1752
Cardiac Cine MRI Super-Resolution based on Diffusion Models1School of Biomedical Engineering, Shanghai Tech University, Shanghai, China, 2Shanghai Clinical Research and Trial Center, Shanghai, China
Synopsis
Keywords: AI Diffusion Models, Machine Learning/Artificial Intelligence
Motivation: Cardiac cine MRI requires multiple breath-holds to cover the left ventricle. Acquiring images of small matrix size effectively reduces acquisition time but causes a loss of spatial details.
Goal(s): To further research on the application of diffusion models in accelerating Cardiac cine MRI.
Approach: A diffusion model was constructed to achieve super-resolution of cardiac cine MRI to restore lost details in low-resolution images.
Results: The proposed diffusion model based super-resolution method can recover high-frequency details for cardiac cine MRI and outperformed the state-of-the-art generative adversarial super-resolution network.
Impact: The proposed method yielding good-quality cardiac cine images from low-resolution images helps to accelerate cardiac cine MRI and could be potentially applied to achieve high spatial-temporal real-time cardiac MRI.
Introduction
Cardiac cine MRI is the standard technique for quantitative evaluation of cardiac function, which is commonly acquired under breath-holding. Due to limited breath-hold durations, multiple breath-holds are required to cover the whole left ventricle, leading to patients discomfort and prolonged acquisition times. Accelerating cardiac cine MRI is an active research area, where a number of deep learning (DL) methods have been developed, including DL reconstruction and super-resolution (SR), which respectively achieves acceleration by undersampling or acquiring small data matrix. Notably, recent studies [1, 6] showed the feasibility of convolutional neural-network (CNN) or generative adversarial network (GAN) based cardiac cine SR. However, CNN tends to generate blurring images and GAN may introduce hallucinations [1]. Diffusion Models have demonstrated remarkable results in image generation, outperforming GAN in generation quality. However, its application to Cardiac cine SR remains to be investigated. This study explored the feasibility of Denoising Diffusion Implicit Models (DDIM) [2] for Cardiac cine MRI SR and compared its performance with a state-of-the-art GAN SR method, ESRGAN [1].Method
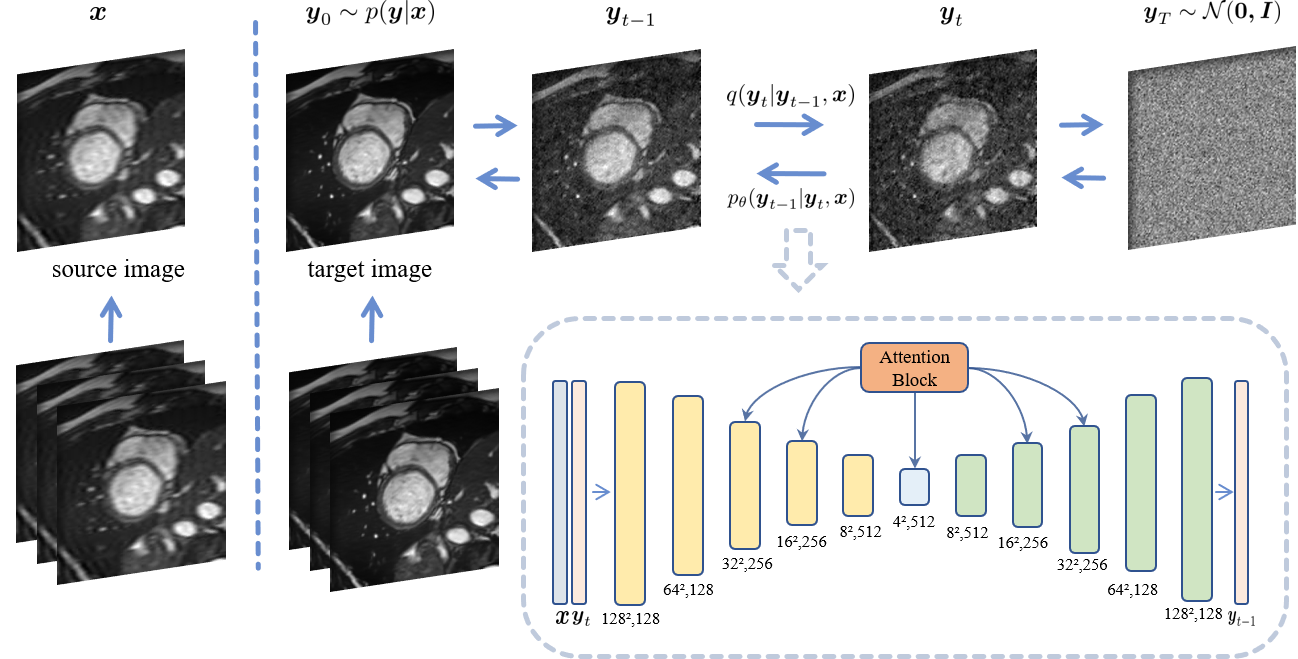
Conditional DDIM:As shown in Fig. 1, given the source low-spatial-resolution and target high-spatial-resolution image pairs $$$\{x_{i}, y_{i}\}_{i=1}^{N}$$$, the SR DDIM is designed to recover $$$y$$$ from $$$x$$$. In the forward diffusion process, the target image $$$y$$$ is gradually disturbed to a Gaussian noise: $$$y_{0} \rightarrow y_{T}, y_{T}\sim\mathcal{N}(0,I)$$$. In order to introduce a dependency on the source image, $$$x$$$ is utilized as an additional input of the denoising network during the reverse sampling process for conditional DDIM. Specifically, the following steps are iteratively performed in the reverse diffusion process until $$$t \rightarrow 0$$$: at a timestep $$$t$$$, the target image $$$\hat{y}_t$$$ is estimated and concatenated with the source image $$$x$$$ in the channel dimension, serving as the input of the denoising U-Net to obtain the corresponding next-level noisy target image $$$\hat{y}_{t-1}$$$. The backbone denoising network is an attention U-Net [2,3,4].
Dataset:
We conducted experiments on the public ACDC dataset [7], with 100 subjects for training and 50 subjects for testing. The cardiac cine MRI of each subject contains 10-15 slices and 15 to 30 frames per slice. To generate high-spatial-resolution and low-spatial-resolution image pairs for training. The low-spatial-resolution images were synthesized by discarding 75%–80% of outer phase-encoding lines of the corresponding k-space of the high-spatial-resolution images, while keeping data in the readout direction.
Implementation Details:
The super-resolution with DDIM is applied to each cine frame separately, in line with the baseline method, ESRGAN [1]. DDIM was trained via Adam optimizer on an A6000 GPU, with the following settings: training epochs=100, batch size=8, diffusion steps=2000, inference steps=100.
Results
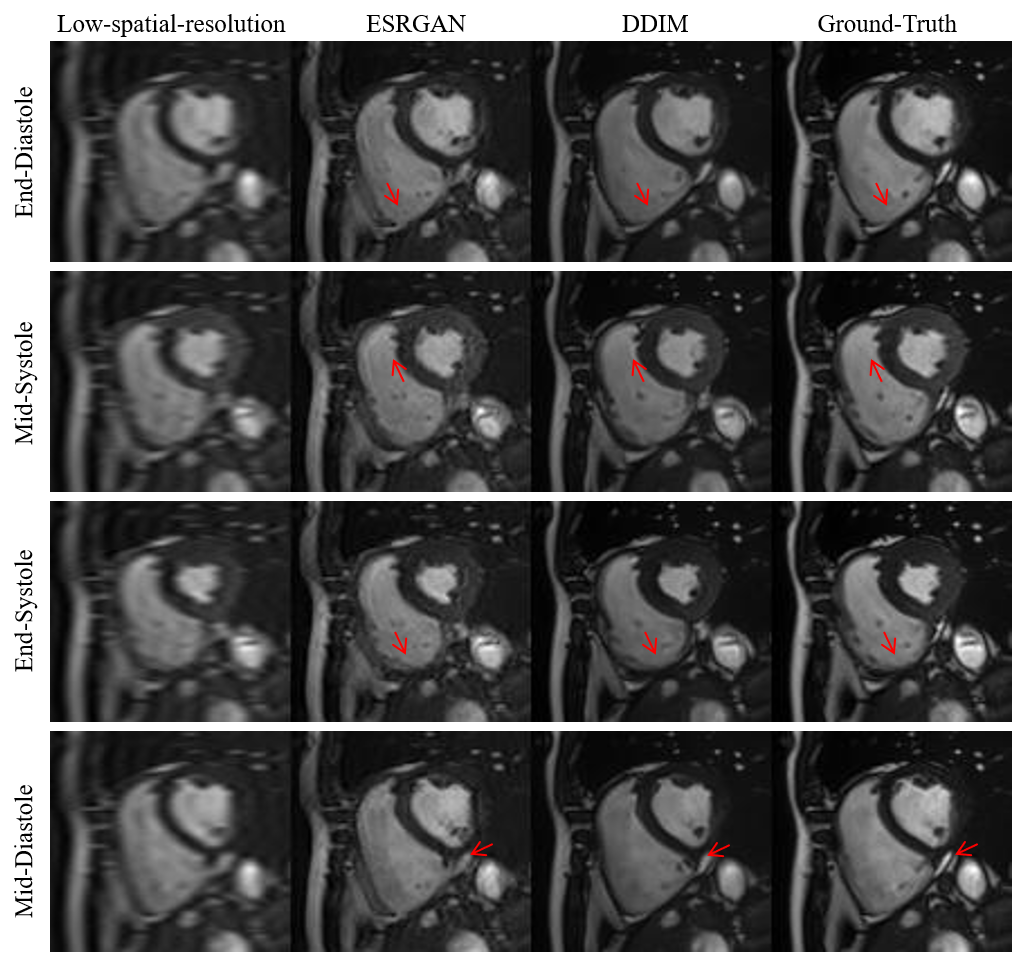
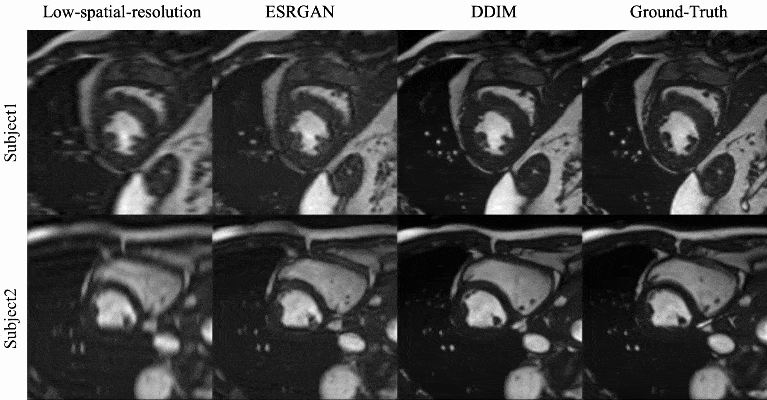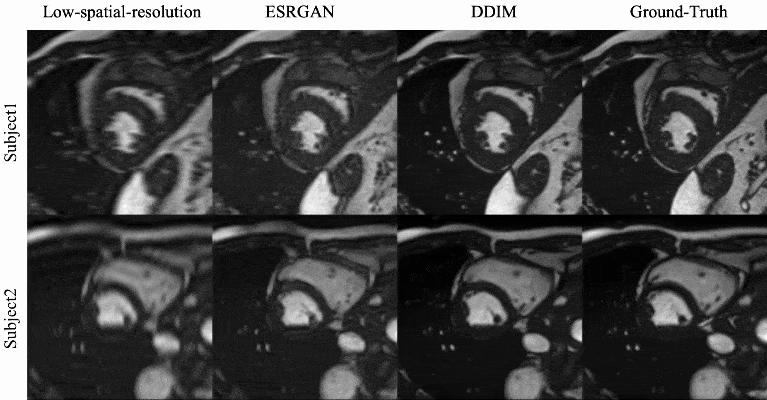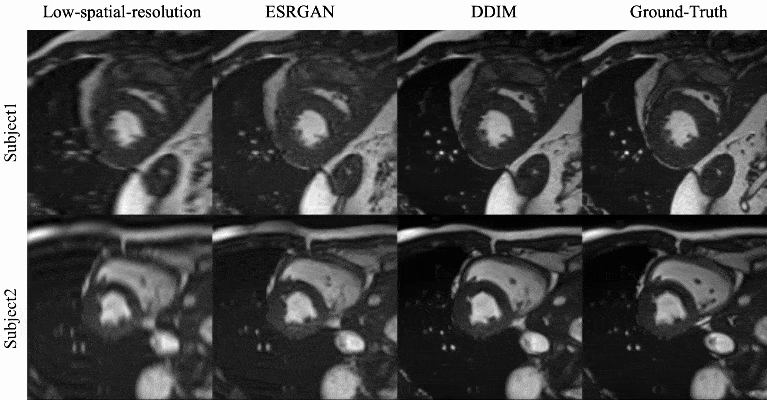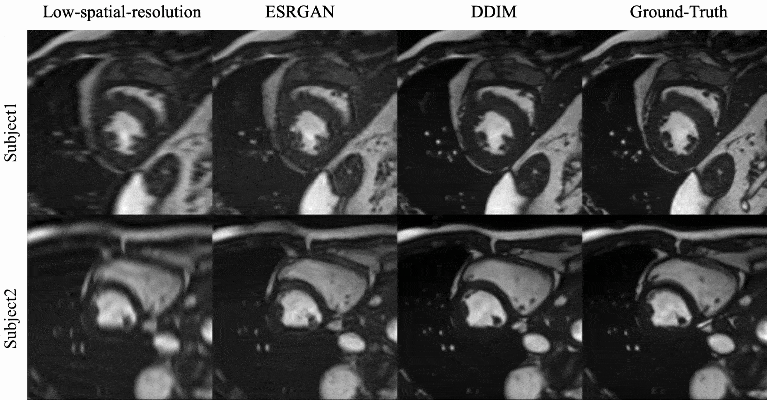
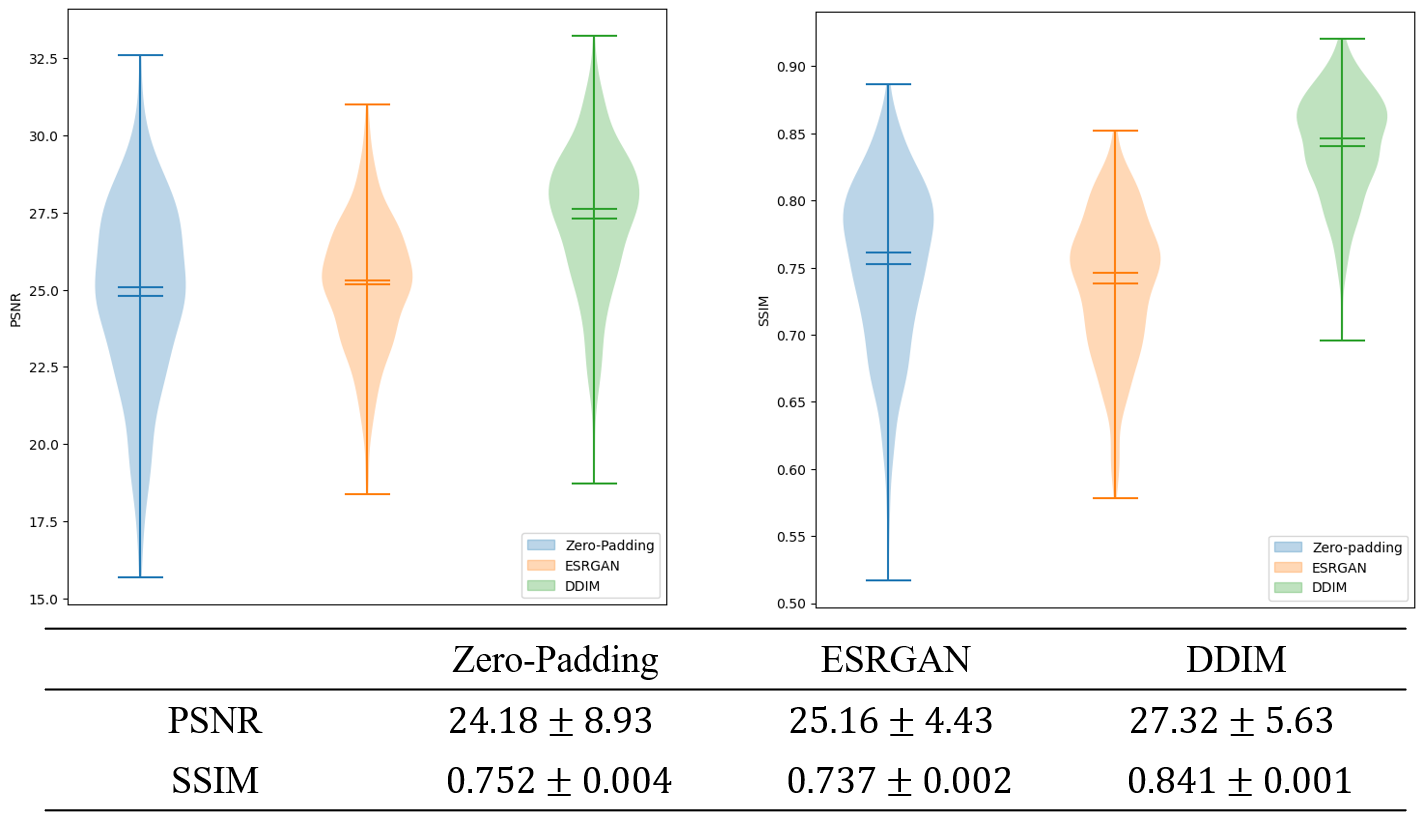
Qualitative evaluation: Figure 2 shows example SR results with ESRGAN and the proposed DDIM for four different cardiac phases. Compared with the low-spatial resolution image, both SR methods are able to add spatial details, with SR DDIM outperforming ESRGAN in producing high-spatial images more consistent with the original full-spatial-resolution image. The dynamic cardiac cine images for two subjects are shown in Fig. 3, where the superior SR performance can be observed for the proposed DDIM.Quantitative evaluation: The PSNR and SSIM of the low-spatial-resolution images, and the SR images with ESRGAN and DDIM are compared in Fig. 4. The metrics of DDIM are significantly higher than ESRGAN.
Discussion and Conclusions
In this study, we demonstrated the feasibility of diffusion models for cardiac cine MRI super-resolution. The distribution of the high-resolution images, conditioned on low-resolution images, is learned during the forward diffusion process and then utilized to super-resolve the source images in the reverse diffusion process. The SR DDIM outperformed the baseline ESRGAN in generating more realistic image details. This may be attributed to the fact that diffusion models are capable of not only enhancing the clarity of the image by sharpening it, but also generating image details through distribution learning, which is unattainable by the GAN method. However, it is noted that the generation speed of DDIM is much lower than GAN. In the future work, we will focus on accelerating the diffusion sampling process and taking advantage of the temporal information across the cine frames to further improve the SR performance.Acknowledgements
No acknowledgement found.References
[1]S. Yoon et al., “Accelerated Cardiac MRI Cine with Use of Resolution Enhancement Generative Adversarial Inline Neural Network,” Radiology, vol. 307, no. 5, p. e222878, Jun. 2023, doi: 10.1148/radiol.222878.
[2]J. Song, C. Meng, and S. Ermon, “Denoising Diffusion Implicit Models.” arXiv, Oct. 05, 2022. Accessed: Jul. 14, 2023. [Online]. Available: http://arxiv.org/abs/2010.02502
[3]J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models.” arXiv, Dec. 16, 2020. Accessed: Mar. 01, 2023. [Online]. Available: http://arxiv.org/abs/2006.11239
[4]P. Dhariwal and A. Nichol, “Diffusion Models Beat GANs on Image Synthesis.” arXiv, Jun. 01, 2021. Accessed: Jun. 03, 2023. [Online]. Available: http://arxiv.org/abs/2105.05233
[5]Z. Wu, X. Chen, S. Xie, J. Shen, and Y. Zeng, “Super-resolution of brain MRI images based on denoising diffusion probabilistic model,” Biomedical Signal Processing and Control, vol. 85, p. 104901, Aug. 2023, doi: 10.1016/j.bspc.2023.104901.
[6]E. M. Masutani, N. Bahrami, and A. Hsiao, “Deep Learning Single-Frame and Multiframe Super-Resolution for Cardiac MRI,” Radiology, vol. 295, no. 3, pp. 552–561, Jun. 2020, doi: 10.1148/radiol.2020192173.
[7] O. Bernard et al., "Deep Learning Techniques for Automatic MRI Cardiac Multi-Structures Segmentation and Diagnosis: Is the Problem Solved?," in IEEE Transactions on Medical Imaging, vol. 37, no. 11, pp. 2514-2525, Nov. 2018, doi: 10.1109/TMI.2018.2837502.
Figures