1667
Instance Segmentation Based approach for Robust automatic 3D Multi-View Planning for Cardiac MRI1Philips Healthcare, Bengaluru, India
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Cardiovascular, Scan planning, Cardiovascular MR acquisition, Computational geometry
Motivation: Manual planning for cardiac MRI (CMR) involving complex oblique views is time-consuming and introduces intra- and inter-technologist variability.
Goal(s): To develop a fast and robust model that automatically predicts the standard CMR views from a 3D survey scan (SS) image.
Approach: We use a deep learning (DL) based approach to map the 3D-SS image to four standard CMR using an instance segmentation strategy that identifies all planes followed by a finetuning strategy, which potentially offers improved robustness.
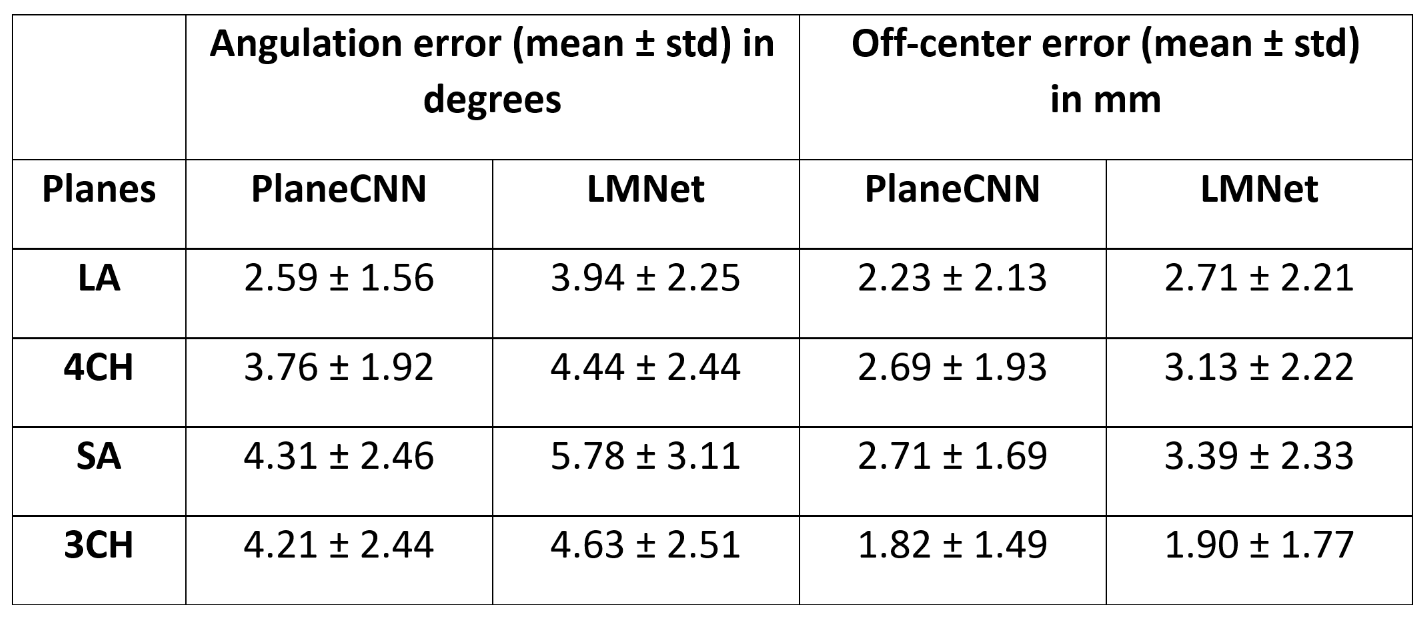
Results: We achieved mean angulation and offset errors of 3.72±2.1 degrees and 2.36±1.8 mm, respectively across four standard CMR views averaged across 100 test subjects.
Impact: Plane estimation as instance segmentation problem understands the spatial conformations of the planes and can adapt to various heart shapes and sizes and can go a long way in reducing intra- and inter-technologist variability and more importantly reducing scanning time.
Introduction
Manual planning for cardiac MRI (CMR) is performed in select institutes with experienced technicians and involves double oblique views. It is complex, time-consuming and introduces intra- and inter-technologist variability. Few groups have suggested(1,2) and commercially implemented(3,4) deep learning (DL) based automatic plane prescription modules for CMR, involving two steps as follows: a three-axis 2D localizer, followed by a low-resolution 3D survey scan (SS) covering the heart is obtained, which is then used as input to the DL model.Here, we developed an end-to-end DL-based method that automatically prescribes standard cardiac planes, given the 3D-SS image. Previous DL-based approaches rely on 3D landmark detection, followed by plane fitting(5). Alternatively, we pose the cardiac plane estimation as an instance segmentation problem which identifies all planes followed by a finetuning strategy, which would offer improved robustness.
Materials and Methods
Imaging parameters for the 3D SS are provided in Table 1. All imaging was performed on a Philips 3.0T Ingenia system (Best, Netherlands) from adult patients undergoing routine diagnostic CMR. Ground truth annotation of the four functional cardiac planes: Long axis (LA), 4 chamber (4 CH), short axis (SA) and 3 chamber view (3 CH) were labeled from the 3D SS data by a panel of clinical specialists and confirmed by an MRI technologist (author) with >12 years of experience in CMR. Training-validation-test split of data was 300 – 100 – 100 respectively.Proposed method: Figure 1 shows the proposed workflow involving the neural network that predicts the planes, called PlaneCNN. It involves two parts: 1) Segmentation module that maps the 3D SS image to the planes and 2) Fitting the predicted segmentations to individual planes. The segmentation module is implemented as a UNet6 which takes the 3D SS image as input. For improved localization of the planes, we localize the image to the heart region using another neural network (called MaskCNN).
Training strategy: We obtained the set of 3D-SS images and corresponding plane annotations $$$\{(X_i, \{P_{i,j}\}_{i=1}^N)\}_{j=1}^K$$$, from $$$K=300$$$ subjects. Here, $$$\{P_{i,j}\}_{i=1}^N)$$$ represents the set of $$$N$$$ planes (here $$$N=4$$$) annotated for each subject $$$i$$$ and $$$X_i$$$ represents the input 3D-SS image. We convert each of the annotated planes for every patient into a segmentation mask with unique labels . Regions outside of any plane were considered as background (value = 0). At voxels where planes intersect, we heuristically assign the maximal label value at that specific location. We train the PlaneCNN as an instance segmentation problem, where the output prediction is representing the plane or background at each voxel location. A combination of the dice loss and pixel-wise cross entropy loss was used as loss function. The network was trained with a batch size of 2 and an initial learning rate of 1e-4 and stochastic gradient descent as the optimizer.
Comparison Method (LMNet): For comparison with the conventional landmark-based approach, called LMNet, we implemented a UNet based architecture to learn the mapping between the input image and the set of landmarks for the four diagnostic views. Ground truth landmarks were annotated by the same team, by first arriving at the desired cardiac plane in the 3D volume and then annotating at least 3 anatomically relevant landmarks within each of those planes. Landmark detection problem was framed as a heatmap regression problem with Gaussian smoothing. A combination of Euclidean loss (mean squared error) and the pixel wise cross entropy loss between the predicted and the ground truth heatmaps as the loss function. Finally, the planes are fitted using singular value decomposition as the set of landmarks corresponding to a specific plane is known.
Evaluation Metrics: (i) Angulation difference and (ii) offset difference between the predicted and the ground truth planes was used as the metrics for comparison.
Results
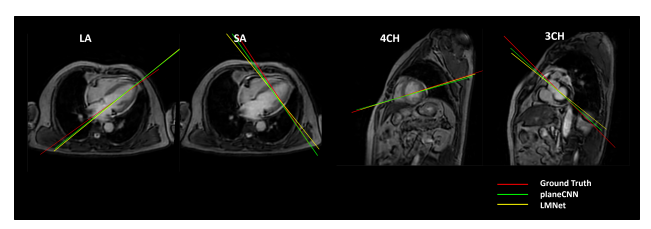
Figure 2 shows the predicted planes viewed from a reference view for ground truth, PlaneCNN and LMNet. Figure 3 shows the resulting predicted (oblique) views in comparison with the ground truth. Table 2 provides the quantitative comparison between the two methods for all the four views across 100 test subjects. Across the four views, averaged across 100 test subjects, we obtained mean angulation and offset errors of 3.72 ± 2.1 degrees and 2.36 ± 1.8 mm, respectively.Discussion and Conclusions
Our segmentation-based approach significantly improves over the landmark-based approach, both quantitatively and qualitatively by modelling the 3D conformations of the planes as segmentation masks and inherently enabling learning of inter-plane relationships. Finally, as the planes are directly obtained as segmentation masks, we overcome the error-prone (i) LM approach that predicts multiple landmarks followed by plane prediction and (ii) manual approach that adds planes sequentially.Acknowledgements
No acknowledgement found.References
1. Lu X, Jolly M-P, Georgescu B, Hayes C, Speier P, Schmidt M, et al. Automatic view planning for cardiac MRI acquisition. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2011: 14th International Conference, Toronto, Canada, September 18-22, 2011, Proceedings, Part III 14. Springer, 2011:479–486.
2. Alansary A, Folgoc L Le, Vaillant G, Oktay O, Li Y, Bai W, et al. Automatic view planning with multi-scale deep reinforcement learning agents. In: Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, September 16-20, 2018, Proceedings, Part I. Springer, 2018:277–285.
3. Vista.ai. www.Vista.ai.
4. Cardioline https://us.medical.canon/download/mr-atw-cardioline. Cardioline.
5. Bluekens AMJ, Holland R, Karssemeijer N, Broeders MJM, Den Heeten GJ. Comparison of digital screening mammography and screen-film mammography in the early detection of clinically relevant cancers: A multicenter study. Radiology 2012
6. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 2015:234–241.
Figures
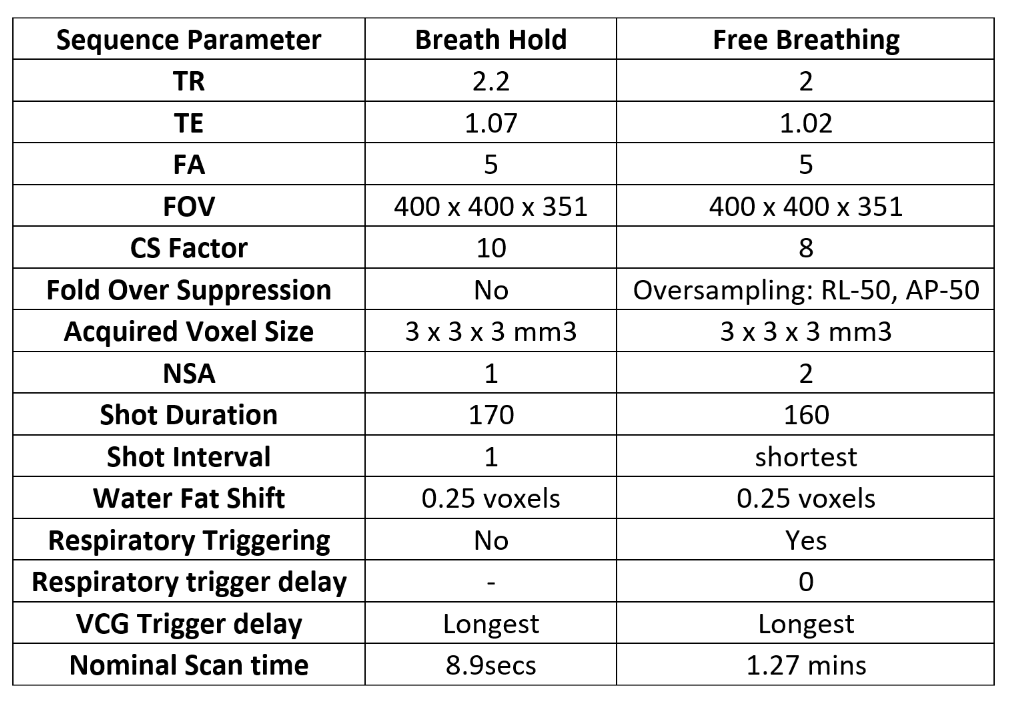
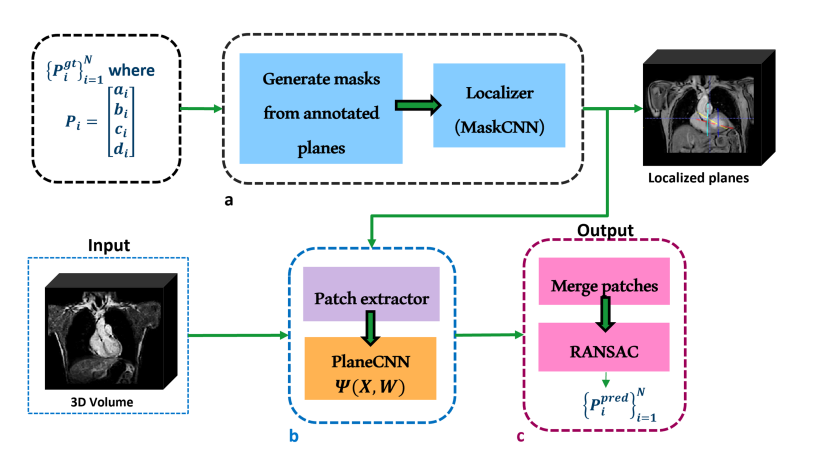
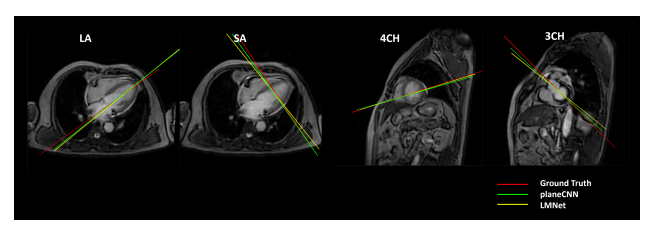
Figure 2: Comparison of the angulation difference for the different methods from a reference view for a representative patient. Figure shows red - ground truth plane, yellow - LMNet predicted plane, green - PlaneCNN predicted plane for all four selected CMR view planes. Clearly, in all four cases, the plane from PlaneCNN is closer to the ground truth.