1072
DeepGrasp-Quant: A General Framework for Deep Learning-Enabled Quantitative Imaging Based on Golden-Angle Radial Sparse Parallel MRI1Bernard and Irene Schwartz Center for Biomedical Imaging, Department of Radiology, New York University Grossman School of Medicine, New York City, NY, United States, 2Center for Advanced Imaging Innovation and Research (CAI2R), Department of Radiology, New York University Grossman School of Medicine, New York City, NY, United States, 3Department of Electrical and Computer Engineering, NYU Tandon School of Engineering, New York City, NY, United States, 4Biomedical Engineering and Imaging Institute, Icahn School of Medicine at Mount Sinai, New York City, NY, United States, 5Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Quantitative Imaging, Quantitative Imaging, Deep Learning
Motivation: Quantitative MRI typically involves a multi-step imaging pipeline from data acquisition to parameter estimation. Deep learning holds great promise to improve and streamline the entire workflow for quantitative MRI.
Goal(s): This work presents a general deep learning-based rapid quantitative MRI framework, called DeepGrasp-Quant, for efficient and accurate quantification of MRI parameters based on Golden-angle RAdial Sparse Parallel (GRASP) MRI.
Approach: DeepGrasp-Quant was designed with cascaded deep learning modules for reconstruction and parameter fitting, enabling direct estimation of MR parameters from undersampled images.
Results: Two examples of DeepGrasp-Quant (DeepGrasp-T1 and DeepGrasp-T1-Dixon) were demonstrated for rapid accurate T1 mapping of the brain and the liver.
Impact: DeepGrasp-Quant is expected to be a promising technique for efficient and accurate quantification of MRI parameters from highly-accelerated free-breathing data acquisition. In addition to T1 mapping, it can also be integrated with other quantitative MRI methods for different clinical applications.
Introduction
Golden-angle RAdial Sparse Parallel(GRASP) MRI is a rapid motion-robust imaging technique that combines golden-angle radial sampling with multi-coil compressed sensing reconstruction1, 2. Recently, GRASP has been extended to Magnetization-Prepared GRASP3(MP-GRASP), a framework enabling rapid motion-robust quantitative MRI. Specific applications of MP-GRASP have been demonstrated for quantification of T1(GraspT1)3, quantification of fat fraction and fat/water-separated T1(GraspT1-Dixon) 3, quantification of chemical exchange saturation transfer(GraspCEST)4 and others5. However, MP-GRASP involves a complex imaging pipeline, like many other quantitative MRI methods, resulting in slow image reconstruction and pixel-wise parameter estimation in different steps. Meanwhile, the use of standard iterative reconstruction algorithms limits archivable acceleration rates. In this study, we propose DeepGrasp-Quant, a general framework for highly-accelerated, efficient, and accurate quantitative imaging using deep learning based on GRASP MRI. We demonstrate two specific examples of DeepGrasp-Quant for T1 mapping of the brain(DeepGraspT1) and fat/water-separated T1 mapping of the liver(DeepGraspT1-Dixon).Methods
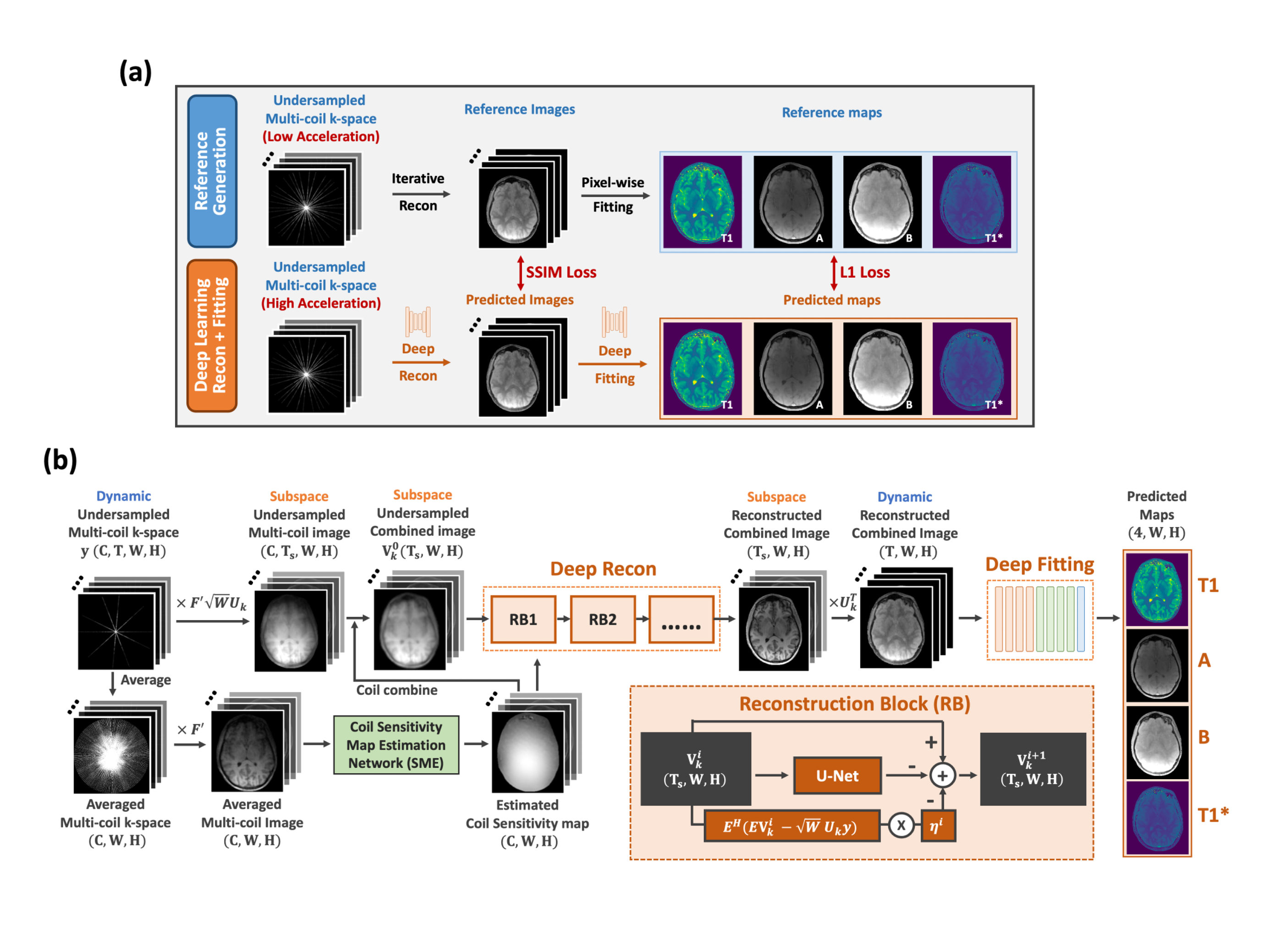
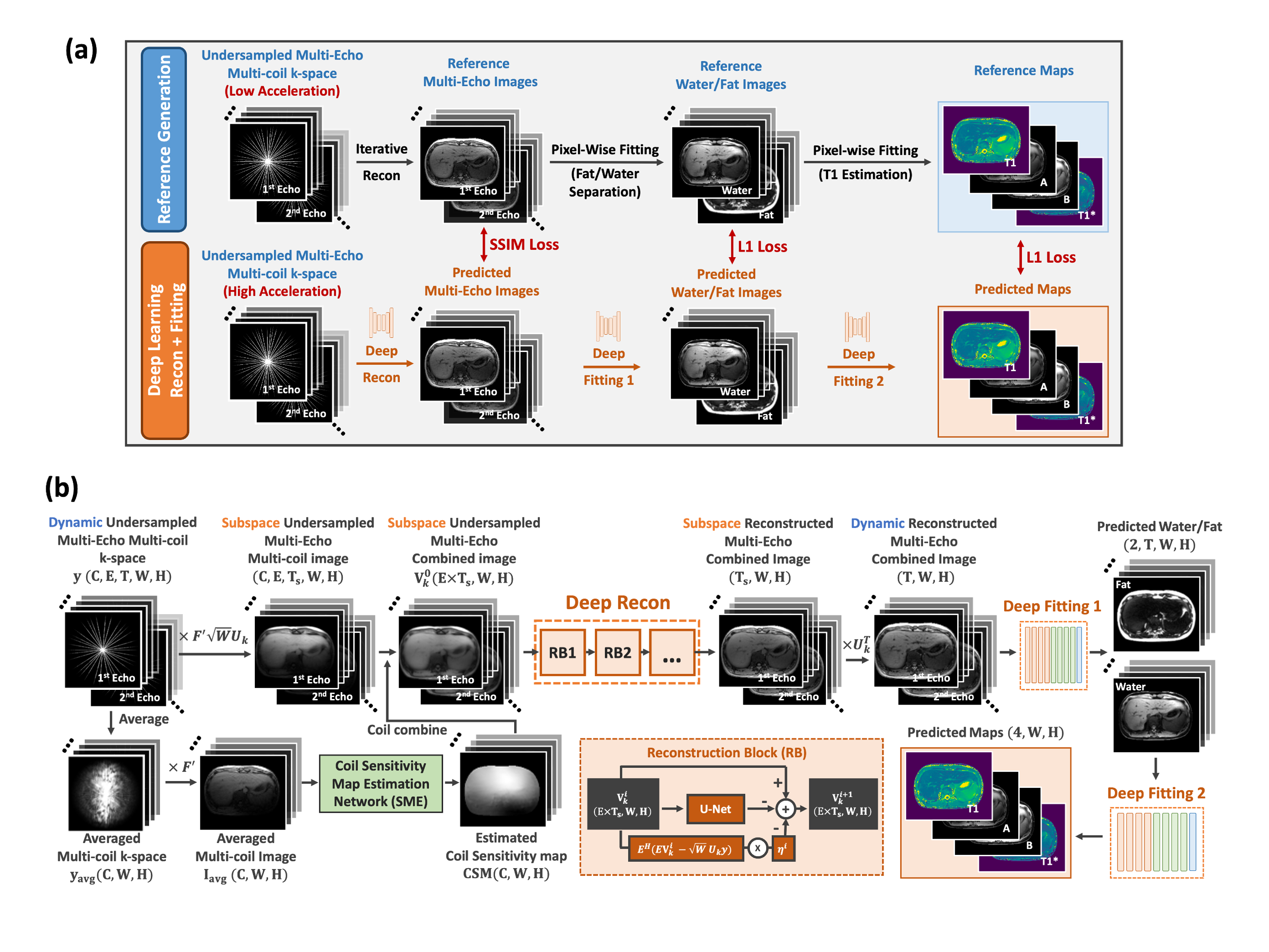
DeepGrasp-Quant consists of two cascaded modules for reconstruction(DeepRecon) and parameter estimation(DeepFitting), which are jointly trained using the reference images or parameter maps generated from low-acceleration data using conventional reconstruction and fitting approaches. DeepGrasp-Quant has two loss functions, one enforcing a structural similarity index measure(SSIM) loss between reference and reconstructed images on the DeepRecon module, and the other enforcing L1 loss between the reference and estimated parameter maps. During inference, DeepGrasp-Quant can efficiently estimate parameter maps from undersampled images by sequentially processing each cascaded module. A specific example of DeepGrasp-Quant for T1 mapping (referred to as DeepGraspT1), is shown in Figure.1. When multiple fitting steps are required, the DeepFitting module can be extended, as shown in Figure.2 for a specific example of fat/water-separated T1 mapping of the liver (referred to as DeepGraspT1-Dixon). After image reconstruction, DeepGraspT1-Dixon includes two fitting steps for fat/water separation and parameter estimation, respectively.The DeepRecon module employs an unrolled network consisting of multiple blocks to model iterative gradient descent updates by estimating the gradient of the regularization function using convolutional neural networks as shown in Figure 1(b) and Figure 2(b). It also integrates a low-rank subspace model, where a temporal basis is estimated from the simulated T1 dictionary for the T1 quantification3. Another network in the DeepRecon module is also used to estimate coil sensitivity maps employed in the reconstruction process from averaged multi-coil k-space data6. The DeepFitting module uses a modified U-net7 that employs spatiotemporal convolutional filters and removes downsampling/upsampling layers to enable accurate pixel-wise parameter generation.
52 (34/8/10 for training/validation/testing) brain GraspT1 datasets with 17/8/5 inversion recovery (IR) repetitions (30 slices/sample) and 60 (45/5/10 for training/validation/testing) liver GraspT1-Dixon datasets with 26/17 IR Repetitions (14 slices/sample) were used for evaluating the DeepGraspT1 and DeepGraspT1-Dixon framework, respectively. Note that the high-acceleration data (e.g. 8 IR Repetitions) were generated from low-acceleration data (e.g. 17 IR Repetitions) by directly removing selected IR Repetitions.
The reconstructed images, separated water/fat images, and T1 maps generated from DeepGraspT1/ DeepGraspT1-Dixon were compared with those from GraspT1/GraspT1-Dixon using different IR repetitions. The error of T1 estimation was assessed in different T1 ranges as follows: $$Error\left(\%\right)=\frac{\left|Pred-Ref\right|}{Ref}\times100\%$$
Results
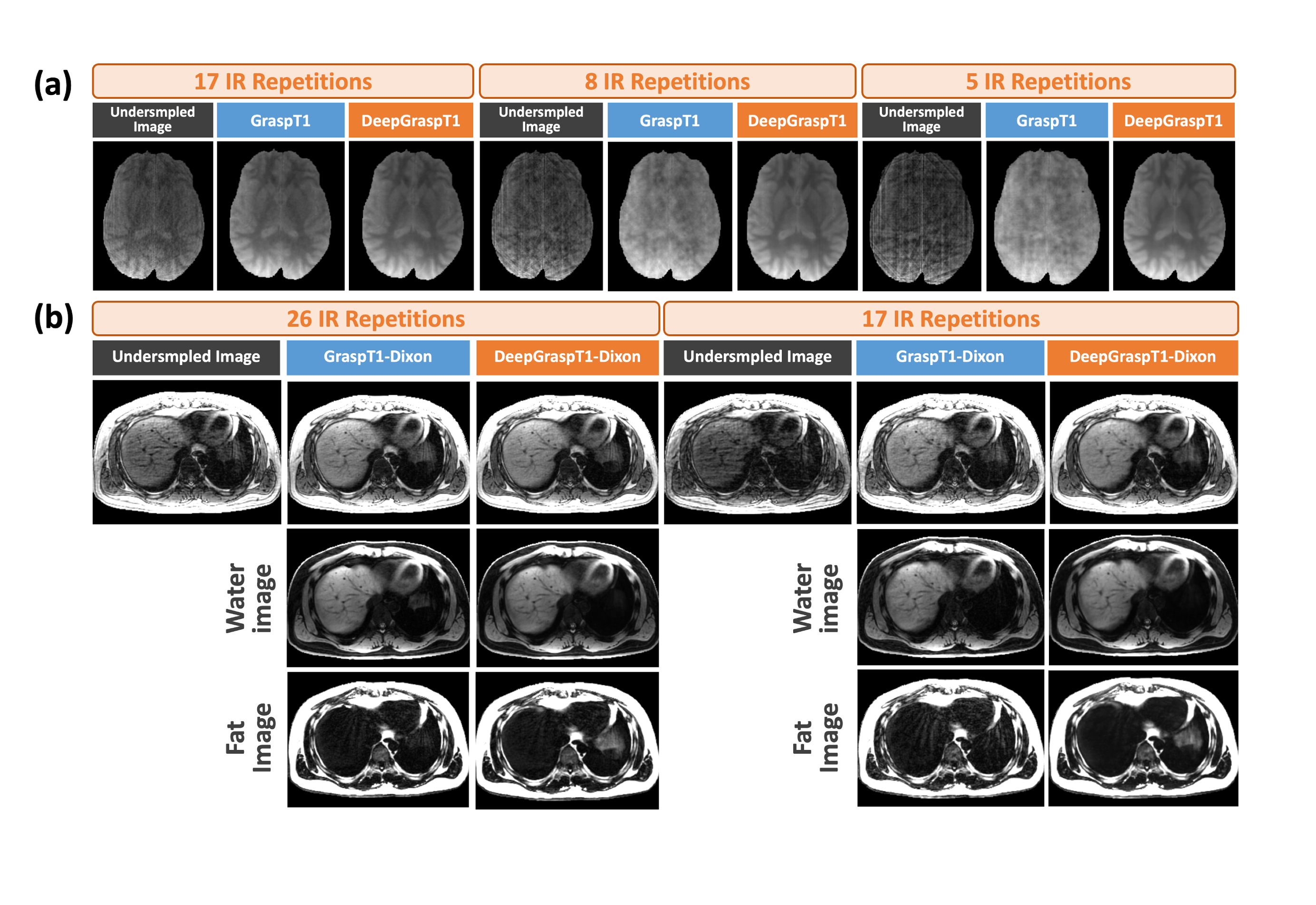
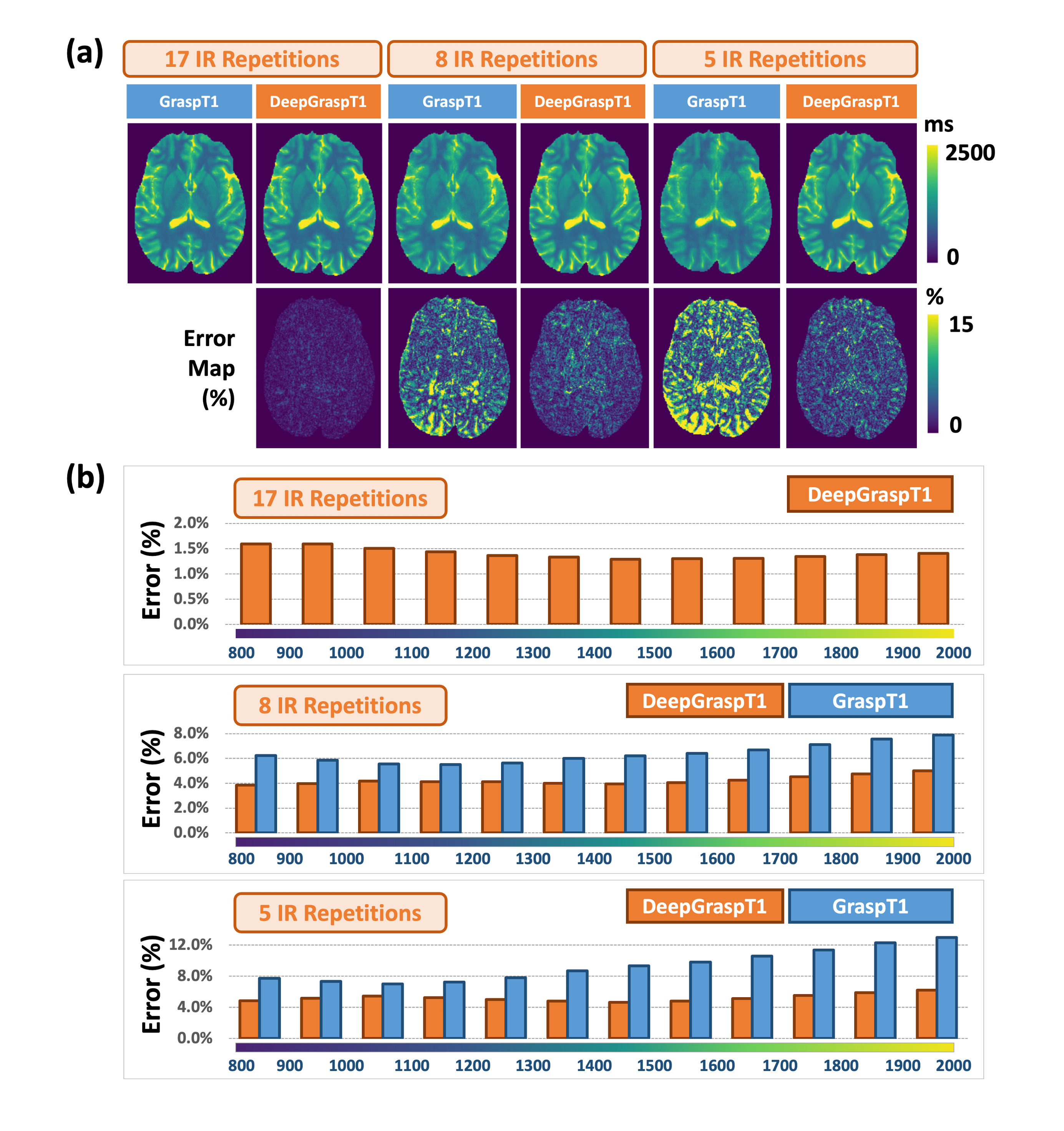
Figure.3(a) shows a representative case comparing one frame of the reconstructed images estimated using DeepGraspT1 and GraspT1 from a GraspT1 dataset with IR repetitions progressively reduced (e.g., from 17 to 8 to 5 IR repetitions). Figure.3(b) shows a representative case comparing one frame of the reconstructed images as well as the separated water and fat images estimated using DeepGraspT1-Dixon and GraspT1-Dixon from GraspT1-Dixon dataset with 26/17 IR repetitions. The results demonstrate that even with fewer IR repetitions, the DeepGrasp-Quant framework consistently achieves higher-quality reconstructed images and parameter maps than the conventional framework.Figure.4(a) shows a representative case comparing the T1 maps estimated using DeepGraspT1 and GraspT1 with different numbers of IR repetitions. Figure.4(b) summarizes the quantitative comparison of GraspT1 with DeepGraspT1 in all 10 testing datasets with different numbers of IR repetitions based on averaged pixel-wise errors in various T1 ranges. Both the error map and the quantitative comparison illustrate that DeepGraspT1 enables more accurate T1 map estimation than GraspT1 when IR repetitions are reduced.
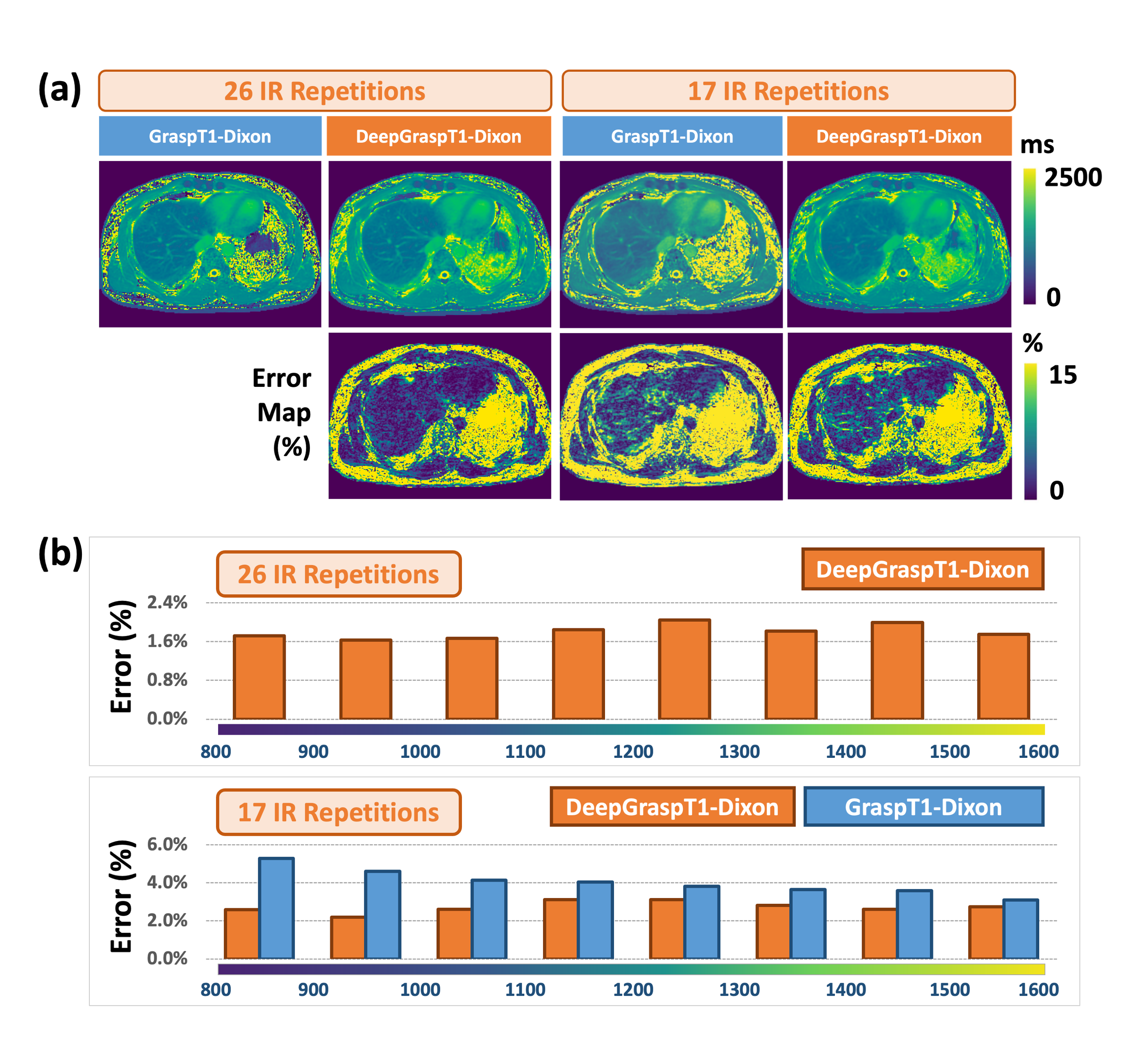
Figure.5(a) compares T1 maps from DeepGraspT1-Dixon and GraspT1-Dixon with varying numbers of IR repetitions. Figure.5(b) summarizes the quantitative comparison of DeepGraspT1-Dixon and GraspT1-Dixon across 10 testing datasets in various T1 ranges, revealing improved T1 map accuracy for DeepGraspT1-Dixon as IR repetitions decrease.
Conclusion
This work introduces DeepGrasp-Quant, a general framework for deep learning-enabled quantitative imaging based on GRASP MRI. Compared to a conventional framework that requires slow image reconstruction and pixel-wise parameter estimation in two separate steps, DeepGrasp-Quant enables faster inference while maintaining quantification accuracy even with highly-accelerated data.Acknowledgements
This work was supported by the NIH (R01EB030549, R21EB032917, and P41EB017183) and was performed under the rubric of the Center for Advanced Imaging Innovation and Research (CAI2R), an NIBIB National Center for Biomedical Imaging and Bioengineering.References
1. Feng L, Grimm R, Block KT obia., et al.: Golden-angle radial sparse parallel MRI: combination of compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI. Magn Reson Med 2014; 72:707–717.2. Feng L, Wen Q, Huang C, Tong A, Liu F, Chandarana H: GRASP-Pro: imProving GRASP DCE-MRI through self-calibrating subspace-modeling and contrast phase automation. Magn Reson Med 2020; 83:94–108.
3. Feng L, Liu F, Soultanidis G, et al.: Magnetization-prepared GRASP MRI for rapid 3D T1 mapping and fat/water-separated T1 mapping. Magn Reson Med 2021; 86:97–114.
4. Xu, Xiang, et al. "GraspCEST: Fast Free-Breathing 3D Steady-State CEST MRI Using Golden-Angle Radial Sparse MRI."
5. Feng, Li, and Lirong Yan. "GraspMRA: High Temporal Resolution, Non-Contrast Enhanced, Time-Resolved 4D MR Angiography Using Golden-angle Radial Sparse Parallel Imaging."
6. Sriram, Anuroop, et al. "End-to-end variational networks for accelerated MRI reconstruction." Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part II 23. Springer International Publishing, 2020.
7. Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing, 2015.
Figures