1399
Multimodal Approach for CDR : Vision-Language Integration for Enhanced Clinical Dementia Rating Classification in Alzheimer’s Disease1Department of Electrical and Computer Engineering, Seoul National University, Seoul, Korea, Republic of
Synopsis
Keywords: Analysis/Processing, Alzheimer's Disease, multimodal, language-text
Motivation: The diagnosis of Alzheimer's disease (AD) considers not only clinical symptoms but also various data sources, including MR imaging.
Goal(s): In this study, we used a multimodal approach to integrate both language and vision information to improve the performance of clinical dementia rating classification network.
Approach: We used contrastive pre-training with language and vision data pairs; then trained a classifier, freezing the pre-trained network during classifier training.
Results: The results show that the integrated model achieved the highest accuracy. In addition, the contrastive learning process improved the performance of the vision encoder with guidance of abundant linguistic information.
Impact: With multimodal training, we successfully integrated both vision and language information and yielded the best results with integrated model. Also, multimodal training enhanced vision encoder's performance. When limited language information was provided, the complementary information from visual information was greater.
INTRODUCTION
Alzheimer's disease (AD) is the leading cause of dementia worldwide, and its incidence is increasing, in part due to the aging of the population.1 Recently, diagnosis of AD considers not only clinical symptoms but also various data sources, including MR imaging.2 Along with the advancement of computer vision technology, numerous approaches have been developed to classify AD using MRI,3 but identifying a specific stage, such as clinical dementia rating (CDR), remains challenging with MRI data alone.4Recently, multimodal approaches have successfully integrated vision and language information.5 With the broader supervision information from language data, performance of vision encoder has been leveraged and showed astonishing performance.6 In this study, we used a multimodal approach to integrate language and vision information to improve CDR classification. The results indicate that the integrated model achieved the highest level of accuracy. Additionally, the contrastive learning process improved the performance of the vision encoder.
METHOD
[data]The OASIS-4 dataset7 was utilized. For language information, OASIS4_data_CDR meta-data was used, which includes memory and orientation, among other cognitive ability scores, in addition to the CDR. For MRI vision data, T1-weighted images were employed. Using the ANTS library tissue segmentation tool, we identified the superior aspect of the brain and extracted 120 slices caudally. In cases of multiple MRI and metadata for a subject, the pair with the closest MRI scan and CDR assessment dates were chosen. The dataset underwent refinement, resulting in 645 data pairs. Out of these, 580 pairs were incorporated in the train and validation set. The remaining 65 pairs were assigned to the test set.
[Preprocessing]
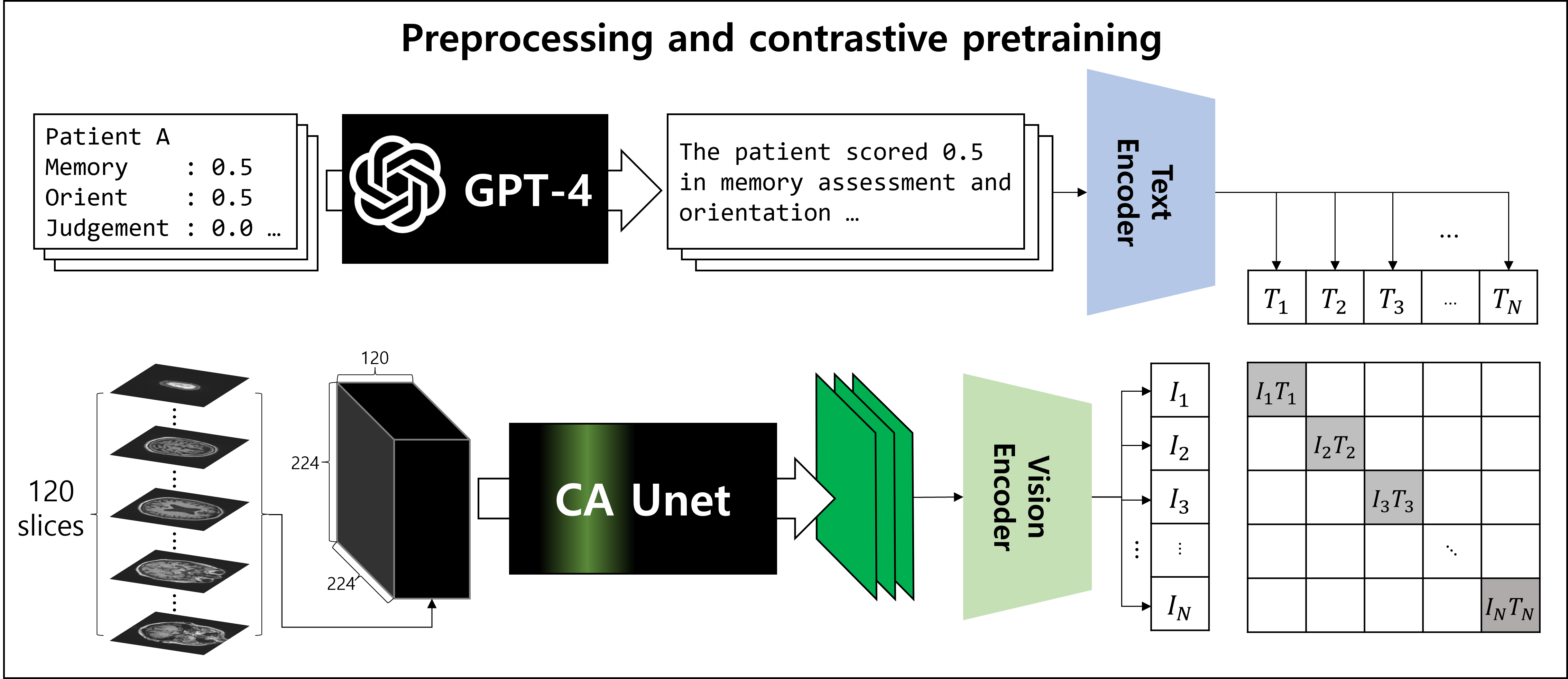
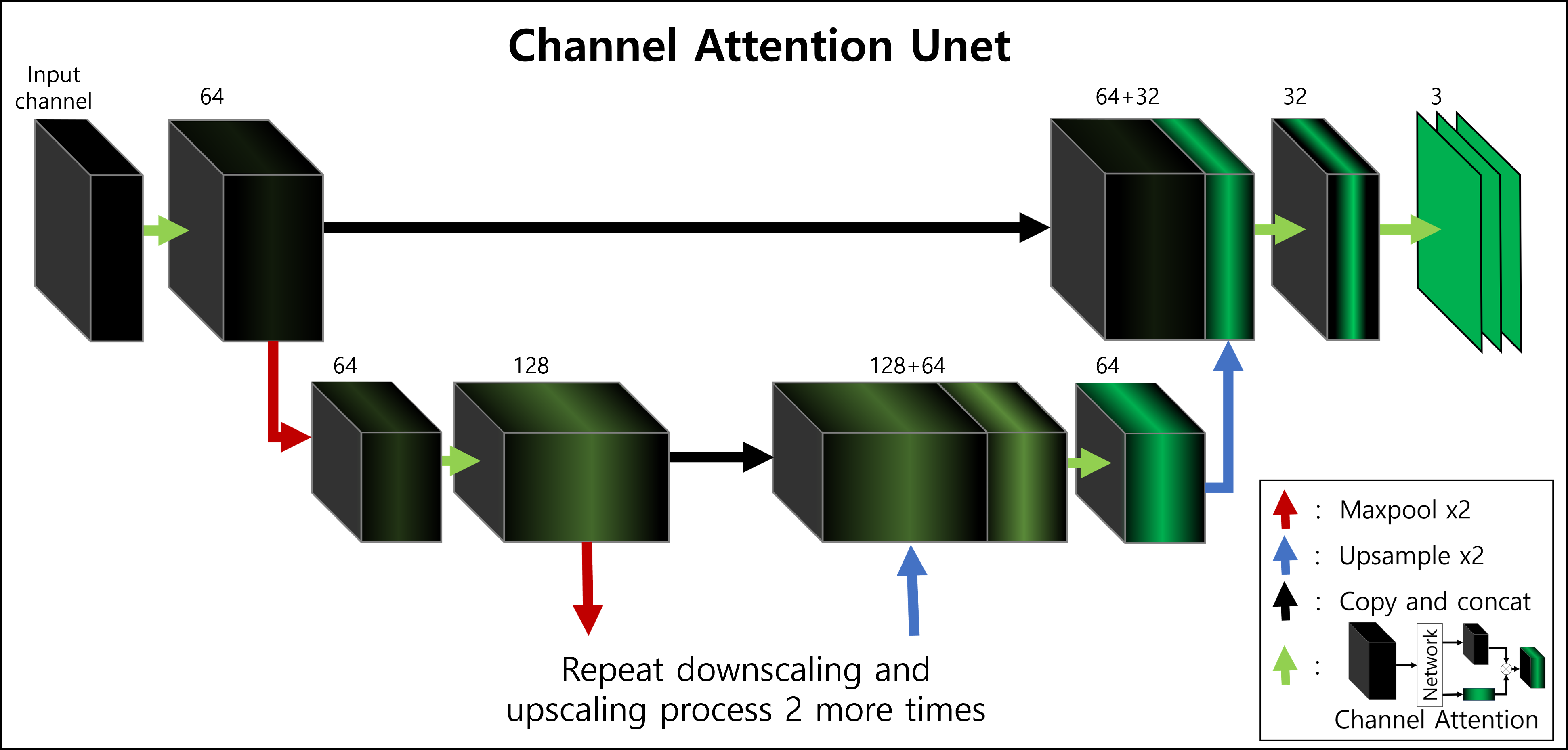
As shown in Figure 1, data was generated using GPT-4,8 with sentences manually generated and then paraphrased by GPT-4. Since MRI data are 3D and vision transformers are 2D optimized, a network combining Unet9 with Channel Attention (CA)10 was designed to transform 3D MRI inputs into 2D slices, called CA Unet in the study. (Figure 2) This model was trained to extract the three most informative slices during contrastive learning.
[Contrastive pretraining]
As also shown in Figure 1, we utilized CLIP5 technique with preprocessed data using ViT-L-14 network. The network optimized two encoders simultaneously using contrastive learning:6
$$L_{con}=-\frac{1}{N}\left(\sum_{i}\log\frac{\exp(x_{i}^{T}y_{i}/\sigma)}{\sum_{j=1}^{N}\exp(x_{i}^{T}y_{j}/\sigma)}+\sum_{i}\log\frac{\exp(y_{i}^{T}x_{i}/\sigma)}{\sum_{j=1}^{N}\exp(y_{i}^{T}x_{j}/\sigma)}\right)$$
Where xi and yj represent pairs of i-th image embeddings and j-th text embeddings, respectively. We trained for 700-epochs using one RTX4090 for 115-hours and selected the optimal results.
[Classification training]
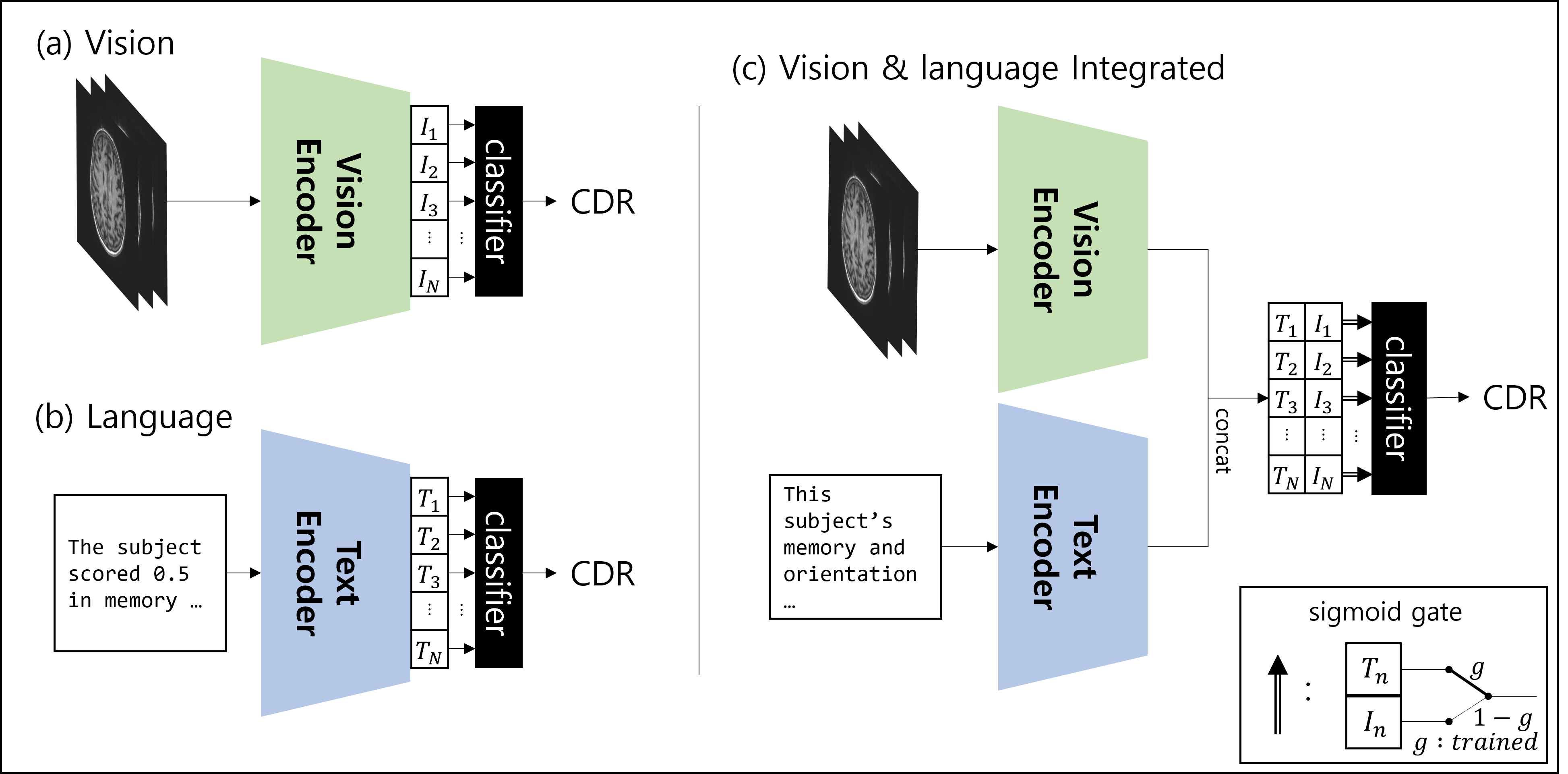
A five-layer, fully-connected-network was trained for classification using embeddings from the pre-trained network, which were frozen during classifier training. To address data imbalance, we employed weighted random sampling to ensure that the network encountered an equal ratio of classes throughout training. See Figure 3. We utilized the 10-fold cross-validation method, and calculated the average accuracy of the test set.
For vision only trained classification comparison, we utilized the identical visual encoder architecture both with and without the CA Unet. The training was conducted under the same conditions.
RESULTS
The study evaluated the accuracy of four-class CDR classification with vision-only training and multimodal training cases with vision input, language input, and integrated. With the vision-only training case, the accuracy was 42.7%, which increased to 45.2% with multimodal contrastive learning. The highest accuracy, 81.7%, was achieved with the integrated inputs, outperforming the language-only model by 1.23%. (Figure 4) In scenarios with limited language information, the integrated model outperformed single data approaches: with InfoB language input alone, accuracy was 74.8%, but with the integrated model it rose to 79.3% (4.5↑). With less informative language data (InfoA), the language model achieved 63.4% accuracy, while the integrated model achieved 69.4% (6.0↑), indicating that the advantage of the integrated model was more pronounced when the language data was less informative. (Figure 5)DISCUSSION & CONCLUSION
In our study, we employed a vision-language multimodal framework to improve the classification of the CDR in Alzheimer's disease. The findings indicate that the performance of the vision encoder is enhanced when guided by the abundance information from linguistic inputs. Moreover, the integrated model, which synergistically combines visual and language data, yielded the most superior results.This study was limited to CDR classification with related language data and MRI vision information pairs. However, AD diagnosis has been supported by various biomarker evidence such as imaging, serum and CDF.1 In addition, some research shows that some of the treatments for Alzheimer's disease may be effective in the early stages of MCI.1,11,12 Thus, not only is a definitive diagnosis of Alzheimer's disease important, but distinguishing its specific stages is also crucial for treatment. Hence, multimodal research should broaden to encompass diverse data and detailed stage subclassifications.
Acknowledgements
This work has been supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT)(No. 2021M3E5D2A01024795),
This work was supported by Samsung Electronics Co., Ltd (IO201216- 08215-01),
This work is supported by the Korea Agency for Infrastructure Technology Advancement(KAIA) grant funded by the Ministry of Land, Infrastructure and Transport (Grant 21NPSS-C163415-01) and Institute of New Media and Communications (INMC).
References
[1] Weller, J., Budson, A., 2018. Current understanding of Alzheimer’s disease diagnosis and treatment. F1000Research 7, 1161.. https://doi.org/10.12688/f1000research.14506.1
[2] Van Oostveen, W.M., De Lange, E.C.M., 2021. Imaging Techniques in Alzheimer’s Disease: A Review of Applications in Early Diagnosis and Longitudinal Monitoring. International Journal of Molecular Sciences 22, 2110.. https://doi.org/10.3390/ijms22042110
[3] Garg, N., Choudhry, M. S., & Bodade, R. M. 2023. A review on Alzheimer’s disease classification from normal controls and mild cognitive impairment using structural MR images. Journal of neuroscience methods, 384, 109745.
[4] Zhang, Y., Fan, W., Chen, X., Li, W., 2023. The Objective Dementia Severity Scale Based on MRI with Contrastive Learning: A Whole Brain Neuroimaging Perspective. Sensors 23, 6871.. https://doi.org/10.3390/s23156871
[5] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[6] Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., & Wu, Y. (2022). Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917.
[7] Koenig, L. N., Day, G. S., Salter, A., Keefe, S., Marple, L. M., Long, J., ... & Dominantly Inherited Alzheimer Network. (2020). Select Atrophied Regions in Alzheimer disease (SARA): An improved volumetric model for identifying Alzheimer disease dementia. NeuroImage: Clinical, 26, 102248.
[8] OpenAI, 2023, GPT-4 Technical Report, OpenAI (2023).
[9] Ronneberger, O., Fischer, P., Brox, T., 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation, in: Transactions on Petri Nets and Other Models of Concurrency XVII. Transactions on Petri Nets and Other Models of Concurrency XVII, pp. 234–241.. https://doi.org/10.1007/978-3-319-24574-4_28
[10] Woo, S., Park, J., Lee, J. Y., & Kweon, I. S. (2018). Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV) (pp. 3-19).
[11] Salloway, S., Sperling, R., Fox, N.C., Blennow, K., Klunk, W., Raskind, M., Sabbagh, M., Honig, L.S., Porsteinsson, A.P., Ferris, S., Reichert, M., Ketter, N., Nejadnik, B., Guenzler, V., Miloslavsky, M., Wang, D., Lu, Y., Lull, J., Tudor, I.C., Liu, E., Grundman, M., Yuen, E., Black, R., Brashear, H.R., 2014. Two Phase 3 Trials of Bapineuzumab in Mild-to-Moderate Alzheimer's Disease. New England Journal of Medicine 370, 322–333.. https://doi.org/10.1056/nejmoa1304839
[12] Doody, R.S., Thomas, R.G., Farlow, M., Iwatsubo, T., Vellas, B., Joffe, S., Kieburtz, K., Raman, R., Sun, X., Aisen, P.S., Siemers, E., Liu-Seifert, H., Mohs, R., 2014. Phase 3 Trials of Solanezumab for Mild-to-Moderate Alzheimer's Disease. New England Journal of Medicine 370, 311–321.. https://doi.org/10.1056/nejmoa1312889
Figures