1068
Efficient Constrained Reconstruction of Non-Cartesian Time-Segmented Data with Implicit GROG and Polynomial Preconditioning1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States
Synopsis
Keywords: Image Reconstruction, MR Fingerprinting
Motivation: Fast, regularized subspace reconstruction would enable the acquisition and synthesis of a standard clinical brain protocol in mere minutes.
Goal(s): Our goal is to make high-resolution, image reconstruction faster and more robust to $$$B_0$$$ inhomogeneities.
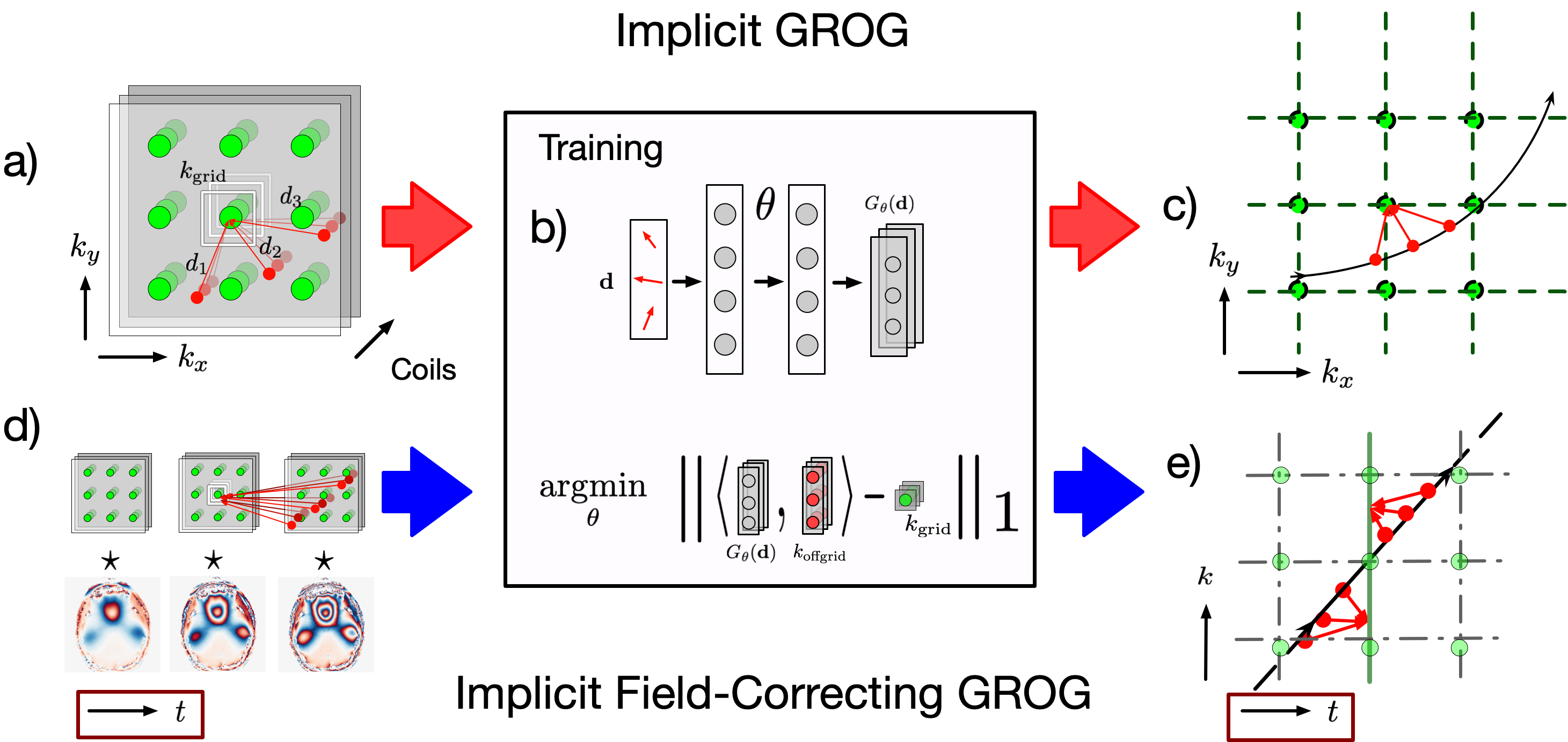
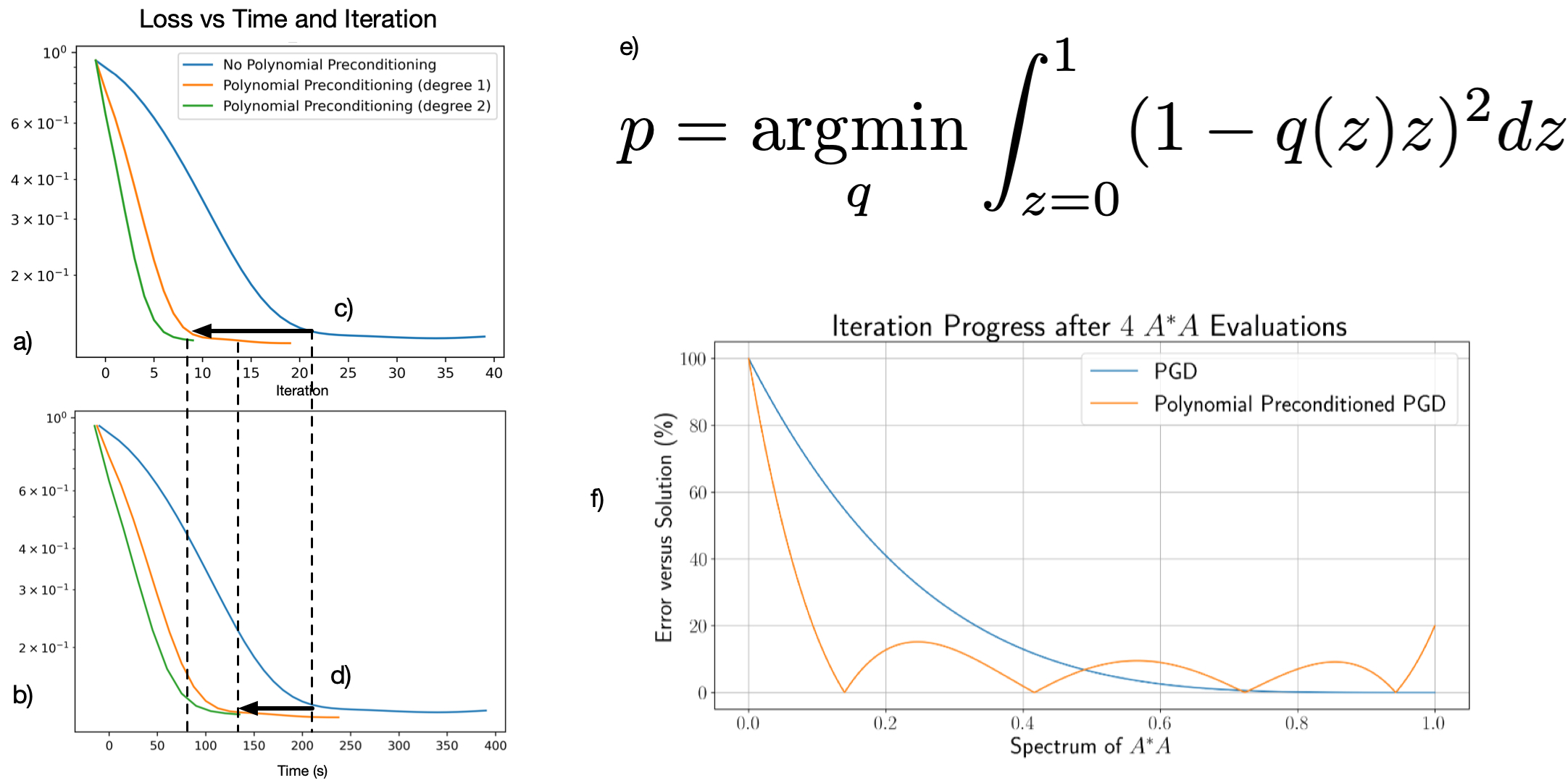
Approach: Our reconstruction alternates between data consistency (DC) and spatio-temporal low rank regularization. We leverage coil sensitivities to "snap" non-Cartesian trajectories to the kspace grid, speeding up DC steps and enabling $$$B_0$$$-robust reconstructions with fewer time segments. Polynomial preconditioning enables convergence in up to 2x fewer iterations, reducing expensive proximal updates.
Results: Our method reduces the reconstruction time by an order of magnitude while retaining quality.
Impact: The ability to reconstruct MRF quickly should make integration of MRF into clinical workflows not just possible, but convenient. Additionally, the efficiency gains from this framework can make even the most sophisticated and expensive regularizers computationally feasible.
Introduction
Rapid, high-fidelity, and high-resolution reconstruction of efficiently-encoded MRI data is a longstanding challenge. While variable-flip-angles and non-Cartesian trajectories can increase the efficiency of a single scan, they often entail slow, memory-intensive, time-segmented non-uniform FFTs (NUFFTs) during the data consistency step, and expensive spatio-temporal proximal operations, such as Locally-Low-Rank [1]. Furthermore, accounting for field imperfections via time-segmentation further compounds the problem by making the forward model even larger. To address these issues, our contributions are (1) fast data consistency steps via a gridded forward model that accounts for $$$B_0$$$ inhomogeneity, (2) a polynomial preconditioner that allows the reconstruction to take place over many fewer overall iterations, thereby reducing the number of proximal operations required. We demonstrate the power of our approach by reconstructing a 48-channel 1mm-iso whole-brain MRF scan at 3T [2] with $$$B_0$$$ correction in under 3 minutes on a standard consumer GPU.Methods
FISTA Reconstruction: We consider the $$$B_0$$$-corrected subspace reconstruction problem $$\hat\alpha=\underset{\alpha}{\arg\min}\,\|F_{\Omega}SB\Phi\alpha-b\|_{2}^{2}+\lambda{}R(\alpha)$$where $$$b$$$ is the acquired kspace data, $$$\Phi$$$ is the temporal subspace, $$$B$$$ is the time-segmented, spatially-varying $$$B_0$$$ phase map, $$$S$$$ is the coil sensitivity matrix, $$$F_\Omega$$$ is the NUFFT operator, $$$\lambda{}R$$$ is our regularizer, and $$$\alpha$$$ is the desired subspace image. The Fast Iterative Shrinkage-Thresholding Algorithm (FISTA)[3] updates are:$$\begin{align*}\alpha^{(i+)} &\leftarrow \text{prox}_{\lambda R}\left(\alpha^{(i)} - \mu(A^{*}A\alpha^{(i)}- A^{*}b)\right)\tag{1}\\\alpha^{(i+1)} &\leftarrow \alpha^{(i+)} + \beta_i\left[\alpha^{(i+)} - \alpha^{(i)}\right]\end{align*}$$where $$$\mu$$$ is the step size, $$$\beta_i$$$ is a momentum term, and $$$\text{prox}_{\lambda{}R}=\text{LLR}_{\lambda}$$$ is the soft-thresholding operator applied to the singular values of $$$\alpha$$$.Implicit Field-Correcting GROG: We adopt the implicit GROG framework . From a fully-sampled calibration region, GROG learns a kernel that linearly predicts on-grid kspace points from single off-grid acquired kspace points. Application of the kernel to the rest of the data produces data entirely on the Fourier grid points, and eliminates NUFFT by replacing the Kaiser-Bessel (KB) interpolation with simple indexing and eliminating the need to interpolate the data to an oversampled grid. Implicit GROG Improves upon this by generalizing the kernel to predict gridded kspace from multiple off-grid sources, and modeling it with an implicit neural representation. [4,5,6]
Polynomial Preconditioning: By equalizing the eigenvalue spectrum of $$$A^{*}A$$$, preconditioning reduces the number of iterations required for convergence. [7] proposes a polynomial preconditioner $$$p(A^{*}A)$$$ that can be applied with function-only access to $$$A^{*}A$$$. Applying this to (1), the updates become$$\begin{align*}\alpha^{(i+)} &\leftarrow \text{prox}_{\lambda R}\left(\alpha^{(i)} - \mu\,p(A^{*}A)(A^{*}A\alpha^{(i)}- A^{*}b)\right)\quad\tag{2}\\\alpha^{(i+1)} &\leftarrow \alpha^{(i+)} + \beta_i\left[\alpha^{(i+)} - \alpha^{(i)}\right].\end{align*}$$Whereas an ordinary FISTA data-consistency (DC) step requires a single $$$A^{*}A$$$ evaluation per iteration, polynomially-preconditioned FISTA of degree $$$D$$$ requires $$$(D+1)$$$ $$$A^{*}A$$$ evaluations per DC step. Preconditioning therefore enables a tradeoff between the number of $$$A^{*}A$$$ evaluations and the total number of steps (and therefore proximal operations) required. If $$$A^{*}A$$$ is significantly faster than the proximal operator (as is the case with GROG), increasing the degree of the polynomial preconditioner trades expensive proximal operations for lightweight FFTs and elementwise multiplications, shortening the overall convergence time. (Figure 2)
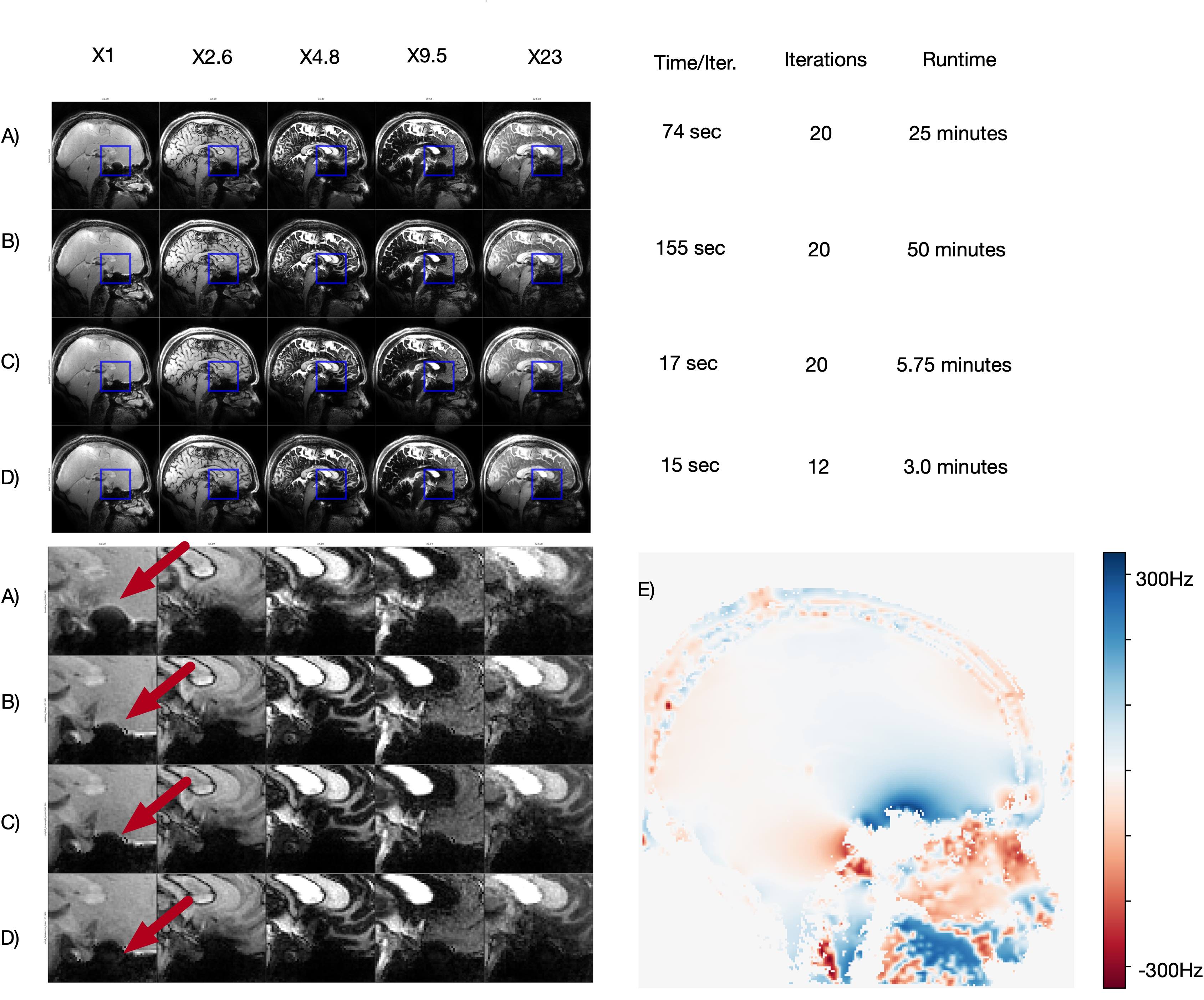
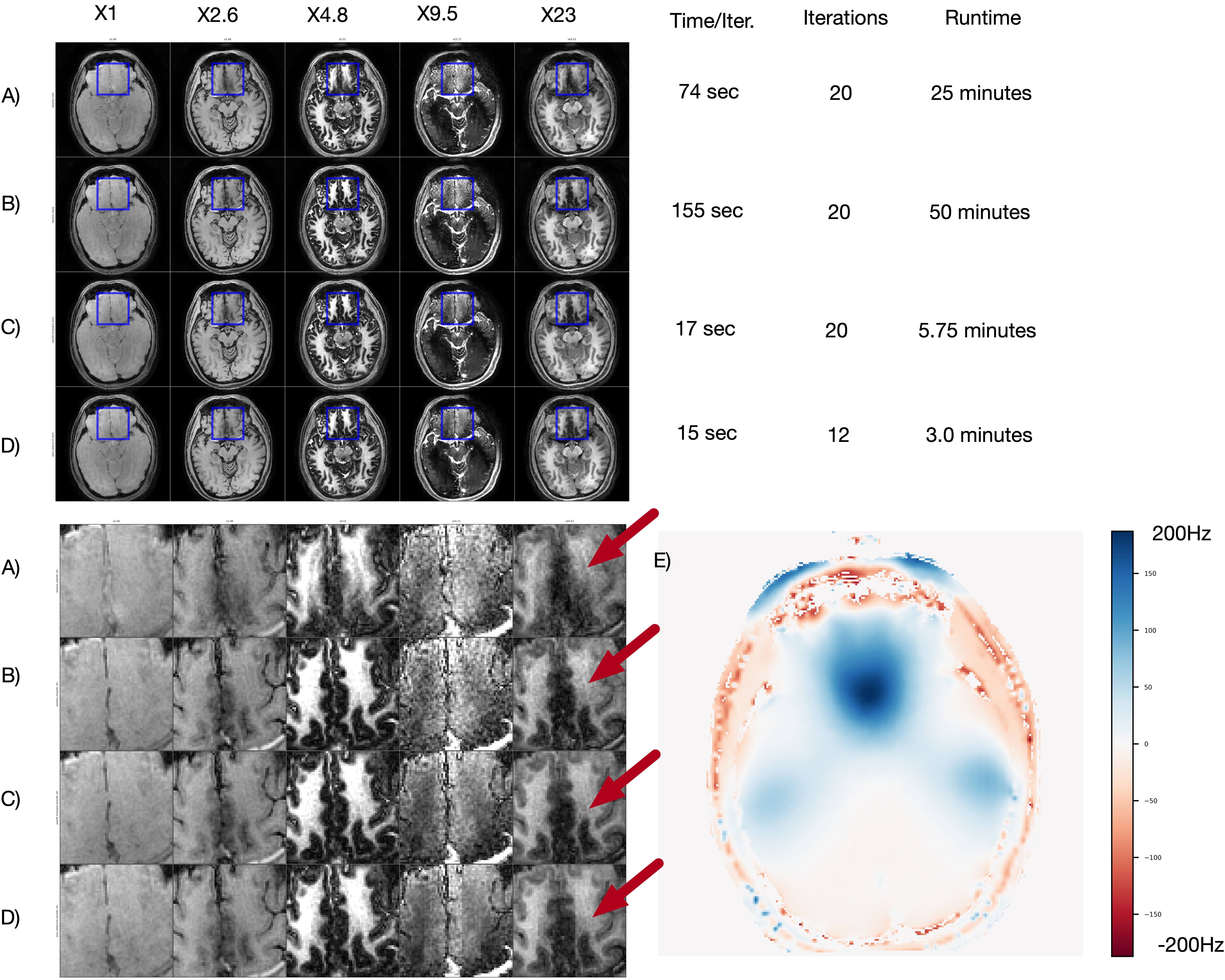
In-Vivo Study We acquired MRF data in 6 minutes at 3T (Premier, GE Healthcare) from healthy volunteers using the TGAS-SPI-MRF sequence (6ms readouts, 500 TRs, 48 groups). We acquired maps using the PhysiCal framework [9]. We used a 48-channel head coil, compressed down to 6 virtual coils.We used an Intel Core i7-12700k with 64Gb of RAM and an NVIDIA RTX 3090 for all experiments. We implemented our implicit GROG operator and Locally-Low-Rank operator in PyTorch [8]. Our baseline was an existing implementation in SigPy of GROG and a Locally-Low- Rank operator. While our implementation requires roughly 50-100% more memory per iteration than the SigPy, it is takes 90% less time even without polynomial preconditioning, and 94% less time with polynomial preconditioning of degree 1.
Results
We significantly reduce the convergence time FISTA with LLR regularization using implicit field-correcting GROG and polynomial preconditioning. Our method dramatically reduces the reconstruction time while preserving quality and represents a significant step towards practical real-time MRF.Conclusion
We significantly reduce the convergence time FISTA with LLR regularization using implicit field-correcting GROG and polynomial preconditioning. Our method dramatically reduces the reconstruction time while preserving quality and represents a significant step towards practical real-time MRF.Acknowledgements
This work was supported by the National Institutes of Health under grants R01MH116173, R01EB019437, U01EB025162, P41EB030006, R01EB033206, U24NS129893, R01EB009690, and U01EB029427.References
1. Tamir JI, Uecker M, Chen W, Lai P, Alley MT, Vasanawala SS, Lustig M. T2 shuffling: Sharp, multicontrast, volumetric fast spin-echo imaging. Magn Reson Med. 2017 Jan;77(1):180-195. doi: 10.1002/mrm.26102. Epub 2016 Jan 20. PMID: 26786745; PMCID: PMC4990508.
2. Cao, X, Liao, C, Iyer, SS, et al. Optimized multi-axis spiral projection MR fingerprinting with subspace reconstruction for rapid whole-brain high-isotropic-resolution quantitative imaging. Magn Reson Med. 2022; 88: 133-150. doi:10.1002/mrm.29194
3. A. Beck and M. Teboulle, "A fast Iterative Shrinkage-Thresholding Algorithm with application to wavelet-based image deblurring," 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 2009, pp. 693-696, doi: 10.1109/ICASSP.2009.4959678.
4. Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2021. NeRF: representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 1 (January 2022), 99–106. https://doi.org/10.1145/3503250
5. Shen L, Pauly J, Xing L. NeRP: Implicit Neural Representation Learning With Prior Embedding for Sparsely Sampled Image Reconstruction. IEEE Trans Neural Netw Learn Syst. 2022 Jun 3;PP. doi: 10.1109/TNNLS.2022.3177134. Epub ahead of print. PMID: 35657845.
6. Sitzmann, V., Martel, J., Bergman, A., Lindell, D., & Wetzstein, G. (2020). Implicit neural representations with periodic activation functions. Advances in neural information processing systems, 33, 7462-7473.
7. Iyer, S. S., Ong, F., Cao, X., Liao, C., Daniel, L., Tamir, J. I., & Setsompop, K. (2022). Polynomial Preconditioners for Regularized Linear Inverse Problems. arXiv preprint arXiv:2204.10252.
8. Paszke, A. et al., 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In _Advances in Neural Information Processing Systems 32_. Curran Associates, Inc., pp. 8024–8035.
9. PhysiCal: A rapid calibration scan for B0, B1+, coil sensitivity and Eddy current mapping. Siddharth Srinivasan Iyer, Congyu Liao, Qing Li, Mary Katherine Manhard, Avery Berman, Berkin Bilgic, and Kawin Setsompop. Proc. ISMRM 2020
Figures