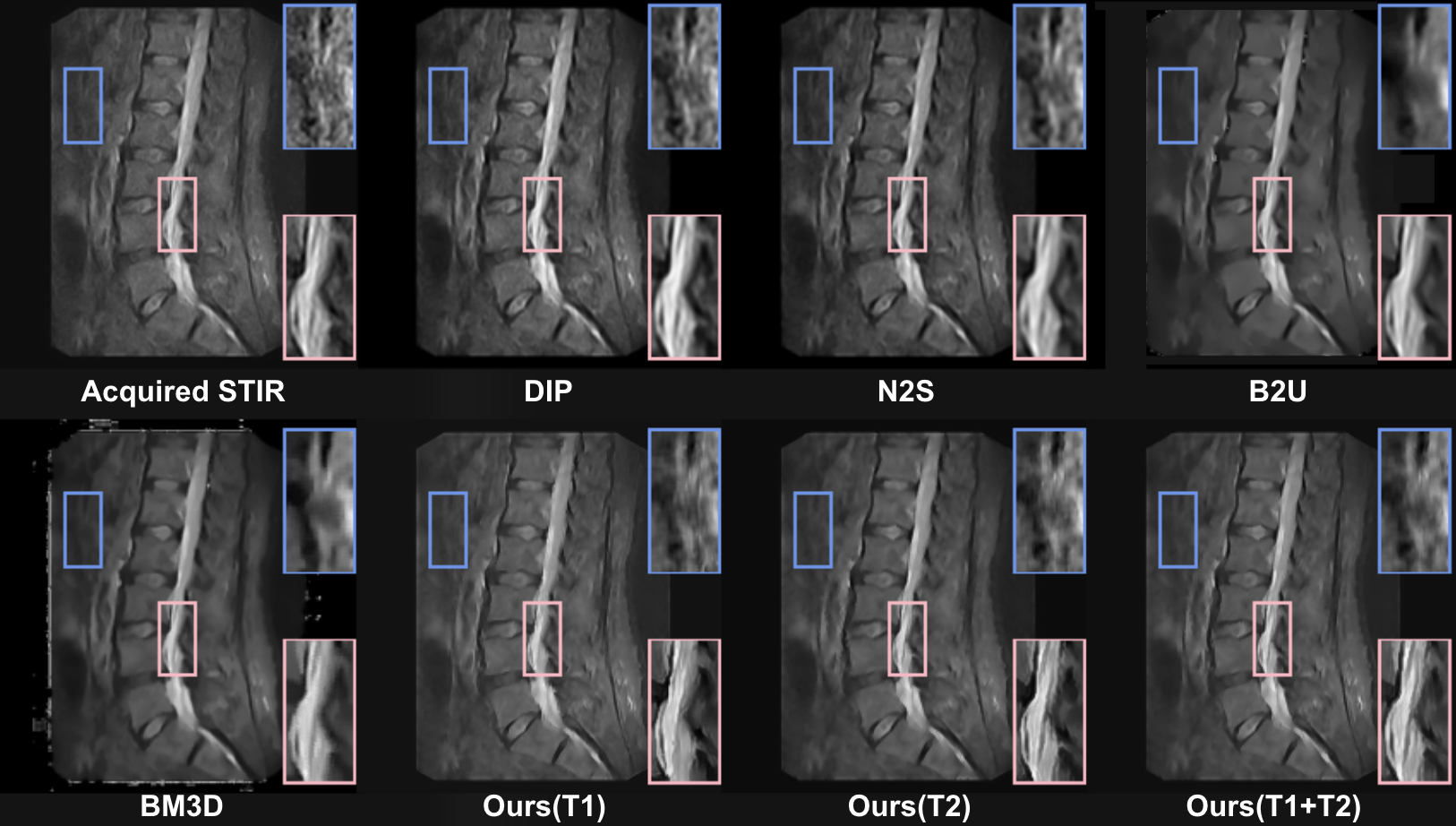
All results are shown in Figure 2. The STIRs after B2U and BM3D show a pattern of over-smoothing(the top right zoomed area), which might lead to missing pathologies. On the other hand, the STIRs after N2S and DIP have some blurriness around the boundary(the lower right zoomed area). Similar trends can be observed in Table 1. Although the results from B2U and BM3D have the highest SNR, their EPI scores are the lowest, while for DIP and N2S, the images have high EPI but little improvement in SNR.Discussion
The results from our framework show the best tradeoff between edge enhancement and noise suppression. Also, the enhancement performance varies under different guided images. Overall, guided using both T1 and T2 achieves the best scores on metrics, followed by the image guided by T2 only. The metrics agree with the visual evaluation from Figure 2. The spinal cord roots (the lower right zoomed area) are more distinguishable in the inference results guided by using concatenated T1 and T2 or T2 only. Due to the higher acquisition matrix of T2 than T1, utilizing a higher-resolution image for guidance would result in better performance.Conclusion
In this study, we utilized a self-supervised learning framework for multi-contrast MR image enhancement and assessed its performance under various metrics. The results demonstrate its effectiveness on low-field spine MR images. Also, the enhancement performance can be boosted by using more (particularly high-resolution) images as guidance.Acknowledgements
No acknowledgement found.References
1. Xiaoyu Dong, Naoto Yokoya, Longguang Wang, and Tatsumi Uezato. Learning mutual modulation for self-supervised cross-modal super-resolution. In ECCV, 2022.
2. Kasper Marstal, Floris Berendsen, Marius Staring, and Stefan Klein. Simpleelastix: A user-friendly, multi-lingual library for medical image registration. In 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 574–582, 2016.doi: 10.1109/CVPRW.2016.78.
3. WF Good, JH Sumkin, N Dash, CM Johns, ML Zuley, HE Rockette, and D Gur. Observer sensitivity to small differences: a multipoint rank order experiment. AJR Am JRoentgenol, 173(2):275–278, 1999.
4. Tingting Liu, Ning Ye, Ke Li, and Lei Wang. Blind image quality assessment using semi-supervised rectifier networks. IEEE Transactions on Image Processing, 22(8):3114–3125,2013.
5. Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Color image denoising via sparse 3d collaborative filtering with grouping constraint in luminance-chrominance space. IEEE transactions on image processing, 16(8):2080–2095, 2007.
6. Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep image prior. arXiv preprint arXiv:1711.10925, 2018.4
7. Joshua Batson and Loic Royer. Noise2self: Learning image restoration without knowing noise distribution. In International Conference on Learning Representations, 2019
8. Tingting Liu, Ning Ye, Ke Li, and Lei Wang. Blind image quality assessment using semi-supervised rectifier networks. IEEE Transactions on Image Processing, 22(8):3114–3125,2013.
Figures