1076
Rotating-view super-resolution (ROVER)-MRI reconstruction using tailored Implicit Neural Network1Brigham and Women's Hospital, Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence
Motivation: Direct acquisition of high resolution data is time-consuming and degrades SNR. Super-resolution reconstruction (SRR) is widely used to address these challenges. However, existing reconstruction tools use algorithms that are sensitive to noise and motion.
Goal(s): Our study aims to develop a training-free deep learning-based SRR method that integrates multi-view thick-slice data to reconstruct images with enhanced spatial resolution and high SNR.
Approach: We used an implicit neural representation (INR) network, leveraging data from scans at various views, to achieve high isotropic SRR.
Results: Our technique exhibited 30% better SNR and significant motion-robustness compared to existing techniques.
Impact: Implicit neural representations allow continuous functional representation of MRI images thereby being a natural candidate for performing SRR in low SNR regimes. Our study validates the feasibility of employing INRs to reduce scan time, motion artifacts, and achieve high-quality SRR.
Introduction
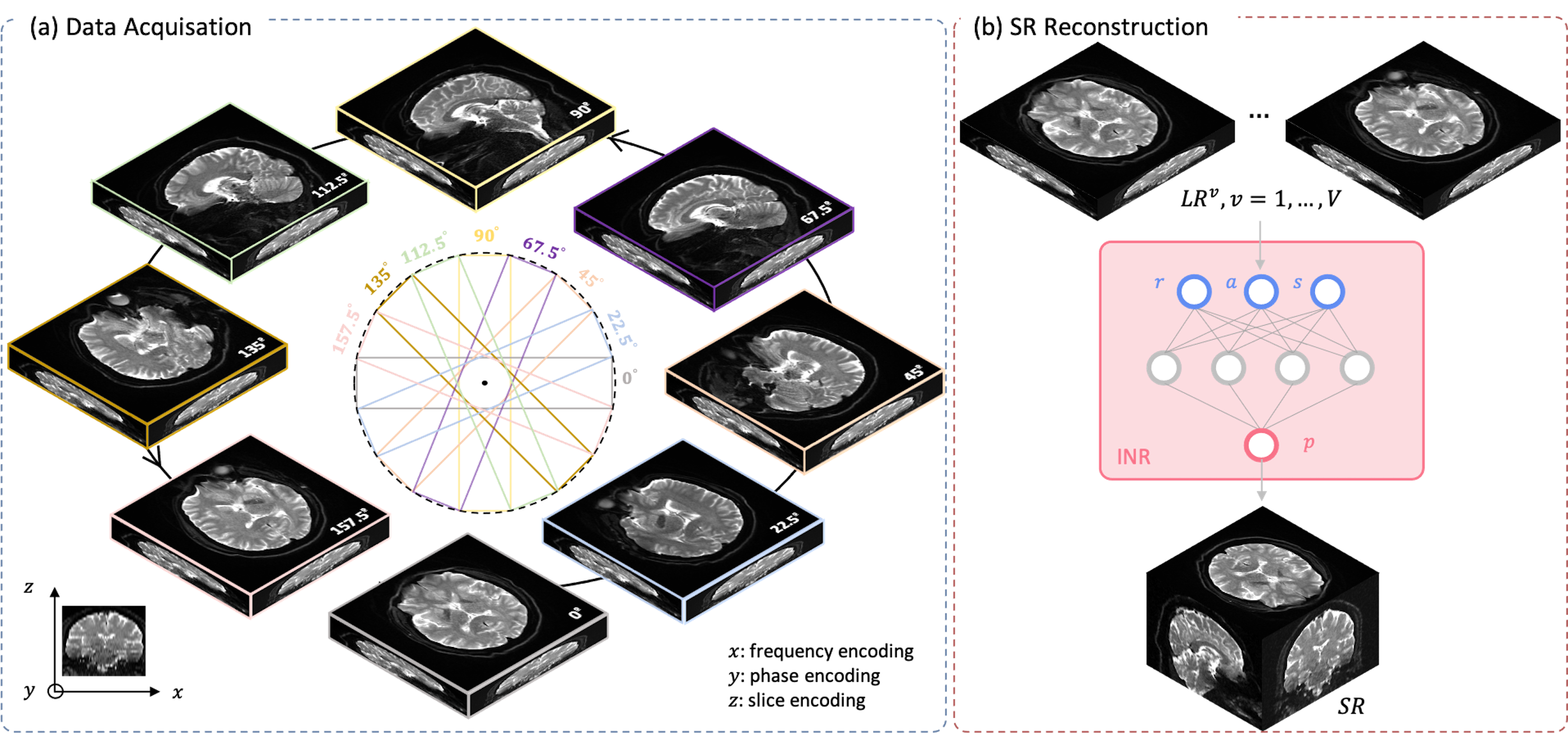
High spatial resolution in MRI aids in precise anatomical localization, enhancing the quality of interpretation and analysis. However, acquiring direct high-resolution (HR) images is plagued with low SNR and long scan times. Other challenges include patient motion and other physiological noise during prolonged scans. Current acquisition methods include RF-encoding of thick slabs using gSlider[1] or acquiring rotating/translating views with thick slabs[2,3,4]. The reconstruction of the data in these cases is typically done using standard L2 minimization with a Tikonov regularization term. However, such an approach is highly sensitive to noise and cannot be easily extended to sparse data regimes. While standard supervised deep learning techniques provide an alternative, yet they require ground truth high-resolution data for training, which is typically not available. Further, such techniques are highly sensitive to the training dataset used, and may fail in cases of gross anatomical abnormalities.We address these challenges in this work, and propose to use a training-free unsupervised implicit neural network[5] that provides a continuous functional representation of the image and does not require any ground truth data for learning the representation. Given the continuous representation, INRs can naturally be used to represent data from different views, thereby allowing SRR with fewer views than that required by Nyquist criteria (π/2 x super-resolution factor).
Methods
- Data
- Implicit Neural Representation
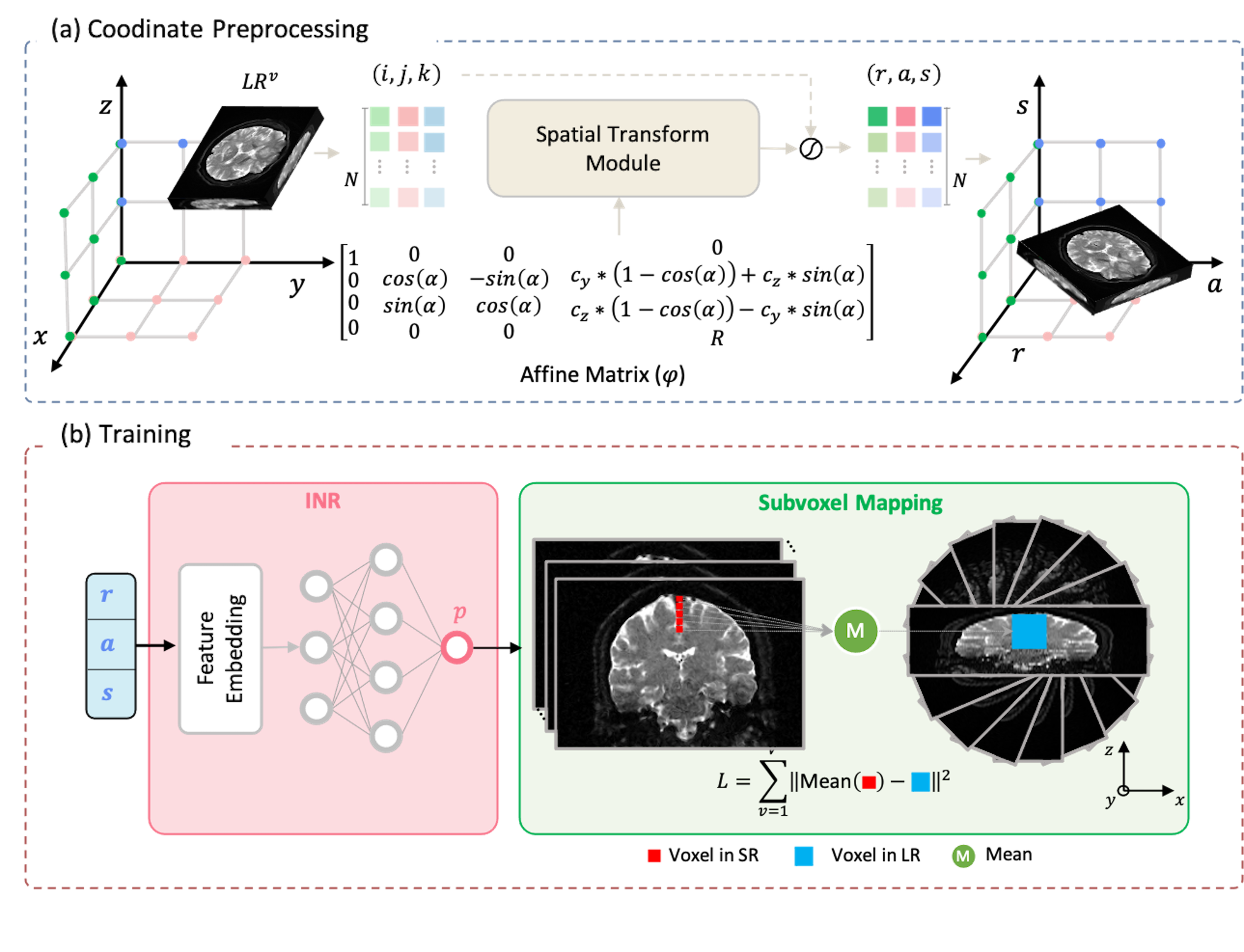
Figure 2 presents a comprehensive framework overview. (a) Coordinate Preprocessing: The input comprises matrix coordinates of LR images from each view. Following multiplication by an affine matrix, the output represents specific values in the RAS coordinate system. (b) Fitting procedure: Given a coordinate [r, a, s], the feature embedding layer encodes it into feature maps. Subsequently, the INR decodes it into pixel intensity. The subpixel mapping block averages the output of INR in the z-direction, facilitating the computation of the mean square error (MSE) loss with the corresponding LR image.
- Implementation
Results
- Experiment 1: SRR Results
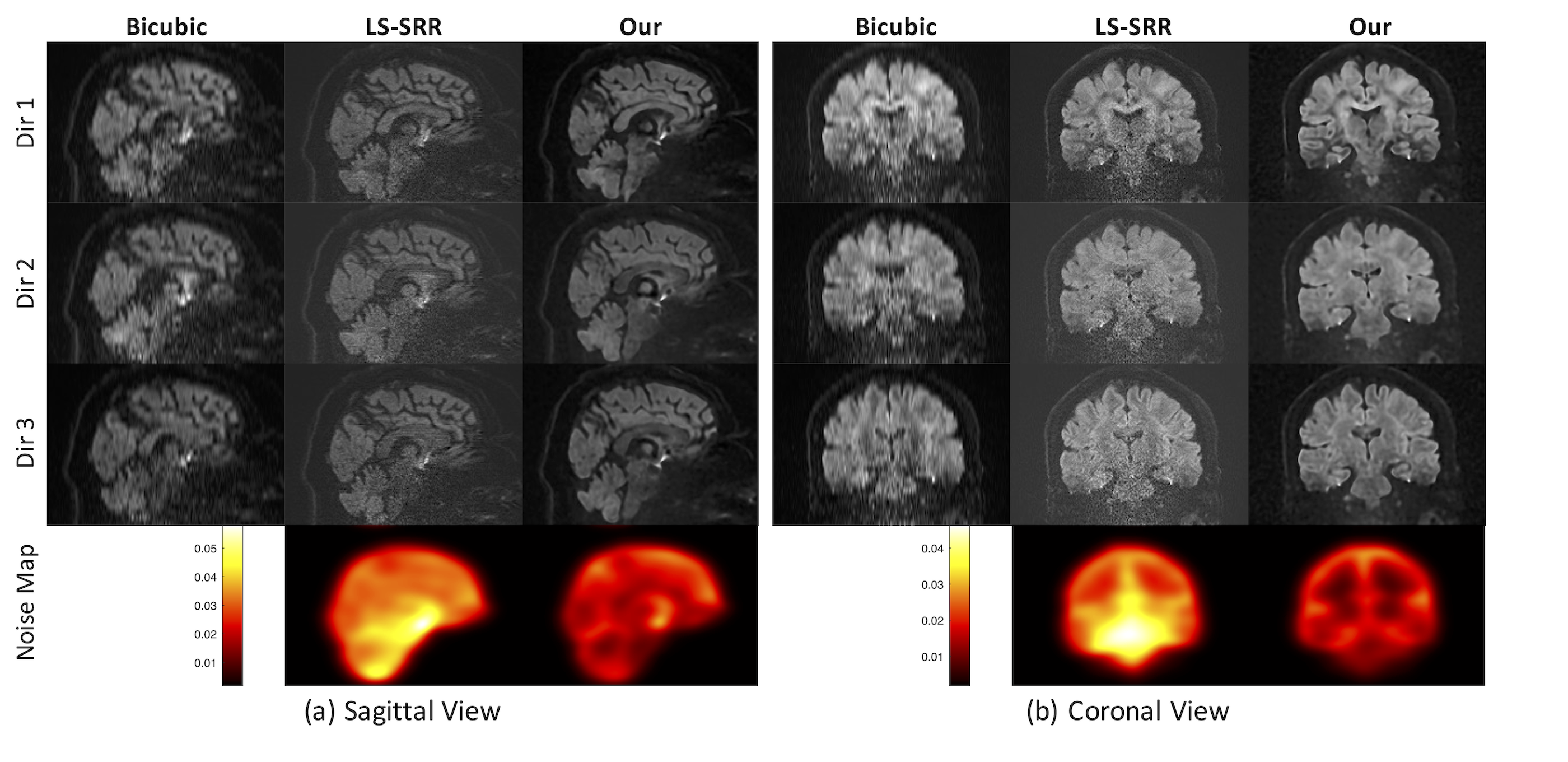
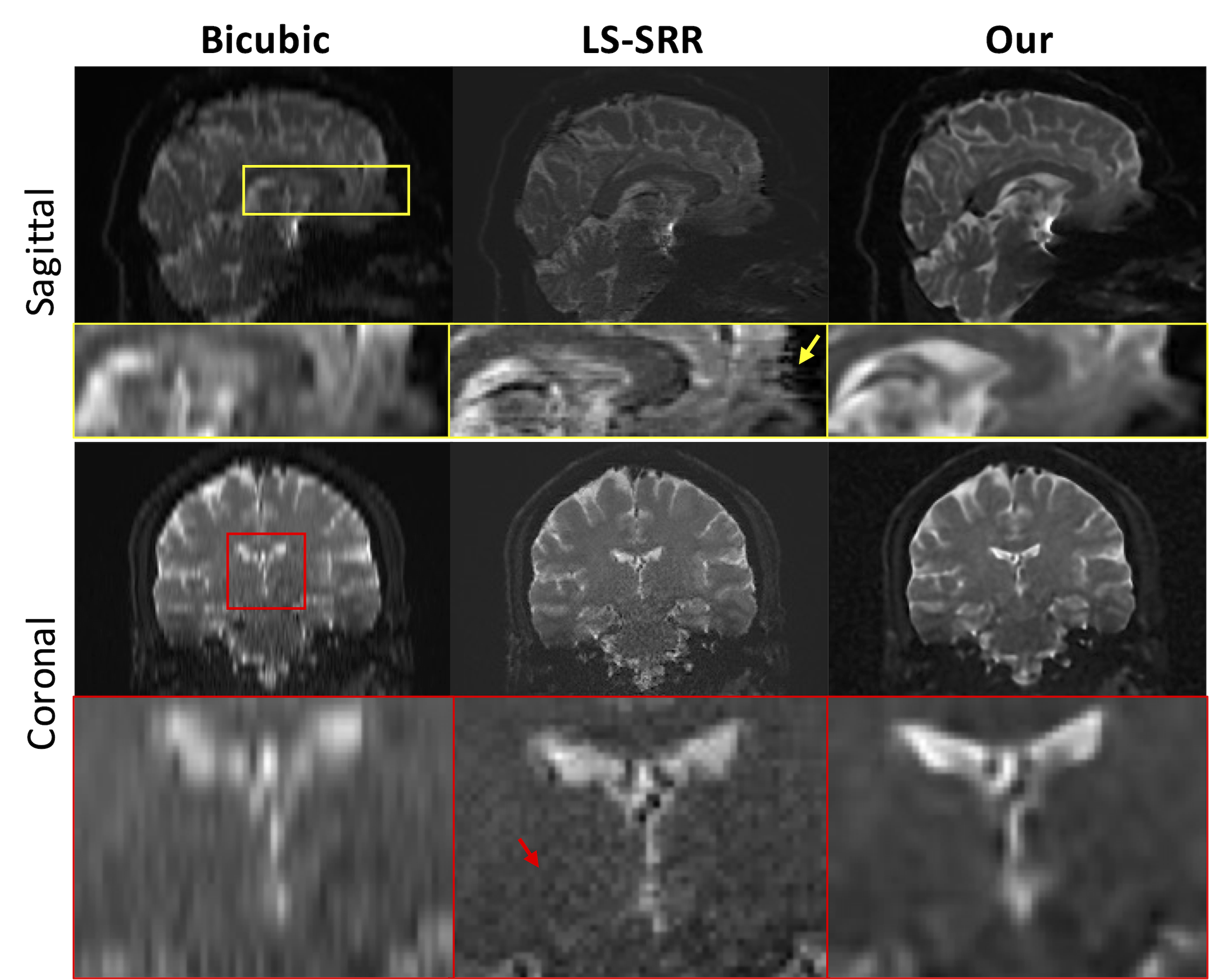
Figure 4 displays the qualitative results of our approach in comparison to two baseline methods, Bicubic and LS-SSR, for b=0 images. As can be seen, our method notably reduces motion artifacts when compared to the LS-SRR algorithm and shows better SNR.
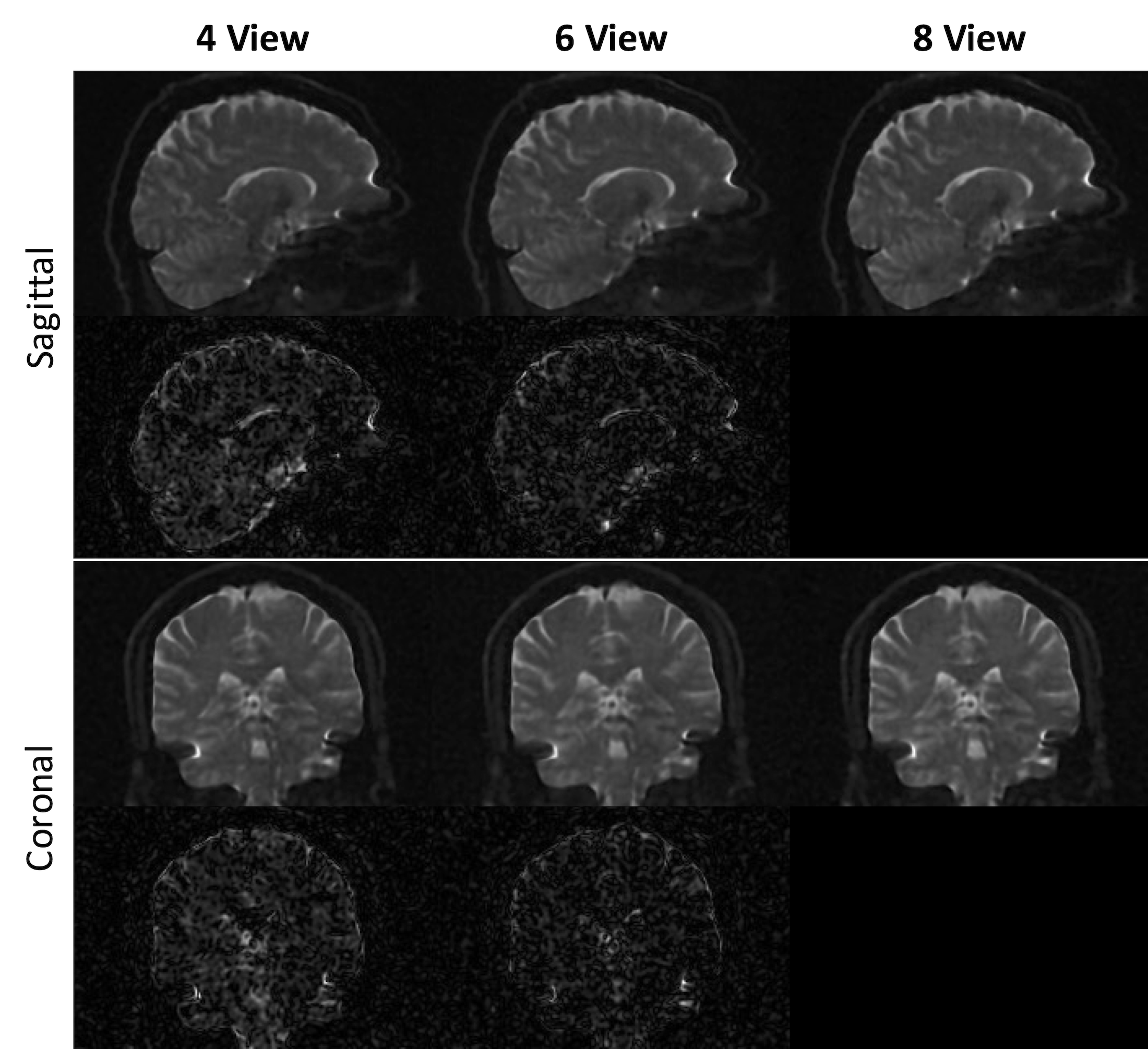
- Experiment 2: SRR Results with undersampled data
Conclusion
In summary, we used implicit neural representations to enable SRR without the need for training datasets. Compared to the existing SRR algorithms, our approach can reconstruct high-quality images and exhibits stronger motion robustness and noise reduction capabilities (30%), while further reducing scan time.Acknowledgements
No acknowledgement found.References
- Setsompop, Kawin, et al. "Generalized SLIce Dithered Enhanced Resolution Simultaneous MultiSlice (gSlider-SMS) to increase volume encoding, SNR and partition profile fidelity in high-resolution diffusion imaging." Proceedings of the 24th Annual Meeting of ISMRM, Singapore. 2016.
- Vis, Geraline, Markus Nilsson, Carl-Fredrik Westin, and Filip Szczepankiewicz. "Accuracy and precision in super-resolution MRI: Enabling spherical tensor diffusion encoding at ultra-high b-values and high resolution." NeuroImage 245 (2021): 118673.
- Zijing Dong, J Polimeni, L. Wald, and F Wang, “SuperRes-EPTI: in-vivo mesoscale distortion-free dMRI at 500μm-isotropic resolution using short-TE EPTI with rotating-view super resolution”, ISMRM 2023
- Ning, Lipeng, et al. "A joint compressed-sensing and super-resolution approach for very high-resolution diffusion imaging." NeuroImage 125 (2016): 386-400.
- Sitzmann, Vincent, et al. "Implicit neural representations with periodic activation functions." Advances in neural information processing systems 33 (2020): 7462-7473.
- Aja-Fernández S, Pieciak T, Vegas-Sánchez-Ferrero G. Spatially variant noise estimation in MRI: a homomorphic approach. Med Image Anal. 2015 Feb;20(1):184-97. doi: 10.1016/j.media.2014.11.005. Epub 2014 Nov 24. PMID: 25499191.
Figures