1142
A Contrastive Learning for Accelerating Diffusion Tensor Imaging with High Adaptability to Diffusion Gradient Schemes1Department of Electrical and Electronic Engineering, Yonsei University, Seoul, Korea, Republic of
Synopsis
Keywords: Diffusion Reconstruction, Diffusion Tensor Imaging
Motivation: High-quality DTI requires numerous DWIs, extending scan times; however, despite deep learning's advances in reconstructing DTI with fewer DWIs, its adaptability across various gradient protocols remains limited, challenging its clinical application.
Goal(s): Our aim is to enable consistent, high-quality DTI reconstructions from fewer DWIs across different gradient schemes, enhancing adaptability in various clinical environments.
Approach: We employ self-supervised contrastive learning to extract and preserve key features between datasets derived from the same data with different gradient sampling methods.
Results: Our method reliably enhanced diffusion tensor maps from reduced DWIs across various gradient sampling schemes, outperforming both conventional methods and state-of-the-art deep learning model.
Impact: Our method creates high-quality DTI from fewer DWIs, reducing scan times and easing patient burden, while showing consistent performance across various gradient sampling schemes, ensuring high adaptability and ease of use in diverse clinical settings.
Introduction
Diffusion tensor imaging (DTI)1 is a widely used technique for investigating microstructures of white matter tissue and visualizing fiber tracts. Ideally, DTI can be reconstructed with only 6 diffusion-weighted images (DWIs) and one non-DWI. However, due to low signal-to-noise ratio (SNR), typically over 30 DWIs are required, prolonging scan times. As a result, there’s a growing need to derive accurate DTI from fewer DWIs. Recently, deep learning has shown promising performance in reconstructing DTI with fewer DWIs2,3, yet these methods often lack generalizability across different scanning protocols due to their reliance on specific diffusion gradient directions used during training.To address this challenge, we propose a self-supervised contrastive learning approach to efficiently enhances DTI quality under diverse gradient acquisition conditions. As our method can effectively learn to identify and preserve the most relevant features from the data, it not only yields high-quality DTI with fewer DWIs but also ensures consistent DTI enhancement, regardless of varying diffusion gradient schemes.
Method
DataWe utilized diffusion MRI (dMRI) data of 35 individuals from the HCP-MGH Adult Diffusion dataset4. To simulate various scanning scenarios, we selected subsets of gradient directions (6, 10, and 20 directions out of 64 DWIs), which were obtained by rotating optimized diffusion-encoding directions5 and selecting the nearest match from our 64 gradients. After processing these subsets with the linear least square (LLS) method, we generated five DTI variations per subject (Figure 1(A)) and compared to a ground truth DTI, obtained by denoising the full dMRI data with BM4D6 and applying LLS method.
Self-Supervised Contrastive Learning
Our model improves robustness by learning high-level features that are common across different gradient sampling schemes from the same subject’s data. We employed a SimSiam7 network architecture within our contrastive learning framework that uses a stop-gradient operation to obviate the need for negative pairs or large batch sizes, often challenging in the context of medical imaging.
As depicted in Figure 1(B), our architecture processes two DTI datasets $$$x_{1}$$$ and $$$x_{2}$$$ derived from the same original data; $$$x$$$, using different gradient schemes. Each dataset is fed through a shared U-Net8 encoder and subsequently through a projection MLP head denoted as $$$f$$$. Additionally, one dataset undergoes further processing via prediction MLP head;$$$h$$$ The resulting outputs, $$$p_{j} = h(f(x_{j}))$$$ and $$$z_{k} = f(z_{k})$$$, are incorporated into a contrastive loss function; $$$L_{con}$$$, to evaluate the similarity between representations for different DTI pairs. This encourages the model to preserve similar features across the datasets:
$$L_{con} = -\frac{1}{C_2^M} \sum_{j=1}^M\sum_{k=1}^M [I(j,k)\times\frac{1}{2}(D(p_{j}, stopgrad(z_{k}))+D(p_{k}, stopgrad(z_{j})))]$$
where $$$I(j,k) = \begin{cases}1, & j < k\\0, & j \geq k\end{cases}$$$ and $$$D(p_{j},z_{k}) = \frac{p_{j}}{\parallel p_{j}\parallel_{2}}\cdot \frac{z_{k}}{\parallel z_{k}\parallel_{2}}$$$. Given $$$M = 5$$$ subsampled DTIs per scan, the function assesses all unique pairs, $$$C_2^M$$$, within the five subsampled sets and employs a stop-gradient operation to prevent backpropagation from one part of the loss.
Reconstruction Network
After training the encoder, we detached the MLP head and transferred the encoder’s trainable parameters. Subsequently, a U-Net decoder was attached, and trained on DTI data across various subsampling methods using an $$$L1$$$ loss function. Throughout this phase, the encoder’s weights were fixed to preserve its learned features, as illustrated in Figure 1(C).
Result
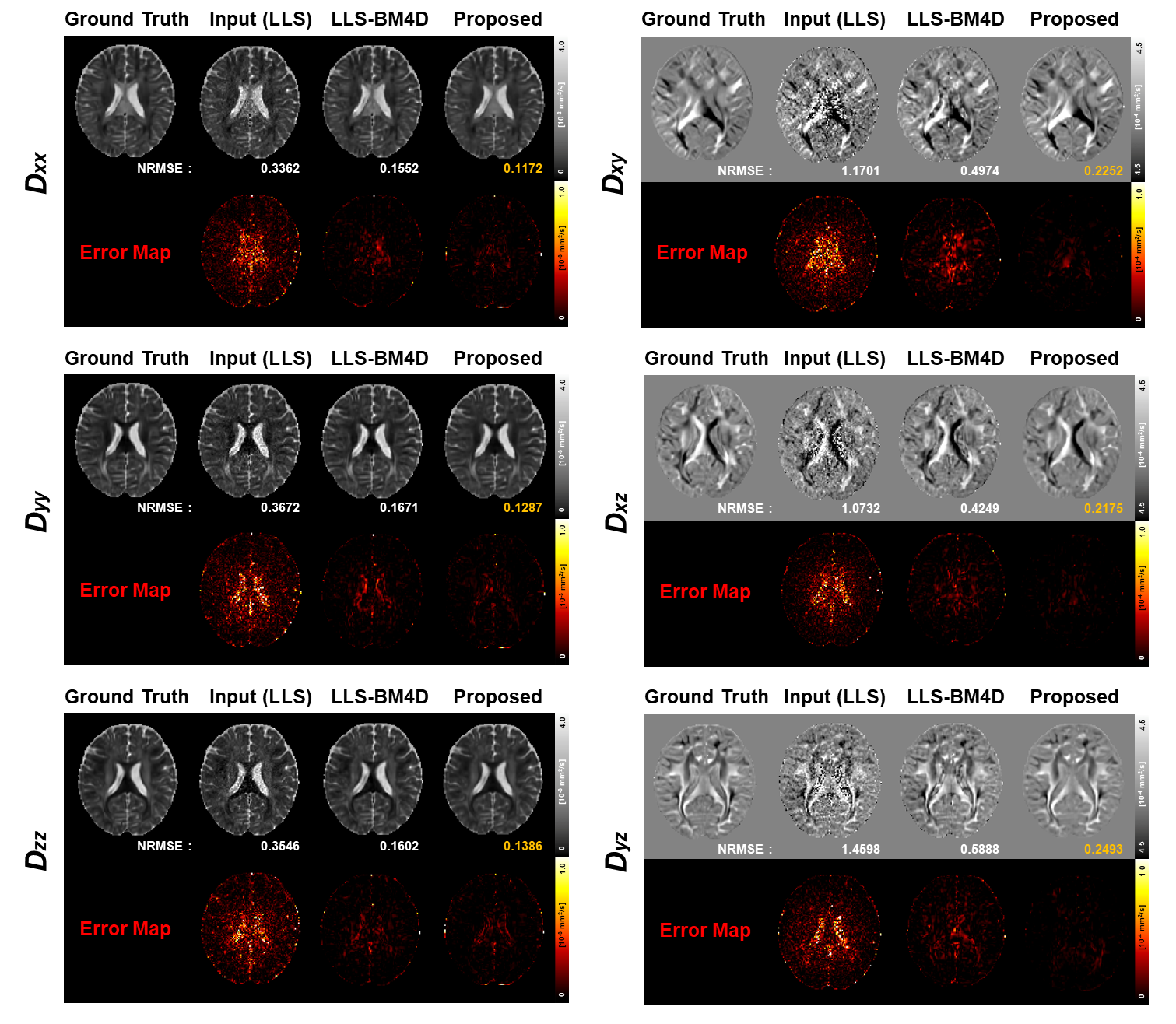
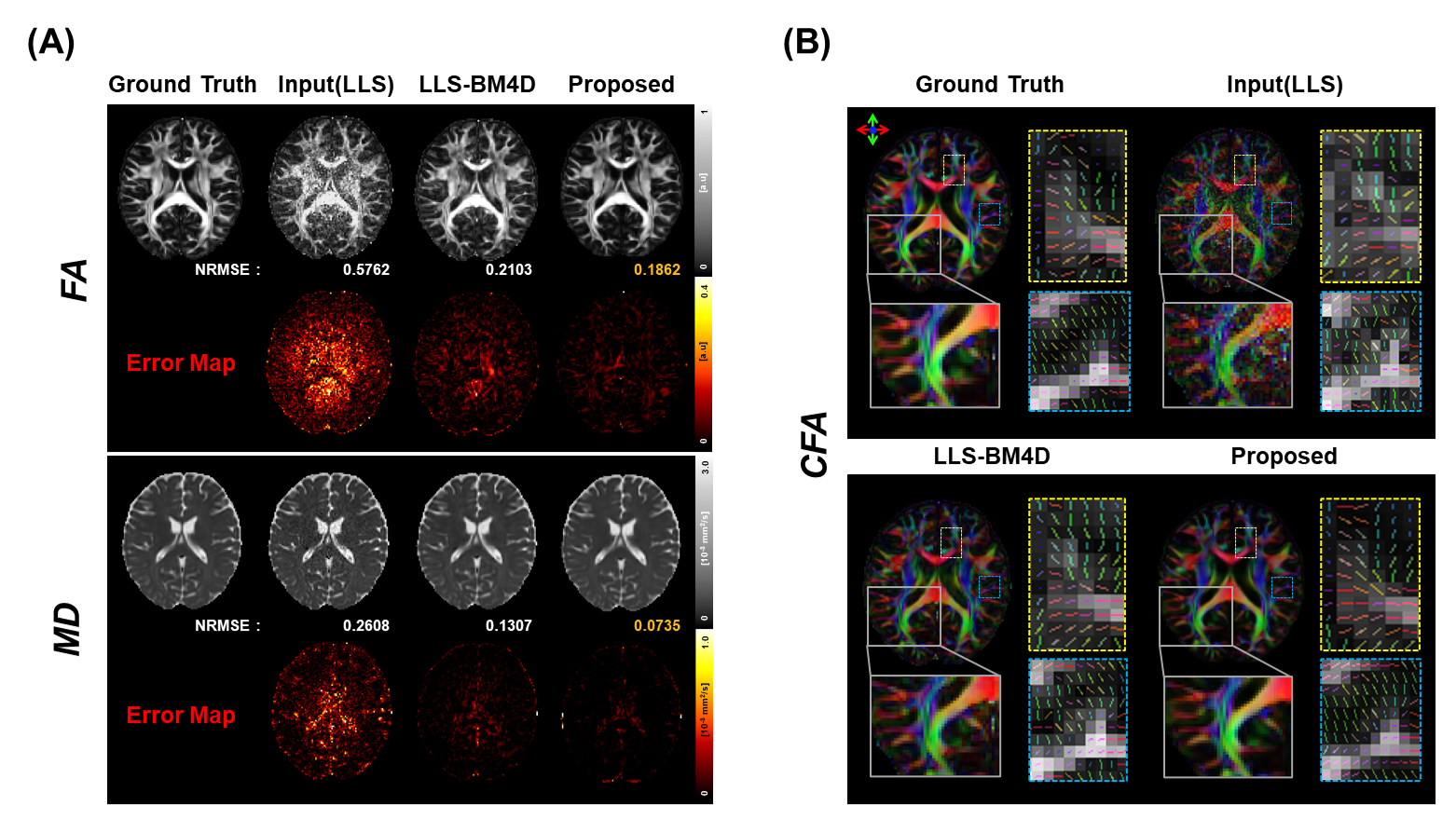
Figure 2 shows the diffusion tensor maps reconstructed from six in-vivo DWIs. Our method successfully recovered tensor maps from the LLS-processed inputs, outperforming the LLS-BM4D method.Figure 3 illustrates the FA, MD and color-coded FA maps derived from six in-vivo DWIs. Our method achieved the lowest NRMSE for both FA and MD, and accurately reconstructed detailed structures that closely align with the ground truth, as evidenced in the color-coded FA maps.
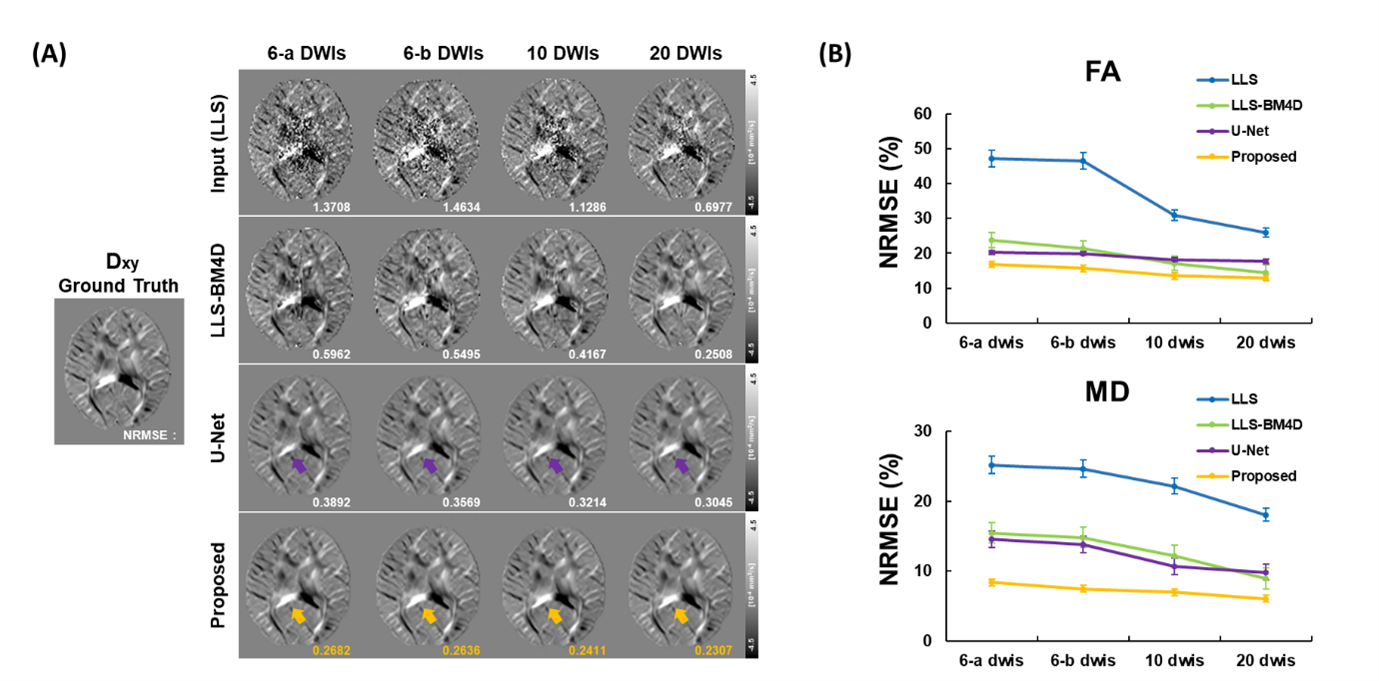
Figure 4(A) demonstrates that our method yields stable diffusion tensor maps across different gradient sampling schemes, outperforming the inconsistent results of LLS-BM4D and U-Net. Furthermore, Figure 4(B) shows that our method’s low NRMSE for FA and MD, demonstrating robustness across various gradient numbers and sampling schemes compared to others.
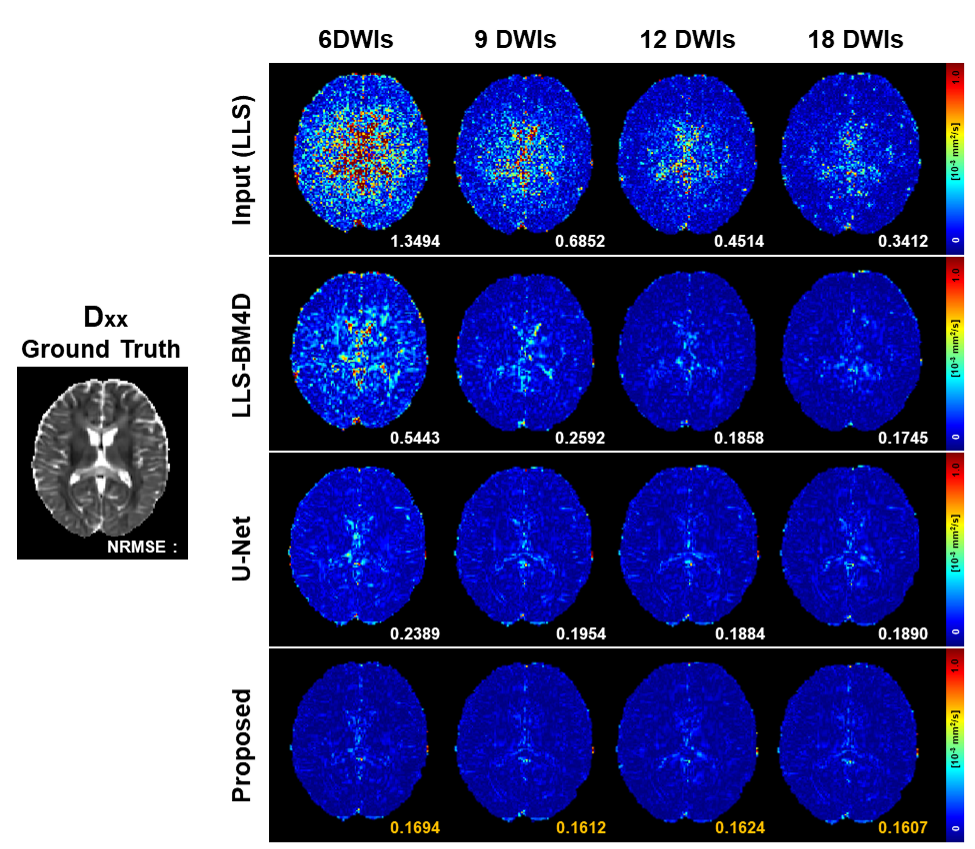
Figure 5 displays error maps for diffusion tensor maps reconstructed from entirely randomly sampled gradients, highlighting our method's extensive adaptability. Our method consistently outperformed others, achieving superior performance even under challenging conditions with extremely high error, such as 6DWIs from random sampling.
Discussion & Conclusion
In our study, we proposed a contrastive learning-based method that improves DTI reconstruction from a limited number of DWIs, adaptable to various gradient acquisition settings. By employing a pre-trained encoder informed by contrastive learning, our approach preserves the most informative features across disparate gradient schemes of the identical scans. This feature preservation, combined with the reconstruction network, enables to efficiently produce high-quality DTIs with robustness to gradient parameter variations.Acknowledgements
This research was supported by the MSIT(Ministry of Science and ICT), Korea, under the ITRC(Information Technology Research Center) support program(IITP-2022-2020-0-01461) supervised by the IITP(Institute for Information & communications Technology Planning & Evaluation).References
[1] Le Bihan, D., Mangin, J. F., Poupon, C., Clark, C. A., Pappata, S., Molko, N., & Chabriat, H. (2001). Diffusion tensor imaging: concepts and applications. Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine, 13(4), 534-546.
[2] Tian, Q., Bilgic, B., Fan, Q., Liao, C., Ngamsombat, C., Hu, Y., ... & Huang, S. Y. (2020). DeepDTI: High-fidelity six-direction diffusion tensor imaging using deep learning. NeuroImage, 219, 117017.
[3] Li, H., Liang, Z., Zhang, C., Liu, R., Li, J., Zhang, W., Liang, D., Shen, B., Zhang, X., Ge, Y., Zhang, J., & Ying, L. (2021). SuperDTI: Ultrafast DTI and fiber tractography with deep learning. Magnetic resonance in medicine, 86(6), 3334–3347.
[4] Fan, Q., Witzel, T., Nummenmaa, A., Van Dijk, K. R., Van Horn, J. D., Drews, M. K., ... & Rosen, B. R. (2016). MGH–USC Human Connectome Project datasets with ultra-high b-value diffusion MRI. Neuroimage, 124, 1108-1114.
[5] Skare, S., Hedehus, M., & Li, T. Q. (2000). Characteristics and stability of different diffusion gradient schemes. In Book of abstracts: Eighth Annual Meeting of the International Society for Magnetic Resonance in Medicine (Vol. 2, p. 806).
[6] Dabov, K., Foi, A., Katkovnik, V., & Egiazarian, K. (2007). Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Transactions on image processing, 16(8), 2080-2095.
[7] Chen, X., & He, K. (2021). Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 15750-15758).
[8] Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 (pp. 234-241). Springer International Publishing.
Figures
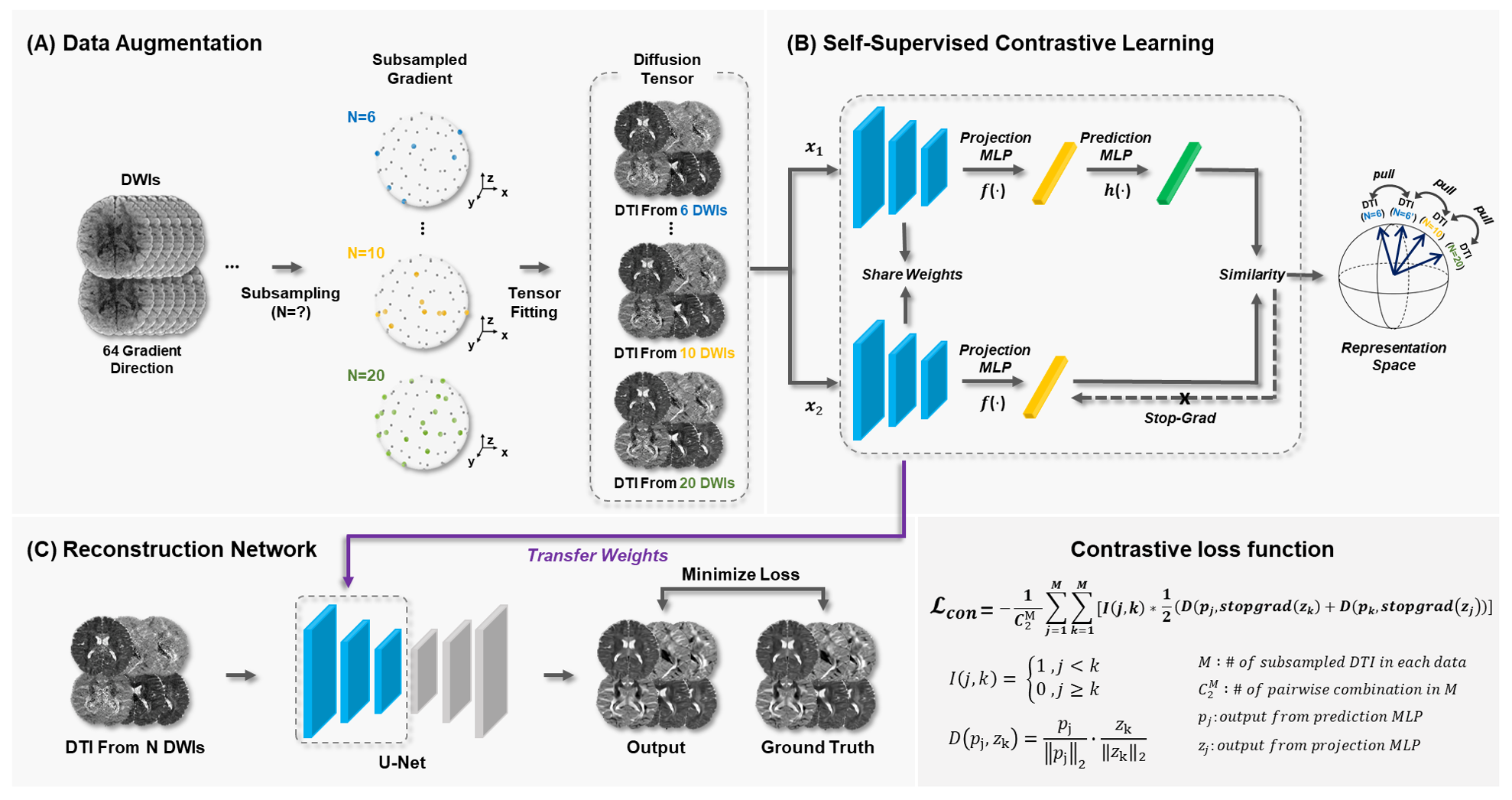
Figure 1. An overview of the proposed contrastive learning framework. (A) Augmentation of data through subsampling of DWI data to generate input DTIs. (B) During the self-supervised contrastive learning phase, two DTI datasets derived from the same subject’s data are processed to calculate contrastive loss. (C) In the reconstruction phase, the network is trained using the parameters from the pre-trained encoder, with an additional decoder for the reconstruction task.