1191
Enhancing MRI Resolution with a Lightweight Network and Reverse Residual Attention Fusion1China Jiliang University, Hangzhou, China, 2Karolinska Institute, Stockholm, Sweden, 3Karolinska University Hospital, Stockholm, Sweden
Synopsis
Keywords: AI/ML Image Reconstruction, Brain
Motivation: In MRI reconstruction, deep-learning methods often increase network complexity for improved super-resolution, leading to longer reconstruction times and training difficulties.
Goal(s): Our solution introduces an enhanced lightweight network that maintains high-quality performance.
Approach: We accomplish this by stacking Reverse Residual Attention Fusion (RRAF) with PCA and Enhanced Spatial Attention (ESA) for precise feature extraction, utilizing Transformers with depth-wise dilated convolution for better context information, and employing High-Frequency Image Refinement (HFIR) for detailed information recovery.
Results: Our experiments confirm the effectiveness of our approach.
Impact: Introducing the lightweight network represents an important improvement in MRI SR reconstruction. By integrating Reverse Residual Attention Fusion, it upholds exceptional image quality, streamlines network complexity, reduces reconstruction time, and simplifies training for SR MRI image reconstruction.
INTRODUCTION
Image super-resolution (SR) is a promising technique that refines high-resolution (HR) images from their low-resolution (LR) counterparts, enhancing visual quality and detail1. In the context of MRI, SR techniques have become increasingly important for improving time efficiency. Deep learning and lightweight networks have emerged as leading approaches for fast MRI SR reconstruction2-4. They offer significant advantages over conventional reconstruction methods, enhancing both reconstruction speed and imaging quality5-6. However, most deep learning models achieve these improvements by increasing network depth and width, which can lead to longer reconstruction times and convergence challenges. In this study, we present an improved lightweight model that achieves high-quality performance without introducing unnecessary complexity.METHODS
The network in Fig. 1 comprises three components: deep feature extraction, upsampling reconstruction, and SR correction. Multiple Reverse Residual Attention Fusion (RRAF) modules progressively refine features from a LR image. These modules incorporate various techniques, such as PCA, ESA, and channel shuffle, to enhance feature extraction, with the deep feature extraction section culminating in a Transformer module for context enrichment.We evaluated the proposed network using publicly available MRI brain datasets: IXI and MICCAI datasets. From the IXI dataset, we randomly selected 80 T1-weighted volumes and 80 T2-weighted volumes, and from the MICCAI dataset, 80 T1-weighted volumes. To further validation, we obtained matched whole-brain 3D T1w and T2w datasets with resolutions of 0.8 mm and 0.6 mm from 12 healthy adult subjects using a Siemens Magnetom Prisma and Terra-X scanners, respectively. Each dataset was split into a 7:2:1 ratio for training, validation, and testing, respectively. We resized each 3D MRI volume to 100 slices of 256×256 images. These original images served as ground-truth HR images and were down-sampled to LR images with scaling factors of 2× and 4× using bicubic interpolation. For the matched 3T and 7T datasets, the 7T HR images served as ground truth to reconstruct the LR 3T images.
The model was implemented in the PyTorch framework using an NVIDIA GeForce 3060 GPU. In the training phase, we used the L1 loss function and the AdamW optimizer7 with parameters 𝛽1=0.9, 𝛽2=0.999, and 𝜖=10-8. The batch size was set to 16, and the initial learning rate was 0.0001 for 200 epochs. For comparison, we also implemented 7 reference methods, including bicubic, SRCNN2, VDSR3, EDSR4, PAN5, W2AMSN-S8, and FMEN6. Image quality metrics including PSNR, SSIM and Blur were assessed.
RESULTS
Fig. 2 illustrates a representative slice displaying the outcomes of the reconstruction process, with a 4× downsampling of a volume IXI (T1w), IXI (T2w) and MICC (T1w), utilizing various SR models. Quantitative assessments of image quality are detailed in Table 1 and Fig. 3. These evaluations collectively demonstrate strong performance across the models. Notably, our proposed approach excels in all aspects of image quality, delivering remarkable results while maintaining a streamlined parameter count. Further insights into model performance were gained through ablation tests. Table 2 presents quantitative data from these experiments, focusing on evaluation metrics such as PSNR and SSIM. The results underscore the robustness of the baseline architecture and the outstanding performance of the full model, consistently outperforming various sub-model variations. Particularly, the inclusion of the channel shuffle module consistently contributes to approximately 1dB improvement in PSNR and a 1% enhancement in SSIM, highlighting its effectiveness in our proposed network. Fig. 4 showcases representative reconstruction results, demonstrating the application of our proposed method for super-resolution reconstruction on low-resolution (LR) 3T data using a paired high-resolution (HR) 7T dataset. This demonstrates the feasibility of obtaining T1w and T2w images that rival 7T quality through an LR 3T scan, presenting a valuable prospect in clinical practice.DISCUSSION
In our study, we pragmatically selected a 256×256 HR patch size for the IXI and MICC datasets due to GPU RAM constraints. Nonetheless, we considered the option of SR reconstruction at larger sizes like 512×512 or 1024×1024, offering scalability for diverse applications. Our model incorporates four RRAF blocks for deep feature extraction and embraces a dual-path reconstruction approach, focusing on both low and high-frequency information. The HFIR module plays a pivotal role in refining MR images, enhancing precision and detail recovery.CONCLUSION
Our study tackled the MRI super-resolution reconstruction challenge with a lightweight network featuring reverse residual attention fusion. This approach effectively elevates image quality without introducing unnecessary complexity. Ablation tests underscored the efficacy of our network enhancements. The matched 3T and 7T datasets indicate promising clinical applications, making our model a valuable addition to medical imaging practices.Acknowledgements
This research was supported by a grant from the Zhejiang Natural Science Foundation of China (No. LY23F010005), the ALF foundation in the Stockholm Region, and the Joint China–Sweden Mobility program from STINT (Dnr: CH2019-8397).
References
1. Eyal C, Siuyan L, Noga A, et al. Resolution enhancement in MRI. Magnetic Resonance Imaging. 2006; 24: 133–154. 2. Chao D, Chen Change L, Kaiming H, et al. Learning a deep convolutional network for image super-resolution. ECCV. 2014; Part IV, LNCS 8692: 184–199. 3. Jiwon K, Jung Kwon L, Kyoung Mu L. Accurate image super-resolution using very deep convolutional networks. CVPR. 2015; 1646-1654. 4. Bee L, Sanghyun S, Heewon K, et al. Enhanced deep residual networks for single image super-resolution. CVPR. 2017; 1132-1140. 5. Hengyuan Z, Xiangtao K, Jingwen H, et al. Efficient image super-sesolution using pixel attention. aXiv:2010.01073v1 [eess.IV] 2 Oct 2020. 6. Zongcai D, Ding L, Jie L, et al. Fast and memory-efficient network towards efficient image super-resolution. CVPR. 2020; 853-862. 7. Xiaole Z, Yulun Z, Tao Z, et al. Channel Splitting Network for Single MR Image Super-Resolution. IEEE Trans Image Process. 2019. 28(11): 5649-5662. 8. Haoqian W, Xiaowan H, Xiaole Z, et al. Wide weighted attention multi-scale network for accurate MR image super-resolution. IEEE Trans Circuits Syst Video Technol, 2022; 32(3): 962-975.
Figures
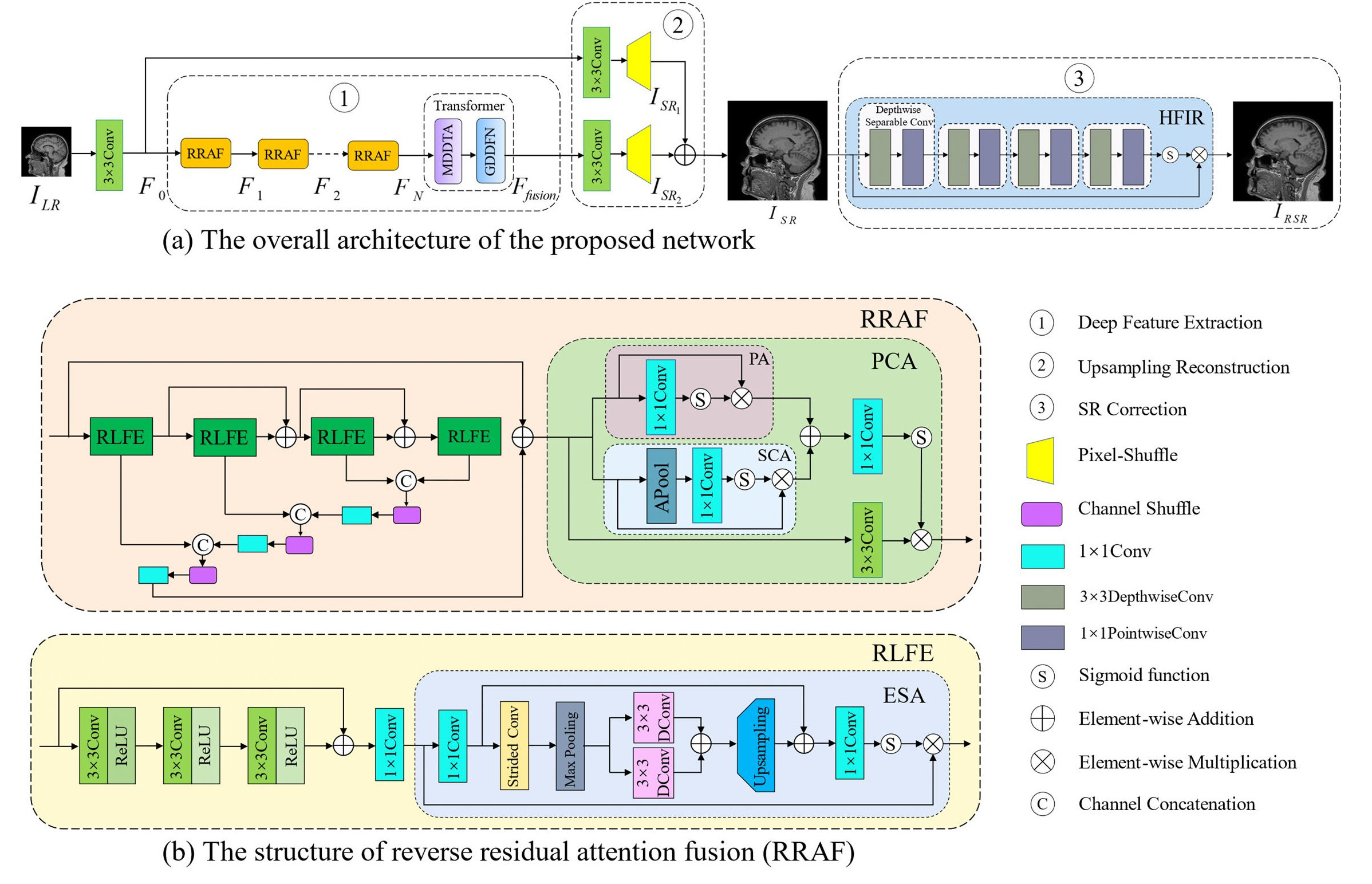
Fig. 1: The network consists of three key components: deep feature extraction, upsampling reconstruction, and SR correction (a). RRAF modules (b) progressively enhance features through residual local feature extraction, Pixel and channel attention (PCA), efficient spatial attention (ESA), channel shuffle (CS), and residual connections. The long-distance skip connection input feature is integrated into the feature refinement process, which culminates with a Transformer module for context enrichment.

Fig. 2: Representative slice demonstrating the results of the reconstruction process following 4× downsampling of a volume IXI (T1w), IXI (T2w) and MICC (T1w) for various SR models. The 1st to 3rd rows depict the reconstruction, a zoomed display of the region highlighted in the red square, and the Mean Squared Error (MSE) evaluation, respectively. (a) sagittal slice for IXI (T1w), (b) axial slice for IXI (T2w), and (c) coronal slice for MICC (T1w). The reconstructed images exhibit the impact of different SR models on image quality and detail preservation.
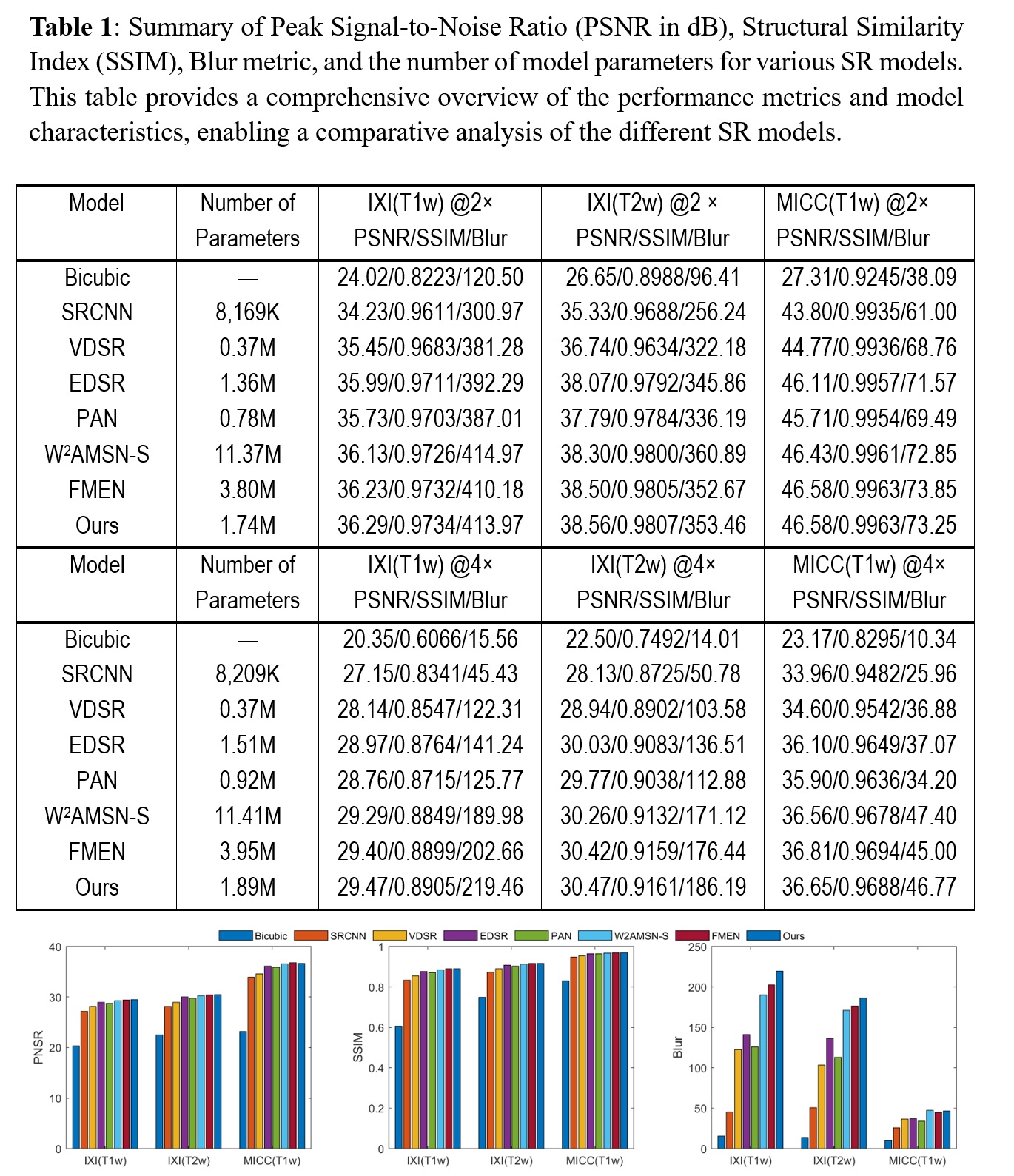
Fig. 3: Bar graphs illustrating image quality metrics at sample scale 4×, including Peak Signal-to-Noise Ratio (PSNR in dB), Structural Similarity Index (SSIM), and Blur assessment. These graphs enable a comprehensive performance comparison between various reconstruction methods, shedding light on the relative effectiveness of each technique in enhancing image quality and detail preservation.
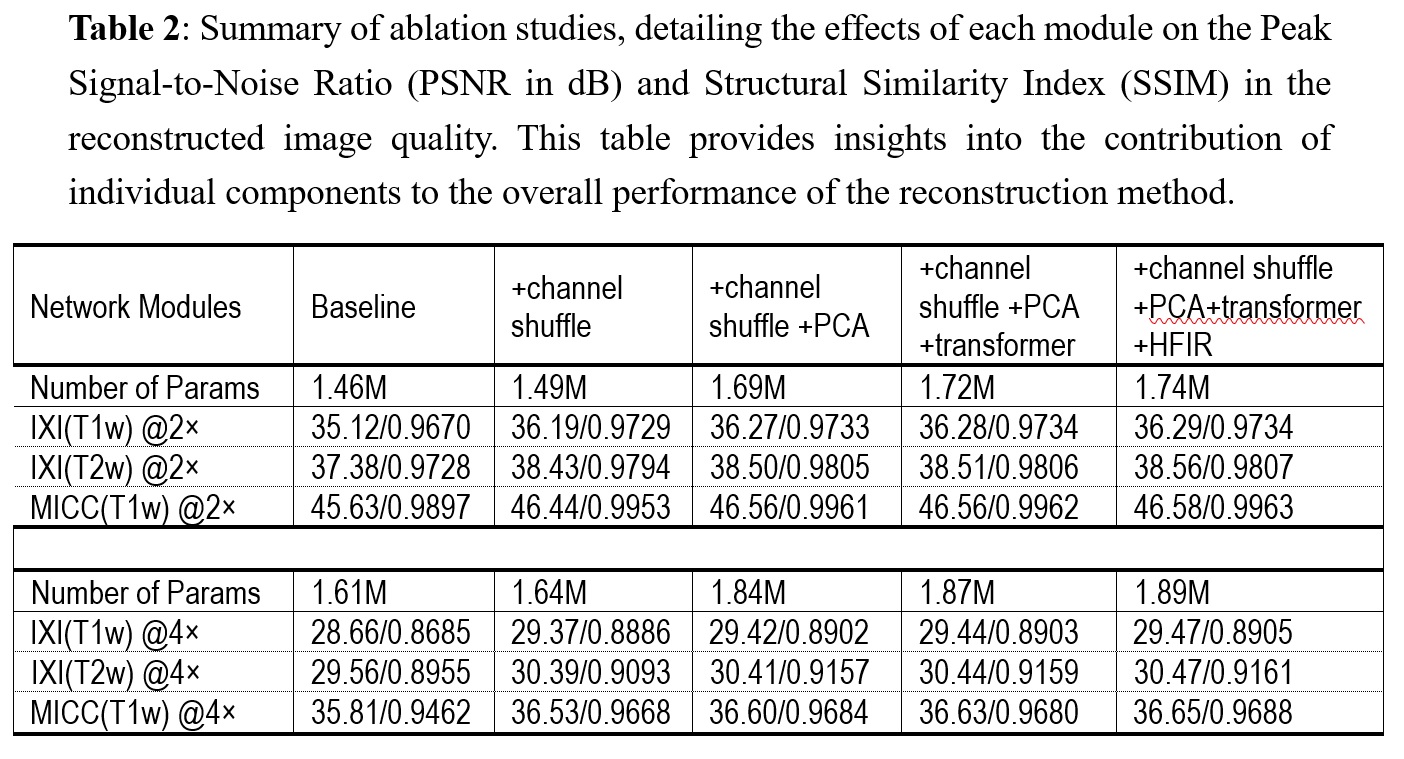
Fig. 4: Summary of ablation studies, detailing the effects of each module on the Peak Signal-to-Noise Ratio (PSNR in dB) and Structural Similarity Index (SSIM) in the reconstructed image quality. This table provides insights into the contribution of individual components to the overall performance of the reconstruction method.
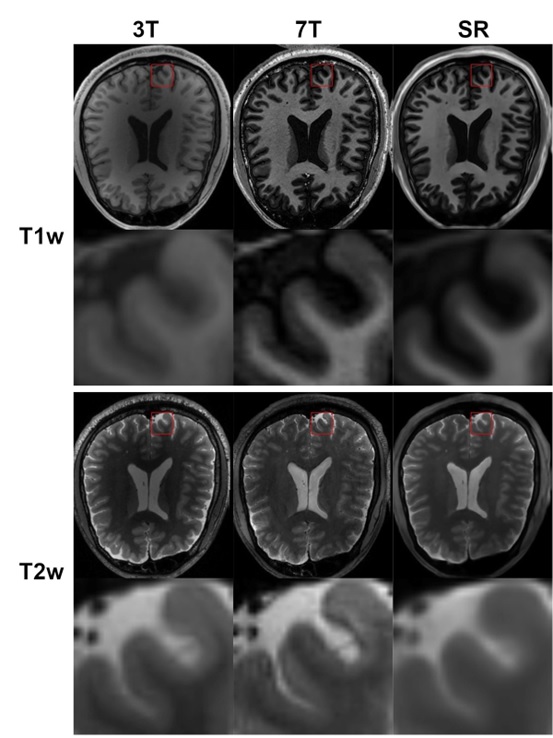
Fig. 5: Representative reconstruction results showcasing the application of the proposed method for SR reconstruction on 3T LR data using a paired HR 7T dataset. This illustrates the feasibility of obtaining T1w and T2w images akin to 7T quality through LR scans, a valuable prospect in clinical practice.