1365
Simultaneous self-supervised reconstruction and denoising for low SNR, sub-sampled training data with Robust SSDU1Wellcome Centre for Integrative Neuroimaging, University of Oxford, Oxford, United Kingdom, 2Department of Medical Biophysics, University of Toronto, Toronto, ON, Canada, 3Physical Sciences, Sunnybrook Research Institute, Toronto, ON, Canada
Synopsis
Keywords: Image Reconstruction, Image Reconstruction, Deep learning, Self-supervised
Motivation: For low SNR training data, such as from low-field scanners, sub-sampled images reconstructed via deep learning can be susceptible to errors due to measurement noise.
Goal(s): To evaluate the performance of the proposed Robust Self-Supervised Learning via Data Undersampling (Robust SSDU), which removes corruptions due to aliasing and measurement noise in an entirely self-supervised manner.
Approach: On the fastMRI dataset and low-field dataset M4Raw, Robust SSDU was compared with a number of benchmarks including supervised training.
Results: Robust SSDU exhibited a substantially higher fidelity image restoration than standard SSDU and sharper reconstructions than competing methods that remove measurement noise.
Impact: This study demonstrates that high quality image reconstruction with deep learning is achievable when only sub-sampled, low SNR data is available for training. The proposed method could particularly impact the diagnostic potential of images acquired from low field scanners.
Introduction
Reconstruction methods that use deep learning usually rely on a fully sampled, high SNR data set for training, which in many circumstances is impractical or even infeasible to obtain1-3. Although progress has been made towards self-supervised methods that require sub-sampled data only4-6, such methods are typically susceptible to reconstruction errors arising from measurement noise7. In response, we propose Robust SSDU8, which extends the popular reconstruction method Self-Supervised Learning via Data Undersampling (SSDU)4 to noisy data by simultaneously removing corruptions due to sub-sampling and measurement noise in an entirely self-supervised manner, so that high quality images are recovered when only sub-sampled, noisy data is available for training.Method
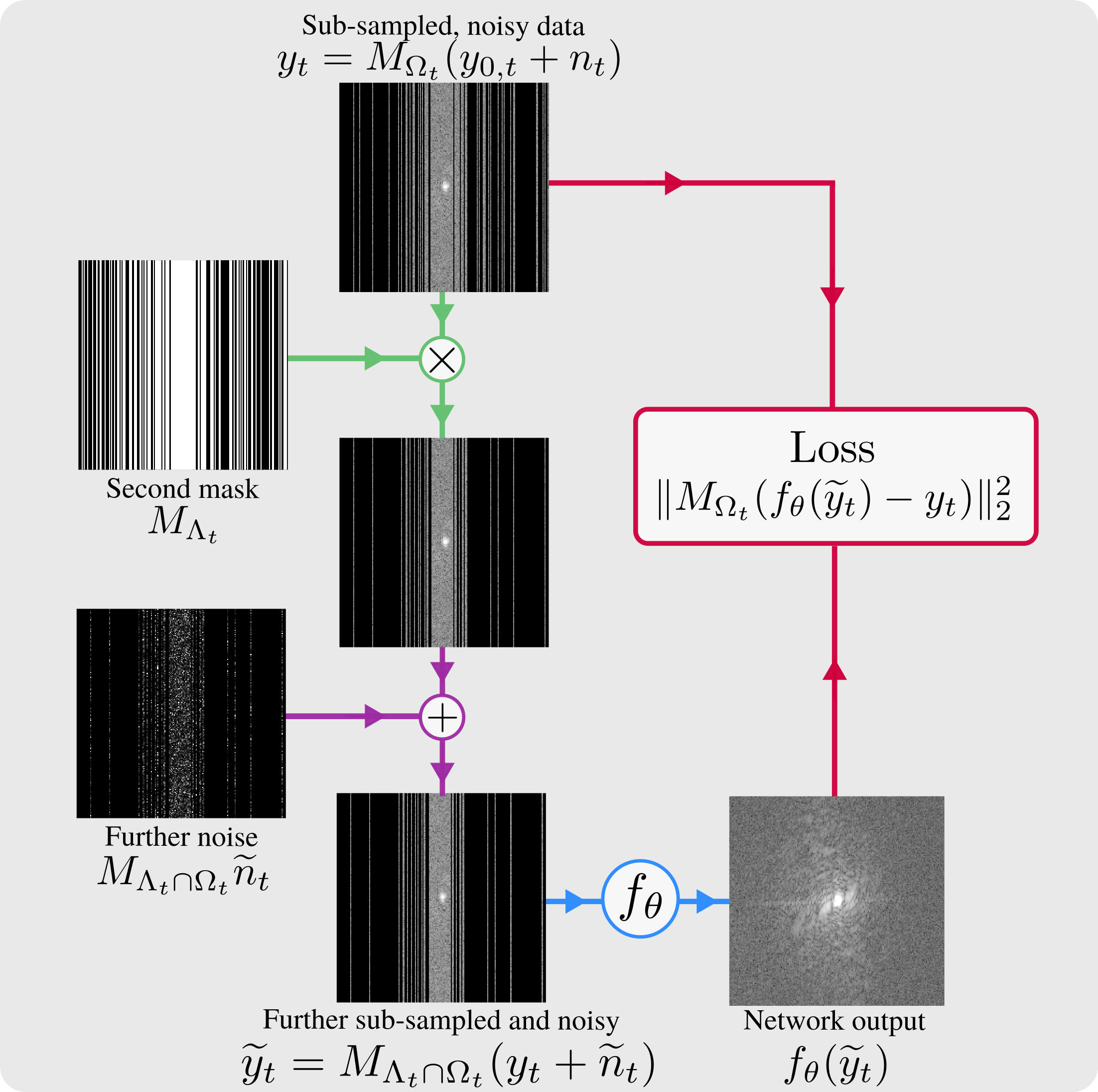
Robust SSDU is a network-agnostic method that recovers noise-free images from sub-sampled and noisy k-space data, simultaneously estimating missing k-space samples and denoising the available samples. To train a network from such data, Robust SSDU introduces further sub-sampling and further noise to the training data: see figure 1. Then the further corrupted data is passed through a reconstruction network and the loss is computed between the output and the singly sub-sampled, noisy data on the non-zero indices of k-space. At inference, the image is estimated by applying an additive Noisier2Noise correction on the sampled indices of k-space to the network output8,9.We validated the performance of the method on the fastMRI dataset11 and on the 0.3T dataset M4Raw12. For the fastMRI dataset, the data was treated as clean and noisy conditions were simulated with additive white complex multi-channel Gaussian noise. For the low SNR M4Raw dataset, no further noise was added; the noise covariance matrix was estimated using the fully-sampled image via a $$$30\times 30$$$ square of background from each corner and the data was whitened with the inverse covariance matrix. The data was retrospectively sub-sampled column-wise with the probability density set to achieve a desired sub-sampling factor $$$R_\Omega$$$.
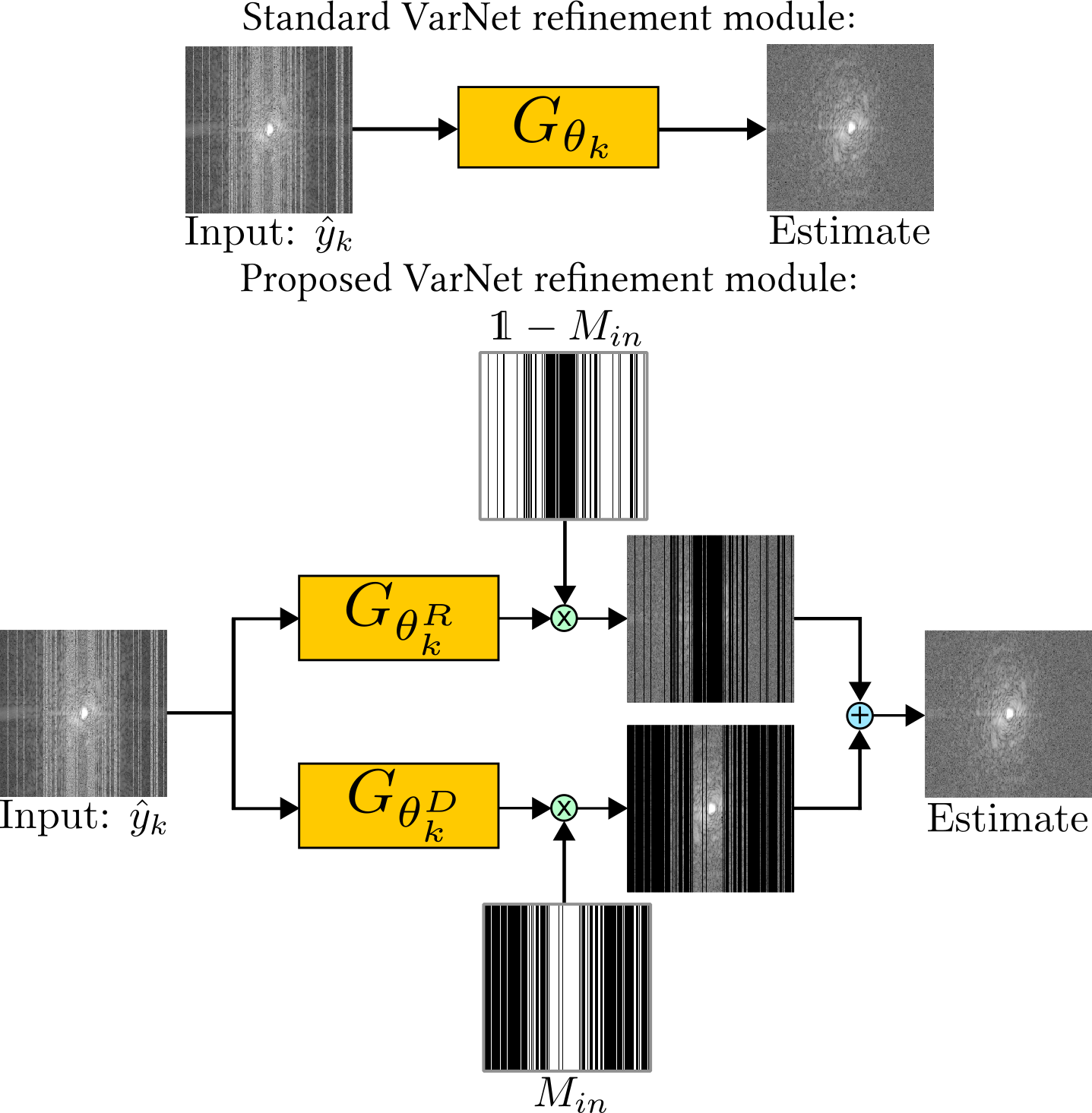
We used a column-wise second mask with sub-sampling factor 2 and further noise standard deviation matching the original noise8,13. We compared Robust SSDU with Standard SSDU, which does not remove measurement noise, and the noise-robust method Noise2Recon-SS7. For both SSDU and Robust SSDU, we used the entry-wise loss weightings based on the sampling densities and further noise distributions that have previously been shown to improve performance and robustness to hyperparameters8,13. For the M4Raw dataset, we also passed the magnitude estimate of SSDU through the untrained denoisier BM3D14,15, using the squared error with the reference acquired via multiple averages as the noise variance estimate. We also trained using supervised reconstruction, where fully sampled, noisy data was available for training, referred to as “Supervised to Noisy”, and for the fastMRI dataset a “Best-case Benchmark” trained on clean, fully sampled data. We used a novel modification of the Variational Network (VarNet) architecture8,16 designed for simultaneous reconstruction and measurement noise removal, as detailed in figure 2. The network was trained from scratch for 50 epochs using the Adam optimizer17 with learning rate $$$10^{-3}$$$.
Results and Discussion
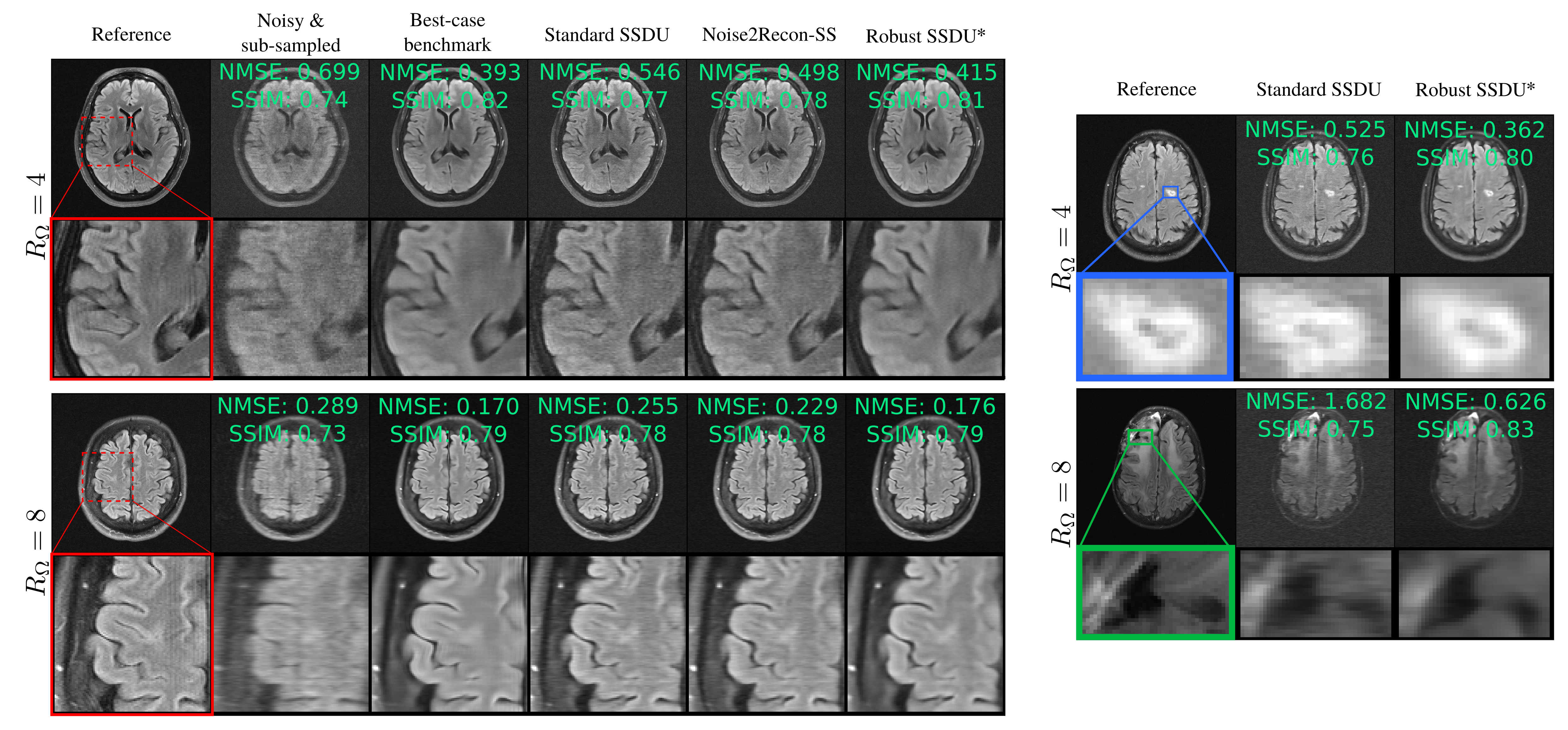
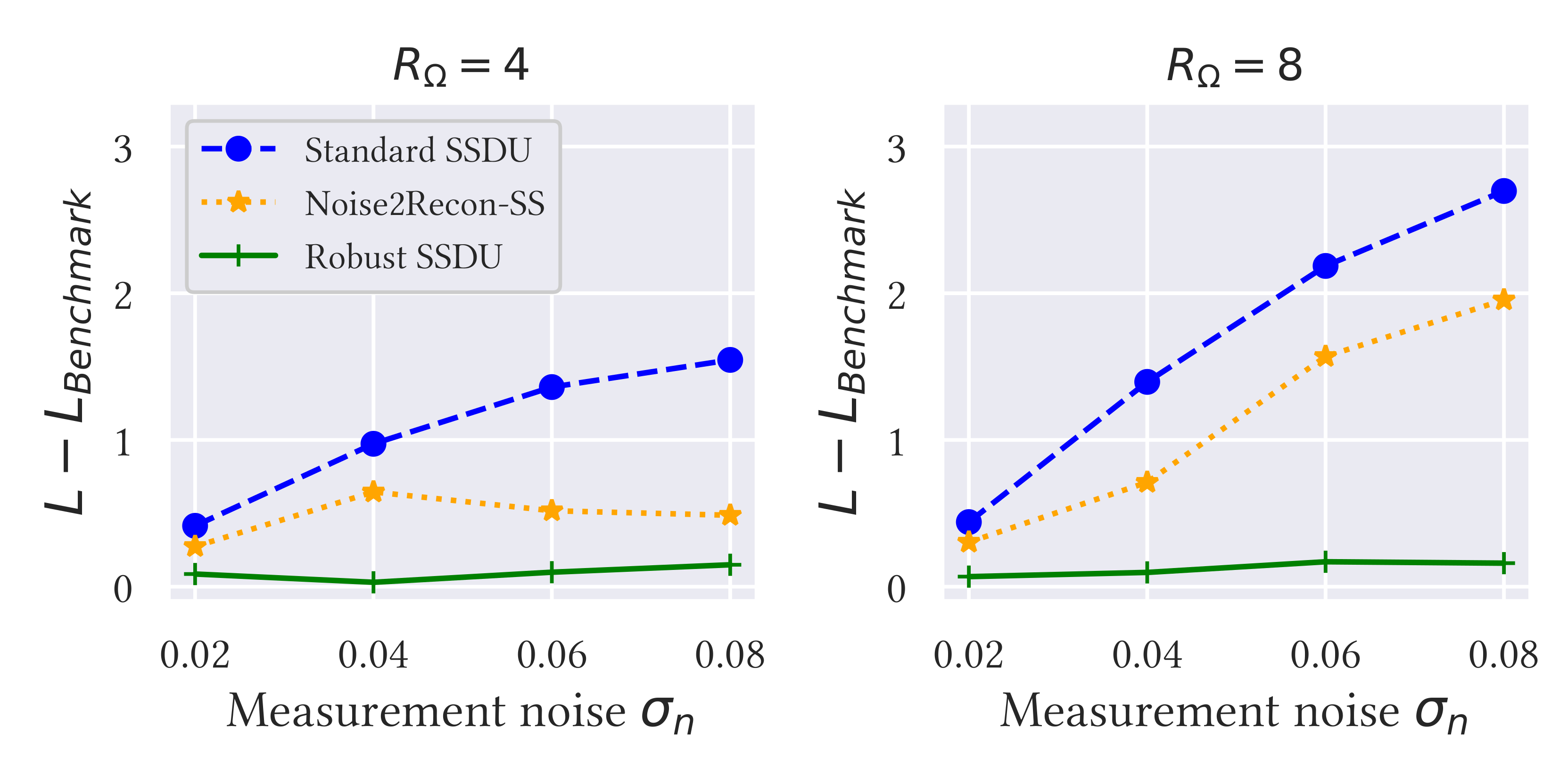
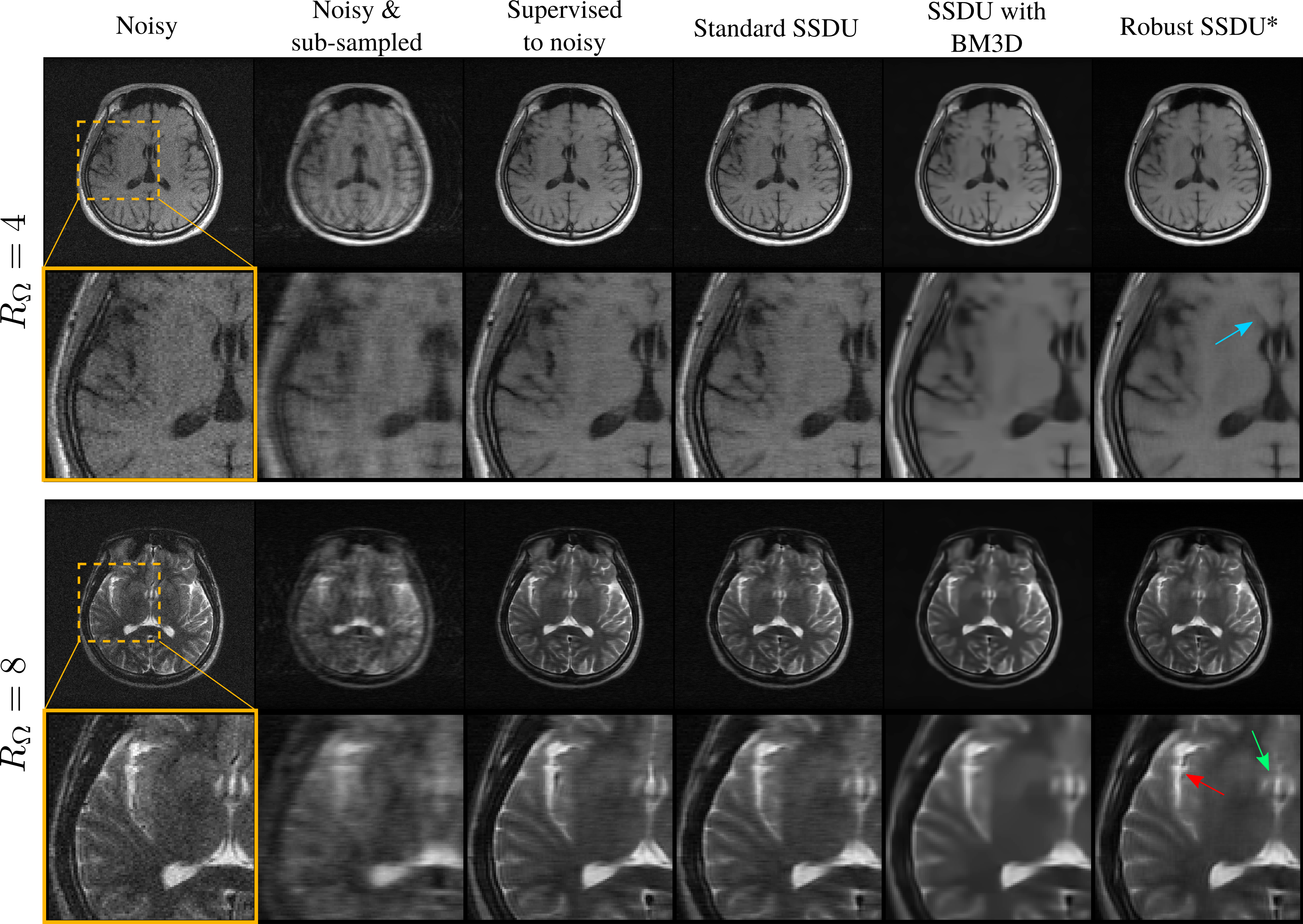
Figure 3 shows example reconstructions for the fastMRI dataset and figure 4 shows the Normalized Mean Squared Error (NMSE) in k-space on the test set for a number of simulated noise levels. Figure 5 shows reconstruction examples from the M4Raw dataset.Supervised to noisy and Standard SSDU perform comparably qualitatively, removing corruption due to sub-sampling but exhibiting substantial residual corruptions due to measurement noise. Noise2Recon-SS offers some improvement over Standard SSDU quantitatively, but only has a moderate denoising effect visually. Robust SSDU performed within 0.05dB of the best-case benchmark for all noise levels, and was very similar to the best-case benchmark qualitatively: see figures 3 and 4. Figure 5 demonstrates that SSDU with BM3D also removes measurement noise, however, it over-smooths and has poorer sharpness at tissue boundaries than Robust SSDU, which may be due to the mismatch between the distribution of the actual error and BM3D’s zero-mean Gaussian model. Robust SSDU was also more computationally efficient than SSDU with BM3D at inference: its reconstruction time was similar to SSDU, while SSDU with BM3D required around 100 times longer per slice.
Conclusions
Robust SSDU is a network-agnostic training method that simultaneously reconstructs sub-sampled k-space while removing measurement noise, performing comparably to the best-case benchmark on the fastMRI dataset for a range of measurement noise levels despite having access to noisy, sub-sampled training data only. Its performance was also validated on the prospectively noisy M4Raw dataset, demonstrating improved reconstruction sharpness and computational efficiency compared to SSDU with BM3D denoising.Acknowledgements
This work was supported in part by the Engineering and Physical Sciences Research Council,grant EP/T013133/1, by the Royal Academy of Engineering, grant RF201617/16/23, and by the Wellcome Trust, grant 203139/Z/16/Z. The computational aspects of this research were supported by the Wellcome Trust Core Award Grant Number 203141/Z/16/Z and the NIHR Oxford BRC. The views expressed are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health. This research was undertaken, in part, thanks to funding from the Canada Research Chairs Program.References
1. M. Uecker, S. Zhang, D. Voit et al, “Real-time MRI at a resolution of 20 ms,” NMR in Biomedicine, vol. 23, no. 8, pp. 986–994, 2010.
2. H. Haji-Valizadeh, A. A. Rahsepar, J. D. Collins et al, “Validation of highly accelerated real-time cardiac cine MRI with radial k-space sampling and compressed sensing inpatients at 1.5 T and 3T,” Magnetic resonance in medicine, vol. 79, no. 5, pp. 2745–2751, 2018.
3. Y. Lim, Y. Zhu, S. G. Lingala et al, “3D dynamic MRI of the vocal tract during natural speech,” Magnetic resonance in medicine, vol. 81, no. 3, pp. 1511–1520, 2019.
4. B. Yaman, S. A. H. Hosseini, S. Moeller et al,“Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data,” Magnetic resonance in medicine, vol. 84, no. 6, pp. 3172–3191,2020.
5. D. Chen, J. Tachella, and M. E. Davies, “Equivariant imaging: Learning beyond the range space,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4379–4388, 2021.
6. H. K. Aggarwal, A. Pramanik, and M. Jacob, “ENSURE: Ensemble Stein’s unbiased risk estimator for unsupervised learning,” in IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP), pp. 1160–1164, 2021.
7. A. D. Desai, B. M. Ozturkler, C. M. Sandino et al, “Noise2Recon: Enabling SNR-robust MRI reconstruction with semi-supervised and self-supervised learning,” Magnetic Resonance in Medicine, 2023.
8. C. Millard and M. Chiew, “Clean self-supervised MRI reconstruction from noisy, sub-sampled training data with Robust SSDU,” arXiv preprint arXiv:2210.01696, 2023.
9. N. Moran, D. Schmidt, Y. Zhong, and P. Coady, “Noisier2Noise: Learning to denoise from unpaired noisy data,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12064–12072, 2020.
10. J. Lehtinen, J. Munkberg, J. Hasselgren et al, “Noise2Noise: Learning image restoration without clean data,” arXiv preprint arXiv:1803.04189, 2018.
11. J. Zbontar, F. Knoll, A. Sriram et al, “fastMRI: An open dataset and benchmarks for accelerated MRI,” arXiv preprint arXiv:1811.08839, 2018.
12. M. Lyu, L. Mei, S. Huang et al, “M4Raw: A multi-contrast, multi-repetition, multi-channel MRI k-space dataset for low-field MRI research,” Scientific Data, vol. 10, no. 1, p. 264, 2023.
13. C. Millard and M. Chiew, “A theoretical framework for self-supervised MR image reconstruction using sub-sampling via variable density Noisier2Noise,” IEEE transactions on computational imaging, 2023.
14. K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-D transform-domain collaborative filtering.,” IEEE transactions on image processing : a publication of the IEEE Signal Processing Society, vol. 16, pp. 2080–95, 2007.
15. N. Koonjoo, B. Zhu, G. C. Bagnall et al, “Boosting the signal-to-noise of low-field MRI with deep learning image reconstruction,” Scientific reports, vol. 11, no. 1, p. 8248, 2021.
16. K. Hammernik, T. Klatzer, E. Kobler et al, “Learning a variational network for reconstruction of accelerated MRI data,” Magnetic resonance in medicine, vol. 79, no. 6, pp. 3055–3071, 2018.
17. D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
18. O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 234–241, Springer, 2015.
19. R. Zhao, B. Yaman, Y. Zhan et al, “fastMRI+, Clinical pathology annotations for knee and brain fully sampled magnetic resonance imaging data,” Scientific Data, vol. 9, no. 1,p. 152, 2022.
Figures