1763
Pretraining using masked language modeling improves label noise robustness on the metadata standardization task1Subtle Medical Inc., Menlo Park, CA, United States
Synopsis
Keywords: Data Processing, Software Tools
Motivation: The lack of standardization in MRI metadata increases radiologist workload.
Goal(s): To demonstrate an approach to standardize the image contrast and the body part examined information in the DICOM header and to understand the benefits of self-supervised pretraining on the metadata standardization task in the presence of label noise.
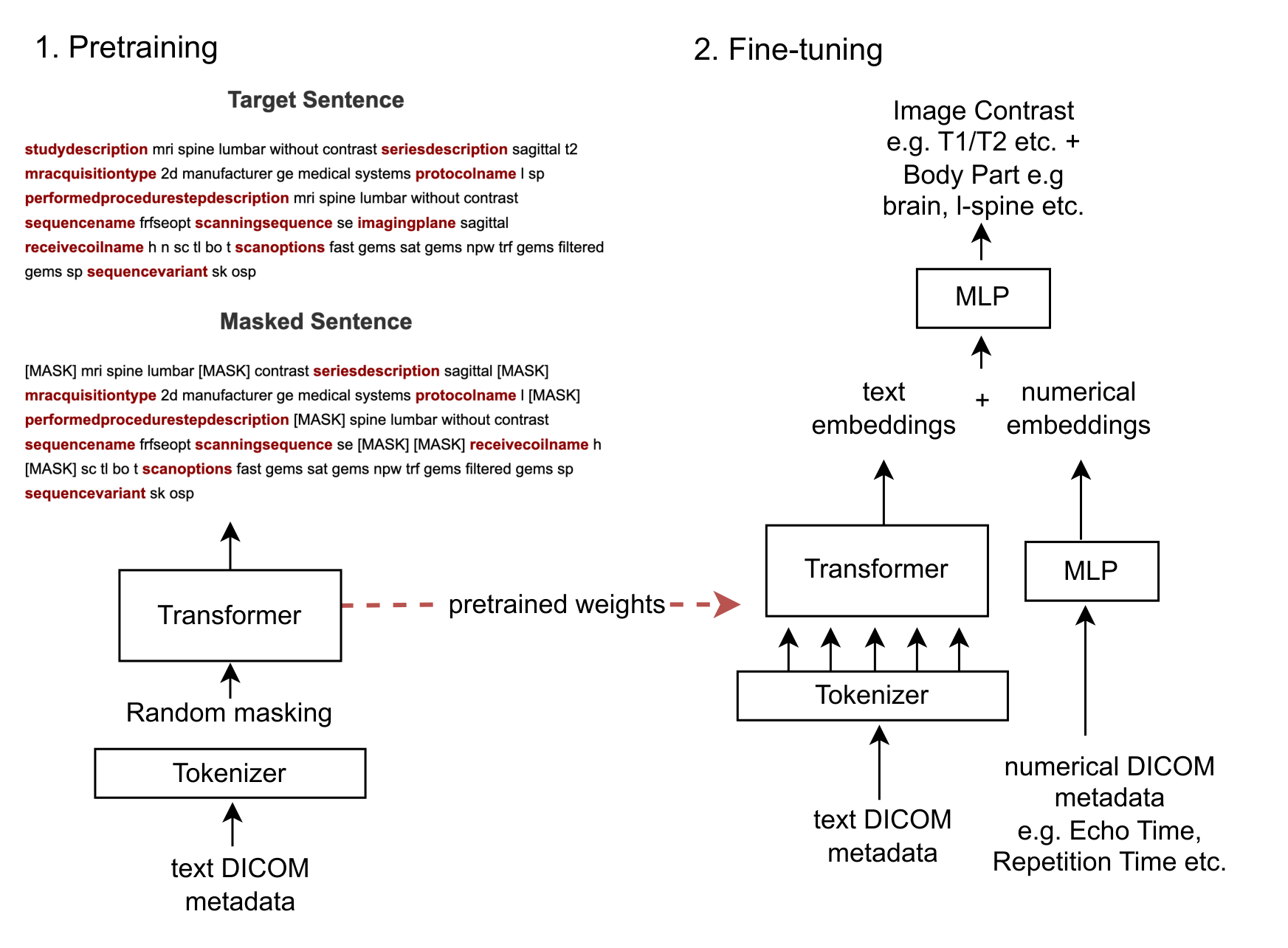
Approach: Masked language modeling was used for pretraining. At the fine-tuning stage, a transformer model was used to predict the image contrast and body part from both the text and numerical DICOM tags.
Results: Pretraining improves robustness to label noise, with there being no loss in performance at 20% label noise.
Impact: Pretraining using masked language modeling is effective at rendering a metadata stanardization system robust to label noise. Such a system can be used to standardize MRI metadata and therefore reduce radiologist workload. Future work should investigate class conditional label noise.
Introduction
The lack of standardization in MRI metadata increases radiologist workload and causes major issues for downstream data analyses. In this study, we demonstrate an end-to-end supervised learning approach that can standardize the image contrast and the body part examined information in the DICOM header using only the DICOM header as the input. One of the major difficulties in building such a system is the need for a large and diverse set of labeled data. In order to alleviate this labeling burden, we hypothesize that self-supervised pretraining will enable few-shot learning or learning with noisy labels generated from preexisting tools. To examine whether such a strategy is feasible, we employ the masked language modeling (MLM) technique, which has frequently been used for pretraining large language models such as BERT [1], and examine whether this results in improved performance across a range of label noise levels compared to training from scratch.Methods
To leverage both the numerical data and text data included in the DICOM header, the text data need to be converted to vector embeddings prior to being fed to the classification layers. To generate these embeddings, a 6-layer encoder-only transformer model with an embedding dimensionality of 512, hidden layer dimensionality of 1024 and 8 attention heads was used. The input to the transformer network was the integer value tokens generated using byte-pair encoding tokenization. For pretraining, the target outputs were the ground-truth (unmasked) tokens. For fine-tuning, the text embeddings and numerical embeddings were concatenated and fed to a 2-layer fully connected network (Fig. 1).Data for this study were derived from in-house sources and included 27 different body part classes: brain, lspine, tspine, cspine, tlspine, knee, ankle, shoulder, pelvis, abdomen, breast, neck, elbow, hand, foot, wrist, hip, orbit, prostate, brachial plexus, leg, carotid, finger, pituitary, iac, chest and arm. As well as 17 image contrast categories: T1, T1+C, T2, T2*, T2FLAIR, PD, STIR, DWI, ADC, localizer, calibration, ASL, perfusion, SSFP, SWI, MRA and fMRI.
A total of n=464,284 unlabeled DICOM series were used for MLM pretraining. Manually labeled data were used for fine-tuning on the sequence and body part tasks. This consisted of n=21,646/2,406/2,974 (train/valid/test) DICOM series for the image contrast task and n=14,928/1,660/3,693 for the body part prediction task. The training data were labeled in a semi-automated fashion using regular expressions and manual corrections, whereas the test data was labeled with care to ensure the validity of the results. The pixel data were used as the ground truth instead of the metadata. To investigate the effect of label noise on model performance, a proportion of training labels was randomly assigned to an incorrect class label.
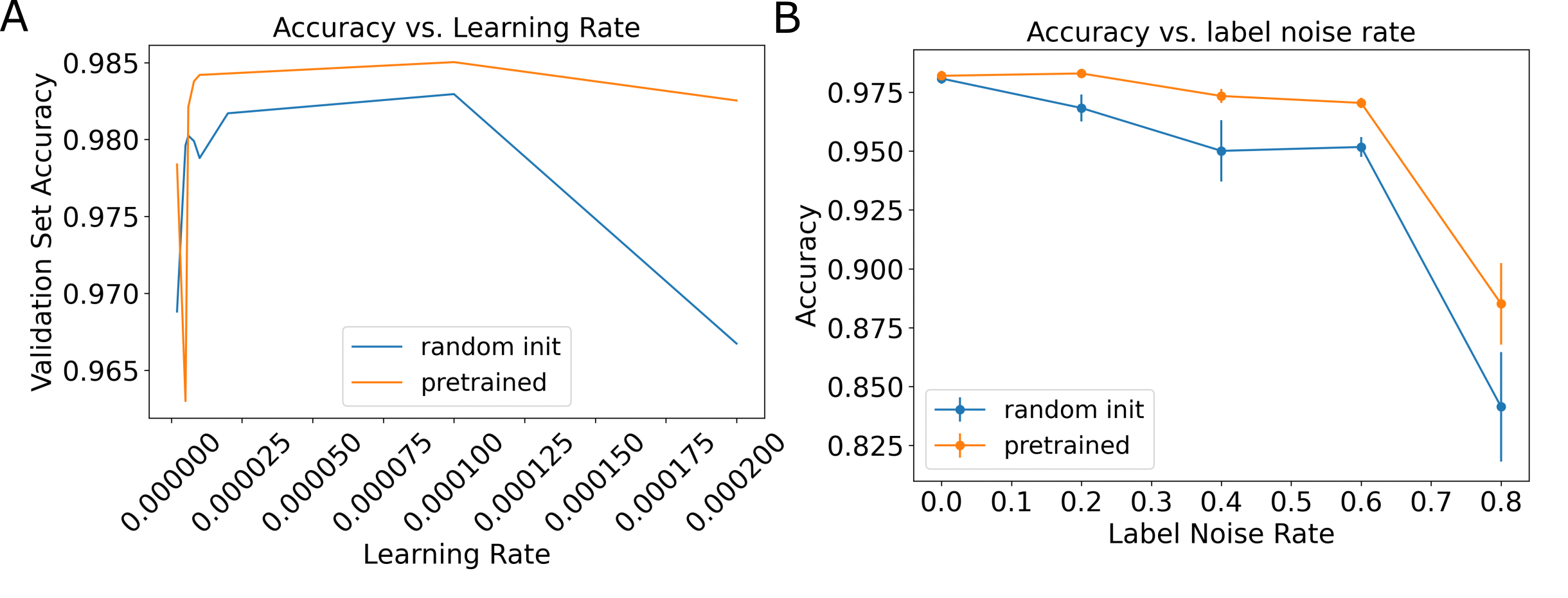
To make a fair comparison between random initialization and pretraining, we optimized the learning rate via grid search on the validation set, using accuracy as the evaluation metric for both tasks.
Results
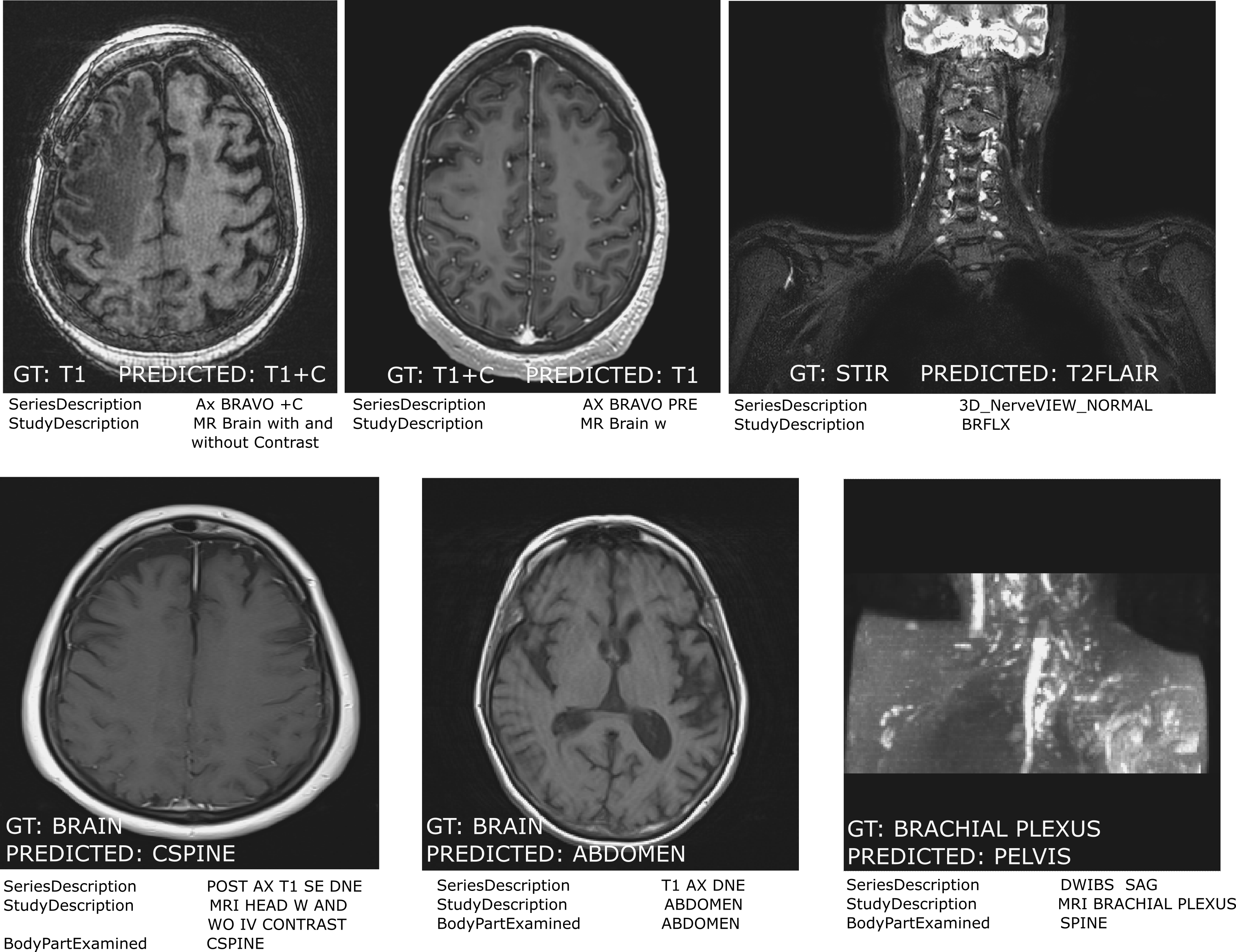
It was hypothesized that the optimal learning rate would differ between the random initialized model and the pretrained model. Evidence suggested that this was not the case and pretraining proved to be robust across a wide range of learning rates. For the image contrast prediction task, pretrained models outperformed the randomly initialized models on the validation set across a broad range of learning rates (Fig. 2A). On the test dataset (Fig. 2B), the pretrained models only modestly outperformed the randomly initialized model at the zero label noise level with accuracies of 98.2% and 98.1% respectively. However, pretraining made the models significantly more robust to label noise and the performance did not fall below the noise free performance at the label noise fraction of 0.2., which was not the case for random initialization, which dropped to 97%. Where misclassifications occurred, this was sometimes because the metadata itself was incorrect e.g. it incorrectly indicated the presence or absence of contrast agent or because of specialist sequences that were not part of the training data (Fig. 3).On the body part prediction task, there were no significant differences in performance between pretrained models and randomly initialized ones. The performance on this task was higher with an accuracy of 99.7%. Misclassification errors also occurred because the ground-truth was labeled based on the pixel data and the metadata itself was incorrect or for classes where there were few training examples.
Conclusions
Pretraining using masked language modeling is highly effective at rendering a metadata classification system robust to label noise. Such a system can be used to standardize MRI metadata and therefore reduce radiologist workload. Here, the label noise was assigned independently. Future work should investigate class conditional label noise.Acknowledgements
No acknowledgement found.References
1. Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).Figures