1589
Deep neural network pre-training on a simulated dataset for optical tracking of head motion without fiducial markers1Medical Biophysics, University of Toronto, Toronto, ON, Canada, 2Sunnybrook Research Institute, Toronto, ON, Canada
Synopsis
Keywords: Analysis/Processing, Brain, Optical position tracking
Motivation: Deep learning methods are popular for head pose tracking in many applications; however, most models focus on large motions that are not applicable to the sub-millimeter accuracy required for motion correction in magnetic resonance imaging.
Goal(s): We aim to create a deep neural network capable of “markerlessly” tracking incremental changes in head pose in 6 degrees of freedom (DOF) with sub-millimeter/degree accuracy.
Approach: We pre-trained a network on simulated images of a face in our expected environment as preparation for real-world data collection and training.
Results: Initial test results show a low average mean squared error of 0.0588 mm/degrees across the 6DOF.
Impact: A deep neural network for sub-millimeter head pose tracking for motion correction was successfully pre-trained on simulated face data, with a test mean MSE of 0.0588 mm/degrees. This method shows potential towards motion correction applications in MRI.
Introduction
Optical position tracking (OPT) methods of measuring rigid body head motion parameters have high temporal resolution and potential for high accuracy, and thus are popular for motion correction applications in magnetic resonance imaging (MRI). However, the need for fiducial markers for OPT introduces limitations (e.g., difficulty affixing the marker, relative motion between the marker and skin). “Markerless” OPT methods are emerging to improve accuracy and practicality, and to provide better convenience to technicians, clinicians, and patients1. Options include tracking facial feature points between images, using structured light to register point clouds, and more1,2. In addition, deep learning methods have advanced substantially in the field of computer vision and pose estimation, including applications to track human head motion3. These applications have typically focused on larger motions, not the sub-millimeter tracking sensitivity desirable for motion correction in MRI4. To address this knowledge gap, the present work describes generation of a simulated dataset and proof-of-concept pre-training results for such a deep neural network prior to collection of real-world markerless OPT data.Methods
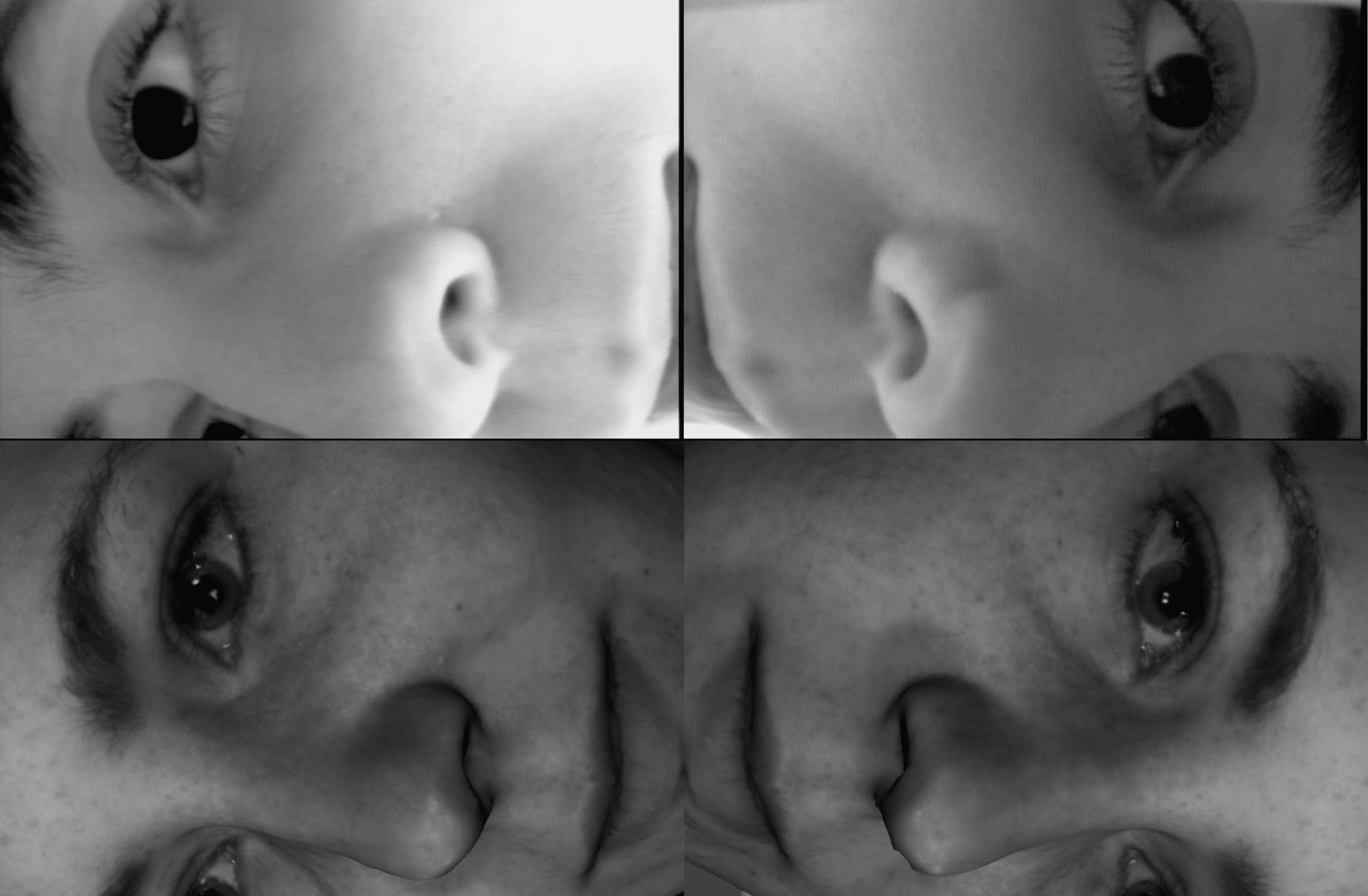
A simulated dataset for training was generated based on the appearance of the expected real-world dataset. The markerless OPT concept under consideration has two MR-compatible cameras mounted in-bore, viewing the head from two angles through the rungs in the head coil. To simulate this arrangement, heads from the Headspace dataset5 were imported in Blender software6 along with a head coil model, appropriate lighting, and virtual camera positions. Figure 1 shows a prototype real-world setup and a screenshot of the simulation, with labelled axes in the top right-hand corner. In Figure 2, a sample of real-world images are displayed with a simulated pair of images for comparison. With simulated images, a deep learning model can be pre-trained and validated as proof-of-concept for markerless OPT, in preparation for future training on real data.A single head from the Headspace dataset was moved as a rigid body 5000 times to various positions in six degrees of freedom (DOF) along randomly generated noisy sinusoidal paths, where the frequency of the motion in each DOF was modified randomly during the movement ranging from 0.05 to 0.08 cycles/frame. The poses were constrained to a range of [-1.5,1.5] mm/degrees, as is typically observed during MRI7.
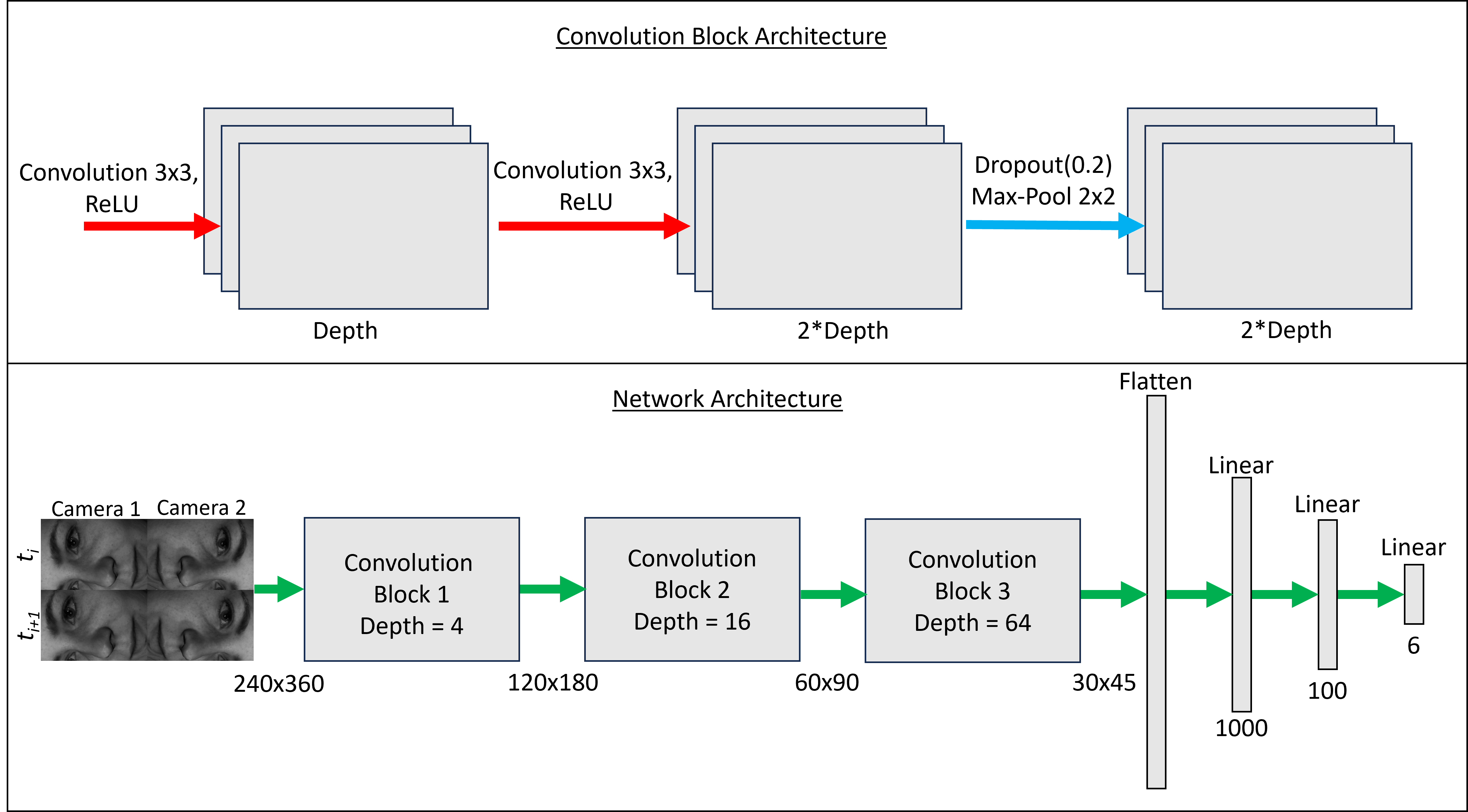
The prototype deep learning network architecture was created and trained in PyTorch, utilizing a straightforward, LeNet style convolutional neural network with a six-output regression head8. Four grayscale images are input, stitched together in a 2 x 2 grid, where the top two images are from frame number ti viewed from the two cameras and the bottom two images are from frame number ti+1 (Figure 3). The desired 6DOF output (each min-max normalized to a range of [0, 1] ($$$x_{normalized} = \frac{x-x_{min}}{x_{max}-x_{min}}$$$) and normally distributed) is the difference in pose between the two time points given as input.
Training was conducted with the following hyperparameters: Adam optimizer9; learning rate=1e-4; weight decay=1e-5; mean squared error (MSE) loss function; 100 epochs; batch size=1; train/validation/test split=70%/20%/10%.
Results
The normalized MSE training loss reached 0.0024 with a validation loss of 0.016 after 100 epochs. The mean test MSE across 6DOF is 0.0588 – suggesting a total error of ~250 µm, satisfying the goal of sub-millimeter accuracy for motion correction in MRI. Table 1 lists results for each DOF (un-normalized).Discussion
These initial training results strongly suggest that deep learning methods are feasible for measuring sub-millimeter head motions towards motion correction in MRI. It is expected that motion parameter estimates perform more equally over all DOF with deep learning methods as opposed to traditional computer vision methods, that often suffer with through-plane (pitch, roll, Z) inaccuracy. This effect was observed in the initial results, with pitch and roll (through-plane rotations) being the best performing DOFs and X (in-plane translation) and yaw (in-plane rotation) the worst performing DOF. Poor performance in X and yaw may be caused by visual similarity or coupling and could be improved with more training samples.Training could also be improved by training for more epochs or creating a weighted loss function to tune accuracy of motion estimates in keeping with physiological characteristics of head motion. Additionally, only one head model was used to generate these results and a variety of head models (~1500 available in Headspace) will be used in future work to ensure equal performance on varying skin tones, sexes, and age groups.
Conclusion
Work on pre-training a deep learning model for incremental head pose estimation is shown here. This work will enable future research in motion correction via markerless head pose tracking in MRI.Acknowledgements
No acknowledgement found.References
1. Kyme, A. Z., Se, S., Meikle, S. R. & Fulton, R. R. Markerless motion estimation for motion-compensated clinical brain imaging. Phys. Med. Biol. 63, 105018 (2018).
2. Slipsager, J. M. et al. Markerless motion tracking and correction for PET, MRI, and simultaneous PET/MRI. PLOS ONE 14, e0215524 (2019).
3. Asperti, A. & Filippini, D. Deep Learning for Head Pose Estimation: A Survey. SN COMPUT. SCI. 4, 349 (2023).
4. Maknojia, S., Churchill, N. W., Schweizer, T. A. & Graham, S. J. Resting state fMRI: Going through the motions. Frontiers in Neuroscience 13, (2019).
5. Dai, H., Pears, N., Smith, W. & Duncan, C. Statistical Modeling of Craniofacial Shape and Texture. Int J Comput Vis 128, 547–571 (2020).
6. Blender Online Community. Blender - a 3D modelling and rendering package. (Blender Foundation, 2018).
7. Seto, E. et al. Quantifying Head Motion Associated with Motor Tasks Used in fMRI. NeuroImage 14, 284–297 (2001).
8. Gu, J. et al. Recent advances in convolutional neural networks. Pattern Recognition 77, 354–377 (2018).
9. Kingma, D. P. & Ba, J. Adam: A Method for Stochastic Optimization. Preprint at https://doi.org/10.48550/arXiv.1412.6980 (2017).
Figures