1139
Neighborhood-attention models for incorporating spatial information in deep learning parameter estimation applied to IVIM1Department of Radiology and Nuclear Medicine, St. Olav’s University Hospital, Trondheim, Norway, 2Department of Circulation and Medical Imaging, NTNU – Norwegian University of Science and Technology, Trondheim, Norway, 3Department of Radiology, Boston Children’s Hospital, Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Analysis/Processing, Signal Representations, AI, transformers, synthetic data, parameter estimation, IVIM
Motivation: Conventional model-fitting approaches neglect spatial information. Recent work showed promise in using convolutional neural networks (CNNs) trained on spatially-correlated synthetic data. However, the convergence rate remained suboptimal, and the spatial extent was limited.
Goal(s): To improve estimator performance by utilizing transformer networks and training on larger receptive-fields.
Approach: Transformers with self-attention and neighborhood-attention with increased receptive-field were trained on spatially-correlated synthetic data (IVIM), and evaluated quantitatively using novel fractal-noise maps and in-vivo scans.
Results: Transformers excelled in integrating spatial information over CNNs. The application of larger receptive-fields with neighborhood-attention effectively leveraged correlated signal information from nearby voxels, leading to improved estimator performance.
Impact: The improved parameter estimation from neighborhood-attention models trained on synthetic data brings challenging ill-posed signal analysis problems, like IVIM, closer to clinical implementation. Additionally, the novel fractal-noise maps provide spatially-correlated ground truths, permitting new approaches to quantitative medical image analysis.
Introduction
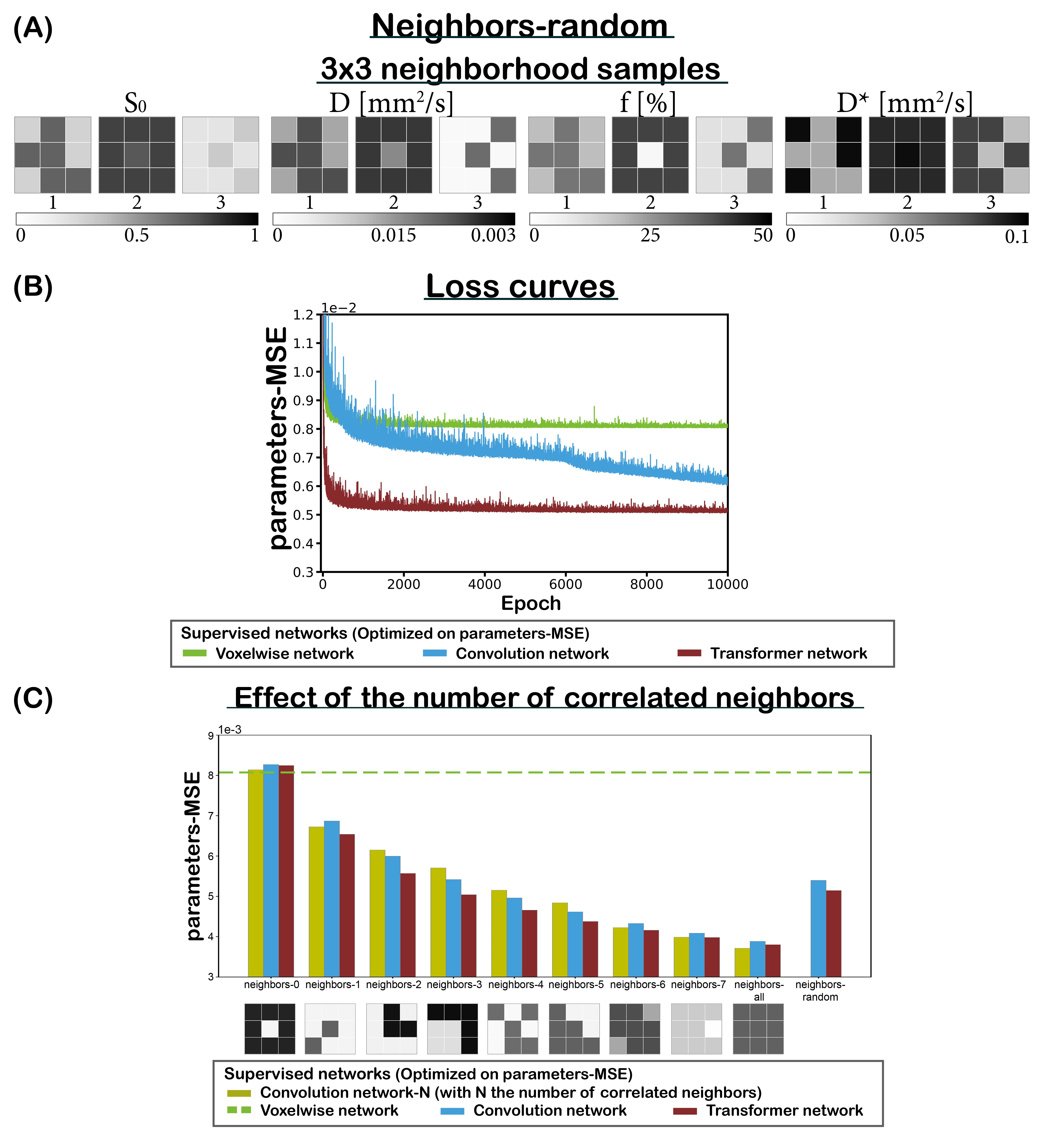
The tissue microenvironment typically exhibits local homogeneity, where properties such as diffusion and perfusion do not change randomly between adjacent voxels1. Leveraging potential correlations between relevant signals in neighboring voxels should therefore enhance model-parameter fitting. However, estimators like least squares (LSQ) and voxelwise neural networks (NNs)2,3 do not incorporate such spatial information4. Our recent work considered convolutional NNs (CNNs)5 with receptive-field 3x3 for incorporating spatial information by training on synthetic data encompassing all plausible combinations of direct correlations. This approach was applied to the intravoxel incoherent motion (IVIM)6 model for diffusion-weighted imaging (DWI), and yielded promising results with apparently reduced noise sensitivity, akin to signal averaging. However, the convergence rate was suboptimal, and the spatial extent was limited.In this work, we address these limitations by replacing CNNs with transformer NNs (attention models)7. Recently, transformers have garnered substantial interest in computer vision8. Conventional transformers rely on self-attention7 (SA), yet their memory usage scales quadratically with the number of pixels, making them less feasible for computer vision tasks. Neighborhood-attention9 (NA) has been proposed as an alternative, which localizes SA to the nearest neighbors, effectively reducing memory consumption. Here we explore whether training with larger receptive-fields can further improve performance, by investigating SA and NA.
Methods
In this work, we considered two types of transformers. The first utilized SA (3 SA-blocks, 128 units) and the second NA (128 units). We trained networks with increasing receptive-field, where SA-X and NA-X denote a receptive-field of X×X voxels. Expanding the receptive-field beyond 7×7 caused excessive memory usage in SA-networks. Therefore, for receptive-fields of 7×7 and larger, NA was employed. Each NA-X network had a varying number of NA-blocks of kernel size 3 (e.g. NA-7 had 3 NA-blocks). We trained a CNN and voxelwise network for comparison. Both CNN and voxelwise networks were multi-layer perceptrons, where the CNN had a 2D-convolution in its first layer with kernel size 3. The network inputs were patches of DWI signals, outputs were IVIM parameters (D: diffusion, D*: pseudo-diffusion, f: perfusion fraction) and S0.In our first experiment, SA-3, CNN and voxel-wise networks were trained supervised on DWI signals simulated by uniformly sampling 3×3 patches of parameters: 0≤S0≤1, 0×10-3≤D≤3×10-3 mm2/s, 0≤f≤50%, and 3×10-3≤D*≤100×10-3 mm2/s, considering 16 b values. Each patch was generated such that a random number of neighbors correlated to its center (neighbors-random, Fig. 1A), meaning that those neighbors shared identical parameters. Rician noise was added to the signals such that S0=1 equated to SNR=200. Convergence rate and final loss were evaluated on the test set consisting of 100,000 patch-wise sets of DWI signals. As proxies for the optimal expected performance of a CNN, an additional set of CNNs was trained specifically for each number of correlated neighbors (neighbors-N, Fig. 1C).
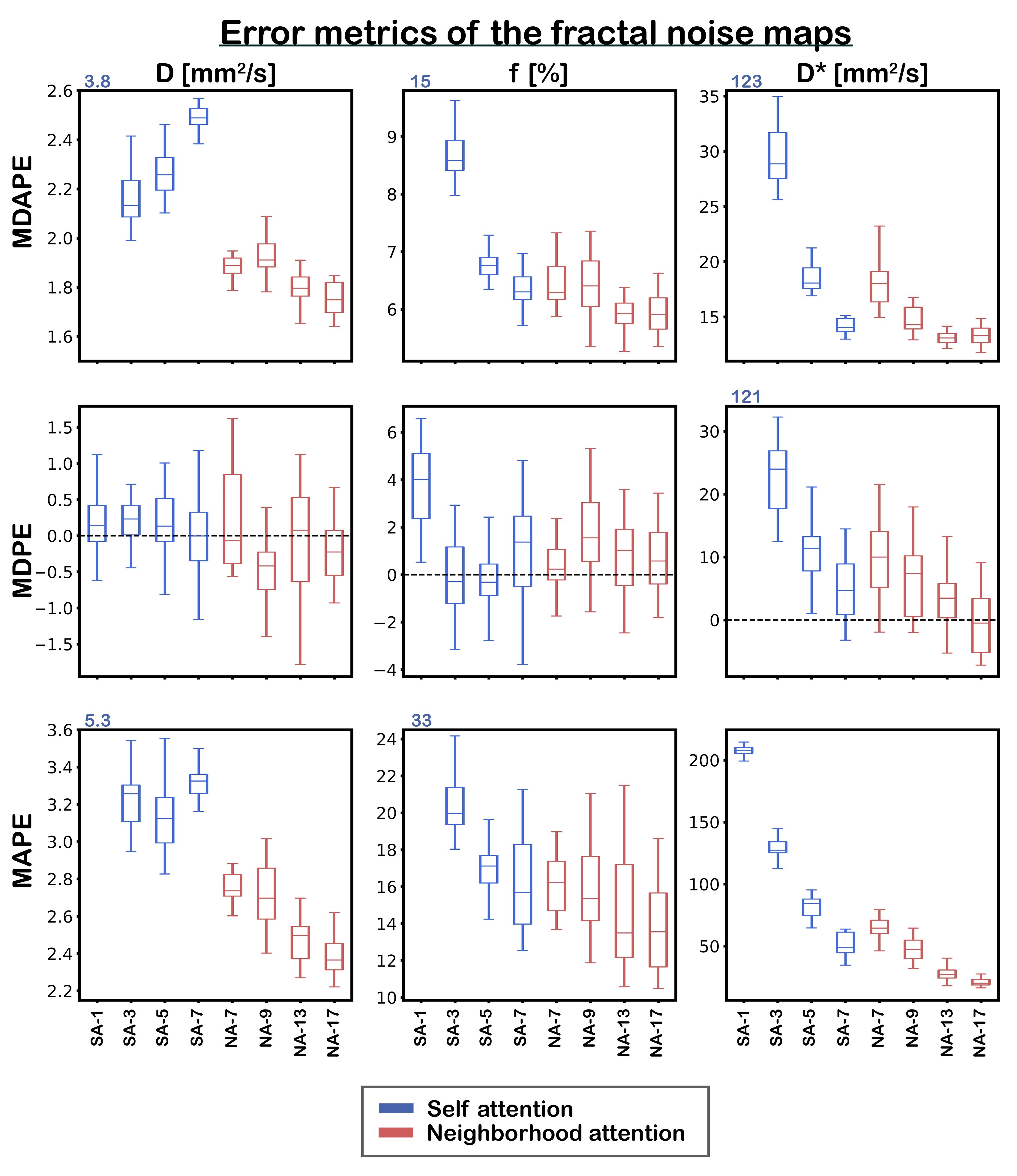
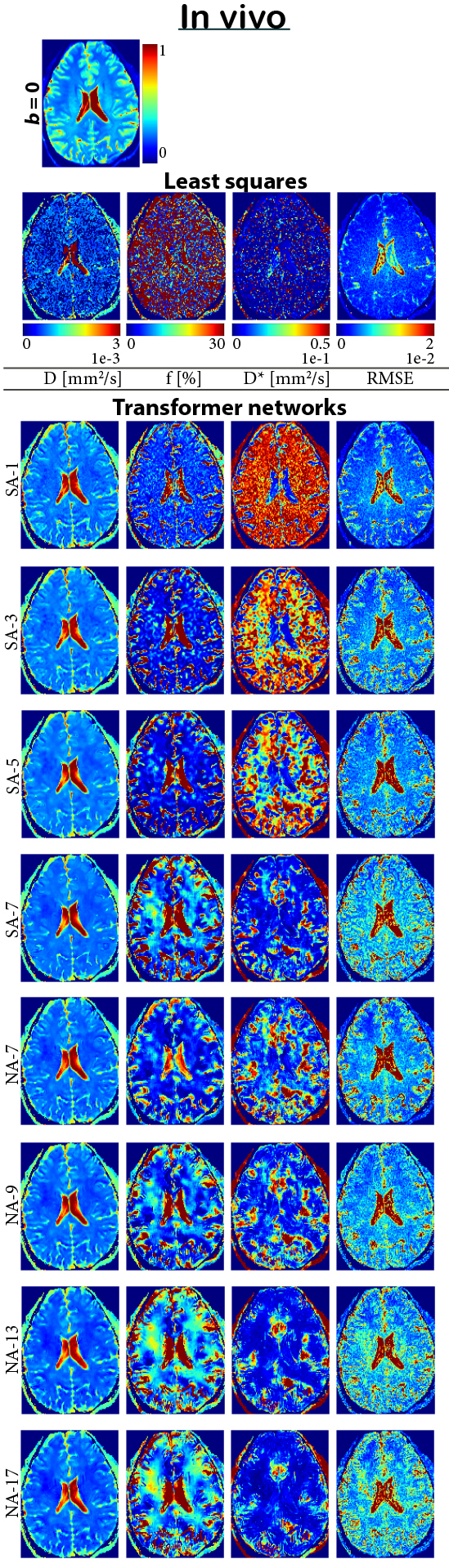
In a second experiment, we trained transformers on larger patch sizes up to 17×17. We conducted a quantitative assessment by testing the networks on synthetic data (128×128 pixels; 16 b values) corresponding to 40 sets of fractal-noise10 parameter maps (Fig. 2). These maps provided spatially-correlated ground truths, considering IVIM parameter ranges relevant to the brain. Evaluation involved assessing parameter maps, median absolute percentage error (MDAPE), median percentage bias (MDPE), mean absolute percentage error (MAPE), and comparison to LSQ. Qualitative assessment was conducted on an IVIM scan from a volunteer.
Results
Transformers outperformed CNNs for incorporating spatial information, exhibiting superior convergence speed and reduced loss (Fig. 1B), and matching or surpassing the CNNs trained for each specific number of correlated neighbors (Fig. 1C). Fig. 3 further shows that training with larger receptive-fields resulted in improved accuracy and reduced inherent supervised bias4 in low SNR regions, while retaining edge-like structures, particularly for D*. Utilizing NA allows training with larger receptive-fields than SA, leading to improved performance. Fig. 4 qualitatively shows similar findings in vivo.Discussion and conclusion
In this work, we showed that transformers outperform CNNs for incorporating spatial information in IVIM parameter estimation when trained supervised on spatially-correlated synthetic data. Quantitative evaluation on novel fractal-noise maps revealed improved performance when trained with larger receptive-fields. SA was limited to smaller receptive-fields due to excessive memory demands, whereas NA could handle larger receptive-fields and therefore may be preferable.Our proposed method brings challenging ill-posed signal analysis problems, like IVIM, closer to clinical application. Furthermore, the novel fractal-noise maps offer spatially-correlated ground truths, which may permit avenues for research within quantitative medical image analysis. Future research should explore whether including additional prior assumptions about the test data into the network's training process, such as representative parameter distributions for tissue types of interest, may further enhance performance.
Acknowledgements
This work was supported by the Research Council of Norway (FRIPRO Researcher Project 302624).References
1. Novikov DS, Fieremans E, Jespersen SN, Kiselev VG. Quantifying brain microstructure with diffusion MRI: Theory and parameter estimation. NMR Biomed. 2019;32(4):1-53. doi:10.1002/nbm.3998
2. Kaandorp MPT, Barbieri S, Klaassen R, et al. Improved unsupervised physics-informed deep learning for intravoxel incoherent motion modeling and evaluation in pancreatic cancer patients. Magn Reson Med. 2021;86(4):2250-2265. doi:https://dx.doi.org/10.1002/mrm.28852
3. Barbieri S, Gurney-Champion OJ, Klaassen R, Thoeny HC. Deep learning how to fit an intravoxel incoherent motion model to diffusion-weighted MRI. Magn Reson Med. 2020;83(1):312-321. doi:10.1002/mrm.27910
4. Kaandorp MPT, Zijlstra F, Federau C, While PT. Deep learning intravoxel incoherent motion modeling: Exploring the impact of training features and learning strategies. Magn Reson Med. 2023;(March):312-328. doi:10.1002/mrm.29628
5. Kaandorp M, Zijlstra F, While P. Synthetic data shows the potential of unsupervised and supervised learning for incorporating spatial information in IVIM fitting. In: Proceedings of Int. Soc. of Magnetic Resonance Imaging. ; 2023. doi:10.1002/mrm.27910
6. Le Bihan D, Breton E, Lallemand D, Grenier P, Cabanis E, Laval-Jeantet M. MR imaging of intravoxel incoherent motions: application to diffusion and perfusion in neurologic disorders. Radiology. 1986;(161(2), 401-407).
7. Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Adv Neural Inf Process Syst. 2017;2017-Decem(Nips):5999-6009.
8. Khan S, Naseer M, Hayat M, Zamir SW, Khan FS, Shah M. Transformers in Vision: A Survey. ACM Comput Surv. 2022;54(10):1-30. doi:10.1145/3505244
9. Hassani A, Walton S, Li J, Li S, Shi H. Neighborhood attention transformer. Proc IEEE/CVF Conf Comput Vis Pattern Recognit. Published online 2023:6185-6194. http://arxiv.org/abs/2209.15001
10. Perlin K. Image Synthesizer. Comput Graph. 1985;19(3):287-296. doi:10.1145/325165.325247
Figures