1397
3D Segmentation of Subcortical Brain Structure with Few Labeled Data using 2D Diffusion Models1School of Computing, Korea Advanced Institute of Science and Technology, Daejeon, Korea, Republic of, 2Department of Radiology, Massachusetts General Hospital and Harvard Medical School, Boston, MA, United States, 3Daegu Gyeongbuk Institute of Science and Technology, Daegu, Korea, Republic of, 4Yale School of Medicine, New Haven, CT, United States
Synopsis
Keywords: Diagnosis/Prediction, Brain
Motivation: Deep learning-based segmentation methods have shown promising results; however, they require a large number of segmentation labels for training, which is very costly to obtain, especially for 3D labels.
Goal(s): Our goal is to achieve promising 3D segmentation results with few labels by exploiting the ability to capture semantic information from 2D diffusion models trained without labels.
Approach: We train simple pixel classifiers using features extracted from 2D diffusion models that have been trained with slices from three orthogonal orientations.
Results: In our experiments on the Human Connectome Project database, our proposed method outperformed conventional segmentation methods in a few labeled scenarios.
Impact: Our proposed method for segmenting subcortical brain structures can be readily applied to pre-trained diffusion models with only a few labeled data, while also generating paired segmentation labels for the images produced by diffusion models.
Introduction
Accurate segmentation of subcortical brain structures from magnetic resonance imaging (MRI) plays a critical role in quantifying volumes and monitoring longitudinal morphology changes associated with neurodegenerative disorders [1,2]. Following the success of U-Net [3], numerous deep learning-based segmentation methods have been introduced, demonstrating impressive results [4, 5]. Nevertheless, acquiring segmentation labels demands a significant time commitment from experts, and the performance of segmentation methods exhibits significant variation depending on the quantity and quality of labeled datasets.One of the efforts aimed at overcoming the challenge of training with limited labeled data is DDPM-seg [6], which leverages the advantages of denoising diffusion probabilistic models (DDPM) [7]. DDPM has demonstrated superior performance compared with other approaches, such as generative adversarial networks, in modeling image distribution [8]. DDPM-seg has shown its capability to extract high-level semantic information from the representations acquired by DDPM without the need for labels, surpassing alternative methods in few-shot scenarios based on these representations. Inspired by DDPM-seg, this work introduces a segmentation approach for subcortical brain structures that constructs 3D context from orthogonal views of 2D diffusion models. Our method yields promising 3D segmentation results, requiring a minimum of just one 3D labeled data sample.
Methods
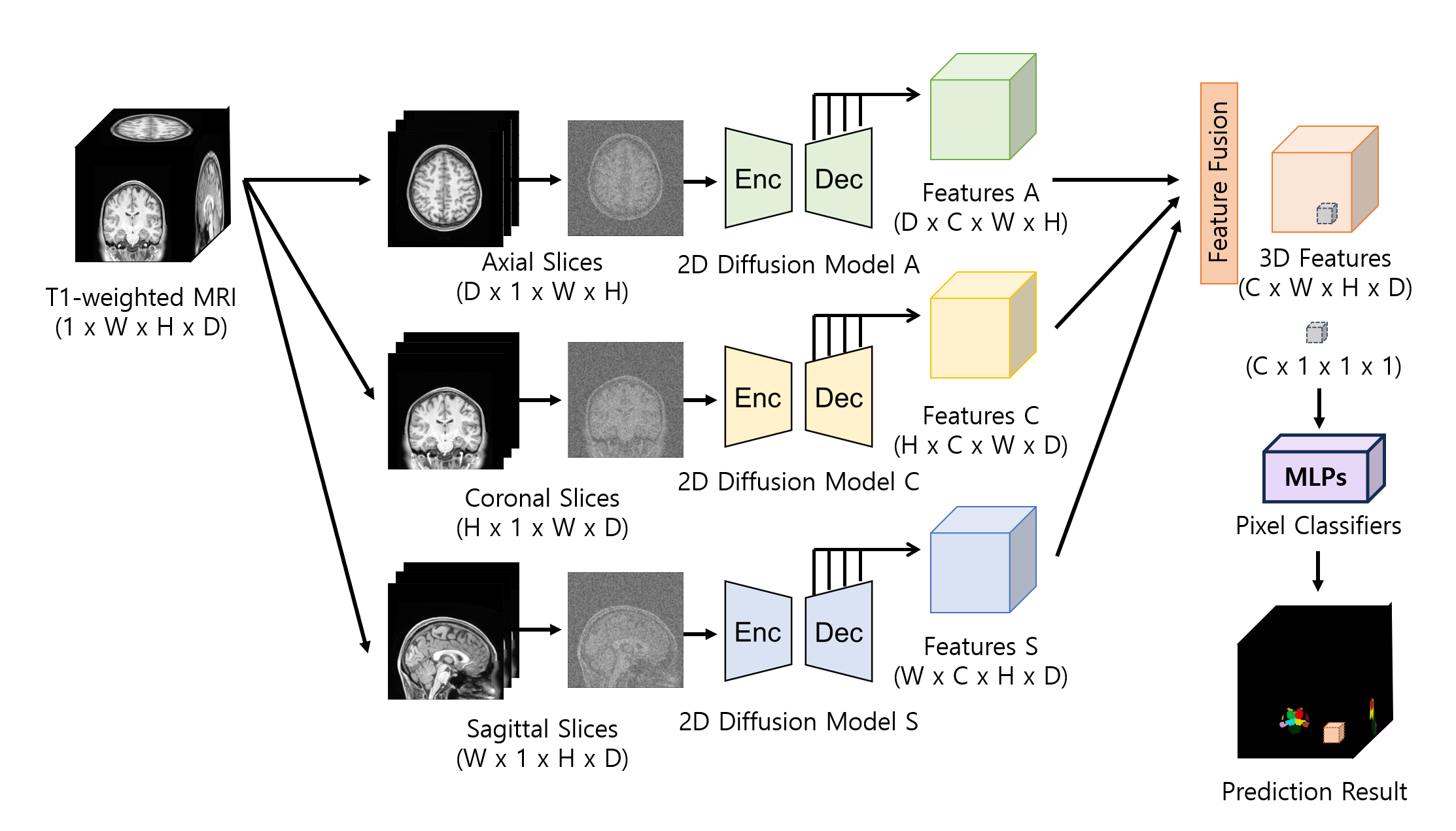
Accurately segmenting 3D images requires acquiring contextual information about the target structure. Due to the substantial computational demands of 3D diffusion models, however, the use of 2D diffusion models becomes necessary for extracting semantic information. Nonetheless, 2D diffusion models handle image slices independently, resulting in a lack of interaction between neighboring slices.To tackle this, we employ multiple 2D diffusion models that are trained using image slices from orthogonal orientations, including axial, coronal, and sagittal views. To extract the semantic representation of a volume, we partition the volume along various axes and use these slices as inputs for 2D diffusion models from different perspectives. Then, we reshape the extracted features to match the original shape of the 3D volume and combine all three sets of features, thereby extending the 2D information from each view into a comprehensive 3D contextual representation. We used these fused feature representations to train the pixel classifiers, predicting semantic labels for each pixel as in [6]. The overall structure of the proposed method is shown in Fig. 1. The pixel classifier has a simple structure of two hidden layers with ReLU activation function and batch normalization following the MLP architecture of [9]. We train ten independent classifiers using the cross-entropy loss to ensure robust prediction results through an ensemble method.
Results
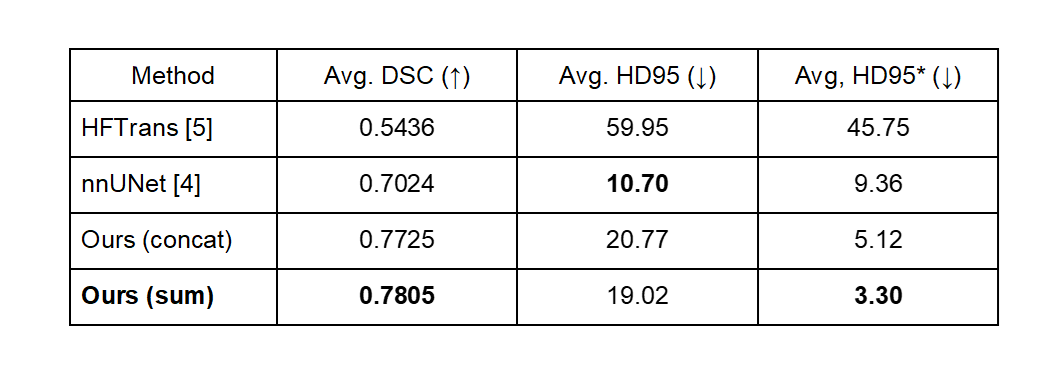
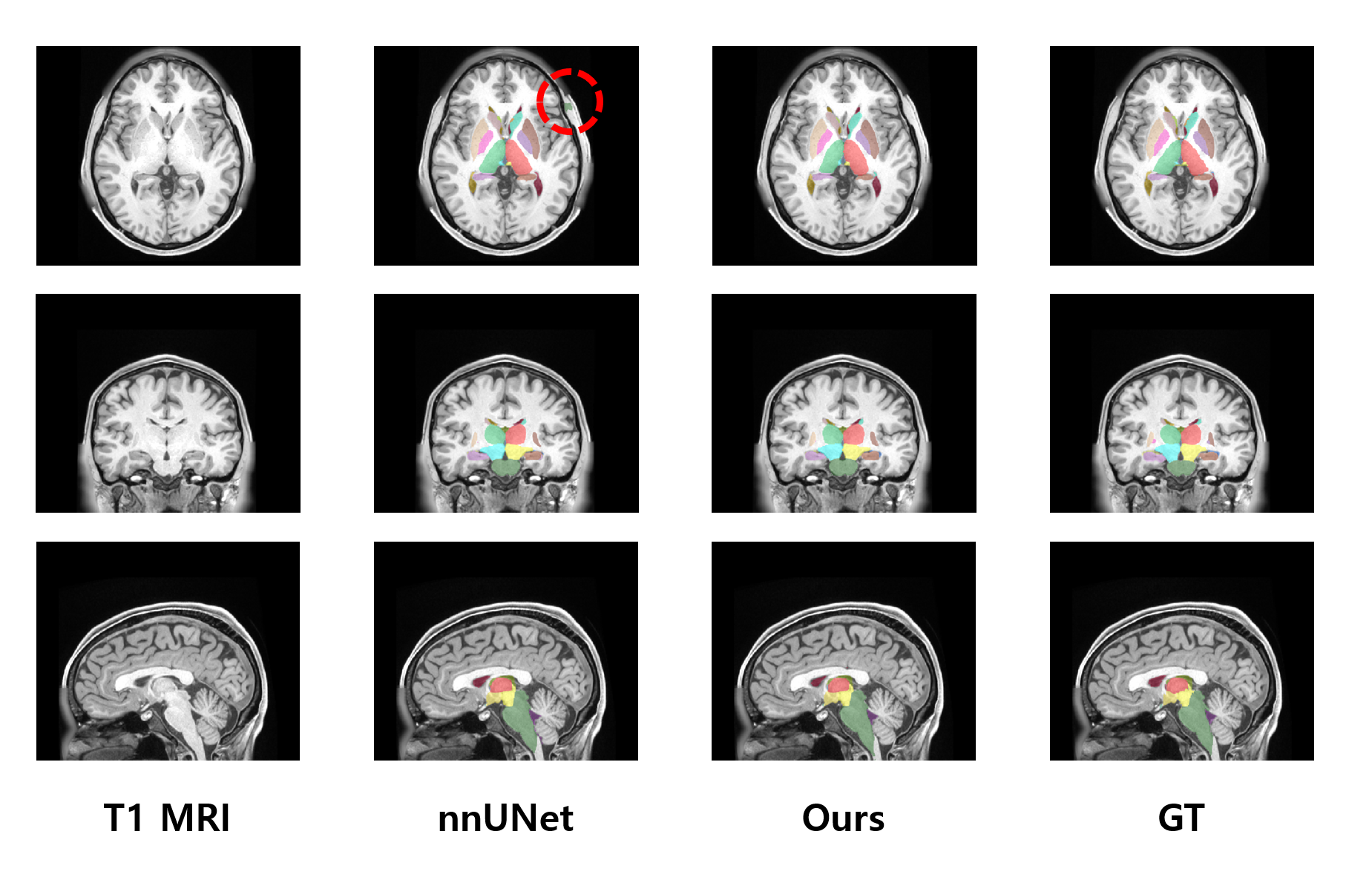
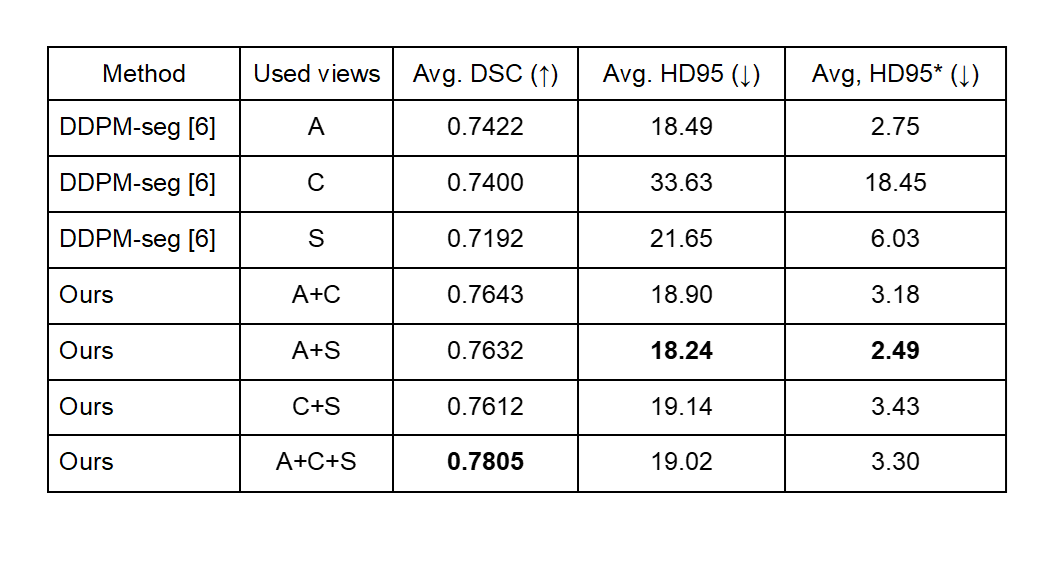
In our experiments, we used the Human Connectome Project (HCP) database, comprising 1,026 subjects with T1-weighted MRI scans, out of which 11 subjects had been manually segmented by [10]. The segmentation labels consist of a background and 28 subcortical brain structures. We trained 2D diffusion models as in [8] with a dataset comprising 1,015 unlabeled subjects, which corresponds to a total of 259,840 slices. Then, we performed training and testing of pixel classifiers using 1 and 10 labeled subjects, respectively. For the comparison, we trained and tested nnUNet [4] and HFTrans [5] using identical pixel classifier settings.As shown in Figs. 2 and 3, our proposed method yielded superior performance, even with a limited amount of labeled data, while compared segmentation methods, particularly the transformer-based approach [5], which lacks inductive bias, yielded the poorest results. It demonstrated the ability to transform 2D semantic information from diffusion models into 3D contextual semantic information. The five categories with the lowest prediction accuracy in our approach include the 5th ventricle, optic chiasm, right inferior horn of the lateral ventricle, left inferior horn of the lateral ventricle, and CSF, with corresponding Dice scores of 0.0, 0.2386, 0.6137, 0.6177, and 0.7017, respectively. In our ablation study, shown in Fig. 4, we observed that the axial view contains rich semantic information. Nevertheless, our approach can accurately capture semantic information even when the axial view is absent, as long as 3D information is constructed from any two other views.
Discussion and Conclusion
This work presented a subcortical brain structure segmentation method using a few labeled data. Specifically, we demonstrated our capacity to extract 3D information from 2D diffusion models and achieved promising results. In our future work, we will explore methods for capturing semantic information in small regions, such as the 5th ventricle, which consists of only 9 voxels in the training data.Acknowledgements
Data were provided in part by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.References
[1] Lee, J. H., Ryan, J., Andreescu, C., Aizenstein, H., & Lim, H. K. (2015). Brainstem morphological changes in Alzheimer’s disease. Neuroreport, 26(7), 411.
[2] Mak, E., Bergsland, N., Dwyer, M. G., Zivadinov, R., & Kandiah, N. J. A. A. J. N. (2014). Subcortical atrophy is associated with cognitive impairment in mild Parkinson disease: a combined investigation of volumetric changes, cortical thickness, and vertex-based shape analysis. American Journal of Neuroradiology, 35(12), 2257-2264.
[3] Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 (pp. 234-241). Springer International Publishing.
[4] Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211.
[5] Cho, J. & Park, J., (in press). Hybrid-fusion transformer for multisequence mri. In Proceedings of 2022 International Conference on Medical Imaging and Computer-Aided Diagnosis (MICAD 2022).
[6] Baranchuk, D., Rubachev, I., Voynov, A., Khrulkov, V., & Babenko, A. (2021). Label-efficient semantic segmentation with diffusion models. arXiv preprint arXiv:2112.03126.
[7] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
[8] Dhariwal, P., & Nichol, A. (2021). Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34, 8780-8794.
[9] Zhang, Y., Ling, H., Gao, J., Yin, K., Lafleche, J. F., Barriuso, A., Torralba, A., & Fidler, S. (2021). Datasetgan: Efficient labeled data factory with minimal human effort. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10145-10155).
[10] Rushmore R.J., Sunderland, K., Carrington H., Chen J., Halle M., Lasso A., Papadimitriou G., Prunier N., Rizzoni E., Vessey B., Wilson-Braun P., Rathi Y., Kubicki M., Bouix S., Yeterian E., & Makris, N. (2022). Anatomically curated segmentation of human subcortical structures in high resolution magnetic resonance imaging: An open science approach. Frontiers in Neuroanatomy, 16, 894606.
Figures