0877
LESEN: Label-Efficient Self-Ensembling Network for Multi-Parametric MRI-based Visual Pathway Identification1Paul C Lauterbur Research Center for Biomedical Imaging, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 2University of Chinese Academy of Science, Beijing, China, 3Zhejiang University of Technology, Hangzhou, China, 4Guangdong Provincial Key Laboratory of Artificial Intelligence in Medical Image Analysis and Application, Guangzhou, China, 5Peng Cheng Laboratory, Shenzhen, China
Synopsis
Keywords: Analysis/Processing, Brain, Semi-supervised learning
Motivation: Obtaining labeled data for visual pathway (VP) segmentation can be laborious and time-consuming. Therefore, it is crucial to develop algorithms with good performance in situations with limited labeled samples.
Goal(s): The goal is to propose a label-efficient self-ensembling network (LESEN) for VP segmentation.
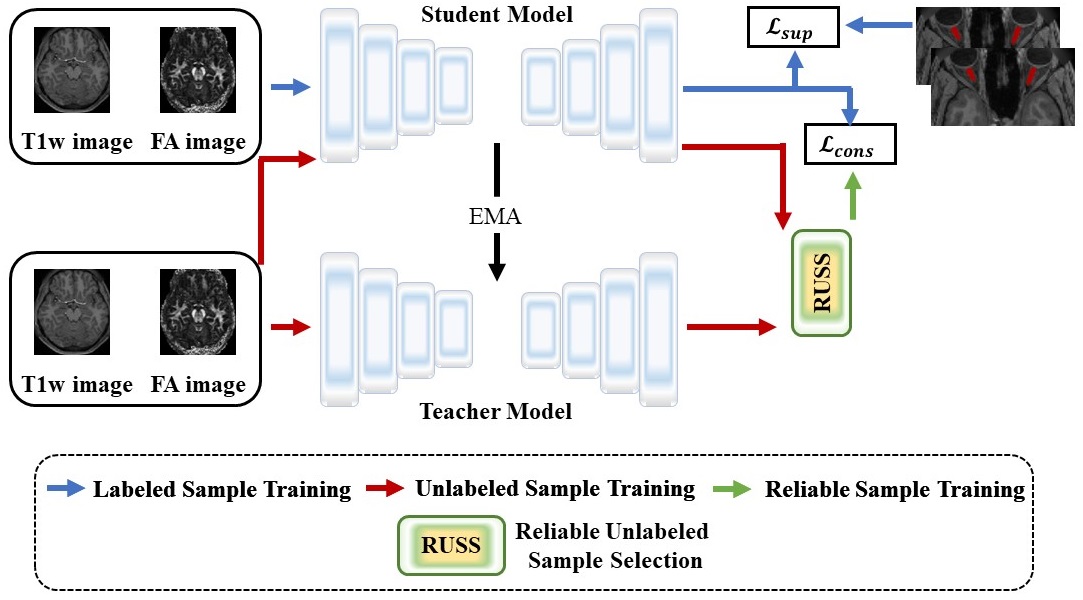
Approach: We first introduce the LESEN model which consists of a student model and a teacher model that learn from each other using supervised and unsupervised losses. Additionally, a novel reliable unlabeled sample selection (RUSS) method is introduced to enhance the effectiveness of the LESEN model.
Results: The LESEN model surpasses existing techniques on the human connectome project (HCP) dataset.
Impact: The proposed LESEN model can improve visual pathway segmentation accuracy and reliability with limited labeled data, advancing multi-parametric MRI analysis in clinical and research settings.
Introduction
Accurate segmentation of visual pathway (VP) is crucial for understanding the complex anatomy and connectivity of the visual system. The retinogeniculate visual pathway, responsible for transmitting visual information from the retina to the brain, is particularly important. In recent years, multi-parametric MRI (such as T1-weighted and fractional anisotropy images) has emerged as a powerful tool for VP visualization, offering great potential for comprehensive analysis in clinical and research settings 1. However, segmenting multi-parametric MRI is a challenging task due to the differences in appearance, resolution, and imaging characteristics across imaging sequences.Deep learning approaches, such as convolutional neural networks (CNNs) and their variants, have shown significant advancements in multi-parametric MRI-based VP segmentation 1-4. However, the process of obtaining labeled data for the segmentation remains a laborious and time-consuming endeavor 5,6. As a result, there is a pressing need to develop algorithms that can achieve good performance with limited labeled samples.
To address this challenge, we propose a label-efficient self-ensembling network (LESEN). The LESEN framework leverages the benefits of labeled and unlabelled data to achieve accurate visual pathway segmentation. Furthermore, we introduce a novel reliable unlabeled sample selection (RUSS) to enhance the effectiveness of LESEN. To evaluate the performance of our proposed LESEN framework, we conducted experiments on the open-source human connectome project (HCP) dataset. The experimental results demonstrate the superior performance of LESEN compared to state-of-the-art techniques in multi-parametric MRI visual pathway segmentation.
Methodology
As illustrated in Figure 1, our proposed LESEN consists of a student model and a teacher model, both based on a U-shaped encoder-decoder architecture with spatial attention. During the training, labeled samples are fed into the student model and used to calculate the supervised loss by comparing its segmentation output with ground truth labels. On the other hand, the unlabeled samples are fed into both the student and teacher models. Then, the unsupervised consistency loss is calculated between the student model’s predictions and the teacher model’s predictions. The student model is updated using the gradients calculated from both losses, while the teacher model’s parameters are updated based on the student model’s parameters. This enables the student and teacher models to learn from each other.However, since there is a high risk of getting inaccurate predictions from the teacher model, directly utilizing all the pseudo labels generated by the teacher model could potentially lead to misleading training of the entire framework. Therefore, RUSS is designed to address this issue and enhance the model's effectiveness. RUSS first applies $$$m$$$ times stochastic augmentation of the unlabeled samples. Then, we calculate the consistency of predictions between the models by measuring the standard deviation of probability vectors. During training, only the samples with the highest consistency values are retained. This ensures consistent predictions between the models, thus further improving the model's performance.
The overall training loss is defined as:
$$ loss = α.l_{sup} + γ.l_{cons} $$,
where $$$l_{sup}$$$, and $$$l_{cons}$$$ denote the supervised loss, and the unsupervised consistency loss, respectively. α and γ are hyperparameters.
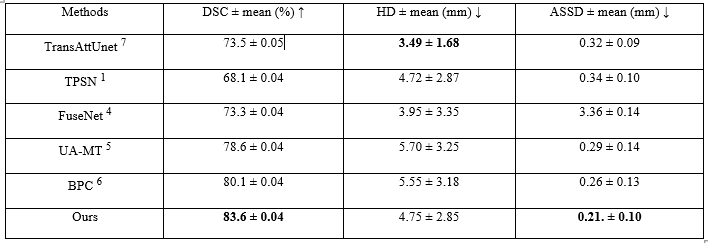
Evaluation metrics, including Dice similarity coefficient (DSC), Average symmetric surface distance (ASSD), and Hausdorff distance (HD), are used to assess the model's performance. Experiments are conducted on the HCP dataset, with a division into training (16 labeled and 66 unlabeled samples), and testing sets (10 samples). The performance is then evaluated on the testing set and compared its performance with state-of-the-art techniques.
Results and Analysis
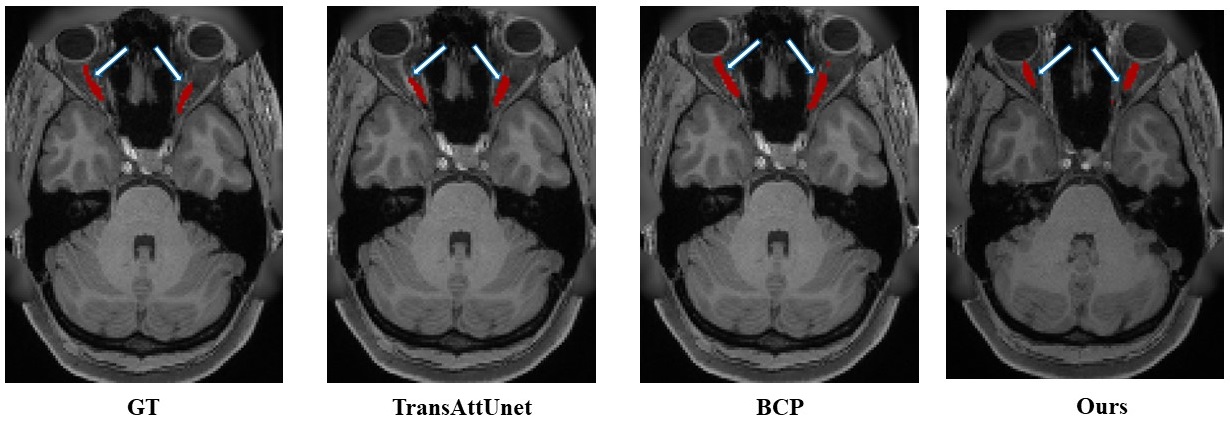
The quantitative and qualitative results shown in Figure 2 and Table 1 demonstrate that LESEN model achieves superior segmentation performance, even with a limited number of annotated samples. By effectively utilizing the available annotations and unlabeled data, our approach reduces the reliance on extensive manual annotations, making the segmentation pipeline more practical and scalable.The significance of these results lies in the potential clinical and research applications. Accurate VP segmentation is crucial for various neuroimaging studies and clinical assessments. The improved performance of the LESEN model suggests its potential for enhancing the accuracy and reliability of VP segmentation in these contexts. Though our results are promising, it is essential to validate the model on diverse datasets to ensure its robustness and applicability in different scenarios.
Conclusion
In conclusion, the proposed LESEN model offers a promising solution for label-efficient multi-parametric MRI-based VP segmentation, with potential applications in neuroimaging studies and clinical assessments. The results demonstrate its superior performance compared to existing techniques, highlighting its potential to enhance the accuracy and reliability of VP segmentation. We may consider investigating the proposed method for possible clinical uses in the future by enhancing its generalization capability.Acknowledgements
This research was partly supported by the National Natural Science Foundation of China (62222118, U22A2040), Guangdong Provincial Key Laboratory of Artificial Intelligence in Medical Image Analysis and Application (2022B1212010011), Shenzhen Science and Technology Program (RCYX20210706092104034, JCYJ20220531100213029), and Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2023B1212060052).References
1. S. Li, Z. Chen, W. Guo, Q. Zeng, and Y. Feng, “Two parallel stages deep learning network for anterior visual pathway segmentation,” in Computational Diffusion MRI: International MICCAI Workshop, Lima, Peru, October 2020. Springer, 2021, pp. 279–290.
2. A. Mansoor, J. J. Cerrolaza, R. Idrees, E. Biggs, M. A. Alsharid, R. A. Avery, and M. G. Linguraru, “Deep learning guided partitioned shape model for anterior visual pathway segmentation,” IEEE Transactions on Medical Imaging, vol. 35, no. 8, pp. 1856–1865, 2016.
3. Z. Zhao, D. Ai, W. Li, J. Fan, H. Song, Y. Wang, and J. Yang, “Spatial probabilistic distribution map based 3d fcn for visual pathway segmentation,” in Image and Graphics: 10th International Conference, ICIG 2019, Beijing, China, August 23–25, 2019, Proceedings, Part II 10. Springer, 2019, pp. 509–518.
4. L. Xie, L. Yang, Q. Zeng, J. He, J. Huang, Y. Feng, E. Amelina, and M. Amelin, “Deep Multimodal Fusion Network for the Retinogeniculate Visual Pathway Segmentation,” in The 42nd Chinese Control Conference (CCC 2023), 2023.
5. L. Yu, S. Wang, X. Li, C.-W. Fu, and P.-A. Heng, “Uncertainty-aware self-ensembling model for semi-supervised 3d left atrium segmentation,” in Medical Image Computing and Computer Assisted Intervention– MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part II 22. Springer, 2019, pp. 605–613.
6. Y. Bai, D. Chen, Q. Li, W. Shen, and Y. Wang, “Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 514–11 524.
7. Bingzhi Chen, Yishu Liu, Zheng Zhang, Guangming Lu, and Adams Wai Kin Kong, “Transattunet: Multi-level attention-guided u-net with transformer for medical image segmentation,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2023
Figures