1199
Dynamic Contrast-Enhanced MRI Parameter Mapping for Cervical Cancer Using CycleGAN-like model with UNet-Vision Transformer1Lauterbur Research Center for Biomedical Imaging, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, Shenzhen, China, 2National Cancer Center/National Clinical Research Center for Cancer/Cancer Hospital & Shenzhen Hospital, Chinese Academy of Medical Sciences and Peking Union Medical College, Shenzhen, China, 3Key Laboratory of Biomedical Imaging Science and System, Chinese Academy of Sciences., Beijing, China
Synopsis
Keywords: Analysis/Processing, Cancer, Cervical Cancer,Dynamic Contrast-Enhanced MRI,UNet,Vision Transformer, CycleGAN, self-supervised pretraining
Motivation: DCE-MRI plays an important role in non-invasive detection and monitoring of cervical cancer, providing key information for improving diagnosis and treatment accuracy.
Goal(s): DCE-MRI faces complexities and noise issues in application and needs to be optimized and improved by deep learning techniques for parameter mapping. Existing deep learning based methods suffer from limited data and model efficiency.
Approach: We propose a CycleGAN-like model with UNet-Vision-Transformer generator, enhance the discriminator with gradient penalty, and pre-train the model via self-supervised image inpainting.
Results: The numerical experimental results demonstrate that the proposed model is quite efficient and robust compared with other deep learning-based methods.
Impact: This research offers fresh avenues for processing medical imaging data by proposing a novel and efficient deep learning model, significantly impacting the improvement of disease diagnosis. Furthermore, it provides researchers with new directions and insights, advancing scientific and technological progress.
Introduction
Dynamic Contrast-Enhanced MRI is an important tool for the non-invasive detection and treatment monitoring of cervical cancer. Traditional DCE-MRI parameter computation [1-4] is computationally intensive and sensitive to noise, often resulting in inaccurate estimates and limited applicability across different tissues and patients. Current deep learning models [5-10], while robust and capable of learning complex patterns, suffer from a dependency on large, labeled datasets, lack of interpretability, risk of overfitting, and significant computational demands during training. To overcome the shortcomings of existing deep learning approaches in generating DCE-MRI parameter maps, we propose a CycleGAN-like model that employs a UNet with a Vision Transformer at its bottleneck to enhance non-local pattern learning. Moreover, we refine the CycleGAN discriminator by incorporating gradient penalty into its loss function and pre-train the generator via self-supervised image inpainting to achieve a better initial state.Materials and methods
Patient studies:Data from 121 female patients (range of 30-81 years old) were acquired to train and validate the performance of the proposed method, among which 20 patients were labeled with mask on Cervix. For each participant, DCE-MRI scans were acquired using a 3T MR scanner (Discovery MR750w, General Electric Healthcare) employing a 3D saturation recovery spoiled gradient echo technique. The parameters were set to 32 slices with a 3.0 mm slice thickness, a repetition time (TR) of 4.3 ms, an echo time (TE) of 2.2 ms, and a flip angle (FA) of 12°. The frequency field of view (FOV) was 32, with a phase FOV of 0.9 and a bandwidth of 142.86 Hz/pixel. The number of excitations (NEX) was fixed at 1.0. For contrast, 0.1 mmol/kg of Dotarem was administered at a rate of 2 ml/s, followed by a 20 ml saline flush. The protocol captured a total of 40 dynamic sequences.
Method Implements:
We propose a CycleGAN-like model that achieves mutual conversion from DCE-MRI sequences to parametric images through two pairs of generator-discriminator. Figure 1 shows the structure of the proposed model. The generator is A UNet [11] with a pixel-wise Vision Transformer [12] at the bottleneck, where the Vision Transformer is utilized to learn the pairwise relationships of low-frequency features. We use the least squares GAN (LSGAN) loss function [13] in the original Cycle-Gan net loss functions. The discriminator loss is supplemented with a GP term, which is formulated as following:
$$L^{GP}_{{disc}, A} = L_{{disc}, A} + \lambda_{GP} \mathbb{E} \left[ \frac{\left( \left\| \nabla_{x}D_A(x) \right\|_2 - \gamma \right)^2}{\gamma^2} \right]$$
And $$$L_{{disc}, A} $$$ is defined as
$$L_{{disc}, A} = \mathbb{E}_{x \sim B}\ell_{GAN}(D_A(G_{B \to A}(x),0) + \mathbb{E}_{x \sim A}\ell_{GAN}(D_A(x),1)$$
$$$\ell_{GAN}$$$ is the LSGAN loss function. $$$L^{GP}_{{disc}, B}$$$ follows the same form. The $$$\gamma$$$ -centered GP regularization provides more stable training and is less sensitive to the hyperparameter choices. Instead of starting with randomly initialized network weights, we pre-train our generator through self-supervised image inpainting tasks to achieve a better initial state for training.
Data analysis:
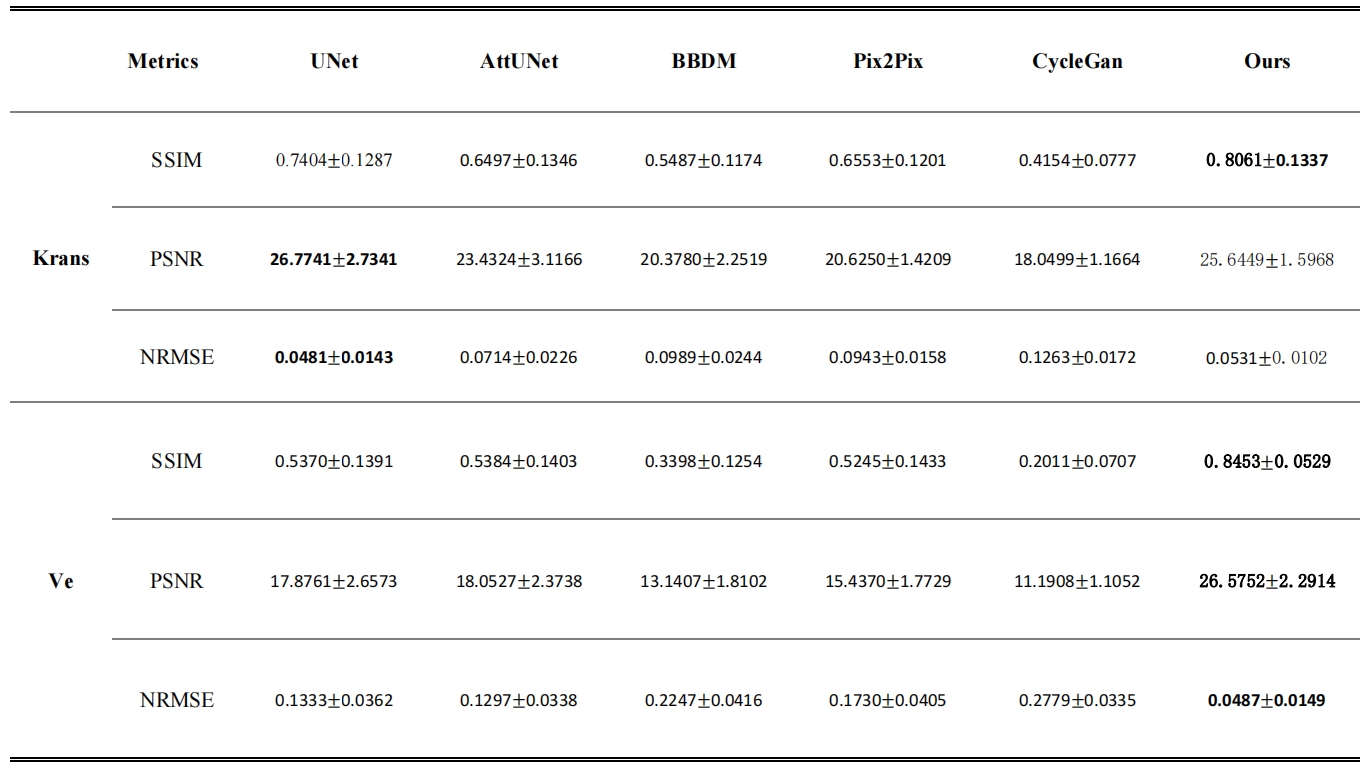
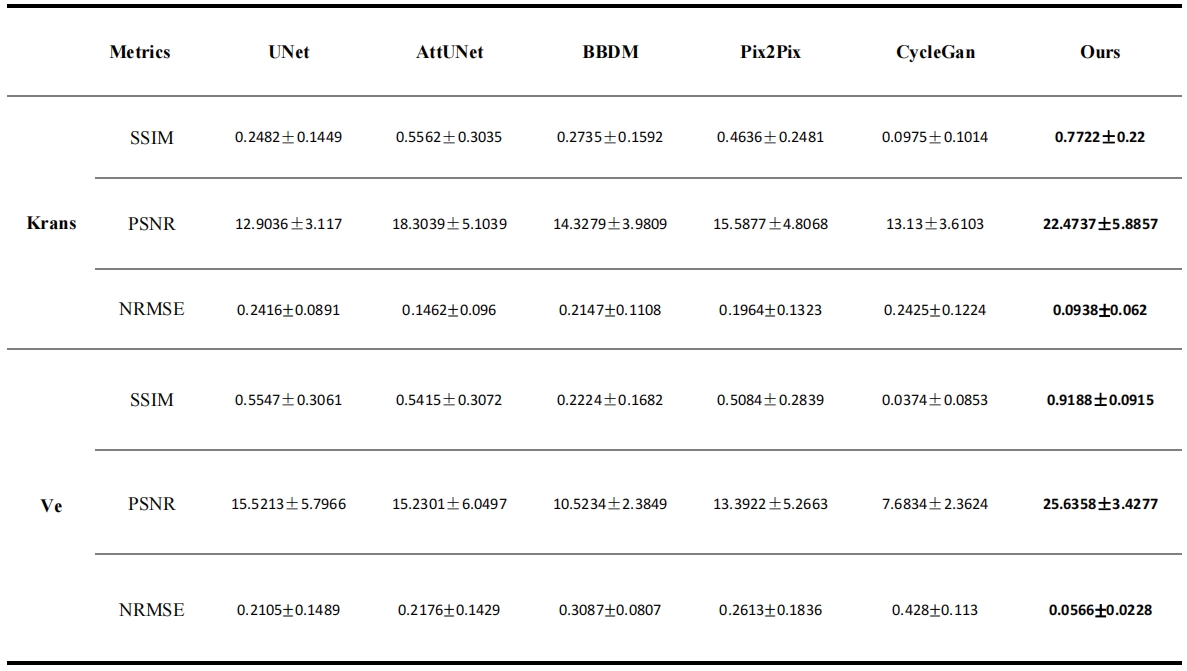
Our dataset includes 101 subjects without masks and an additional 20 subjects with cervical masks for validation. We distributed the 101 subjects into training, validation, and test groups with a split ratio of 8:1:1. To assess the quality of the generated parametric maps, we utilized metrics like SSIM, PSNR, and NRMSE for image quality comparison against the ground truth. We evaluated whole image metrics on the test set and ROI metrics on the additional validation set. Profile analysis was also conducted to measure the accuracy of model generation and ensure structural integrity. Furthermore, we benchmarked our method against leading model-based approaches, including UNet[11], AttUnet[14], BBDM[15], pix2pix[16], and cyclegan[17], to establish comparative performance.
Results
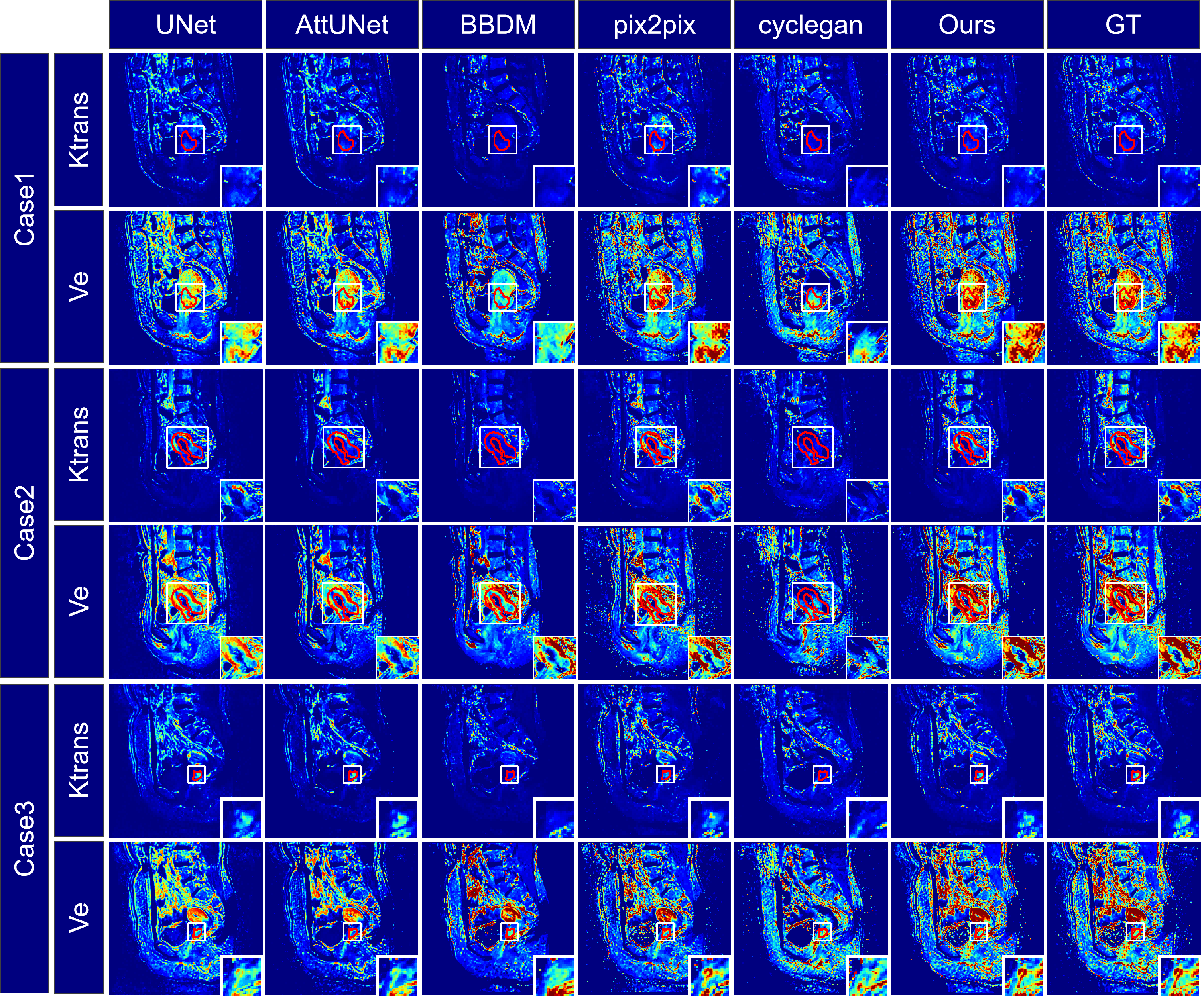
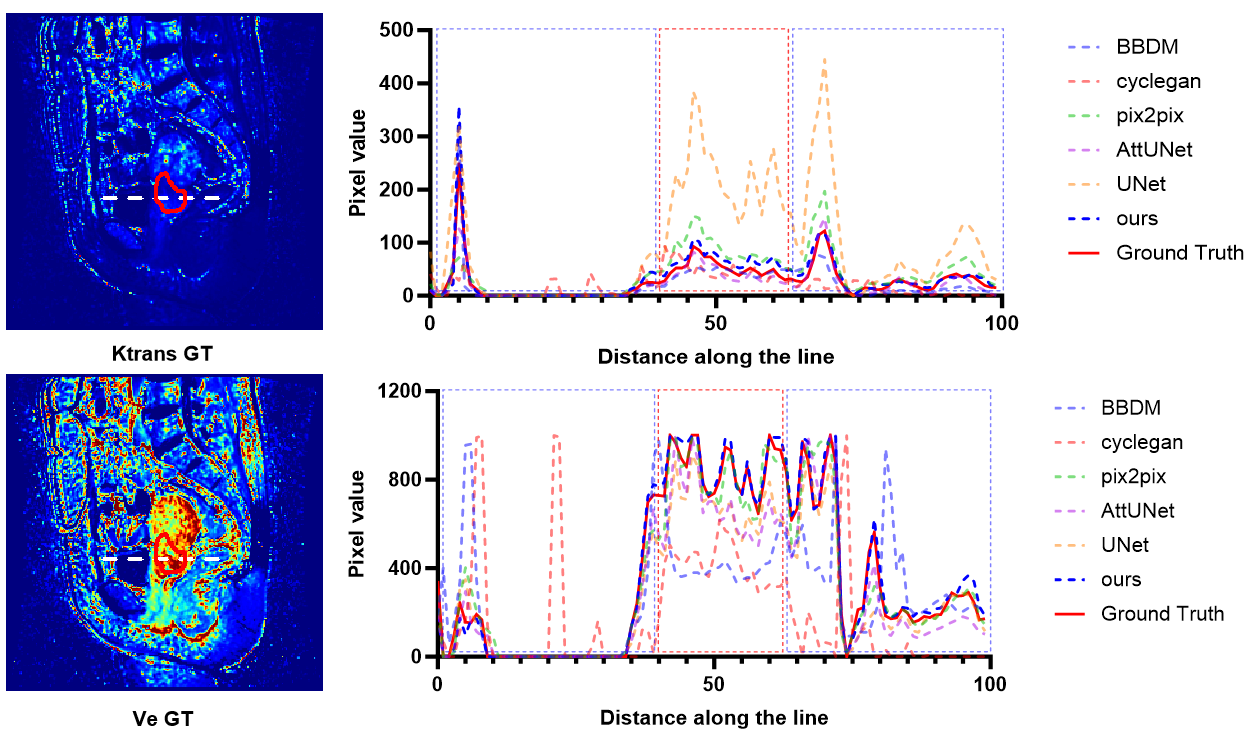
Figure 2 provides a visual comparison of Ktrans and Ve parameter maps for three subjects. Our model demonstrates high congruence with the actual data, especially in capturing cervical area details. The profile analysis in Figure 3 confirms that our method generates more accurate parameter mappings along a specific line within the images compared to other methods. We also computed performance metrics, including SSIM, PSNR, and NRMSE, for overall images on the test dataset and the cervical ROI on the external validation dataset, as detailed in Tables 1 and 2. Our method outshines the alternatives in performance.Discussion and conclusion
We propose a CycleGAN-like model for transforming DCE-MRI sequences into Ktrans and Ve images, utilizing a UNet generator with Vision Transformer for intricate feature extraction and improved by LSGAN loss and gradient penalty. Self-supervised pretraining further refines the generator's initial training state. Our method outperforms others in robustness, as shown in comparative tests, and future work will focus on detailed clinical quantitative analysis based on DCE-MRI standards.Acknowledgements
This work was supported by the National Natural Science Foundation of China (12305409, 82372038 and 62101540), the Shenzhen Excellent Technological Innovation Talent Training Project of China (RCJC20200714114436080), the Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2023B1212060052), the Shenzhen Science and Technology Program (JCYJ20220818101804009 and RCBS20210706092218043), and the Guangdong Basic and Applied Basic Research Foundation (2022A1515110696).References
[1] Gaddikeri S, Gaddikeri RS, Tailor T, Anzai Y. Dynamic Contrast-Enhanced MR Imaging in Head and Neck Cancer: Techniques and Clinical Applications. AJNR Am J Neuroradiol 2016;37(4):588-595.
[2] Khalifa F, Soliman A, El-Baz A, et al. Models and methods for analyzing DCE-MRI: a review. Med Phys 2014;41(12):124301.
[3] Murase K. Efficient method for calculating kinetic parameters using T1-weighted dynamic contrast-enhanced magnetic resonance imaging. Magn Reson Med 2004;51(4):858-862.
[4] Wang C, Yin FF, Chang Z. An efficient calculation method for pharmacokinetic parameters in brain permeability study using dynamic contrast-enhanced MRI. Magn Reson Med 2016;75(2):739-749.
[5] Ulas C, Tetteh G, Thrippleton MJ, et al. Direct estimation of pharmacokinetic parameters from DCE-MRI using deep CNN with forward physical model loss. Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, September 16-20, 2018, Proceedings, Part I: Springer; 2018. p. 39-47.
[6] Ulas C, Das D, Thrippleton MJ, et al. Convolutional Neural Networks for Direct Inference of Pharmacokinetic Parameters: Application to Stroke Dynamic Contrast-Enhanced MRI. Front Neurol 2018;9:1147.
[7] Zou J, Balter JM, Cao Y. Estimation of pharmacokinetic parameters from DCE-MRI by extracting long and short time-dependent features using an LSTM network. Med Phys 2020;47(8):3447-3457.
[8] Julie L, Ikram D, Mailyn PL, et al. A free time point model for dynamic contrast enhanced exploration. Magn Reson Imaging 2021;80:39-49.
[9] Bliesener Y, Acharya J, Nayak KS. Efficient DCE-MRI Parameter and Uncertainty Estimation Using a Neural Network. IEEE Trans Med Imaging 2020;39(5):1712-1723.
[10] Rastogi A, Dutta A, Yalavarthy PK. VTDCE-Net: A time invariant deep neural network for direct estimation of pharmacokinetic parameters from undersampled DCE MRI data. Med Phys 2023;50(3):1560-1572.
[11] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 2015 (pp. 234-241).
[12] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. 2020.
[13] Mao X, Li Q, Xie H, Lau RY, Wang Z, Paul Smolley S. Least squares generative adversarial networks. InProceedings of the IEEE international conference on computer vision 2017 (pp. 2794-2802).
[14] Oktay O, Schlemper J, Folgoc LL, Lee M, Heinrich M, Misawa K, Mori K, McDonagh S, Hammerla NY, Kainz B, Glocker B. Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999. 2018.
[15] Li B, Xue K, Liu B, Lai YK. BBDM: Image-to-image translation with Brownian bridge diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 (pp. 1952-1961).
[16] Isola P, Zhu JY, Zhou T, Efros AA. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition 2017 (pp. 1125-1134).
[17] Zhu JY, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision 2017 (pp. 2223-2232).
Figures
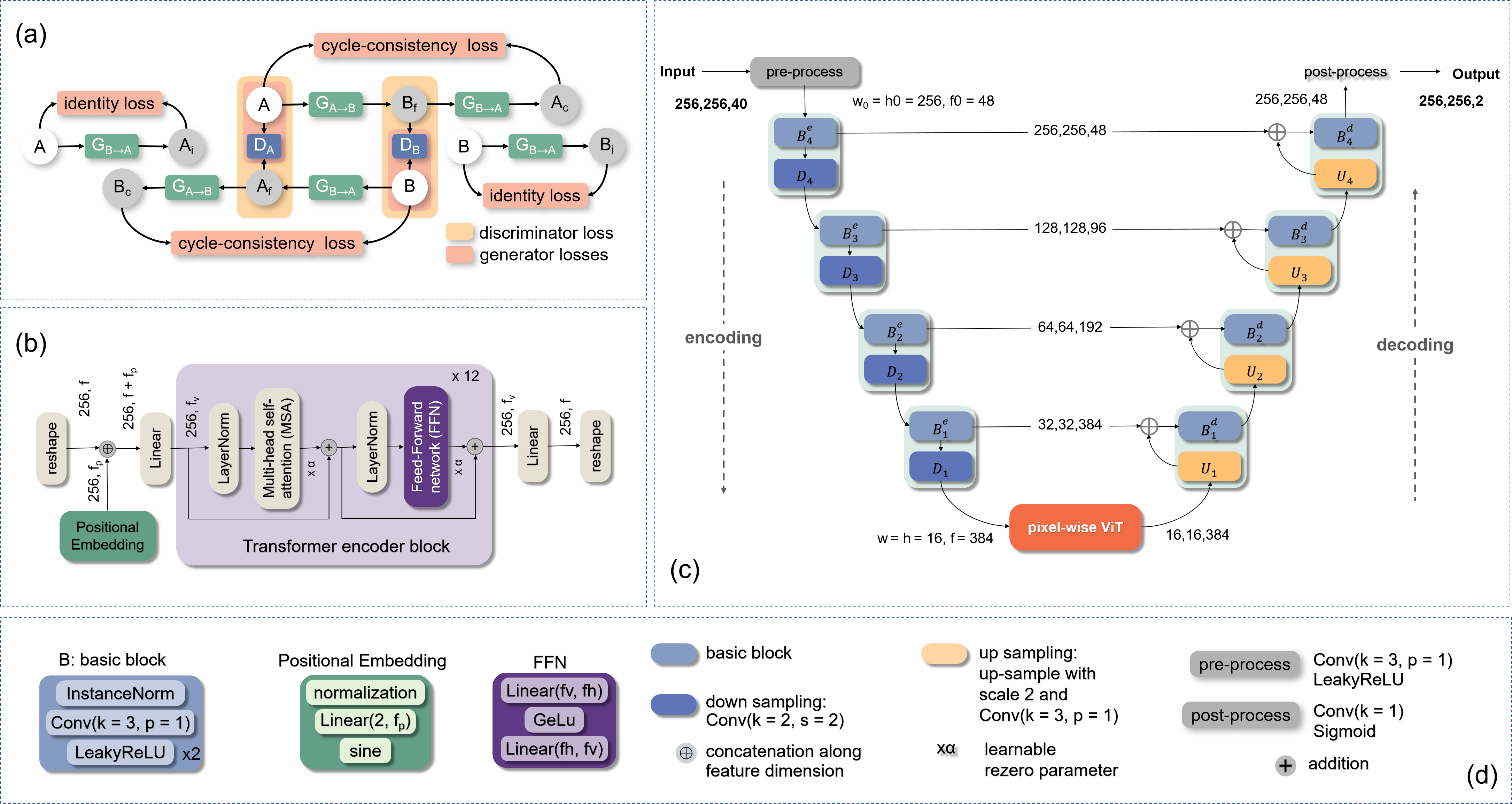
The proposed model's structure. (a) the CycleGAN framework, (b) a Vision Transformer integrated at the UNet's bottleneck, (c) the UNet architecture, and (d) additional diagrams explaining components (a), (b), and (c).