1575
Towards Real-Time RF Coil Failure Recognition Using Deep Transfer Learning1Computer Science, Math, Physics, and Statistics, The University of British Columbia - Okanagan Campus, Kelowna, BC, Canada, 2Medical Imaging, Interior Health Authority, Kelowna, BC, Canada, 3Department of Radiology, Faculty of Medicine, The University of British Columbia, Vancouver, BC, Canada, 4The BioMedical Engineering and Imaging Institute, Icahn School of Medicine at Mount Sinai, New York, NY, United States
Synopsis
Keywords: Analysis/Processing, Safety, Quality Control
Motivation: RF coil failures are often not visually recognizable. Quality control is only done weekly or monthly, leading to days to weeks where diagnostic images may be negatively impacted.
Goal(s): Identify RF coil failures on patient images using deep transfer learning.
Approach: >10,000 passed and failed images from 50 patients were used to train 4 pre-trained deep learning models using 2 different pipelines: (1) shuffled all images into train and test, and (2) shuffled by each patients’ images.
Results: EfficientNet V2 (L) was the highest performing model, achieving 99% accuracy for pipeline 1, and 55% for pipeline 2. Other models showed similar results.
Impact: Introducing a deep learning model that can identify radiofrequency coil failures on patient images would avoid costly rescans of patients whose images were only determined to be poor after a failure was detected on a later quality control scan.
Introduction
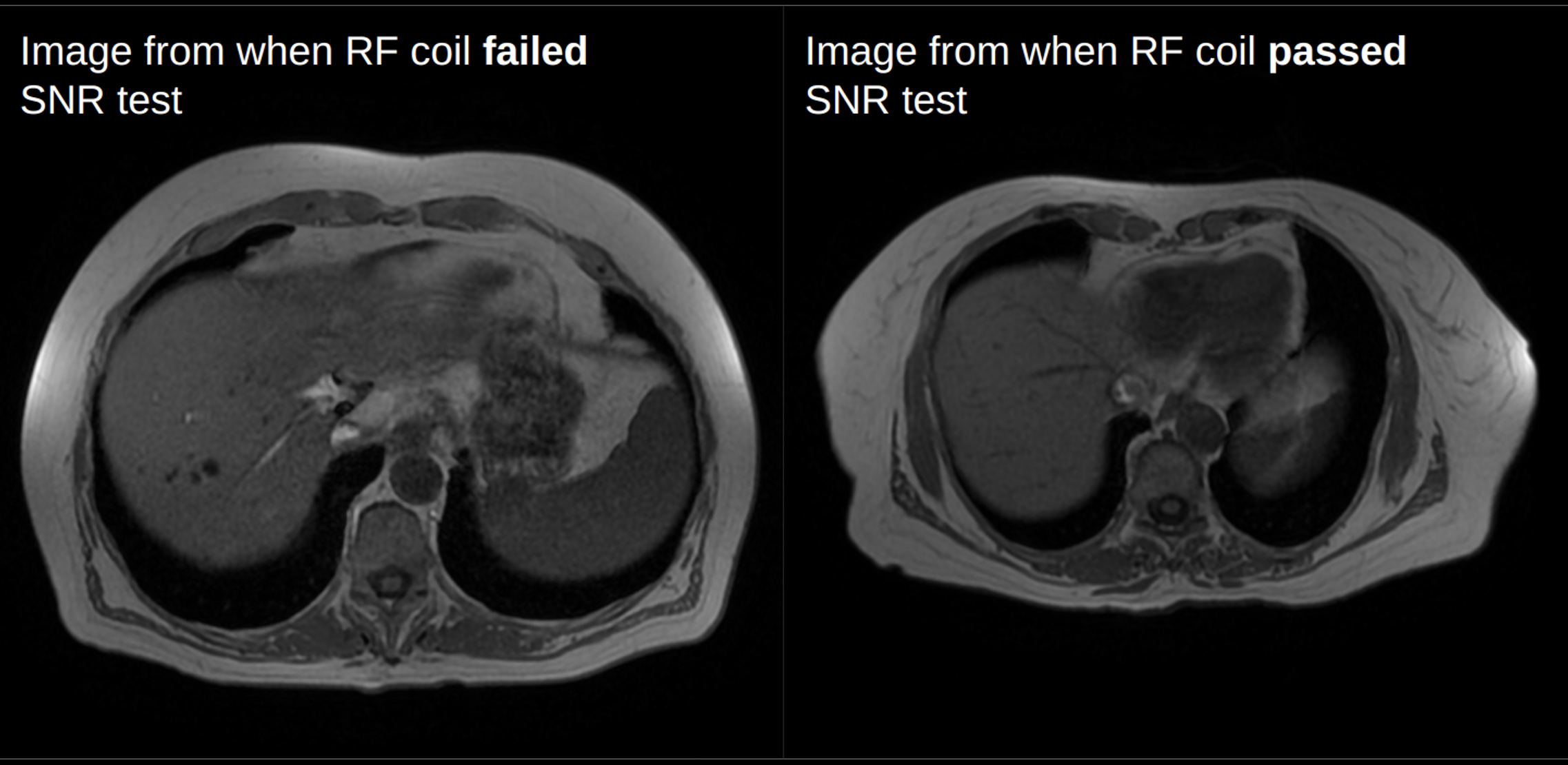
The frequent movement and use of radiofrequency (RF) coils in MRI causes the coils to be prone to failure. Quality Control (QC) procedures are routinely performed on MRI scanners, and are vital to maintain high levels of safety and diagnostic quality1. Coil QC often involves scanning a phantom for 15-20 minutes to measure the signal-to-noise ratio (SNR). The frequency at which the range of RF coils are tested varies heavily depending on department policies and resources2. Often, failures may not be visually recognizable by technicians or radiologists, but can still cause a reduction in diagnostic quality (Figure 1). The Interior Health Authority in British Columbia scans approximately 150 patients per day, so any delay in coil fault recognition can lead to costly patient re-scans that can negatively impact wait times, diagnosis, and treatment planning.We propose to address the problem of the delay between a coil fault and its discovery in QC by using deep learning to train a model on a dataset of labeled passed and failed MRI images. This abstract will focus on using deep transfer learning3,4 as a first step, as it has shown to be effective with image-based classification3. The goal of this work was to develop a real-time tool to detect coil faults, ultimately reducing or eliminating the need for patient re-scanning.
Methods
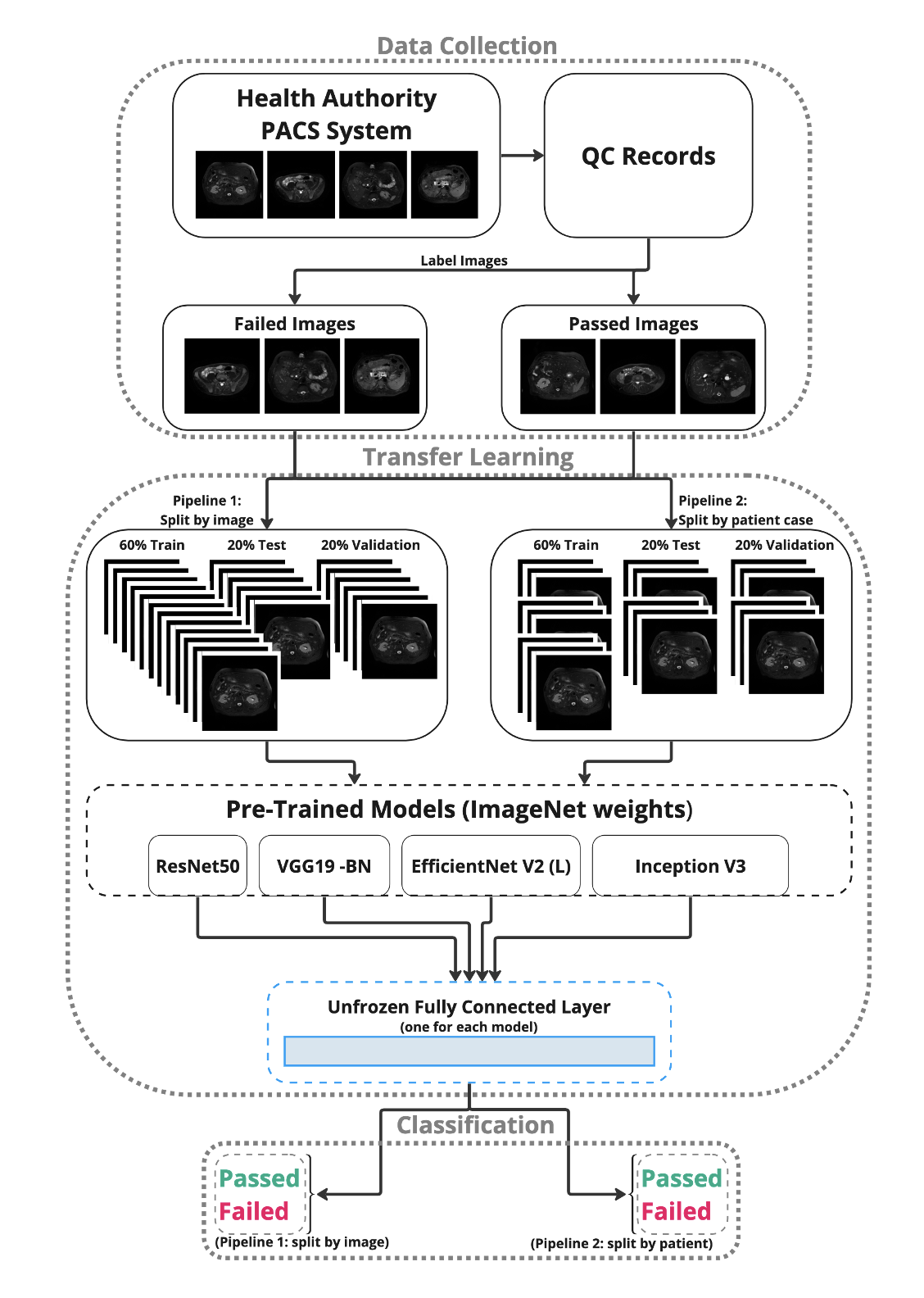
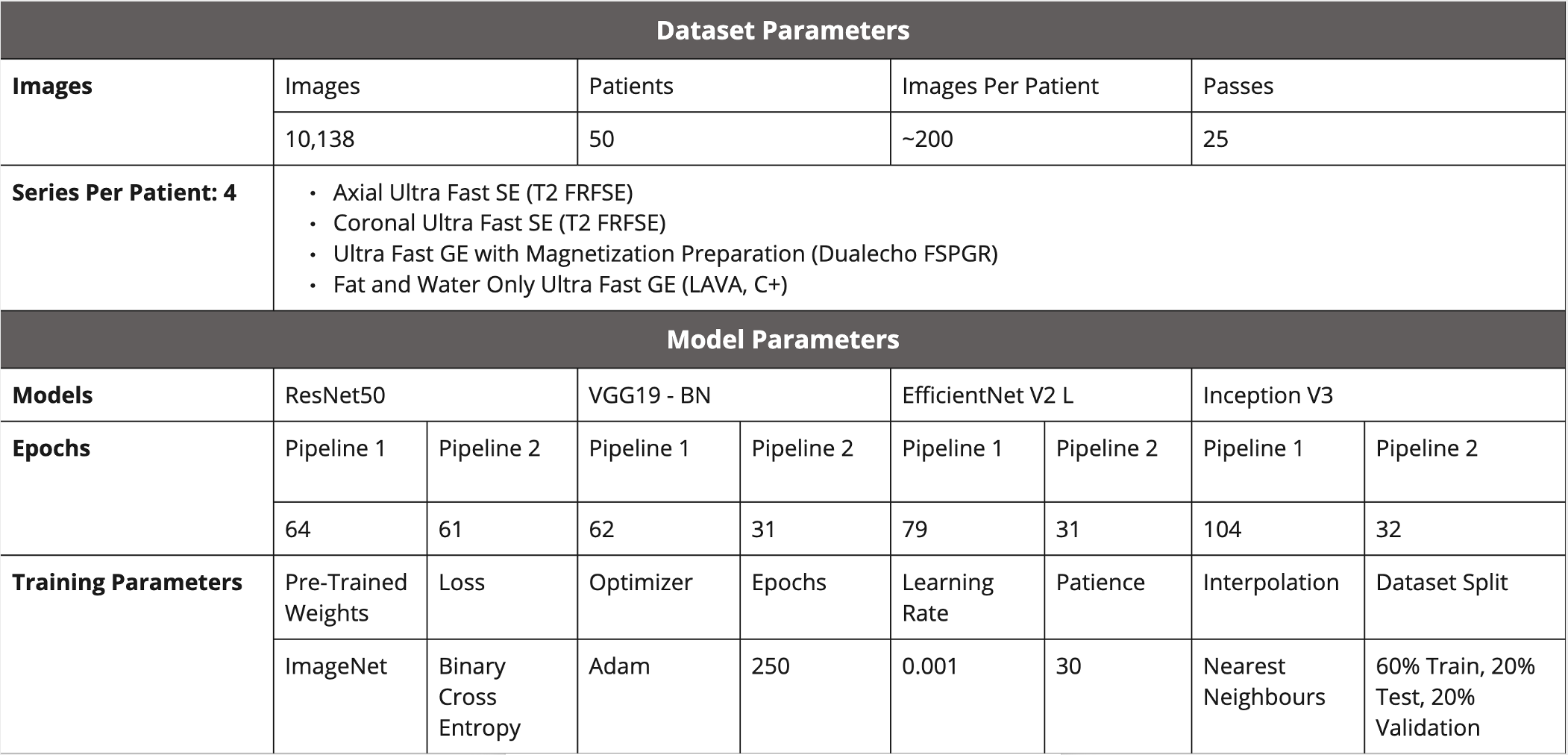
Abdominal images from a 6-Channel Flexible Array Coil on a 1.5 Tesla GE Signa HDxt MRI scanner obtained within 3 days prior to a coil SNR failure were de-identified and downloaded. This timeframe was chosen relatively arbitrarily as the time between the recorded failure and the previously recorded pass was at least one month in each case. For each patient case, the 4 most common pulse sequences were collected (Figure 3) to yield approximately 200 images per case. MR images were collected from the Interior Health Authority PACS system with clinical research ethics board approval.Data partitioning was undertaken with 2 different pipelines: (1) images were separated and shuffled into 60% train, 20% test, and 20% validation datasets, independent of case; and (2) to avoid data leakage, images were shuffled according to the case, such that images from any given case could not be in more than one of the datasets. Pytorch4 was used as the deep learning framework, and transfer learning was carried on 4 deep learning models (ResNet50, VGG19 - BN, EfficientNet V2 (L), and Inception V3) with existing pre-trained ImageNet weights4,6-9 , except for the final fully connected layer, which was modified on each model to have 2 output classes for QC classification (pass/fail), see Figure 2. The model was trained for 250 epochs, but varied for each model following early stopping. The model was set to evaluation before accuracy, f1-score, and area under the receiver operating characteristic curve (ROC-AUC) values were calculated on the test set. A full list of data and training parameters is shown in Figure 3.
Results
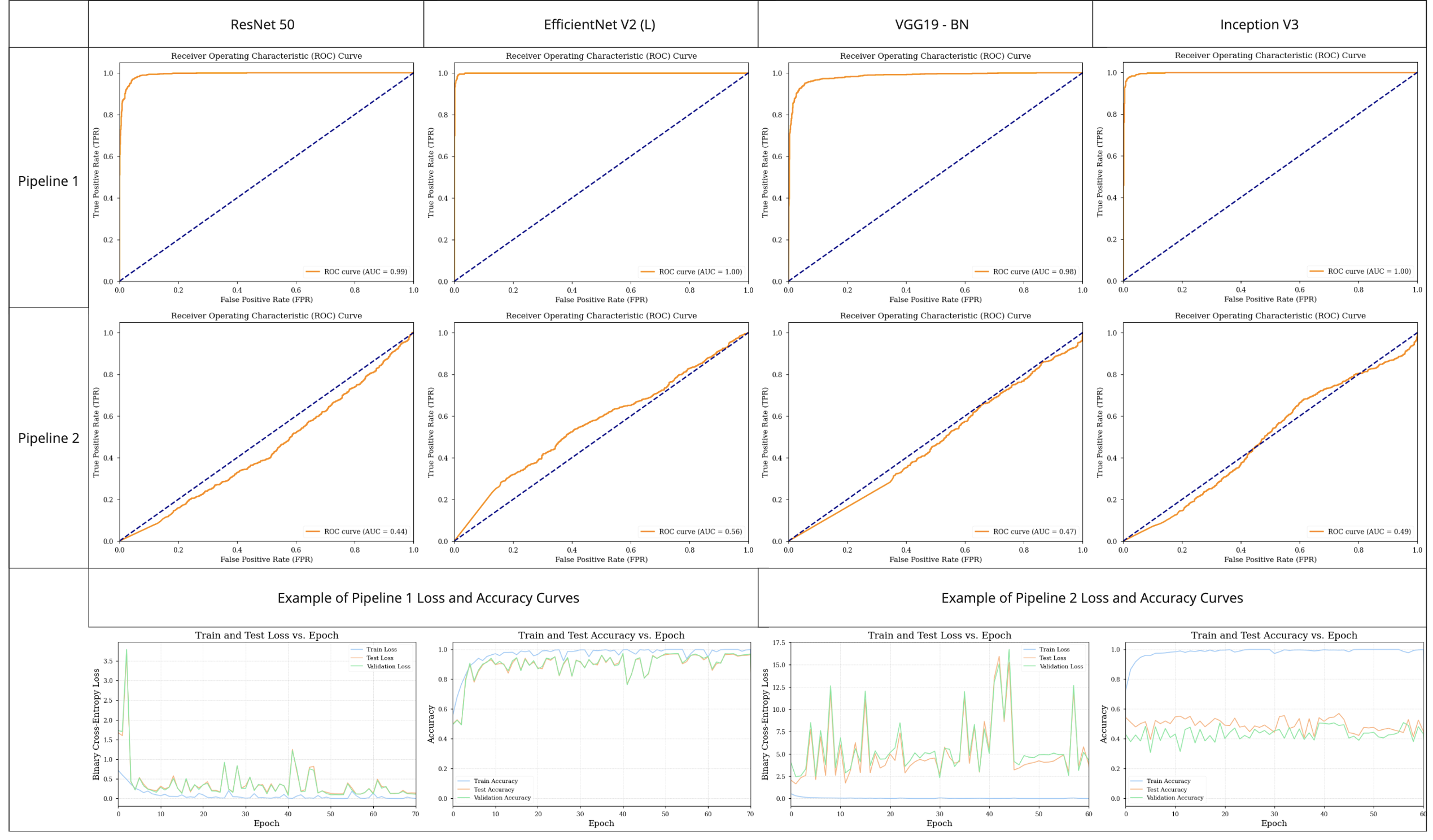
In pipeline 1, EfficientNet V2 (L) had the best performance with accuracy and AUC values of 99% and 0.99, respectively. Accuracy and loss functions of each model are shown in Figure 4, and a full list of models with performance metrics can be seen in Figure 5. In pipeline 2, the accuracy and AUC values of the highest performing model, EfficientNet V2 (L), were 55% and 0.56 respectively. A full list of results and performance metrics can be seen in Figures 4 and 5.Discussion
We found very high accuracy in models which did not split data according to patient case (pipeline 1), and as expected, we see that the models’ performance drops significantly with no data leakage (pipeline 2), from an almost perfect classifier to an almost random classifier. The train loss and accuracy start very high as of the first epoch, indicating that these models are likely not learning, and overfitting to the training dataset. Fine-tuning must be done to further optimize the models by unfreezing further layers than just the final fully connected layers. While this dataset consisted of ~10,000 images, which is a suitable scale for transfer learning, these data arose from only 50 different patient cases. To test the generalizability of these models we plan to collect labeled test datasets of MR images from different hospitals, scanners, coils, and anatomy, as well as to implement leave-one-out cross-validation in order to properly validate the trained model.Conclusion
The results presented in this study suggest that a real-time deep learning tool to detect coil failures may be achievable with future steps.Acknowledgements
The University of British Columbia
NSERC
References
- American College of Radiology. Magnetic resonance imaging quality control manual. Reston, VA: American College of Radiology. 2015.
- Peltonen JI, Mäkelä T, Sofiev A, Salli E. An automatic image processing workflow for daily magnetic resonance imaging quality assurance. Journal of digital imaging. 2017 Apr;30:163-71.
- Kim HE, Cosa-Linan A, Santhanam N, Jannesari M, Maros ME, Ganslandt T. Transfer learning for medical image classification: a literature review. BMC medical imaging. 2022 Apr 13;22(1):69.
- Imambi S, Prakash KB, Kanagachidambaresan GR. PyTorch. Programming with TensorFlow: Solution for Edge Computing Applications. 2021:87-104.
- Guo S, Bocklitz T, Neugebauer U, Popp J. Common mistakes in cross-validating classification models. Analytical Methods. 2017;9(30):4410-7.
- He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition 2016 (pp. 770-778).
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. 2014 Sep 4.
- Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition 2016 (pp. 2818-2826).
- Tan M, Le Q. Efficientnetv2: Smaller models and faster training. In International conference on machine learning 2021 Jul 1 (pp. 10096-10106). PMLR.
Figures