1195
Synthetic CT generation using focal frequency loss improves image sharpness1Advanced Clinical Imaging Technology, Siemens Healthineers International AG, Lausanne, Geneva and Zurich, Switzerland, 2Department of Radiology, Lausanne University Hospital and University of Lausanne, Lausanne, Switzerland, 3LTS5, Ecole Polytechnique Fédérale de Lausanne, Lausanne, Switzerland, 4Swiss Biomotion Lab, Lausanne University Hospital and University of Lausanne, Lausanne, Switzerland, 5Swiss Centre for Musculoskeletal Imaging (SCMI), Balgrist Campus, Zurich, Switzerland
Synopsis
Keywords: Analysis/Processing, Data Processing, synthetic CT
Motivation: Standard intensity-based voxel-wise losses, generally used in image-to-image translation techniques, are typically biased towards the estimation of the low frequency content in image spectra. For the generation of synthetic CT (sCT) contrast, this results in limited image sharpness, and consequently a limited clinical utility.
Goal(s): To improve sharpness in synthetic contrasts.
Approach: We trained a model using a combination of intensity- and frequency-based losses for the generation of sCT images from MRI.
Results: Compared to a baseline model, sCT images generated using the focal-frequency loss resulted in an enhanced level of details in knee images.
Impact: Our results suggest that the use of frequency-based losses, in conjunction with an intensity-based L1 loss, improves image sharpness in synthetic contrasts, and thereby shows the potential to increase their clinical usefulness.
Introduction
Recent developments in bone MR imaging techniques include the generation of synthetic CT (sCT) contrast using deep learning models1,2. However, generative models typically suffer from limited image sharpness, hindering the clinical applicability of sCT for diagnostic purposes. The blurriness of synthetic contrasts can be partly explained by the high energy contained in the low frequencies of the Fourier spectrum of images. This biases the standard intensity-based losses (e.g., L1, L2) and results in a poor estimation of higher frequencies. To overcome this limitation, the use of a focal frequency loss (FFL) has been recently proposed for computer vision applications by Jiang et al.3, and resulted in a more accurate depiction of high frequency details.In this work, we investigate the use of FFL for the generation of sCT images from T1-weighted MRI and compare the results with a baseline model using L1 loss only.
Methods
Demographics, imaging protocols and pre-processingA cohort of 418 subjects (from the Lausanne Knee Study, 47.2±16.2 years old, 231 females) was recruited and underwent both a 3T MRI (MAGNETOM Prismafit, Siemens Healthineers AG, Erlangen, Germany) including a T1-weighted 3D gradient-echo sequence (0.5mm isotropic, TR=700ms, TE=11ms), and a CT scan (0.3mm isotropic, Revolution, GE Healthcare).
The training of supervised generative models required an accurate correspondence between T1-weighted MRI and CT image pairs for each subject. To this end, the T1-weighted MRI images were spatially registered to down-sampled CT volumes applying a combination of rigid, affine and non-linear transformations with elastix4. Two independent readers evaluated the registration quality and only image pairs with the highest score were retained.
Synthetic CT generation
Training and test sets were obtained from the dataset, by selecting 90% and 10% of all image pairs, respectively.
As proposed by Jiang et al.3, the computation of the FFL relies on the L2 difference between Fourier spectra obtained from the sCT and the ground truth (noted $$$FT_{sCT}$$$ and $$$FT_{CT}$$$ hereafter). Additionally, a dynamic weighting scheme is applied to the voxel-wise differences in frequency domain, to assign higher weights to the regions in the Fourier spectra that display the greatest deviations from the ground truth. Therefore, the focal frequency loss can be expressed as:
$$
FFL = \sum_{\forall k}w[k] * ||FT_{sCT}[k] - FT_{CT}[k]||_2 ,
$$
with
$$
w[k] = |FT_{sCT}[k] - FT_{CT}[k] |
$$
denoting the weight associated with frequency $$$k$$$. The total loss of the proposed model can be summarized as:
$$
L=L1 + λ_{FFL}*FFL,
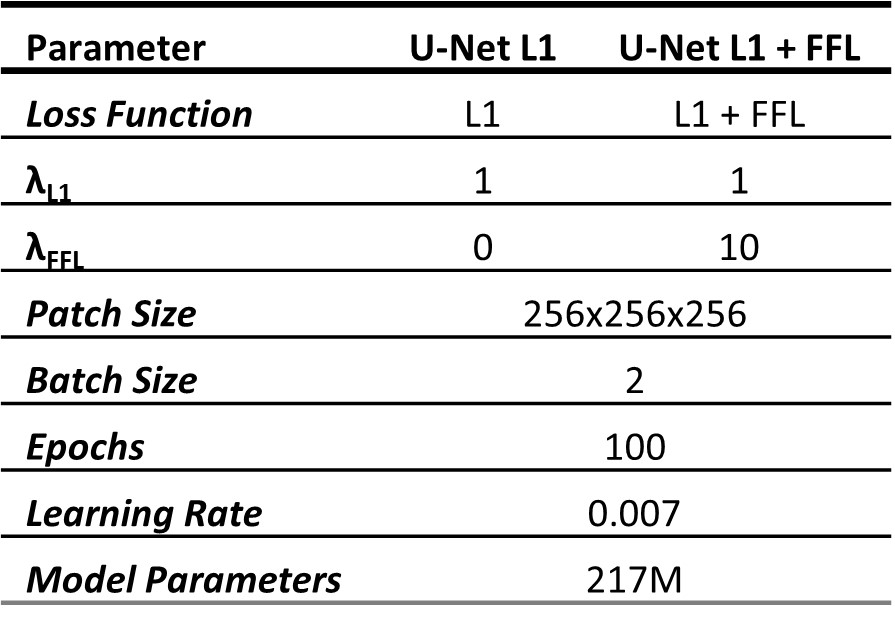
$$ with $$$L1(sCT, CT)=\sum_{\forall r}|sCT[r] - CT[r]|$$$, where $$$X[r]$$$ is the image intensity of image $$$X$$$ in voxel $$$r$$$. The results were compared with a baseline model trained to solely minimize the L1 loss. Table 1 reports the detailed training parameters.
Evaluation
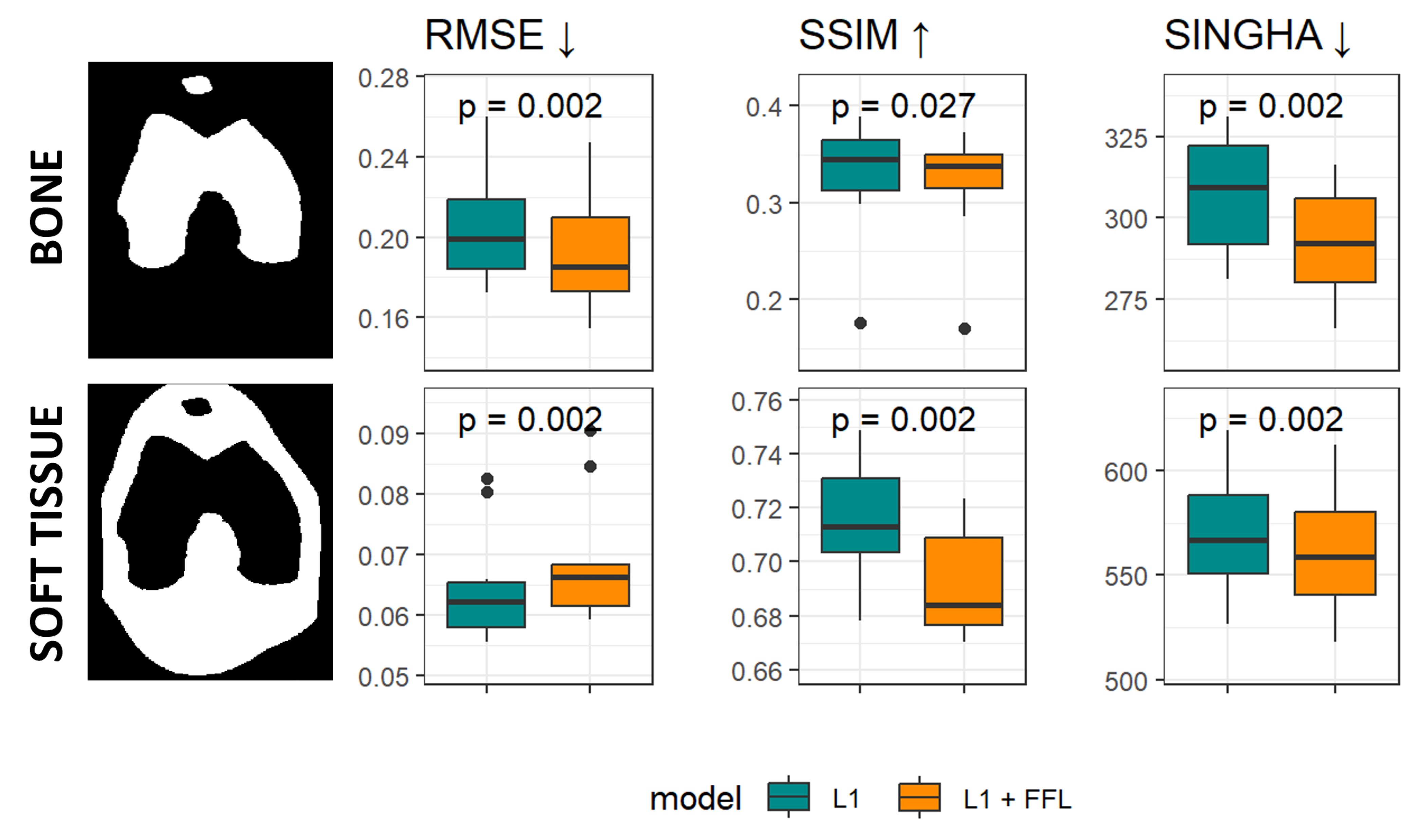
The accuracy of the sCT images was estimated on the test set inside the bone and in soft tissue. For a quantitative evaluation, standard intensity-based distortion metrics were assessed (i.e., structural similarity, SSIM and root mean squared error, RMSE), as well as a novel frequency-based metric dubbed SINGHA (Spectrally-INformed Grading of High-frequency Attributes)5. The latter was used to compare the high spatial frequency contributions between images, and was computed as a weighted sum over the magnitude spectrum that was averaged across frequencies at a common distance to the k-space centre, with higher weight for higher frequencies.
Accuracy metrics computed for both models were compared statistically using the Wilcoxon test for paired samples.
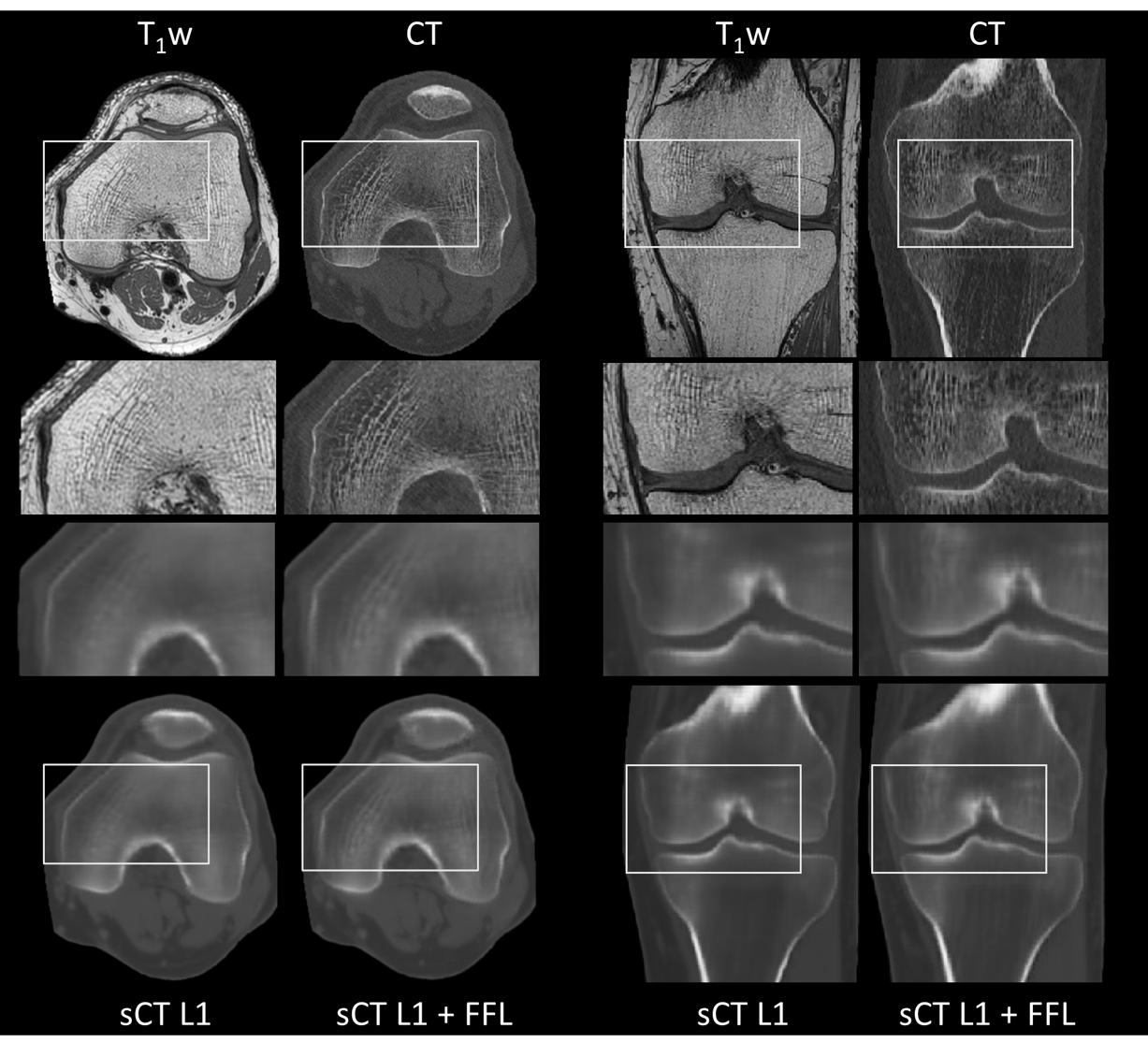
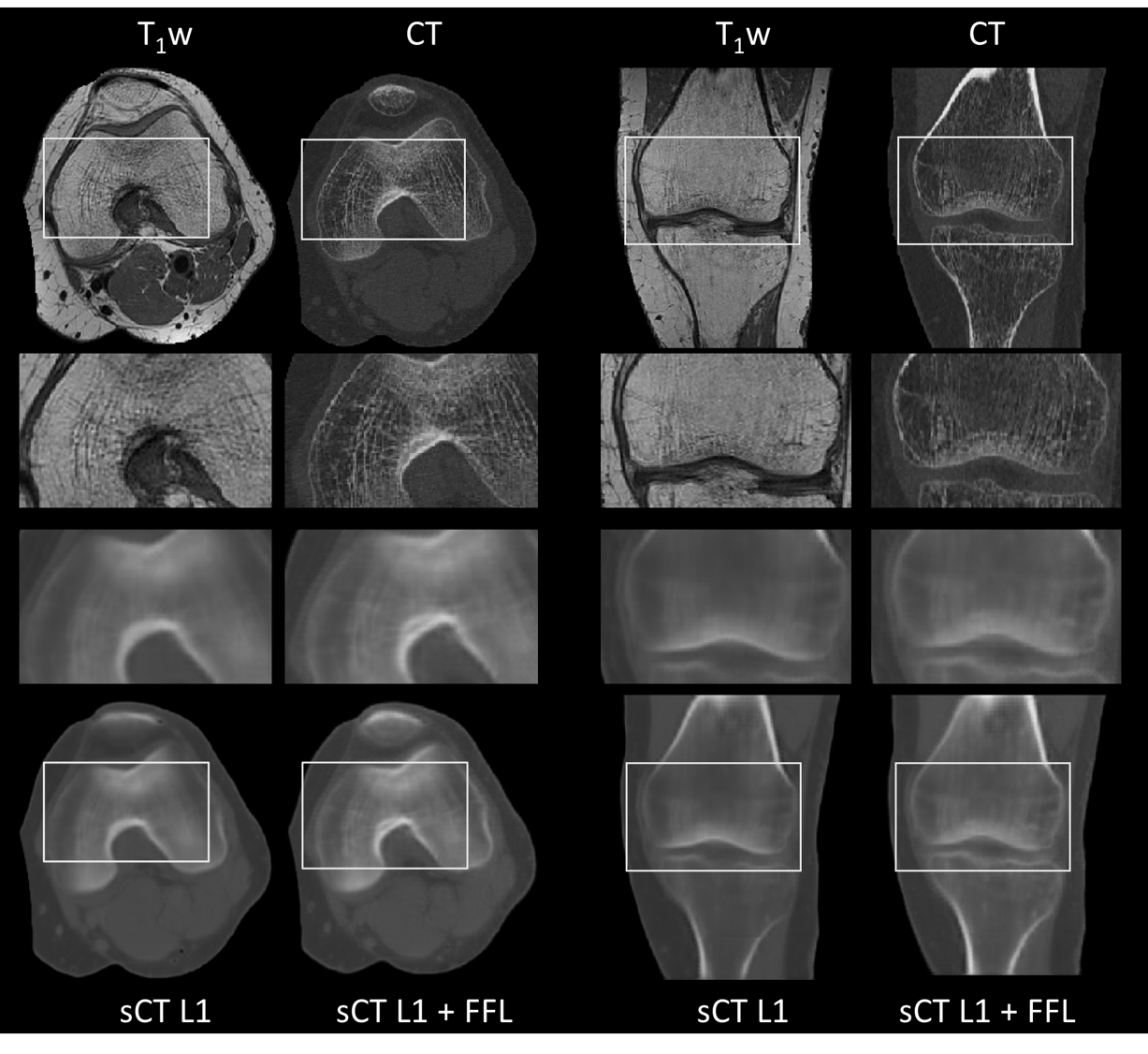
Results
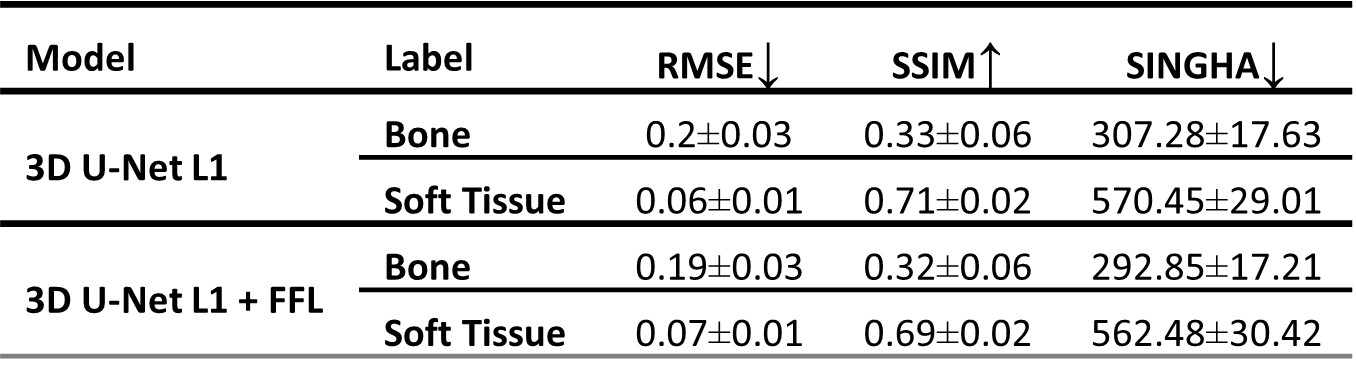
After visual inspection of the registration quality, 101 paired datasets were selected for training and test datasets. Figure 1 and Figure 2 show the sCT images obtained using both models in two example subjects. Qualitatively, the model using the FFL resulted in a higher level of details with increased image sharpness compared to the baseline model. Particularly, trabecular bone structures became more apparent, and the bone fascia was better delineated.Figure 3 and Table 2 show the distribution of accuracy metrics for the two models across the test set. The use of the FFL led to very minor but statistically significant differences in RMSE compared to the baseline model and performed worse in terms of SSIM. However, lower SINGHA values were observed inside the bone for the FFL model, consistent with the visually perceived improvement in image sharpness.
Discussion and Conclusion
Our results suggest that using a frequency-based optimization function, such as a focal frequency loss, contributes to the improvement of image sharpness in image-to-image translation techniques. Therefore, a combination of intensity- and frequency- based loss functions could benefit the accuracy of synthetic contrast generation. Future work will investigate these findings in terms of clinical relevance of sCT for the characterization of bone pathology.Acknowledgements
Lausanne Knee Study: Ethics approved and subjects gave their consent. This work was performed with the support of the Swiss National Science Foundation, Switzerland (Sinergia grant CRSII5_177155)References
1. Hsu SH, Han Z, Leeman JE, Hu YH, Mak RH, Sudhyadhom A. Synthetic CT generation for MRI-guided adaptive radiotherapy in prostate cancer. Front Oncol. 2022;12. doi:10.3389/fonc.2022.969463
2. Palmér E, Karlsson A, Nordström F, et al. Synthetic computed tomography data allows for accurate absorbed dose calculations in a magnetic resonance imaging only workflow for head and neck radiotherapy. Phys Imaging Radiat Oncol. 2021;17:36-42. doi:10.1016/j.phro.2020.12.007
3. Jiang L, Dai B, Wu W, Loy CC. Focal Frequency Loss for Image Reconstruction and Synthesis.; 2021. doi:10.1109/ICCV48922.2021.01366
4. Klein S, Staring M, Murphy K, Viergever MA, Pluim JPW. elastix: a toolbox for intensity-based medical image registration. IEEE Trans Med Imaging. 2010;29(1):196-205. doi:10.1109/TMI.2009.2035616
5. Ravano V, Elwakil A, Yu T, Hilbert T, Maréchal B, Richiardi J, Thiran J-P, Mourad C, Margain P, Favre J, Kober T, Omoumi P, Sommer S. Evaluation of generative models for synthetic CT images using a new spectrally informed metric. Submitted in parallel to ISMRM 2024
Figures