1087
Accelerated CEST Imaging with Deep Learning Priors and Synthetic Brain Tumor Datasets1Key Laboratory for Biomedical Engineering of Ministry of Education, Department of Biomedical Engineering, College of Biomedical Engineering & Instrument Science, Zhejiang University, Hangzhou, Zhejiang, China, 2MR Collaboration, Siemens Healthcare Ltd., Shanghai, China
Synopsis
Keywords: CEST / APT / NOE, Machine Learning/Artificial Intelligence, Synthetic Datasets
Motivation: The clinical application of CEST MRI is constrained by its relatively long scan time.
Goal(s): We aim to develop a deep learning reconstruction method for accelerating CEST imaging in the absence of true experimental data.
Approach: Here, we propose a model-based deep learning framework, in conjunction with the Channel-wise Attention mechanism and Total variation regularization, dubbed as MoDL-CAT. Moreover, we propose a new workflow to synthesize CEST data from the BraTS and fastMRI repositories.
Results: We demonstrate that the BraTS-CEST dataset can improve the performance of all deep learning networks tested, and the MoDL-CAT method achieves superior reconstruction quality to the state-of-the-art methods.
Impact: The proposed deep learning framework with channel-wise attention may offer a better prior for reconstruction. And our novel workflow to synthesize high-quality brain tumor CEST datasets might help researchers with limited data to explore various methods for accelerating CEST imaging.
Introduction
Chemical Exchange Saturation Transfer (CEST) is a novel molecular MRI technique that can detect non-water compounds in tissues and diagnose various diseases1-3. However, it requires repeated saturation and readout at different frequencies, causing a long scan time and limiting its routine clinical adoption. Recently, a Model-based Deep Learning (MoDL) framework was proposed4, which replaced traditional reconstruction priors with networks and showed promising results in accelerated MRI. Here, we further develop a novel MoDL-based method for accelerated CEST imaging.Theory
The reconstruction of images from under-sampled k-space data can be formulated as the following optimization problem: $${\rm{\qquad\qquad\qquad\qquad}}{{\bf{x}}_{{\rm{recon}}}}=\mathop{{\rm{argmin}}}\limits_{\bf{x}}\left\|{{\bf{b}}-{\bf{Ax}}}\right\|_2^2+\lambda\left\|{{{\mathop{\rm{N}}\nolimits}_{\bf{w}}}({\bf{x}})}\right\|_2^2+\mu{\left\|{{\mathop{\rm{TV}}\nolimits}({\bf{x}})}\right\|_1}{\rm{\qquad\qquad\qquad\qquad[1]}}$$ where b represents multi-coil k-space data, and A = MFC, with M as the k-space sampling mask, F as the Fourier transform operator, and C as coil sensitivities. Nw(·) refers to the artifact estimator, aiming to obtain a denoised version (Dw) of x as in the original MoDL method4, where the subscript w indicates the network parameters. TV(·) denotes the extra total variation regulator introduced in this work, and [λ, μ] are regularization weights. Eq. [1] can be solved by the alternating strategy5. Notably, the TV regularization term with L1 norm is handled with the proximal gradient decent method, and the kth iteration is as follows: $${\rm{\qquad\qquad\qquad\qquad\qquad\quad}}\left\{{\begin{array}{*{20}{c}}{{{\bf{z}}_{k-1}}={{\mathop{\rm{D}}\nolimits}_{\bf{w}}}({{\bf{x}}_{k-1}})={{\bf{x}}_{k-1}}-{{\mathop{\rm{N}}\nolimits}_{\bf{w}}}({{\bf{x}}_{k-1}})}\\{{{\bf{x}}^+}={{({{\bf{A}}^{\rm{H}}}{\bf{A}}+\lambda{\bf{I}})}^{-1}}({{\bf{A}}^{\rm{H}}}{\bf{b}}+\lambda{{\bf{z}}_{k-1}})}\\{{{\bf{x}}_k}={{{\mathop{\rm{Prox}}\nolimits}}_{\mu{{\left\|{{\mathop{\rm{TV}}\nolimits}(\cdot)}\right\|}_1}}}({{\bf{x}}^+})}\end{array}}\right.{\rm{\qquad\qquad\qquad\qquad\qquad\quad[2]}}$$ We consider each iteration as a serial module, and the unfolded network with N serial modules is illustrated in Fig. 1a. In the basic Nw unit (Fig. 1b), the channel-wise attention convolutional layer (Fig. 1c) can adaptively capture features at different spatial scales6,7. Meanwhile, the output of the (k-1)th module—xk-1—is reused as the initial value—xest,k—during the conjugate gradient descent calculation of the kth module, avoiding the burn-in period caused by zero initialization. The proposed framework improves MoDL with the Channel-wise Attention mechanism and Total variation regularization, and thus is abbreviated as MoDL-CAT.Methods
To train the proposed MoDL-CAT framework, we synthesized a CEST dataset named BraTS-CEST from the well-known BraTS dataset8, as illustrated in Fig. 2. Firstly, we re-added the skin and skull structures absent in BraTS tumor images, as they provide essential features for artifact estimation. Secondly, we obtained the phase information and coil sensitivities9 from the fastMRI dataset10. Thirdly, we matched z-spectra with different tissues and relaxation times voxel-wise, using logarithmically discretized T1w and T2w images as indices. Finally, simulated z-spectra were imposed on the multi-coil anatomical images.For comparison, we prepared two training sets: BraTS-CEST and fastMRI-CEST, both providing 7400 samples. The latter was generated following the recent CEST-VN work11. The proposed MoDL-CAT framework was optimized using the Adam method12, and compared with conventional reconstruction (GRAPPA13 and compressed sensing L+S14) and deep learning (MoDL4 and CEST-VN11) methods.
All deep learning methods were trained using synthesized datasets, and evaluated using in vivo data from 5 glioma patients and 3 healthy volunteers. The human data were acquired on a 3T MRI system (Siemens MAGNETOM Prisma) with a 20-channel head coil. A single-slice TSE-CEST sequence was conducted with 54 saturation offsets15, and the WASSR16 sequence was run for B0 correction.
Results
Fig. 3 compares source images and k-space data from different datasets. As the saturation frequency approaches 0 ppm, the k-space pattern (Fig. 3a) of BraTS-CEST images shows a similar trend of expansion to that of experimental data. This is likely because the images from the BraTS dataset were finely segmented and different compartments were assigned different z-spectra. In contrast, the fastMRI-CEST dataset11 didn’t allow such fine granularity and thus yielded worse concordance with true data (Fig. 3b).The manifold analysis in Fig. 4a also demonstrates that the distribution of BraTS-CEST data is closer to the cluster of true data in a high-dimensional space than the fastMRI-CEST data11. Importantly, Fig. 4b illustrates that both CEST-VN11 and MoDL-CAT methods achieved lower errors when trained on the BraTS-CEST dataset. Thus, all succeeding analyses used the BraTS-CEST dataset.
Fig. 5a displays 4-fold-accelerated APTw images and their corresponding errors from conventional and deep learning methods in a brain tumor patient. The proposed MoDL-CAT method outperformed the others regarding artifact removal and detail preservation. Fig. 5b presents boxplots for the quantitative results of different methods in all 8 subjects tested, with MoDL-CAT achieving the lowest nRMSE and the highest SSIM for both source images and APTw maps.
Conclusion
This work introduced a novel model-based deep learning reconstruction framework called MoDL-CAT, which incorporated the channel-wise attention mechanism and total variation regularization, improving CEST image quality compared to state-of-the-art methods. Furthermore, a novel workflow of synthesizing CEST data from the BraTS repository was proposed, which improved reconstruction results versus the previous fastMRI-CEST dataset11.Acknowledgements
National Natural Science Foundation of China: 81971605. Key R&D Program of Zhejiang Province: 2022C04031. Leading Innovation and Entrepreneurship Team of Zhejiang Province: 2020R01003. This work was supported by the MOE Frontier Science Center for Brain Science & Brain-Machine Integration, Zhejiang University.
References
1. Wu B, Warnock G, Zaiss M, Lin C, Chen M, Zhou Z, Mu L, Nanz D, Tuura R, Delso G. An overview of CEST MRI for non-MR physicists. EJNMMI physics 2016;3(1):1-21.
2. Zaiss M, Bachert P. Chemical exchange saturation transfer (CEST) and MR Z-spectroscopy in vivo: a review of theoretical approaches and methods. Physics in Medicine & Biology 2013;58(22):R221.
3. Zhou J, Heo HY, Knutsson L, van Zijl PC, Jiang S. APT‐weighted MRI: techniques, current neuro applications, and challenging issues. Journal of Magnetic Resonance Imaging 2019;50(2):347-364.
4. Aggarwal HK, Mani MP, Jacob M. MoDL: Model-based deep learning architecture for inverse problems. IEEE transactions on medical imaging 2018;38(2):394-405.
5. Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends® in Machine learning 2011;3(1):1-122.
6. Woo S, Park J, Lee J-Y, Kweon IS. Cbam: Convolutional block attention module. 2018. p 3-19.
7. Li X, Wang W, Hu X, Yang J. Selective kernel networks. 2019. p 510-519.
8. Menze BH, Jakab A, Bauer S, Kalpathy-Cramer J, Farahani K, Kirby J, Burren Y, Porz N, Slotboom J, Wiest R. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE transactions on medical imaging 2014;34(10):1993-2024.
9. Uecker M, Lai P, Murphy MJ, Virtue P, Elad M, Pauly JM, Vasanawala SS, Lustig M. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magnetic resonance in medicine 2014;71(3):990-1001.
10. Zbontar J, Knoll F, Sriram A, Murrell T, Huang Z, Muckley MJ, Defazio A, Stern R, Johnson P, Bruno M. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv preprint arXiv:181108839 2018.
11. Xu J, Zu T, Hsu Y-C, Wang X, Chan KWY, Zhang Y. Accelerating CEST imaging using a model-based deep neural network with synthetic training data. Magnetic resonance in medicine 2023;1-17.
12. Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:14126980 2014.
13. Griswold MA, Jakob PM, Heidemann RM, Nittka M, Jellus V, Wang J, Kiefer B, Haase A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine 2002;47(6):1202-1210.
14. Otazo R, Candes E, Sodickson DK. Low‐rank plus sparse matrix decomposition for accelerated dynamic MRI with separation of background and dynamic components. Magnetic resonance in medicine 2015;73(3):1125-1136.
15. Liu R, Zhang H, Niu W, Lai C, Ding Q, Chen W, Liang S, Zhou J, Wu D, Zhang Y. Improved chemical exchange saturation transfer imaging with real‐time frequency drift correction. Magnetic resonance in medicine 2019;81(5):2915-2923.
16. Kim M, Gillen J, Landman BA, Zhou J, Van Zijl PC. Water saturation shift referencing (WASSR) for chemical exchange saturation transfer (CEST) experiments. Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine 2009;61(6):1441-1450.
Figures
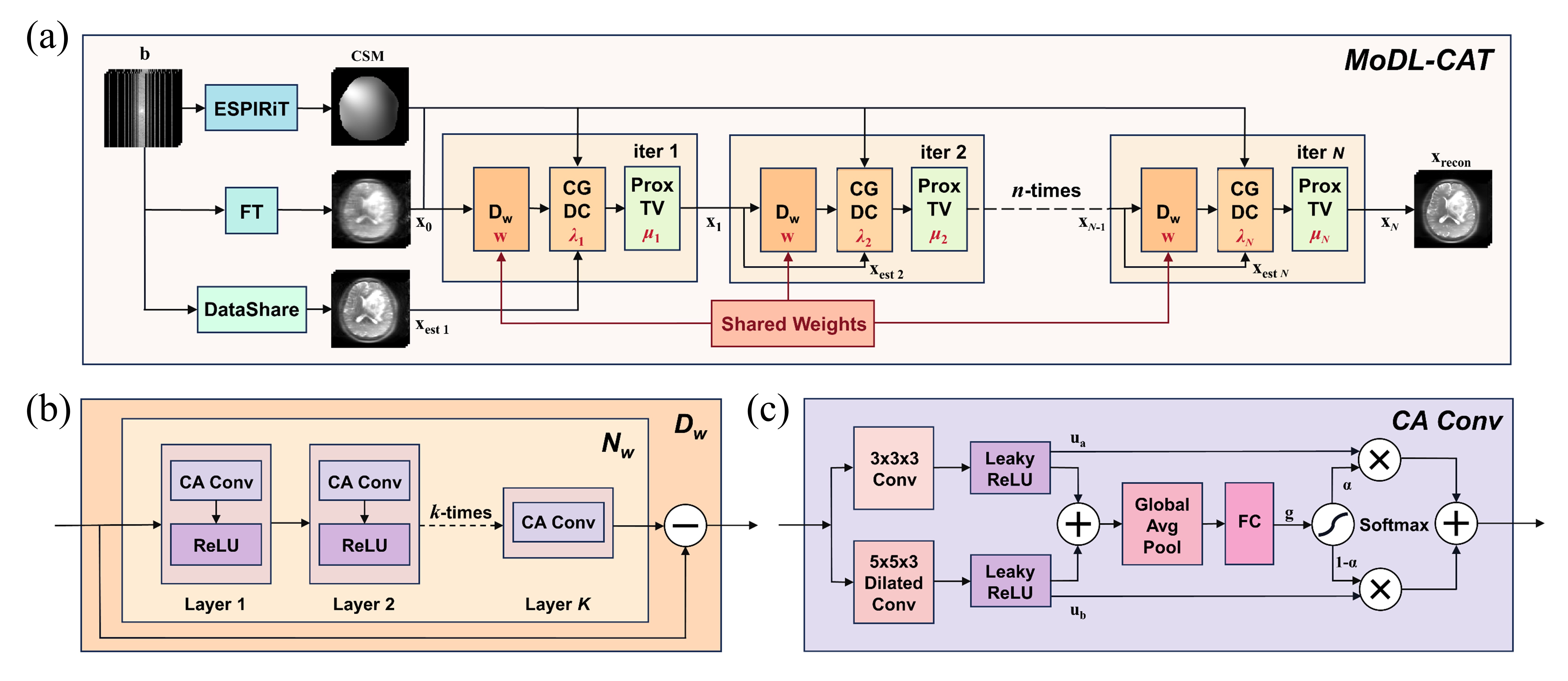
Fig. 1. Architecture of the proposed MoDL-CAT network. (a) The unfolded MoDL-CAT network, with trainable weights highlighted in red, in which the denoising block—Dw—shares weights across modules. (b) Each Dw block consists of an artifact estimator Nw and a residual connection. (c) The layout of each Channel-wise Attention convolutional (CA-conv) layer deployed in the artifact estimator Nw.
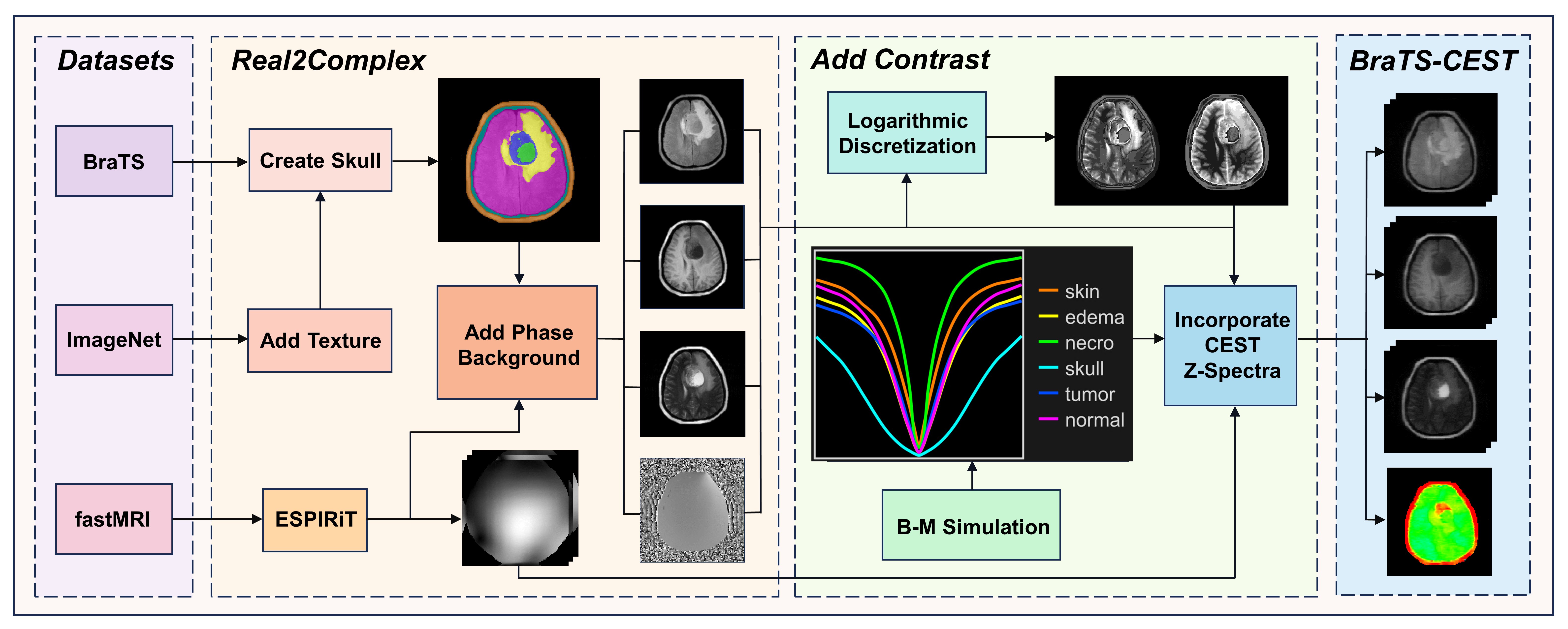
Fig. 2. Flowchart illustrating the synthesis of the BraTS-CEST dataset from the BraTS repository. Skull structures are reintroduced to brain tumor images of the BraTS dataset, and then the phase information and coil sensitivities from the fastMRI dataset are added to generate multi-coil k-space data. Subsequently, Z-spectra are imposed voxel-wise to create CEST contrast for different tissue types using Bloch-McConnell simulations.
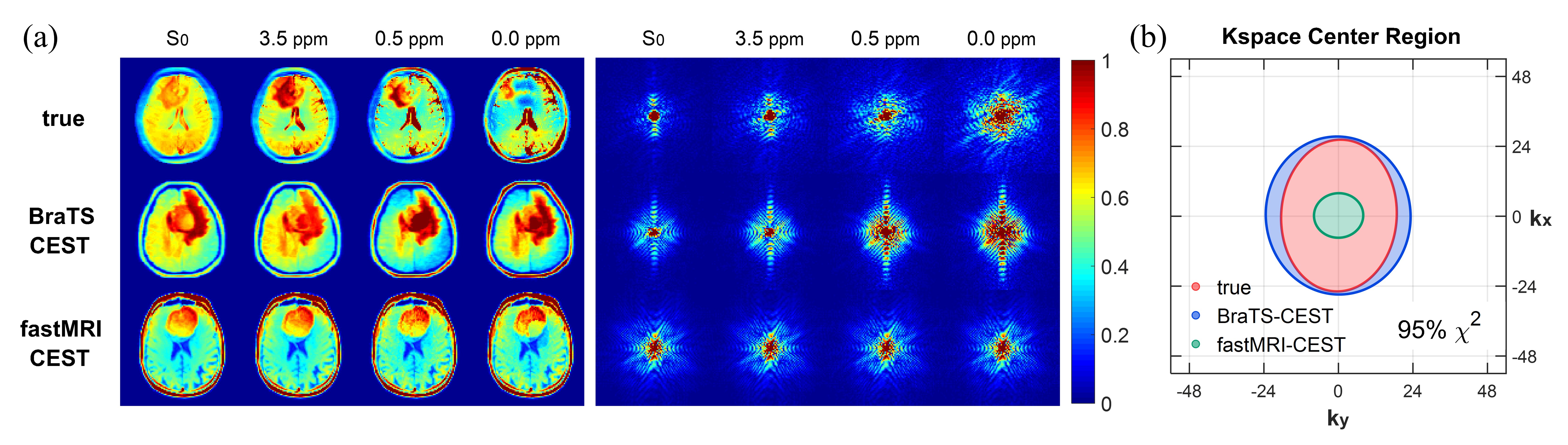
Fig. 3. Comparison of true experimental data, and synthetic BraTS-CEST and fastMRI-CEST data. (a) CEST source images and their corresponding k-space maps. All images are normalized by the maximum amplitudes at each offset. (b) Confidence ellipses (95% confidence intervals of Chi-Square distribution) illustrating the k-space regions at 0 ppm with values greater than the median k-space value at 3.5 ppm. Ellipses were calculated using all 8 true experimental data and 50 randomly selected synthetic data respectively.
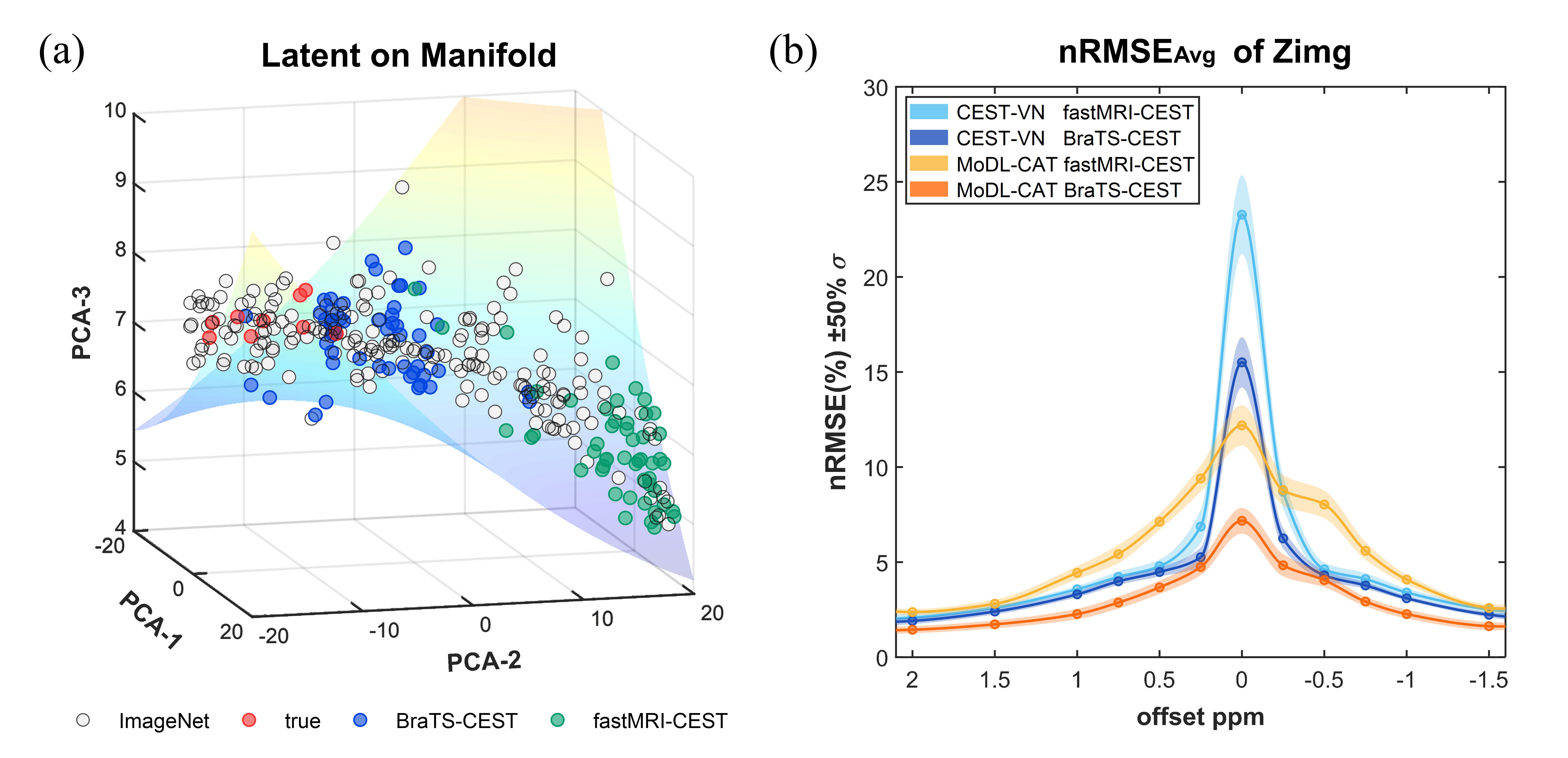
Fig. 4. Quantitative comparison of different datasets. (a) A manifold analysis of latent variables from various image datasets. The BraTS-CEST dataset has the shortest Riemannian distance from true experimental data. (b) Average reconstruction errors for CEST-VN and MoDL-CAT networks trained on BraTS-CEST and fastMRI-CEST datasets. The shaded regions represent the standard deviation σ of errors. nRMSE stands for normalized root mean squared error.
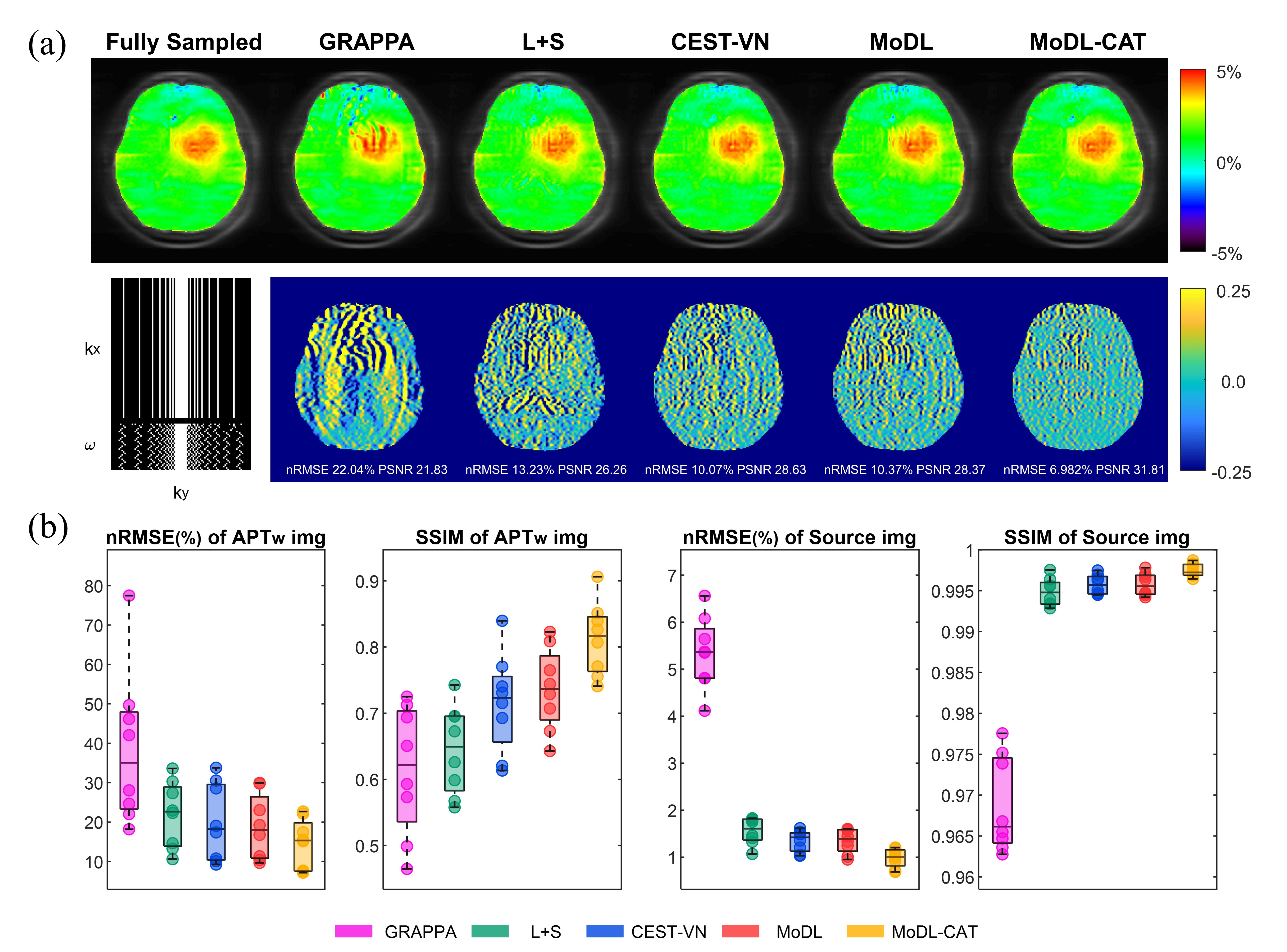
Fig. 5. Reconstruction results of 4-fold accelerated images using various methods. (a) Reconstructed APTw images and their corresponding errors versus fully sampled results from a glioma patient. (b) Boxplots illustrating nRMSE and SSIM pooled in all subjects for each reconstruction method. SSIM stands for structural similarity index.