1207
Assessing Machine Learning Robustness in MRS Quantification: Impact of Training Strategies on Out-of-Distribution Generalization1Department of Electrical Engineering, Eindhoven University of Technology, Eindhoven, Netherlands, 2Center for Biomedical Imaging, Ecole Polytechnique Fédérale de Lausanne, Lausanne, Switzerland, 3Department of Radiology and Nuclear Medicine, Amsterdam University Medical Center, Amsterdam, Netherlands, 4Center for Urban Mental Health, University of Amsterdam, Amsterdam, Netherlands, 5Cancer Center Amsterdam, Imaging and Biomarkers, Amsterdam, Netherlands
Synopsis
Keywords: Analysis/Processing, Spectroscopy, ML Robustness, MRS Quantification
Motivation: Despite promising developments, current machine learning methods for magnetic resonance spectroscopy (MRS) suffer from limited robustness and generalization issues, restricting their clinical application.
Goal(s): This study compares training strategies for MRS quantification, focusing on neural network resilience to out-of-distribution samples.
Approach: Bias towards the training distribution was assessed for various out-of-distribution cases in synthetic data and in-vivo data.
Results: Our findings reveal that, while common supervised regression is most accurate for in-distribution cases, it shows the most data bias; physics-informed self-supervised training is more robust; while integrating a least-squares fitting method within the training framework enhances standalone performance while remaining generalizable.
Impact: To advance integration in clinical MRS, robust and generalizable machine learning methods are needed. This study's exploration of quantification training strategies offers insights into data biases and advocates hybrid models that combine traditional methods with neural networks to maintain robustness.
Introduction
Machine learning (ML) methods for magnetic resonance spectroscopy (MRS) can accurately estimate the concentration of metabolites, especially the low-concentration ones. However, concerns regarding the reliability and sensitivity to unfamiliar data persist 1,3. Previously, supervised regression methods with convolutional neural networks (CNNs) have been used 4-7, but due to a lack of representative ground-truth data such methods are poorly generalizable. An alternative training strategy employed to train NNs incorporates a physics-based signal model into the neural architecture, allowing self-supervised regression to quantify metabolites 8,9. As such methods learn the underlying physics models, they have greater potential to be generalizable. Here, we propose an alternative hybrid model-based/data-driven method that incorporates the iterative least-squares (LS) fitting into the gradient-based optimization framework.This work presents a comparative study of ML training strategies for metabolite quantification in MRS, analyzing the bias toward training distribution, robustness toward deviations, and generalization to simulated out-of-distribution scenarios and in-vivo data. Supervised and self-supervised training strategies are compared to LS fitting using linear combination modeling (LCM) and our hybrid model-based/data-driven method.
Methods
To effectively analyze the performance and reliability of the mentioned methods, human brain spectra at 7T using the semi-LASER sequence are simulated. The MRS signal model employed for the simulation takes the following form: $$ X_{\boldsymbol{\theta}}(f) = e^{i \phi_0} \sum^{M}_{m=1} a_{m} \mathcal{F} \left\{s_{m}(t) \ e^{- (i \epsilon + \gamma + \sigma^2 t) t} \right\} + B(f). $$The simulated data is obtained by randomly drawing the model parameters $$$\theta=\{a_1, ..., a_M, \gamma, \sigma, \epsilon, \phi_0, b_1, .., b_{2K} \}$$$ from uniform distributions (listed in Figure 1) along with adding Gaussian noise to the spectra (peak SNR ranging from 5 to 15 dB). To increase data variability, each batch is simulated ad-hoc during training creating an unlimited training dataset.To compare the generalization and robustness of data-driven quantification methods, a simple multi-layer perceptron (MLP), depicted in Figure 2, was developed for signal parameter estimation. The same network structure was trained for all training strategies illustrated in Figure 2. In the common supervised setting, the MLP is trained with the mean absolute error (MAE) of the system parameters and their estimates. For the self-supervised setting, the knowledge of the underlying signal model is utilized to map the estimated parameters to their corresponding spectrum which is compared to the input spectrum with the mean squared error (MSE). The hybrid training strategy is applied making use of a differentiable LS fitting approach using LCM to iteratively find the parameters that best describe the input data, and backpropagating through the entire unrolled structure to update the NNs weights. Lastly, the standard purely model-based LCM method is a proprietary implementation based on LS and the BFGS algorithm. All mentioned methods estimate relative metabolite concentrations which are optimally scaled to representative absolute values (corresponding to an oracle water referencing).
Results & Discussion
Figure 3 shows the estimated and ground truth concentrations for selected metabolites for a test dataset consisting of 10,000 samples drawn from identical parameter distributions to the training distribution. The obtained MAEs for the entire dataset are 1.20, 0.81, 0.99, and 0.96mM for model fitting, supervised, self-supervised, and hybrid LS fitting, respectively. For lower-concentration metabolites, all methods show an increased bias toward the mean of the distribution.In Figure 4 the datasets are created from the training parameter distributions (dashed lines represent the boundaries), yet a single signal parameter is taken out-of-distribution for different parameters. All methods show degrading performance for an increase in amplitude, noise, and broadening. However, the supervised method shows a clear bias towards its training distribution with severe performance degradation out-of-distribution. The self-supervised methods performance indicates better generalization, specifically for NAA amplitude changes, yet remains similarly biased to seen values. The hybrid LS fitting significantly reduces training bias and allows for more reliable performance out-of-distribution.
Figure 5 shows the estimated concentrations against LCModel estimates relative to total Creatine for selected metabolites for up to 164 in-vivo samples (only concentration estimates were considered that obtained a CRLB percentage value of below 20%). It is observed that the purely data-driven methods have more narrow marginal distributions indicating a data bias and a lack of confidence for unknown scenarios, whereas the model fitting and hybrid LS fitting show more variability in their estimates, and the hybrid method’s and LCModel’s marginal distributions show the most overlap.
Conclusion
The presented comparison of training approaches highlights the critical need for more attention to ML robustness, particularly in handling abnormal, out-of-distribution scenarios. Moreover, the exploration of hybrid methods, merging traditional algorithms with NNs, shows promise in addressing these limitations.Acknowledgements
This work was (partially) funded by Spectralligence (EUREKA IA Call, ITEA4 project 20209).References
1. Rudy Rizzo, Martyna Dziadosz, Sreenath P. Kyathanahally, Amirmohammad Shamaei, and Roland Kreis. “Quantification of MR spectra by deep learning in an idealized setting: Investigation of forms of input, network architectures, optimization by ensembles of networks, and training bias.” Magnetic Resonance in Medicine 89 (2022): 1707 - 1727.
2. Rudy Rizzo, Martyna Dziadosz, Sreenath P. Kyathanahally, Mauricio Reyes, and Roland Kreis. “Reliability of Quantification Estimates in MR Spectroscopy: CNNs vs Traditional Model Fitting.” International Conference on Medical Image Computing and Computer-Assisted Intervention (2022).
3. Dennis M. J. van de Sande, Julian P. Merkofer, Sina Amirrajab, Mitko Veta, Ruud J. G. van Sloun, Maarten J. Versluis, Jacobus F. A. Jansen, Johan S. van den Brink, and Marcel M. Breeuwer. “A review of machine learning applications for the proton MR spectroscopy workflow.” Magnetic Resonance in Medicine 90 (2023): 1253 - 1270.
4. Nima Hatami, Michaël Sdika, and Hélène Ratiney. “Magnetic Resonance Spectroscopy Quantification using Deep Learning.” International Conference on Medical Image Computing and Computer-Assisted Intervention (2018).
5. Amirmohammad Shamaei, Jana Starčuková, and Zenon Starcuk. “A Wavelet Scattering Convolutional Network for Magnetic Resonance Spectroscopy Signal Quantitation.” International Conference on Bio-inspired Systems and Signal Processing (2021).
6. Hyeong Hun Lee and Hyeonjin Kim. “Deep learning‐based target metabolite isolation and big data‐driven measurement uncertainty estimation in proton magnetic resonance spectroscopy of the brain.” Magnetic Resonance in Medicine 84 (2020): 1689 - 1706.
7. Zohaib Iqbal, Dan Nguyen, Michael Albert Thomas, and Steve B. Jiang. “Deep learning can accelerate and quantify simulated localized correlated spectroscopy.” Scientific Reports 11 (2021).
8. Saumya S. Gurbani, Sulaiman Sheriff, Andrew A. Maudsley, Hyunsuk Shim, and Lee A. D. Cooper. “Incorporation of a spectral model in a convolutional neural network for accelerated spectral fitting.” Magnetic Resonance in Medicine 81 (2019): 3346 - 3357.
9. Amirmohammad Shamaei, Jana Starčuková, and Zenon Starcuk. “Physics-informed Deep Learning Approach to Quantification of Human Brain Metabolites from Magnetic Resonance Spectroscopy Data.” Comput Biol Med.2023;158:106837.
10. Marjańska, Małgorzata, Dinesh K. Deelchand and Roland Kreis. “Results and interpretation of a fitting challenge for MR spectroscopy set up by the MRS study group of ISMRM.” Magnetic Resonance in Medicine 87 (2021): 11 - 32.
Figures
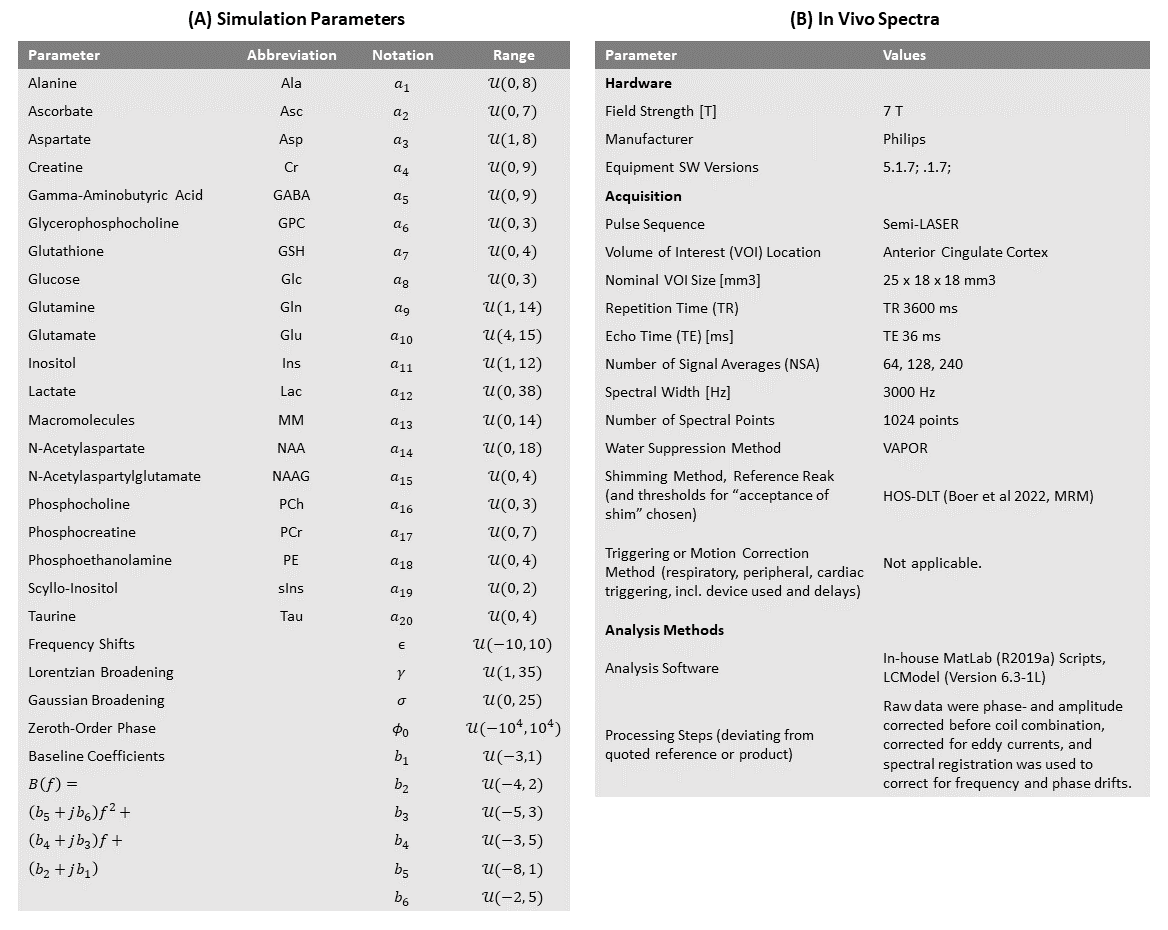
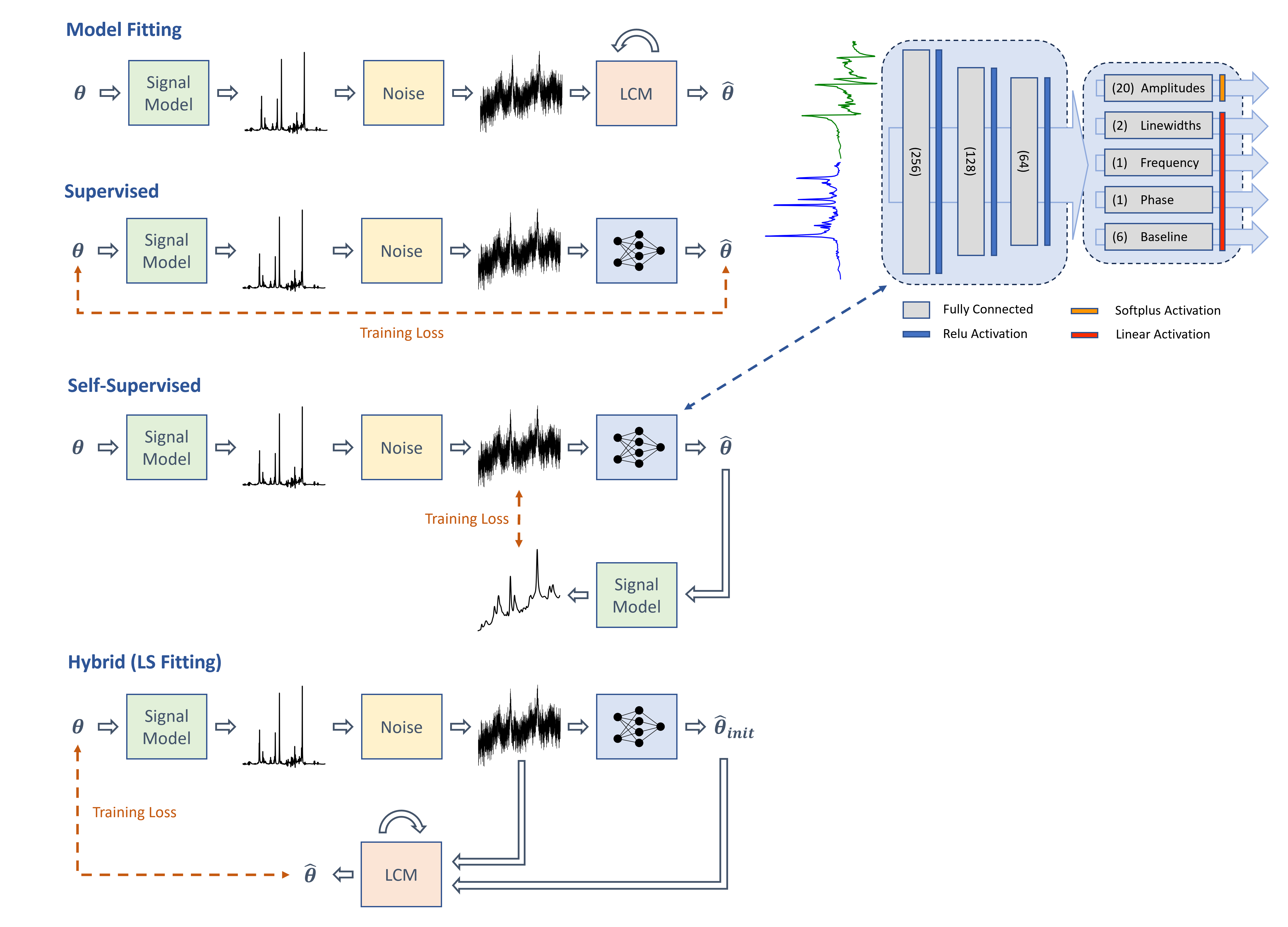
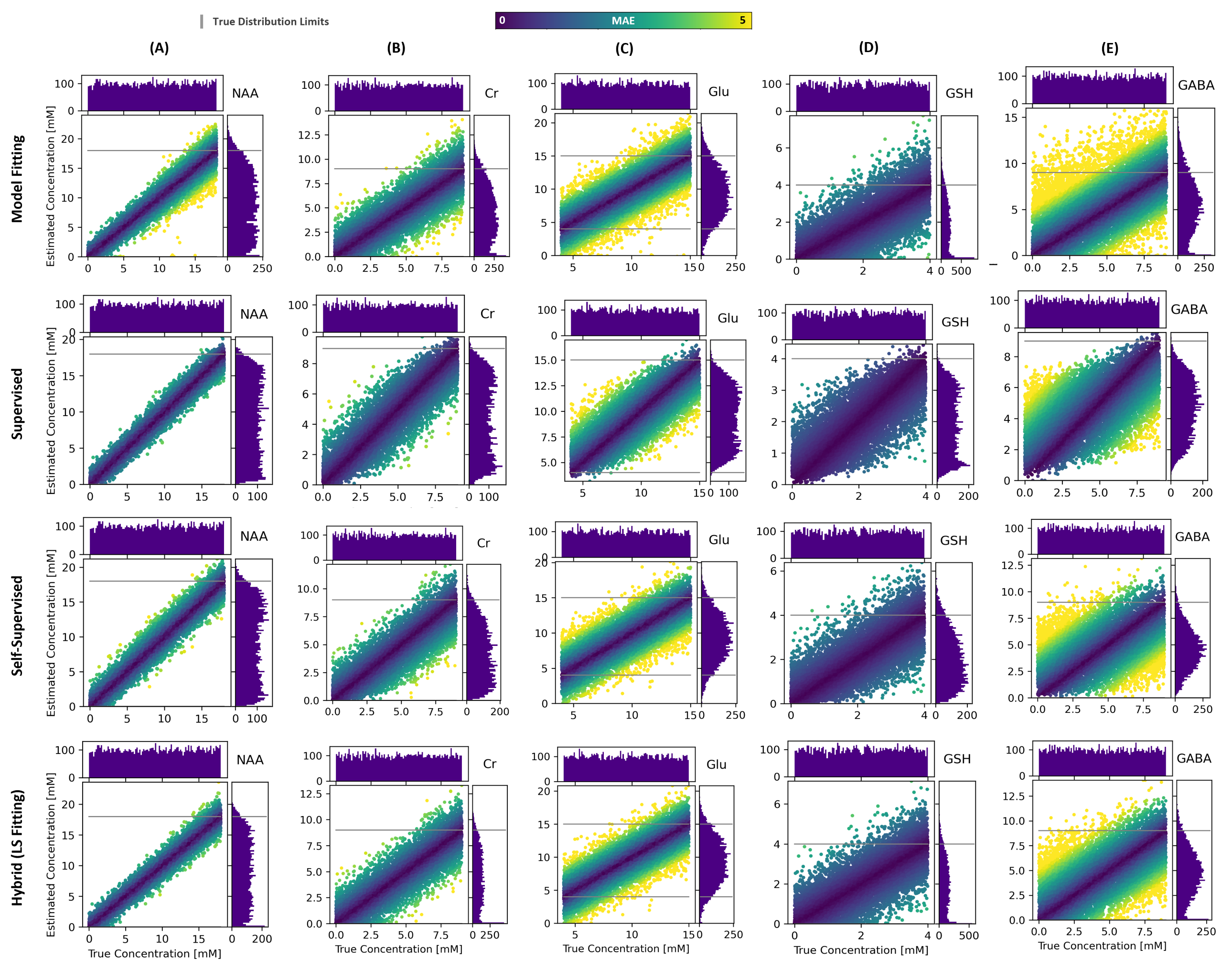
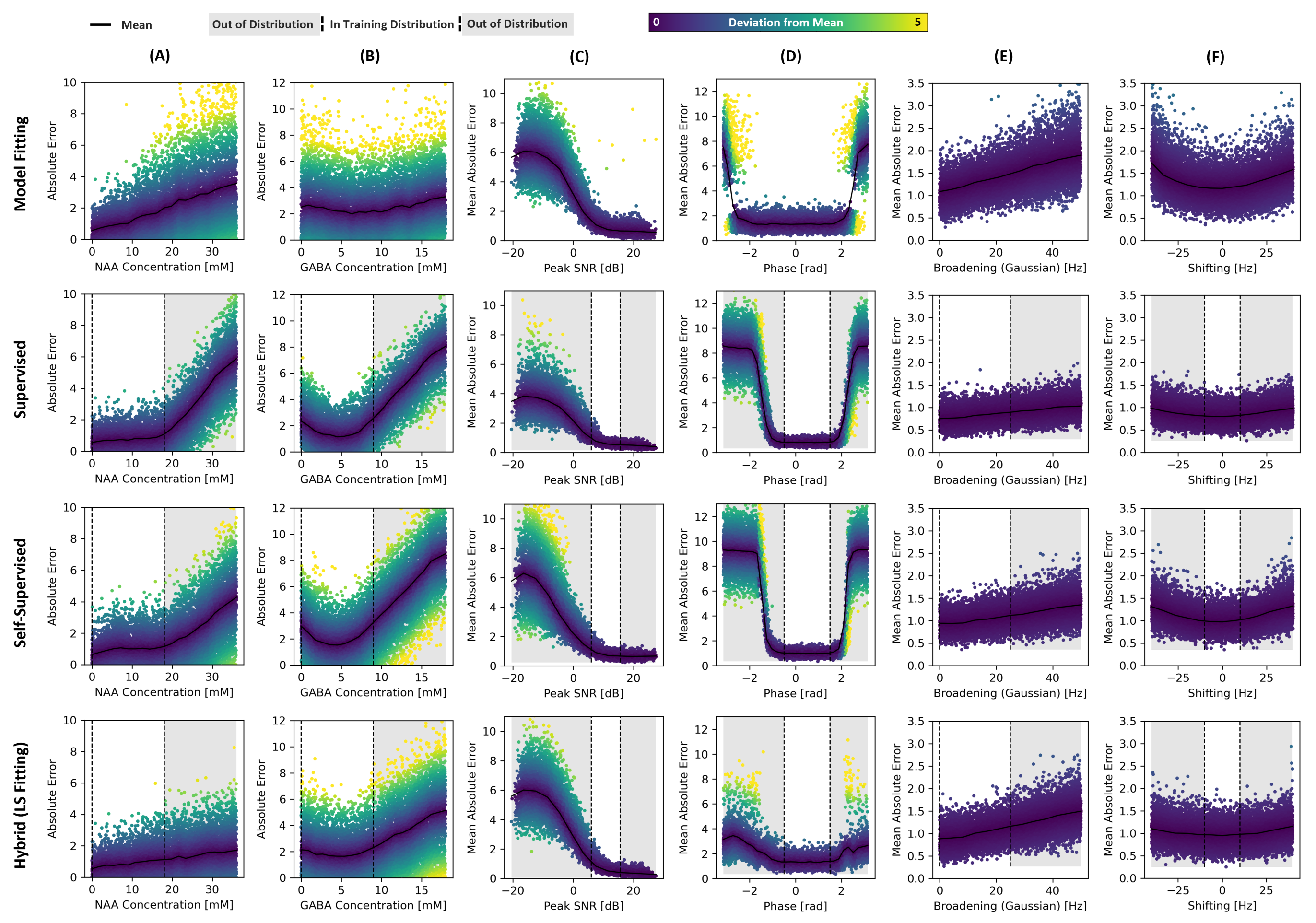
Figure 4. Showns the effects on the mean absolute error (MAE) for all evaluated methods when faced with out-of-distribution scenarios, using a dataset of 10,000 simulated samples. Parameters assessed include: (A) N-Acetylaspartate (NAA) amplitude, (B) Gamma-Aminobutyric Acid (GABA) amplitude, (C) signal-to-noise ratio (SNR), (D) zeroth-order phase, (E) Gaussian broadening, and (F) frequency shifting. The data within the dashed lines represent the training distribution, while the data beyond were not encountered by the networks during training.
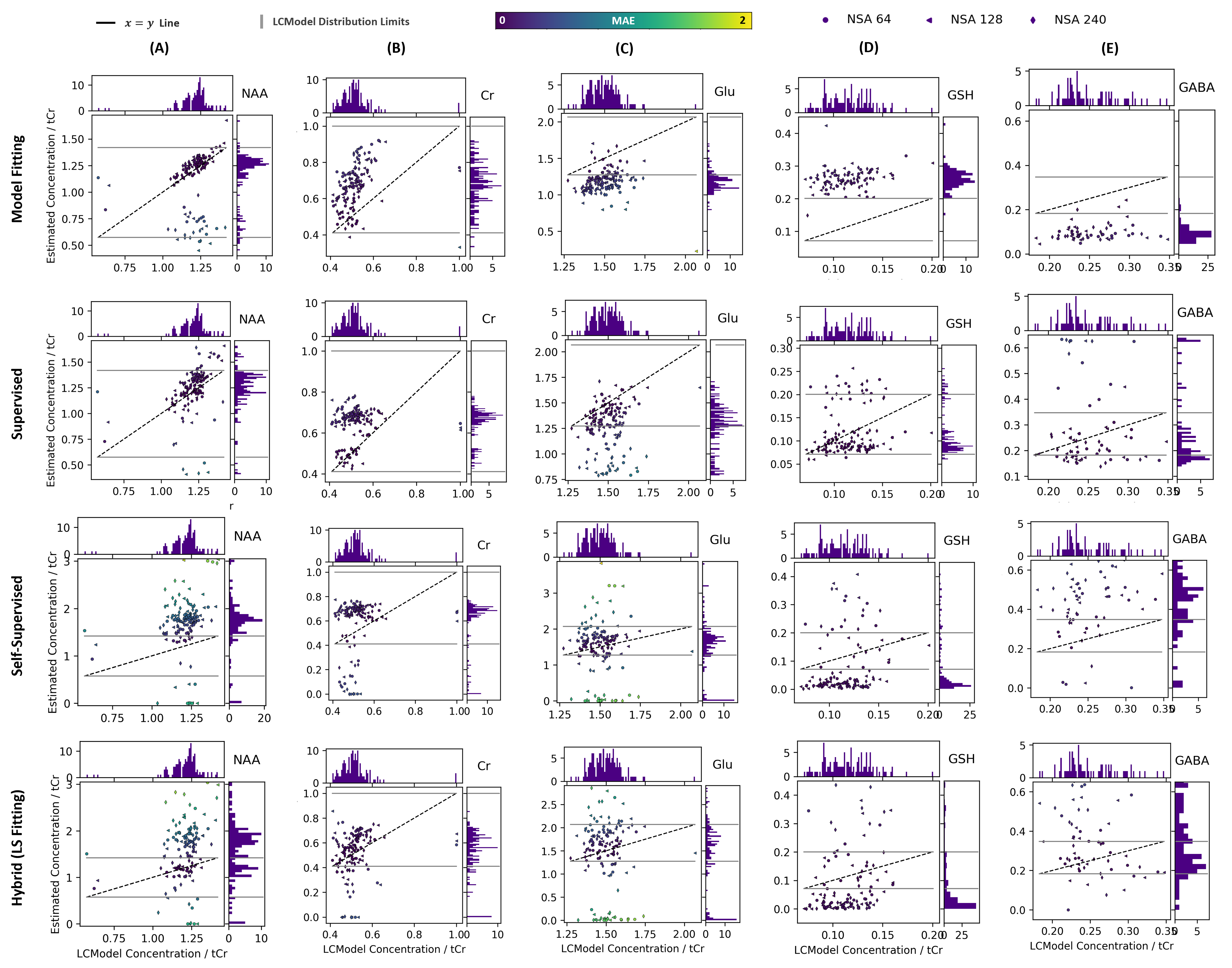
Figure 5. Depicts the correlation between the estimated concentrations of the evaluated methods and LCModel, along with the corresponding marginal distributions, for in-vivo data samples, focusing on selected metabolites: (A) N-Acetylaspartate (NAA), (B) Creatine (Cr), (C) Glutamine (Gln), (D) Glutathione (GSH), and (E) Gamma-Aminobutyric Acid (GABA). Only concentration estimates were considered that obtained a CRLB percentage value of below 20% for the LCModel estimation.