1366
Explicit network noise amplification penalty in loss function for k-space interpolation networks through fast backpropagation
1Molecular and Cellular Imaging, Comprehensive Heart Failure Center, University Hospital Würzburg, Würzburg, Germany, 2Department of Physics, University of Würzburg, Würzburg, Germany, 3Magnetic Resonance and X-ray Imaging Department, Fraunhofer Institute for Integrated Circuits IIS, Division Development Center X-Ray Technology, Würzburg, Germany
Synopsis
Keywords: Image Reconstruction, Machine Learning/Artificial Intelligence
Motivation: GRAPPA and RAKI optimize purely for data consistency, completely lacking physics-driven or model-based loss terms.
Goal(s): Recurrently feed noise amplification information into k-space interpolation networks by penalizing the online computed g-factor.
Approach: JAX-implemented GRAPPA and RAKI g-factors were estimated online in each training iteration and incorporated into the optimization as an inherent network noise amplification penalty.
Results: Networks including g-factor loss outperformed implementations optimizing only for the data consistency term. Inclusion of g-factor loss terms manifested Tikhonov regularization-like effects on image noise distribution, as revealed by difference maps to the fully sampled gold standard.
Impact: Incorporating the penalty of inherent noise amplification into k-space interpolation networks reduces reconstruction noise levels compared to implementation that optimize only for data consistency. G-factor-informed reconstructions manifest Tikhonov regularization-like effects, as revealed by noise distribution on difference maps.
Introduction
K-space interpolation networks, such as RAKI1, residual RAKI2 and iterative RAKI3, manifest superior noise resilience compared to linear methods, such as SENSE4 or GRAPPA5. However, in over-accelerated setups, variational networks6 outperform k-space interpolation networks even though they may exhibit smoothing and hallucination7. One of the possible reasons may be the model-based approach of unrolled networks, whereas RAKI optimizes only for the data consistency term in the loss function.Magnitude image denoisers benefiting from reconstruction-specific noise priors8 outperform simple denoisers, as they account for the changed reconstruction-induced spatial noise distribution.
Here, we introduce an upgraded GRAPPA and RAKI loss function including an inherent network noise amplification term via the recurring image-space g-factor formalism estimated through fast backpropagation on the computational graph.
Methods
Gradient descent-optimized GRAPPA and RAKI were implemented in JAX9, relying heavily on JAX's function-based approach. This allowed an arbitrary number of gradient computations on the retained computational graph while still avoiding vanishing gradients. In a parallel workflow, Conv2D k-space weights were transferred to image space10. Activations were applied in k-space, projecting back and forth between image and k-space.Network noise amplification was estimated pixel-wise with end-to-end autodifferentiation11 in image space. Specifically, the ith pixel of the generalized g-factor gi is calculated as the combined Jacobian of the given pixel Ji (Eq.1). Ji ([Nc,Ny,Nx] channel and image dimensions, respectively] is computed as the pixel-wise first derivative of the output pixel (reconstructed, sum-of-squares coil combined image Ireconi [Ny,Nx] with respect to all input pixels (aliased image Ialiased [Nc,Ny,Nx] ]) (Eq.2) .
$$(1) \qquad g_{i} = \sqrt{J_{i}J_{i}^\dagger}$$
$$(2) \qquad J_{i} = \frac{\partial I^{recon}_{i}}{\partial I^{aliased}}$$
Thus, the g-factor-informed loss backpropagates twice on the computational graph, while the k-space data consistency term backpropagates only once. The net loss Lnet was computed as the weighted sum of the data consistency term Ldata and the noise penalty term Lnoise (Eq.3), using Huber loss with a delta parameter of 0.1, less sensitive to outliers than L2 norm12.
$$(3) \qquad L_{net} = L_{data} + \alpha \cdot L_{noise} = \frac{1}{N}\sum_{i=0}{N}\lVert y_i-\tilde{y}_i \rVert_{Huber} + \alpha \frac{1}{N}\sum_{i=0}^{N}\lVert g_i-\tilde{g}_i \rVert_{Huber}$$
For proof of concept, a GRAPPA kernel for acceleration factor R=2 was trained on the original ACS lines prior to network training, implemented with the standard pseudoinverse formalism. This allowed a reference R=2 g-factor map to be synthesized, providing a physically achievable noise amplification target for the network. Training workflow is depicted on Figure 1.
The g-factor was updated in runtine in each training iteration. Introducing the approximation that the pixel signal originates only from the given pixel, thus neglecting all other pixel correlations by summing image pixels, immensely accelerates gradient backpropagation on the computational graph. Eq.1 and 2 in case of the fast approximation of the generalized g-factor calculations modify as follows:
$$(5) \qquad g = \sqrt{JJ^\dagger}$$
$$(6) \qquad J = \frac{\partial \sum\limits_{i=0}\limits^{N} I^{recon}_{i}}{\partial I^{aliased}}$$
The accuracy of the fast noise standard deviation estimation was previously tested in GRAPPA and RAKI implementations using only data consistency loss terms (Figure 2).
Results
Figure 2 shows the comparison of the fast backpropagation method with the exact method, as described by Wang et al.8, on a 10 x 10 central grid. The proposed fast g-factor estimation is only exact for linear reconstructions, but is a valid approximation for high channel RAKI networks. Network parameters of the g-factor-informed loss implementations were kept in the regime where the approximation does not differ more than 3% from the exact method, resulting in 256/128/64 channels per layers for the specific implementation. Backpropagation time monitoring revealed considerable time gain, which scales linearly with the the number of pixels. Collapsing a 2D image into a single voxel allows for a ~100,000 times (~320 x 320 image pixels) faster gradient computation compared to pixel-wise sweeping, thus enabling inclusion of g-factor to the loss function.Fast backpropagation maintains noise estimation accuracy compared to gold standard pseusdo multiple replica13 (PMR), revealed by noise variation distribution and mean on Figure 3.
Figure 4 and Figure 5 show representative examples of g-factor-informed GRAPPA and RAKI performances. The network clearly optimizes on g-factor maps, inherently influencing noise amplification. Similar to Tikhonov regularization, reconstruction artifacts may be introduced, enforcing the necessity to find an optimal tradeoff between data consistency and g-factor penalty.
Discussion & Conclusion
Fast and accurate estimation of g-factor allows for online monitoring of network noise amplification in image space, raising network interpretability. Including network inherent noise amplification into the loss in a recurring manner boosts reconstruction performance, even without nonlinear activations. Possible inclusion of other image-space-based loss terms besides data consistency may beneficially contribute to k-space interpolation network performance.Acknowledgements
No acknowledgement found.References
1. Akçakaya M, Moeller S, Weingärtner S, Ugurbil K. Scan-specific robust artificial-neural-networks for k-space interpolation (RAKI) reconstruction: database-free deep learning for fast imaging. Magn Reson Med. 2019;81:439-453
2. Zhang C, Moeller S, Demirel OB, Uğurbil K, Akçakaya M. Residual RAKI: A hybrid linear and non-linear approach for scan-specific k-space deep learning. Neuroimage. 2022;256:119248.
3. Dawood P, Breuer F,Stebani J, et al. Iterative training of robust k-spaceinterpolation networks for improved imagereconstruction with limited scan specifictraining samples.Magn Reson Med.2023;89:812-827.
4. Pruessmann KP, Weiger M, Scheidegger MB, Boesiger P. SENSE: sensitivity encoding for fast MRI. Magn Reson Med. 1999;42:952-962.3.
5. Griswold MA, Jakob PM, Heidemann RM, et al. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn Reson Med. 2002;47:1202-1210.
6. Hammernik K, Klatzer T, Kobler E, Pock T, Knoll F, et al. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med. 2018;79:3055-3071.
7. Narnhofer D, Effland A, Kobler E, Hammernik K, Knoll F, Pock T. Bayesian Uncertainty Estimation of Learned Variational MRI Reconstruction. IEEE Transactions on Medical Imaging, 2022;41,:279-291.2
8. Pfaff L., Hoßbach J., Preuhs E., Arroyo Camejo S., Nickel MD., Maier A., Wuerfl T.: Training a tunable, spatially-adaptive denoiser without clean targets. Proceedings of the 30th Annual Meeting of ISMRM; 2022 Abstract Program Number 2437
9. Bradbury J, Frostig R, Hawkins P, Johnson MJ, Leary C, Maclaurin D, Necula G, Paszke A, Vanderplas J, Skye Wanderman-Milne S, Zhang Q. JAX: composable transformations of Python+NumPy programs. 2018; v0.3.13; http://github.com/google/jax
10. Breuer FA, Kannengiesser SA, Blaimer M, Seiberlich N, Jakob PM, Griswold MA. General formulation for quantitative G-factor calculation in GRAPPA reconstructions. Magn Reson Med. 2009;62(3):739-46
11. Wang X, Ludwig D, Rawson M, Balan RV, Ernst T. Estimating Noise Propagation of Neural Network Based Image Reconstruction Using Automated Differentiation. Proceedings of the 30th Annual Meeting of ISMRM; 2022 Abstract Program Number 0500
12. Gokcesu K, Gokcesu H. Generalized Huber Loss for Robust Learning and its Efficient Minimization for a Robust Statistics. ArXiv. 2021:abs/2108.12627. https://api.semanticscholar.org/CorpusID:237353039
13. Robson PM, Grant AK, Madhuranthakam AJ, Lattanzi R, Sodickson DK, McKenzie CA. Comprehensive quantification of signal-to-noise ratio and g-factor for image-based and k-space-based parallel imaging reconstructions. Magn Reson Med. 2008;60(4):895-907.
14. Virtue P. Complex-Valued Deep Learning with Applications to Magnetic Resonance Image Synthesis. Doctoral Dissertation. University of California at Berkeley; 2019.
15. Cole E, Cheng J, Pauly J, Vasanawala S. Analysis of deep complex-valued convolutional neural networks for MRI recon-struction and phase-focused applications. Magn Reson Med. 2021;86:1093-1109
Figures
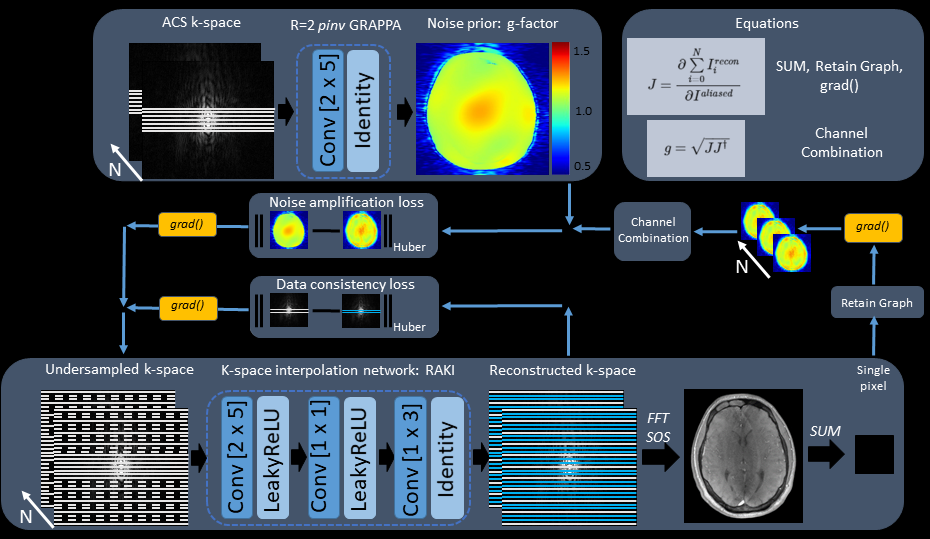
Figure 1. Training workflow of g-factor-informed k-space interpolation networks using complex Conv2D layers14,15 and complex LeakyReLU activations with alpha parameter of 0.5. The fast, online computation of noise amplification by backpropagation consists of collapsing all image pixels into a single one and computing the gradient on the retained graph of the single pixel. Returned noise maps J have equal dimension to the input, so a combination of $$$\sqrt{JJ^\dagger}$$$ is required. Pixel summation introduces linear approximation by neglecting surrounding pixel terms.
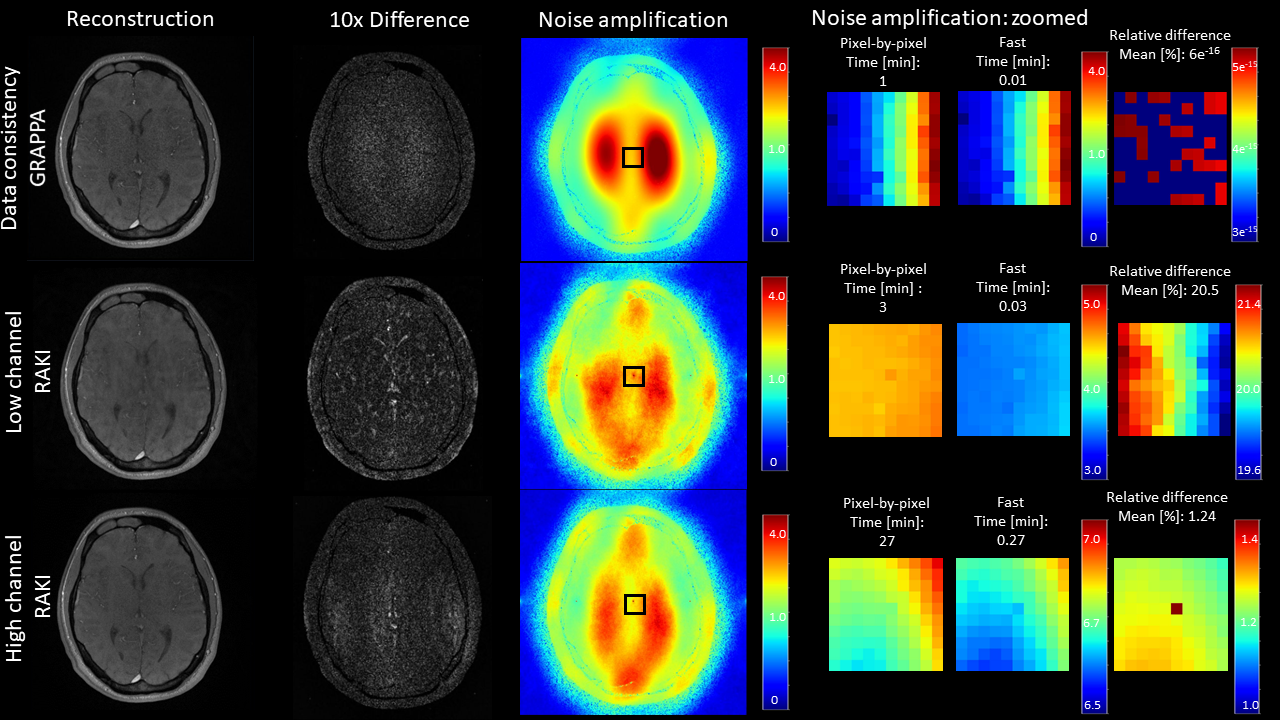
Figure 2. Comparison of the fast backpropagation method with the exact method, as described by Wang et al.8. Gradient descent GRAPPA, low channel RAKI and high channel RAKI were implemented using data loss term only, assigning 64/32/64 and 256/128/64 channels per layer, respectively. Difference maps and fast noise amplification maps provide a qualitative indication of reconstruction quality. For GRAPPA, the fast method is equivalent to the original one, while for RAKI, the approximation is valid for high channel networks.
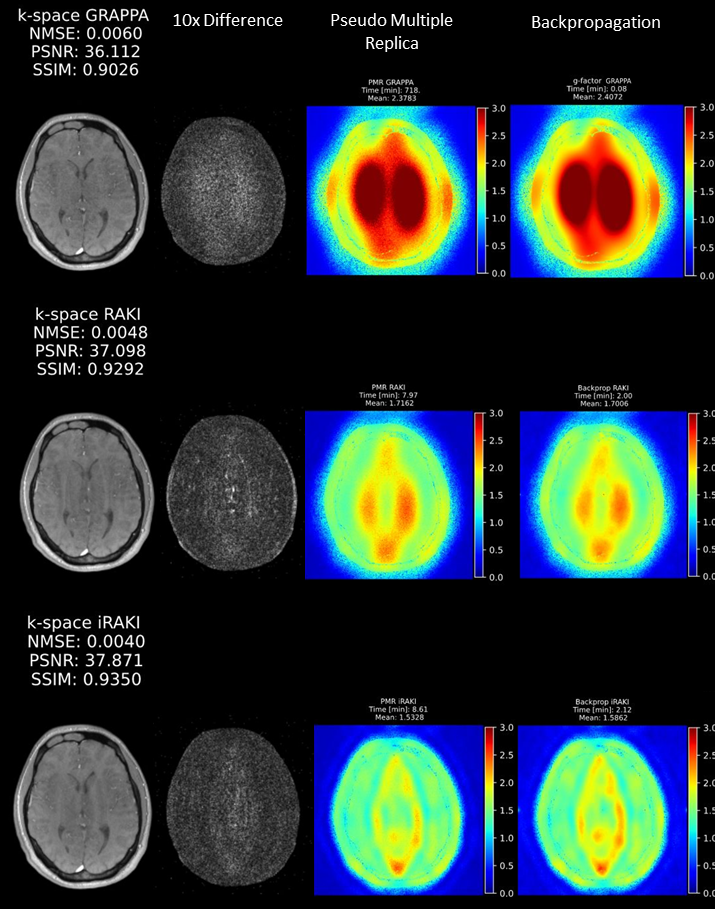
Figure 3. Comparison of the fast, online backpropagation returned noise amplification maps with the gold standard pseudo multiple replica (PMR) method. GRAPPA, RAKI and iRAKI reconstruction and difference maps to the fully sampled reference image (left), PMR and backpropagation noise maps show matcing distributions (right). Note the matching average g-factor values between the PMR and backpropagatio g-factor maps as well as the time gain for the backpropagation method.
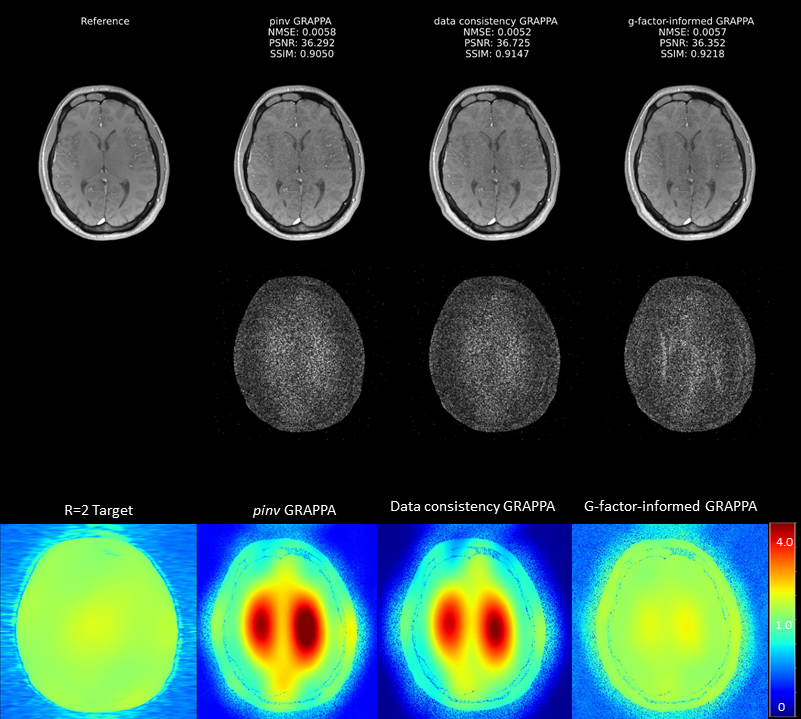
Figure 4. Comparison of GRAPPA reconstruction approaches for R=4. Structural similarity index (SSIM), peak signal-to-noise-ratio (PSNR), normalized mean squared error (NMSE) provide quantitative image quality metrics. G-factor maps and 10x amplified difference maps to fully sampled reference are to visualize spatial noise distribution. The bottom row shows the noise amplification estimated by analytical g-factor (first two columns) and by network backpropagation (last two columns).
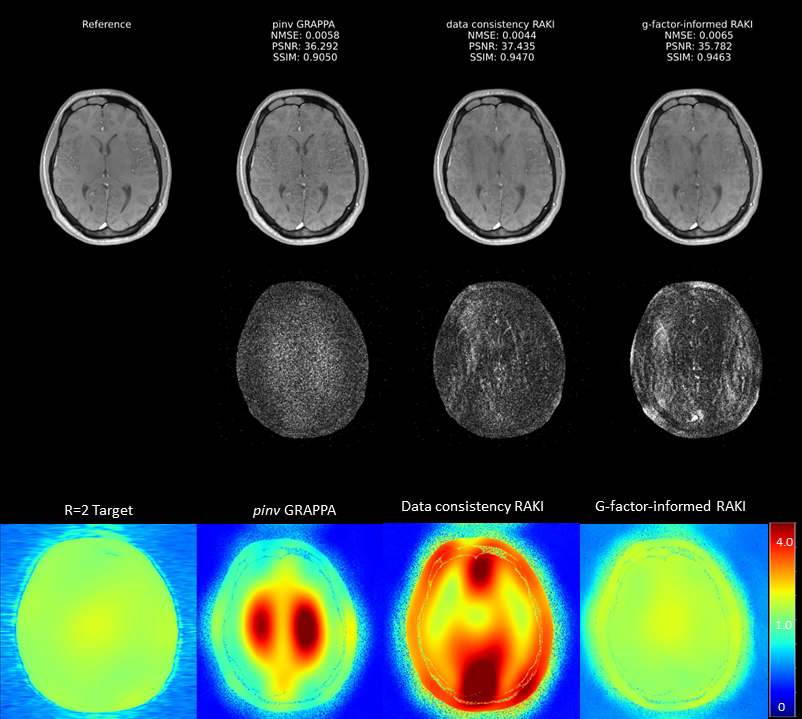
Figure 5. Comparison of RAKI reconstruction approaches for R=4. Structural similarity index (SSIM), peak signal-to-noise-ratio (PSNR), normalized mean squared error (NMSE) provide quantitative image quality metrics. G-factor maps and 10x amplified difference maps to fully sampled reference are to visualize spatial noise distribution. The bottom row shows the noise amplification estimated by analytical g-factor (first two columns) and by network backpropagation (last two columns). Note the effect of Huber loss on RAKI g-factor distribution compared to pinv GRAPPA.