1751
TDI-Conditioned Diffusion Model for Resolution Enhancement of Diffusion-Weighted Images1School of Computer Science and Technolog, Heilongjiang University, Harbin, China, 2School of Information and Technology, Northwest University, Xi'an, China, 3Imperial-X and Department of Computing, Imperial College London, London, United Kingdom, 4School of Computer Science and Engineering, Northwestern Polytechnical University, Xi'an, China
Synopsis
Keywords: AI Diffusion Models, Diffusion/other diffusion imaging techniques
Motivation: Diffusion-Weighted Imaging (DWI) suffers from low resolution. Post-acquisition super-resolution can effectively enhance the resolution of DWIs.
Goal(s): We propose a novel post-acquisition DWI super-resolution method based on the conditioned diffusion model.
Approach: We design an effective condition based on Track Density Imaging (TDI), which contains rich high-resolution information. Furthermore, we consider low-resolution DWIs as another condition to preserve the original information of images.
Results: Extensive experiments on HCP data show that our model is effective in DWI super-resolution and outperforms the cutting-edge models.
Impact: To enhance the resolution of DWIs, we propose a super-resolution method based on conditioned diffusion model. This is beneficial to the clinical practice of DWI.
Purpose
Post-acquisition super-resolution acts as an effective solution to enhance the resolution of Diffusion-Weighted Images (DWIs). As an advanced generative model, the Diffusion Model (DM) shows particularly promising performance in the resolution enhancement of natural images, but has not been employed for DWI super-resolution yet. To this end, we propose a novel conditioned DM for post-acquisition DWI super-resolution. Our model, called TCDM, consists of two effective conditions. One is based on the Track Density Imaging (TDI), which contains rich high-resolution information, and another is based on low-resolution DWIs, which contain vital image original information. Based on the HCP data, we conduct extensive experiments to demonstrate that our model outperforms cutting-edge DWI super-resolution methods.Methods
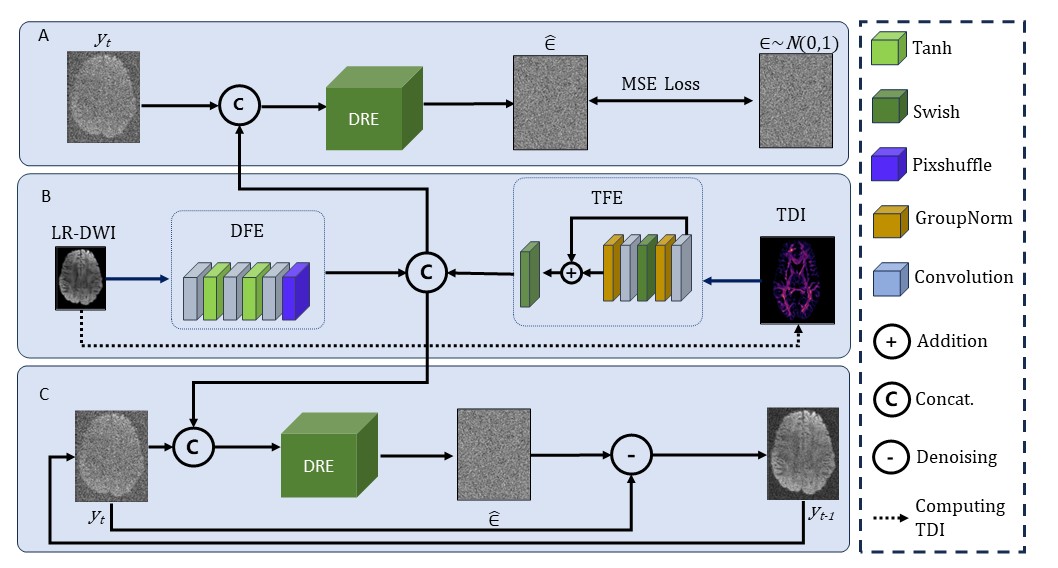
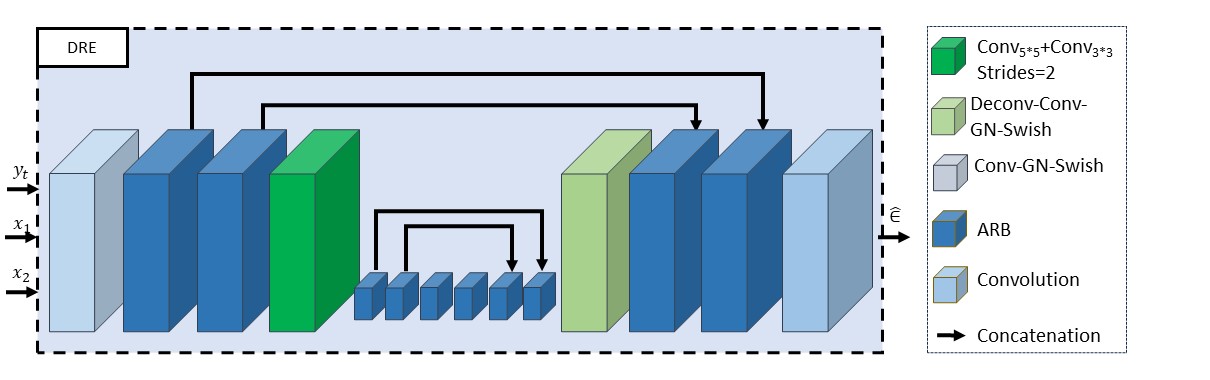
In our TCDM (Fig. 1), a low-resolution DWI $$$x_1$$$is input into the DWI Feature Extractor (DFE) to obtain the DWI feature map, while a TDI map $$$x_2$$$ is input into the TDI Feature Extractor (TFE) to obtain the TDI feature map. Next, two feature maps are fused with the high-resolution DWI $$$y_t $$$ that has been diffused for $$$t $$$ steps, and then input into DWI Resolution Enhancer (DRE) to obtain the Gaussian noise added in the previous step of diffusion:$$\epsilon_t=TCDM_\theta(x_1,x_2,y_t,t)$$
Based on DDIM [3], we define the training objective function as follows:
$$E(\epsilon,\epsilon_t)=\|TCDM_\theta(x_1,x_2,y_t,t)\|^2$$
where $$$\epsilon$$$ denotes standard normal distribution, $$$\|\cdot\|^2$$$ is the mean square error, and $$$\theta$$$ is the weight of neural network parameters. This noise is subtracted from the DWI that has been diffused for t steps to obtain the DWI at the previous step. This procedure is interactively performed and generates the high-resolution DWI without noise at the final step.
Result
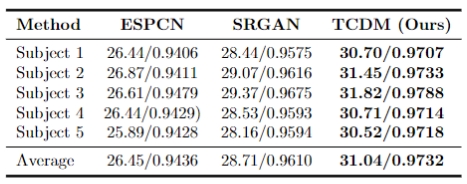
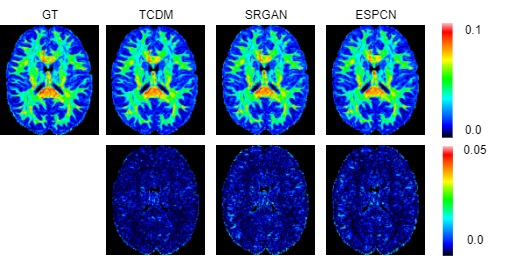
Dataset: The dataset utilized in our study originates from the Human Connectome Project (HCP). Ten subjects were used as the training set and five subjects were used as the testing set. Data preprocessing is detailed as follows: The $$$b_0$$$ image was used for normalization, the mask file was used for skull removal, and the data was cropped to $$$112\times144\times112$$$ as high-resolution DWI. The low-resolution DWI was obtained by averaging the neighboring voxels in the DWI, and was converted to TDI using MRTrix3 software. High-resolution DWIs are used as ground truth for evaluation.Experimental Results: We compare our model with state-of-the-art methods, including ESPCN [4] and SRGAN [5]. The PSNR and SSIM results, shown in Fig. 3, indicate that our model outperforms the state-of-the-art super-resolution methods. The Fractional Anisotropy (FA) images and associated error map, shown in Fig. 4, further demonstrate that our method achieves the best super-resolution performance.
Conclusion
We propose the first DM-based deep learning model for DWI super-resolution. Extensive experiments on HCP data demonstrate the effectiveness of the proposed model, both qualitatively and quantitatively.Acknowledgements
This work is supported in part by the National Natural Science Foundation project (62201465) and Heilongjiang Provincial Natural Science Foundation project (LH2021F046).References
[1] Essayed, W.I., Zhang, F., Unadkat, P., Cosgrove, G.R., Golby, A.J., O’Donnell, L.J. " White matter tractography for neurosurgical planning: A topography-based review of the current state of the art." NeuroImage: Clinical 15 (2017): 659–672.
[2] Calamante, F., Tournier, J.D., Jackson, G.D., Connelly, A. "Track-density imaging (TDI): super-resolution white matter imaging using whole-brain track-density mapping." NeuroImage 53 (2010): 1233–1243.
[3] Song, J., Meng, C., Ermon, S. "Denoising diffusion implicit models." Proceedings of the IEEE conference on computer vision and pattern recognition. 2020.
[4] Shi, W., Caballero, J., Husz ́ar, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert, D., Wang, Z. "Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[5] Edig, C., Theis, L., Husz ́ar, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., et al. "Photo-realistic single image super-resolution using a generative adversarial network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
Figures