1669
Improved cardiac cine MRI using a deep learning-based ESPIRiT reconstruction with video SWIN transformers1Radiology, Stanford University, Stanford, CA, United States, 2Electrical Engineering, Stanford University, Stanford, CA, United States
Synopsis
Keywords: Myocardium, Cardiovascular, SWIN, ESPIRiT, Resnet, CINE
Motivation: Cardiac CINE MRI is used clinically for characterizing heart morphology and function, but requires multiple breath-holds to minimize motion artifacts from respiration.
Goal(s): Deep learning based ESPIRiT (DL-ESPIRiT) is able to reconstruct dynamic MRI data with high reconstruction accuracy. However, the method still has difficulty resolving fine anatomic structures. We aim to improve reconstruction accuracy using newer transformer architecture.
Approach: We replace the ResNet deep learning backbone by a modified Swin Image Restoration network (SwinIR) with video Swin transformers, called DL-ESPIRiT VSwinIR
Results: DL-ESPIRiT VSwinIR has substantially improved reconstruction accuracy and can accelerate acquisitions by up to 20x.
Impact: Fast CINE acquisitions using our DL-ESPIRiT VSwinIR may enable multiple CINE slices to be acquired in a shortened breath-hold, which will allow heart morphology and function assessment in patients with difficulty breath-holding or following instructions.
Introduction
Cardiac CINE MRI is used clinically for characterizing heart morphology and function, but requires multiple breath-holds to minimize motion artifacts from respiration. Accelerated acquisitions can reduce the number and duration of required breath-holds at the cost of aliasing and other reconstruction artifacts. Deep learning based ESPIRiT (DL-ESPIRiT) enables reconstruction of dynamic MRI data with up to 12x undersampling with higher reconstruction accuracy than modern compressed sensing algorithms.1 However, DL-ESPIRiT still has difficulty resolving fast, fine anatomic structures such as the papillary muscles. We previously added a self-attention squeeze-excitation block into the DL-ESPIRiT that saw modest performance gains.2 Inspired by the strong performance of transformers3, in this work, we replace the ResNet backbone of DL-ESPIRiT with a modified Swin Image Restoration network4 (SwinIR) that incorporates video Swin transformers5,6 to capture both spatial and temporal features, which we call DL-ESPIRiT VSwinIR.Methods: Network Architecture
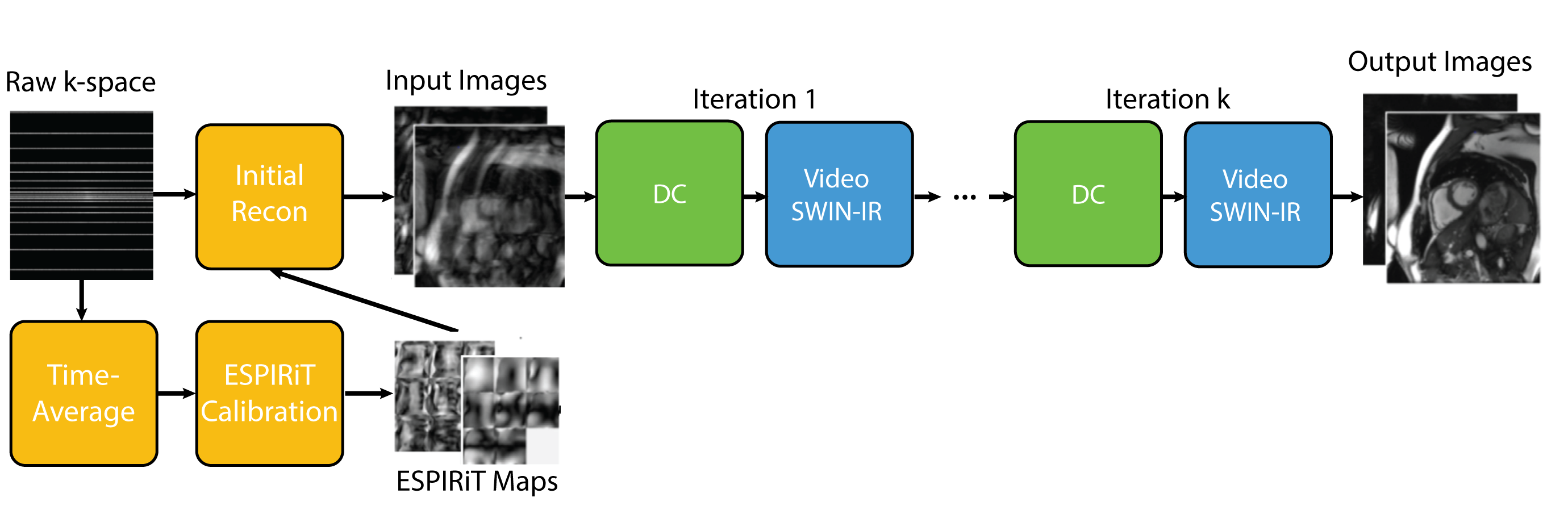
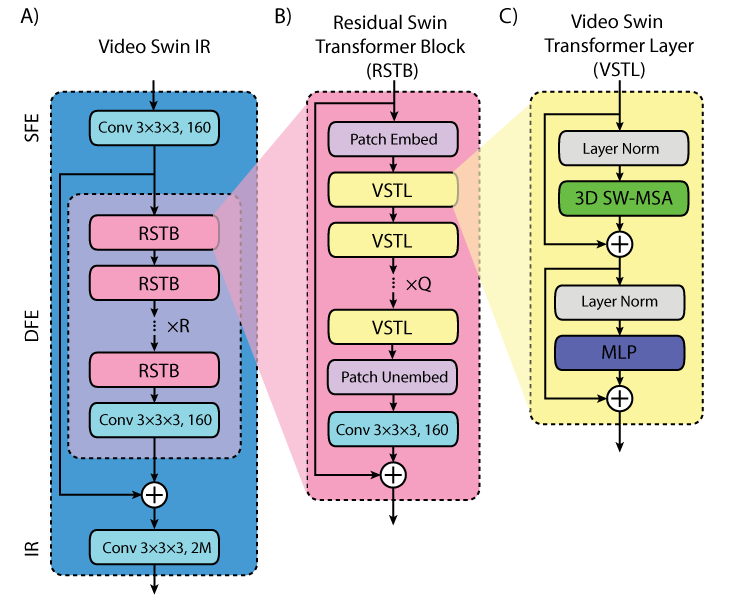
The DL-ESPIRiT VSwinIR network takes input from a zero filled reconstruction of a 2D cardiac CINE slice and ESPIRiT maps computed from time averaged k-space data and alternates between the VSwin-IR neural network and data consistency steps in an unrolled fashion (Fig.1). The VSwin-IR network is adapted from the Swin Image Restoration4 (SwinIR) network, which is composed of shallow feature extraction (SFE), deep feature extraction (DFE), and image reconstruction (IR) modules (Fig.2a).- The SFE module,$$$H_{SFE}$$$, is a convolution that maps an intermediate image after data consistency, $$$x^k\in\mathbb{R}^{T \times H \times W \times C_{in}}$$$ to shallow features $$$F_{SF}\in\mathbb{R}^{T \times H \times W \times C}$$$, where $$$T$$$, $$$H$$$, $$$W$$$, $$$C_{in}$$$, and $$$C$$$ are image frames, height, width, input channel number, and feature channel number.
- The DFE module, $$$H_{DFE}$$$, is composed of R residual Swin transformer blocks followed by a convolution layer. Specifically, $$ F_i = H_{RSTB_i}(F_{i-1}), i=1,2,...,R $$ $$F_{DF} = H_{conv}(F_R)$$ Where $$$F_i$$$ denotes the intermediate feature after the ith RSTB block, $$$H_{RSTB_i}$$$, and $$$H_{conv}$$$ is the convolutional layer.
- The image reconstruction module, $$$H_{IR}$$$, is a convolution that maps the aggregated shallow and deep features back to the image space such that $$ x^{k+1}=H_{IR}(F_{SF}+ F_{DF})$$
The video Swin transformer is composed of a multi-head self-attention (MSA) followed by a multi-layer perceptron (MLP) module (Fig2c). MSA is performed within each non-overlapping 3D windows of size $$$P \times M \times M $$$ and is calculated as $$Attention(Q,K,V) = SoftMax(QK^T/sqrt(d)+B)V$$ Where $$$Q,K,V \in\mathbb{R}^{PM^2 \times d}$$$ are the query, key, and value matrices, d is the query/key dimension, and $$$B\in\mathbb{R}^{P^2 \times M^2 \times M^2} $$$ is the relative position bias. MLP is composed of two fully connected layers with a GELU non-linearity in between. A layer-norm and residual connection is employed for both the MSA and MLP modules. To enable connections across local windows between layers, the windows are shifted by $$$(P/2, M/2, M/2)$$$ between subsequent Swin transformer layers.
Methods: Dataset and Training
Fully sampled 2D cardiac cine datasets were acquired from 22 healthy volunteers on 1.5T and 3.0T GE MRI scanners with a 32 channel cardiac coil using balanced SSFP with TR/TE/FA, slice thickness, and spatial resolution of 3.7ms/1.6ms/40-600, 8mm, and 1.8-2.0$$$\times$$$1.6-1.8mm2. Data were acquired in the short axis, 2-chamber, 3-chamber, and 4/5-chamber views. All data were compressed from 32 to 8 virtual coils. The 22 volunteers were divided into three cohorts for training, validation, and testing (10, 2, 10 split) corresponding with 5220, 660, and 2640 images respectively. Variable density undersampling masks were applied to simulate 10-15x acceleration across k-t space. Training was performed using a Nvidia RTX 3090 24GB video card for a total of 101 hours.Results
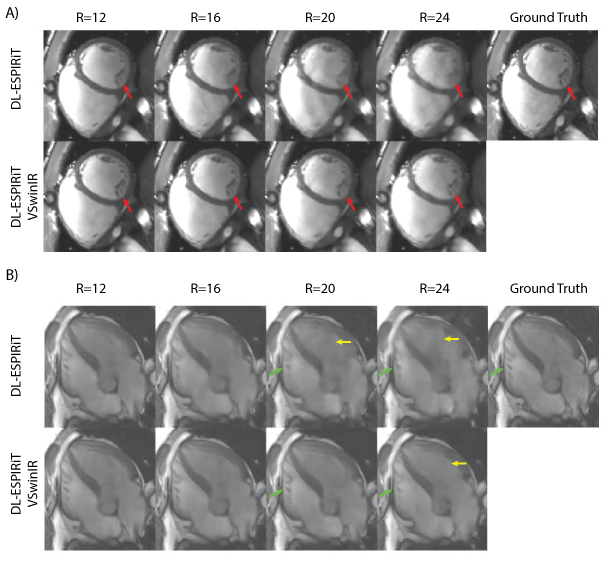
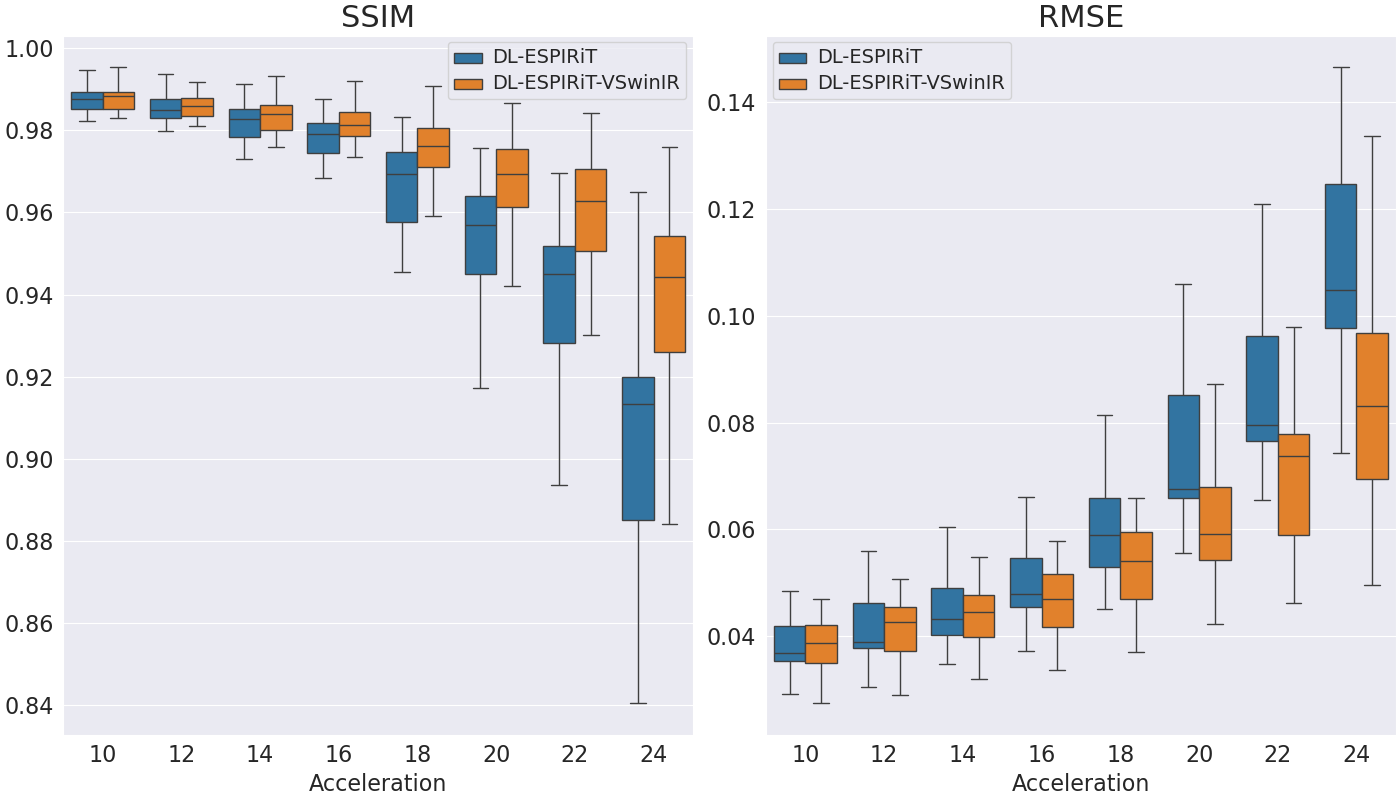
Figures 3a and 3b show representative reconstructions of DL-ESPIRiT, and DL-ESPIRiT VSwinIR on retrospectively undersampled cardiac CINE with varying acceleration factors in the short axis and a 5-chamber view respectively. VSwinIR has substantially less aliasing artifacts at higher acceleration factors up to R=20 and better reconstructs fine anatomic details such as the papillary muscles. Figure 4 demonstrates DL-ESPIRiT VSwinIR has improved reconstruction compared to DL-ESPIRiT across all acceleration factors in terms of SSIM.Conclusion
We used a video Swin transformer network with DL-ESPIRiT and significantly improved the reconstruction quality of cardiac CINE images. This network has better characterization of fine anatomic detail, less aliasing artifacts, and decreased reconstruction error, which can allow us to push the acceleration by up to 20x.Acknowledgements
GE healthcareReferences
- Sandino CM, Lai P, Vasanawala SS, Cheng JY. Accelerating cardiac cine MRI using a deep learning-based ESPIRiT reconstruction. Magn Reson Med. 2021;85(1):152-167. doi:10.1002/mrm.28420
- Jao, Terrence, Sandino CM, Vasanawala SS. Improving cardiac cine MRI using a deep learning-based ESPIRiT reconstruction with self attention. In: Proc. ISMRM 31st Scientific Session. Toronto, Canada; :p4974.
- Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need. ArXiv170603762 Cs. August 2023. http://arxiv.org/abs/1706.03762.
- Liang J, Cao J, Sun G, Zhang K, Van Gool L, Timofte R. SwinIR: Image Restoration Using Swin Transformer. ArXiv210810257 Cs Eess. August 2021. http://arxiv.org/abs/2108.10257.
- Liu Z, Lin Y, Cao Y, et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ArXiv210314030 Cs. August 2021. http://arxiv.org/abs/2103.14030.
- Liu Z, Ning J, Cao Y, et al. Video Swin Transformer. ArXiv210613230 Cs. June 2021. http://arxiv.org/abs/2106.13230.
Figures