1744
Conditional Diffusion Probabilistic Model for Quantitative Analysis of Hyperpolarized 129Xe Ventilation Imaging1State Key Laboratory of Magnetic Resonance and Atomic and Molecular Physics, National Center for Magnetic Resonance in Wuhan, Wuhan Institute of Physics and Mathematics, Innovation Academy for Precision Measurement Science and Technology, Chinese Academy of Sciences, Wuhan National Laboratory for Optoelectronics, Wuhan, China, Wuhan, China
Synopsis
Keywords: AI Diffusion Models, Hyperpolarized MR (Gas)
Motivation: HP 129Xe MRI is remarkably beneficial for investigating structural and functional abnormalities in COPD. Typical VDP calculation methods are based on semi-automatic segmentation to quantify ventilation images, such as k-means. They are highly influenced by image noise and artificial thresholds.
Goal(s): Our goal was to improve the accuracy of automatic segmentation-based VDP on different signal-to-noise ratio images with a small amount of training dataset.
Approach: We proposed a conditional diffusion probabilistic model for thoracic cavity mask and ventilation mask segmentation.
Results: This model can preferably segment the target mask, calculate the VDP, and maintain high robustness compared to other methods.
Impact: Our proposed conditional diffusion probabilistic model can preferably automatically segment the thoracic cavity mask and ventilation mask. It can calculate a more accurate VDP, which allows physicians to better evaluate 129Xe ventilation images.
Purpose
Hyperpolarized (HP) 129Xe magnetic resonance imaging (MRI) is remarkably beneficial for investigating structural and functional abnormalities in chronic obstructive pulmonary disease (COPD).1 Typically, 129Xe ventilation images are quantified using semi-automated segmentation-based ventilation defect percentage (VDP) methods such as k-means.2 In these methods, both 1H MR images and 129Xe MR images are segmented after registration to obtain thoracic cavity volume and ventilation volume, which are then expressed as a ratio to calculate the VDP. However, the semi-automated method is highly affected by image noise and artificial thresholds, which can cause error in the calculation of VDP. Recently, deep learning algorithms (e.g. U-Net) have shown significant advantages in medical image segmentation.3 Unfortunately, these end-to-end convolutional neural networks (CNN) require a large amount of images and annotations for training to have strong segmentation capabilities. To obtain a robust network with little training data, we propose a conditional diffusion probabilistic model for thoracic cavity mask and ventilation mask segmentation. This model consists of a segmentation encoder, a conditional encoder, and a segmentation decoder. Strategically, the model uses multi-step diffusion generation to segment the target mask. Compared with end-to-end U-Net, our proposed conditional diffusion probabilistic model can maintain high robustness. This model effectively improves the segmentation performance and then reduces the error of VDP.Methods
The architecture of the proposed conditional probabilistic diffusion model is shown in Figure 1, which is composed of two encoders (called Segmentation Encoder and Conditional Encoder) and one decoder (called Segmentation Decoder). The Segmentation Encoder and Segmentation Decoder as a symmetric architecture obtains the target mask from the noisy images. The Conditional Encoder extracts the feature from 1H and 129Xe images as the condition feeding into decoder with skip connection.As a type of generative model, the model consists of a forward diffusion process and a reverse diffusion process.4 In the forward process, a series of steps $$${T}$$$ are used to incrementally add Gaussian noise to the segmentation annotation $$$x_{0}$$$. In the reverse process, the model is trained to reconstruct the original data, which can be expressed as:
$$p_{\theta}\left(x_{0:T-1}\mid x_{T}\right)=\prod_{t=1}^{T}p_{\theta}\left(x_{t-1}\mid x_{t}\right)$$
where $$$\theta$$$ is the reverse process parameters. Assuming a Gaussian noise, the distribution of $$$x_{T}$$$ can be expressed as:
$$p_{\theta}\left(x_{T}\right)=\mathcal{N}\left(x_{T};0,I_{n\times n}\right)$$
where $$$I$$$ are the raw images, the reverse process transforms the latent variable distribution $$$p_{\theta}\left(x_{T}\right)$$$ into the data distribution $$$p_{\theta}\left(x_{0}\right)$$$. During each reverse iteration, random paired raw images $$$I_{i}$$$ and their corresponding segmentation labels $$$S_{i}$$$ are sampled as Gaussian distribution noise $$$\epsilon\sim\mathcal{N}(0,I)$$$ for the model training. The loss of the model is represented as:
$$L_{seg}=E_{x_{0},\epsilon\sim N(0,I)}\left[\left\|\epsilon-\epsilon_{\theta}\left(x_{t},I_{i},t\right)\right\|^{2}\right]$$
Experiments
85 subjects were enrolled for segmenting thoracic cavity mask and ventilation mask using 1H MR images and 129Xe MR images. The parameters for 1H imaging are as follows: repetition time/echo time (TR/TE) = 2.4/ 0.7 ms, matrix size = 96 × 96, number of slices = 24, slice thickness = 8mm, flip angle (FA) = 5°, scan time = 2 s. The parameters for 129Xe imaging are as follows: TR/TE = 4.2/1.9 ms, matrix size = 96×96, number of slices = 24, slice thickness = 8 mm, FA = 10°, scan time = 8.4 s. The 1H and 129Xe images were segmented by experts to obtain training labels. We then selected 80% of the pairs for model training and the others for testing. In the experiments, we used 200 diffusion steps for training, and 100, 200, 300, 400 diffusion steps for inference. The Dice value is used to evaluate the quality of image segmentation.Results
Figure 2 shows the segmentation performance of different models on three randomly selected images from the test dataset. It is clear that our proposed model outperforms k-means and U-Net in terms of segmentation performance. Figure 3 shows the ablation experiment, the Dice of the thoracic cavity mask and the ventilation mask reach the highest value at 300 diffusion steps (93.89% and 85.34%). As shown in Figure 4, our proposed model outperforms k-means and U-Net in terms of VDP error for healthy (5.53 ± 3.67), COPD (25.05 ± 2.32) and all (8.40 ± 2.59) subjects.Conclusions
The visual results show that the segmentation by the proposed model maintains higher segmentation accuracy and is closer to the ground truth than other methods. Especially for images with low signal-to-noise ratio, it can still maintain high accuracy, which means the diffusion model is robust. The quantitative results show that the proposed model has lower VDP error than other methods, which allows physicians to better evaluate 129Xe ventilation images.Acknowledgements
This work was supported by National key Research and Development Project of China (2018YFA0704000), National Natural Science Foundation of China (82127802, 21921004, 82001915), Key Research Program of Frontier Sciences (ZDBS-Y-JS004), Hubei Provincial Key Technology Foundation of China (2021ACA013). Xin Zhou acknowledges the support from the Tencent Foundation through the XPLORER PRIZE.References
1. Kirby M, Svenningsen S, et al. Hyperpolarized 3He and 129Xe MR Imaging in Healthy Volunteers and Patients with Chronic Obstructive Pulmonary Disease. Radiology. 2012; 265(2):600-610.
2. Felix CH, Helen M, et al. Regional Ventilation Changes in the Lung: Treatment Response Mapping by Using Hyperpolarized Gas MR Imaging as a Quantitative Biomarker. Radiology. 2017; 284(3):854-861.
3. Garrison WJ, Qing K, et al. Lung Volume Dependence and Repeatability of Hyperpolarized 129Xe MRI Gas Uptake Metrics in Healthy Volunteers and Participants with COPD. Radiology: Cardiothoracic Imaging. 2023; 5(3):e220096.
4. Pinaya WHL, Graham MS, et al. Fast Unsupervised Brain Anomaly Detection and Segmentation with Diffusion Models. 2022; 13438:705-714.
Figures
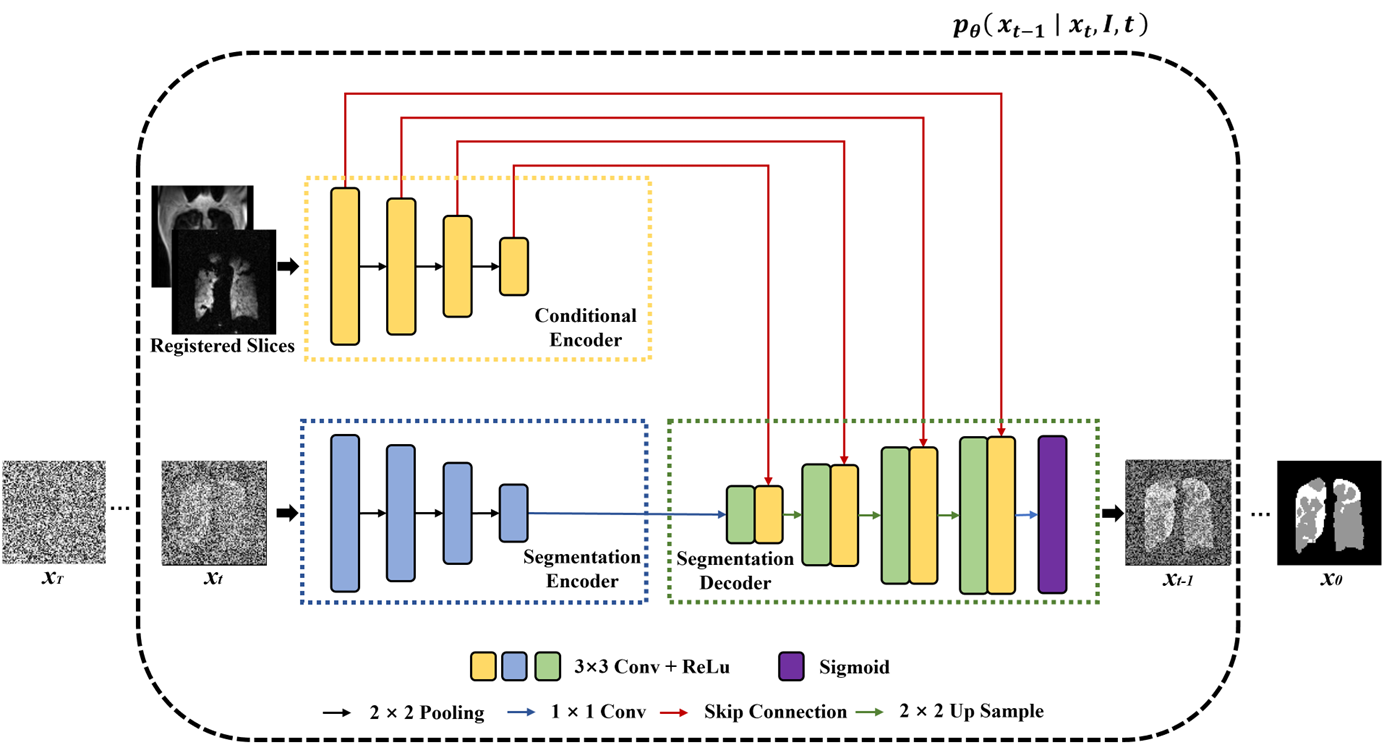
Figure 1. The architecture of the proposed conditional diffusion probabilistic model. The model consists of three parts: the Conditional Encoder, which extracts features from registered 1H and 129Xe images. The Segmentation Encoder, which extracts features from the image of diffusion step xt. The Segmentation Decoder takes the outputs of the above two encoders and segments two types of target masks to generate the image of diffusion step xt-1. Through continuous multi-step generation, the model gradually recovers the image to obtain the final segmentation x0.
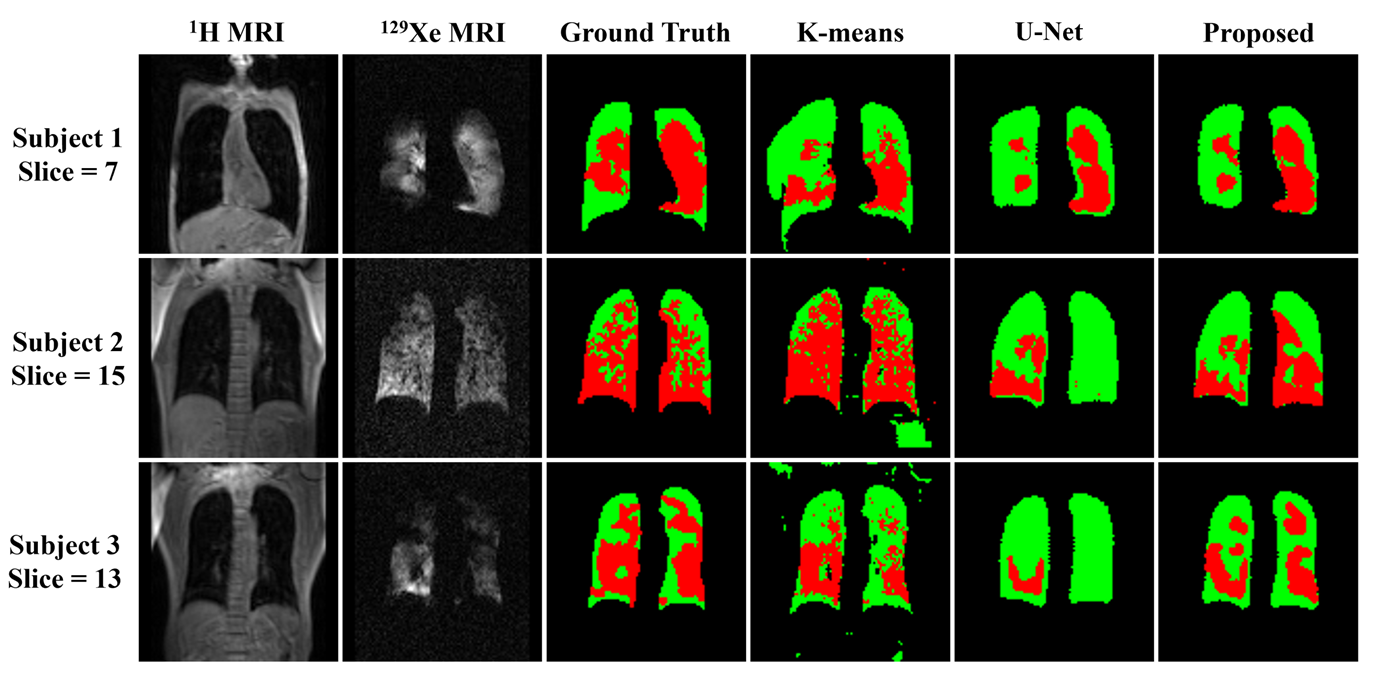
Figure 2. Segmentation results of thoracic cavity mask and ventilation mask by k-means, U-Net and the proposed model. The segmentation results of the proposed model are closer to the ground truth. Moreover, the results segmented by the proposed model maintain a high accuracy on different signal-to-noise ratio images, which means that the diffusion model is robust.
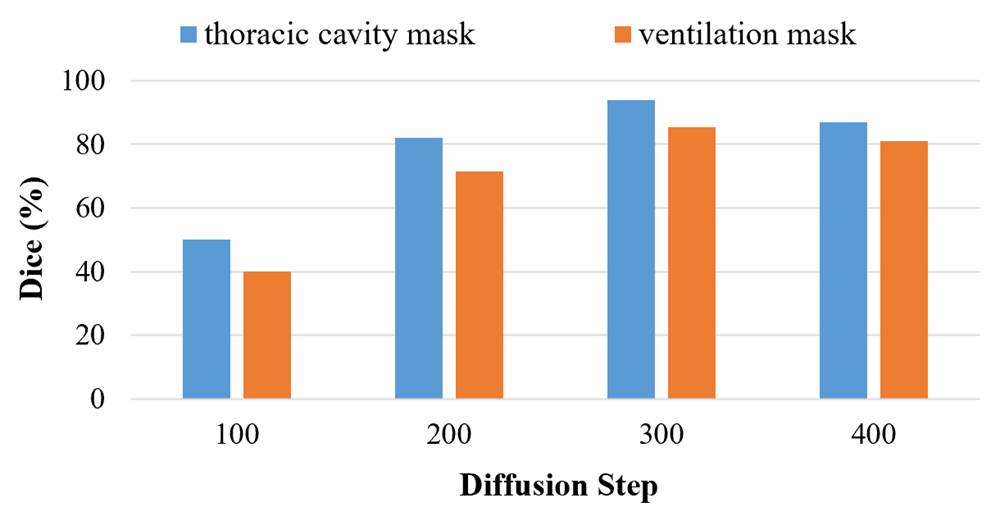

Figure 4. The average and standard error of VDP calculation using different segmentation methods in healthy and COPD subjects. Our proposed model outperforms k-means and U-Net in terms of VDP error for all subjects.