1402
Learning to synthesize MR contrasts using a self-supervised constrained contrastive learning approach1Bernard and Irene Schwartz Center for Biomedical Imaging, Department of Radiology, New York University Grossman School of Medicine, New York, NY, United States, 2Center for Advanced Imaging Innovation and Research (CAI2R), Department of Radiology, New York University Grossman School of Medicine, New York, NY, United States
Synopsis
Keywords: Analysis/Processing, Machine Learning/Artificial Intelligence
Motivation: Although deep learning frameworks have been widely used in all aspects of the MR imaging pipeline, the effect of learning tissue-specific information from MR images in improving model performance needs to be understood.
Goal(s): We demonstrate the utility of a self-supervised contrastive learning framework that uses multi-contrast information to improve synthesis of T1w and T2w images.
Approach: A deep learning model is pretrained to learn T1 and T2 information from a set of multi-parametric MR images.
Results: A contrast synthesis framework was developed using few examples of contrast mapping. Embedding relevant contrast information during pretraining synthesized images with improved MSE, SSIM, and PSNR.
Impact: Multi-contrast information can be leveraged by self-supervised deep learning models to understand underlying tissue characteristics and synthesize new MR contrast-weighted images. This demonstrates the wider applicability of embedding tissue-specific information in improving different aspects of the MR imaging pipeline.
Introduction
The acquisition of images with diverse contrasts (e.g., T1, T2, or diffusion weighting) in clinical MRI provides complementary tissue-specific information to radiologists. Although this is frequently beneficial for decision making, the use of multiple imaging sequences leads to prolonged examination times. Supervised deep learning (DL) models, using a large set of paired examples, can learn a complex mapping from one MR contrast to another [1], in principle enabling reductions in examination time. In the current work, we use a self-supervised framework to embed relevant MR contrast information in a DL model to facilitate synthesis of new MR contrasts when few paired examples are available. Specifically, we focus on learning T1 and T2 characteristics of underlying tissues from multi-parametric MR images to synthesize T1w and T2w images.We also use this work to demonstrate the wider applicability of learning to characterize underlying tissues in improving the performance of deep learning models across tasks in the MR imaging pipeline.
Methodology
Contrastive learning with multi-contrast constraintsA self-supervised contrastive learning approach was recently proposed to reduce annotation burden in MR image segmentation tasks by learning local representations that embed tissue-specific MR contrast information (e.g., T1, T2, etc.) in a DL model [2,3]. This constrained contrastive learning (CCL) approach uses a constraint map generated from a set of relevant MR contrast images (for example, a set of T2 weighted images with varying echo times to generate a T2 constraint map) to provide semantically consistent positive and negative local regions for contrastive learning. Figure 1 (reproduced with permission) illustrates the effect of CCL pretraining on local representations from different anatomical regions in a T2-weighted abdominal image. Local regions that belong to the same anatomical structure exhibit similar feature representations.
Embedding T1 and T2 information in the representational space
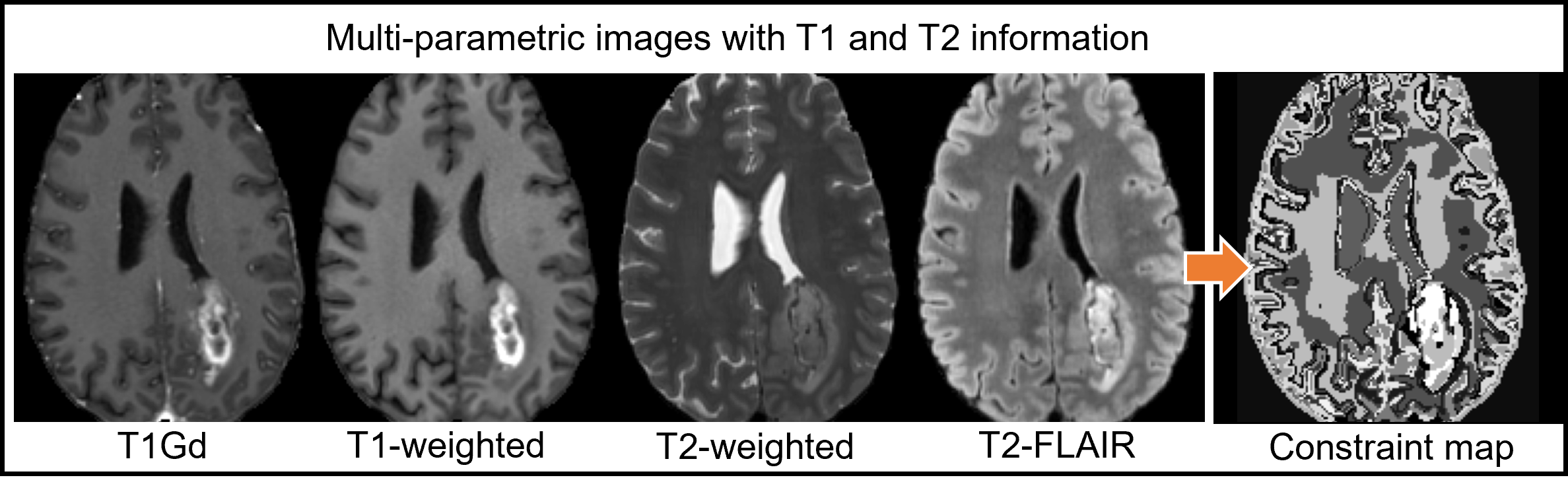
Here, we use multi-contrast information from multi-parametric MR images to train a 3D DL model to embed T1 and T2 information for contrast synthesis. We use a subset (n=80) of the publicly available training set of 2021 Brain Tumor Segmentation (BraTS) dataset [4] that contains co-registered multi-parametric MR images [T1w, T1-Gd enhanced, T2w, and T2-FLAIR]. Following the procedure in [2], constraint maps with T1 and T2 information (Figure 2) were generated for each volume by applying principal component analysis followed by an unsupervised K-means clustering (K=20) along the contrast-dimension.
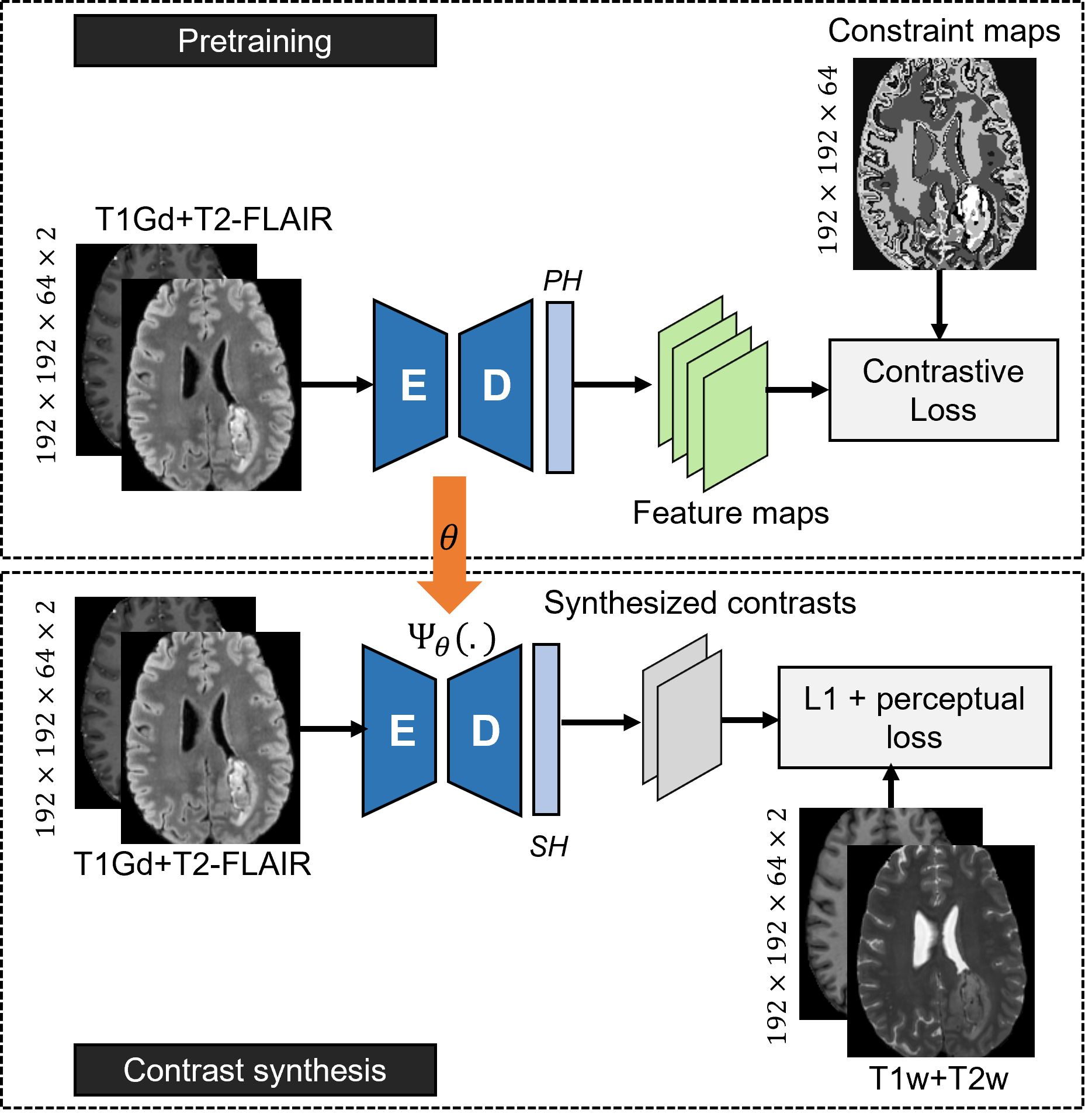
We assume that T1Gd and T2-FLAIR, images with the most information, have already been acquired, and use the CCL approach with multi-channel T1Gd+T2-FLAIR images and the corresponding constraint map (Figure-3A). The learned weights are finetuned to jointly synthesize conventional T1w and T2w images (Figure-3B) using a small subset of paired examples (n-=10). The synthesis loss function minimizes the mean absolute error and perceptual error (calculated from the difference between feature maps generated by ImageNet-pretrained VGG16 architecture for target and synthesized T1w+T2w contrasts).
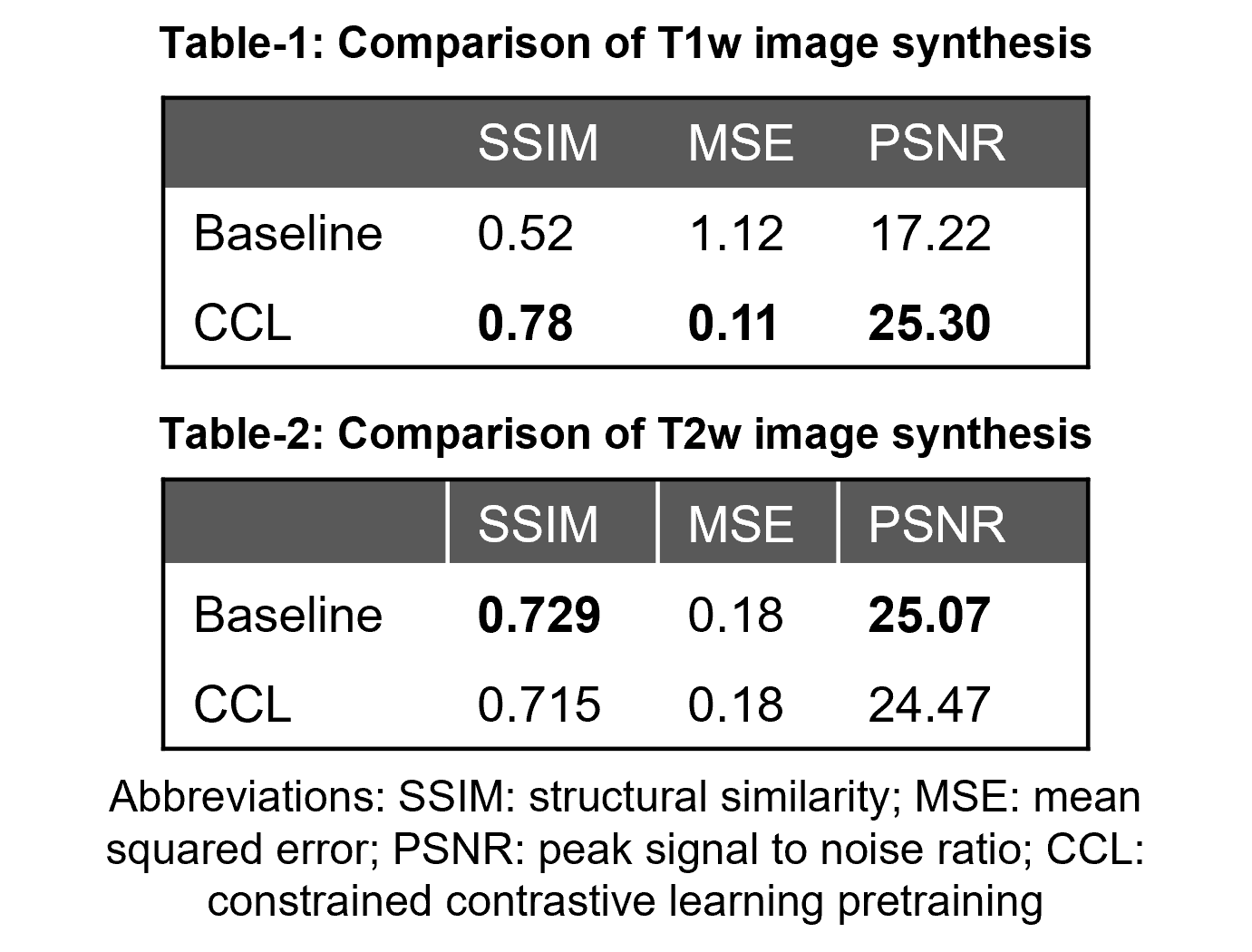
A supervised 3D U-Net (Baseline) was also trained from scratch using randomly initialized weights for comparison. Synthesis performance was assessed using mean squared error (MSE), structural similarity (SSIM), and peak signal to noise ratio (PSNR) on a test set (n=5).
Results
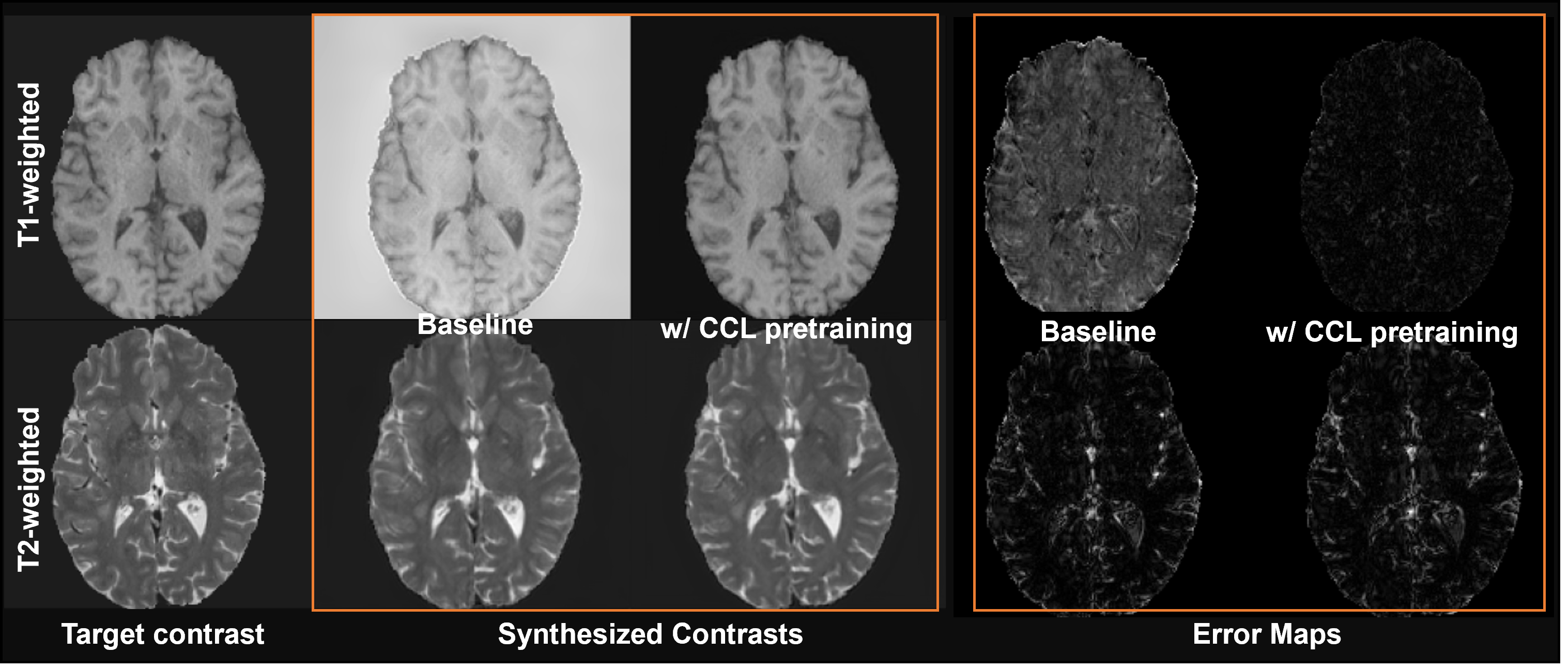
Figure 4 compares the performance of Baseline and the CCL-pretrained model to the reference T1w and T2w contrasts. A quantitative comparison (Tables 1-2) shows that synthesized contrasts generated from CCL pretraining have lower MSE, higher SSIM and PSNR values on average when compared to no pretraining. This is also evident in the error maps where the CCL performs better on both contrasts whereas the Baseline has comparable performance on T2w images but performs poorly in synthesizing T1w images.In this work, a self-supervised contrastive learning approach to characterize tissue contrast information was used to improve subsequent synthesis of new MR contrast images. The results show the potential of embedding underlying tissue characteristics in a DL model. Representational space embedded with relevant MR contrast information can not only improve downstream contrast synthesis tasks but could also have implications in improving other components of the MR imaging pipeline including DL-based image segmentation and reconstruction frameworks.
Conclusion
The use of MR-contrast based constraints to learn contrast synthesis with a few examples demonstrates the wider applicability of embedding tissue-specific information in improving different aspects of the imaging pipeline.Acknowledgements
This work was performed under the rubric of the Center for Advanced Imaging Innovation and Research (CAI2R, www.cai2r.net), an NIBIB National Center for Biomedical Imaging and Bioengineering (NIH P41 EB017183).References
[1] Umapathy L, Keerthivasan MB, et al. Convolutional Neural Network Based Frameworks for Fast Automatic Segmentation of Thalamic Nuclei from Native and Synthesized Contrast Structural MRI. Neuroinformatics. 2022 Jul;20(3):651-664. doi: 10.1007/s12021-021-09544-5
[2] Umapathy L, Brown T, Mushtaq R, et al. Reducing annotation burden in MR: A novel MR-contrast guided contrastive learning approach for image segmentation. Med Phys. 2023;1-14. https://doi.org/10.1002/mp.16820
[3] Umapathy L, Brown T, et al. Reducing annotation burden in MR segmentation: A novel contrastive learning loss with multi-contrast constraints on local representations. Proc. ISMRM. 2023
[4] Menze BH, Jakab A, Bauer S, et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE transactions on medical imaging. 2015/10// 2015;34(10):1993-2024. doi:10.1109/TMI.2014.2377694
Figures