0814
Compressibility-Based Unsupervised Loss for Physics-Driven MRI Reconstruction Networks1Electrical and Computer Engineering, University of Minnesota, Minneapolis, MN, United States, 2Center for Magnetic Resonance Research, University of Minnesota, Minneapolis, MN, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Image Reconstruction, Accelerated imaging, compressed sensing, unsupervised learning
Motivation: Alternative unsupervised training methods are needed for training physics-driven deep learning reconstruction without fully-sampled data.
Goal(s): We propose a novel loss formulation, inspired by compressibility, to evaluate reconstruction quality in supervised, unsupervised and zero-shot settings.
Approach: We leverage reweighted $$$\ell_1$$$-norm, which corresponds to $$$\ell_0$$$-norm of a sparse signal, to evaluate reconstruction quality. In supervised setting, reference weights are used for reweighting, while in unsupervised case, they are updated after each reweighting.
Results: Our findings demonstrate that the networks trained with this loss outperform conventional compressed sensing, while performing similarly to deep learning methods trained using established supervised and unsupervised techniques.
Impact: This work proposes an alternative compressibility-inspired loss formulation that is applicable to supervised, unsupervised and zero-shot learning problems for the training of physics-driven reconstruction neural networks. This approach utilizes compressibility and convexity for learning.
Introduction
Physics-driven deep learning (PD-DL) reconstruction is a powerful tool for fast MRI1,2. Early methods used supervised learning with fully-sampled k-space as reference labels3,4. To address the challenges of obtaining fully-sampled data in various scenarios, unsupervised learning methods have been proposed5, including self-supervised learning6,7 and generative models8,9. In the former, e.g. SSDU6, parts of acquired k-space are masked out, and the network learns to predict these from remaining k-space. In the latter, a generative model is used to estimate the prior distribution of images, which is then used in conjunction with a log-likelihood data term during test-time. In our work, we propose an alternative approach for unsupervised training of PD-DL networks, drawing inspiration from statistical image processing and compressed sensing (CS)10,11. In particular, while we still rely on the power of non-linear low-dimensional representations afforded by PD-DL networks for signal recovery, we use compressibility to evaluate reconstruction quality. Results show that our approach performs similar to SSDU6 and supervised learning, while outperforming conventional CS.Methods
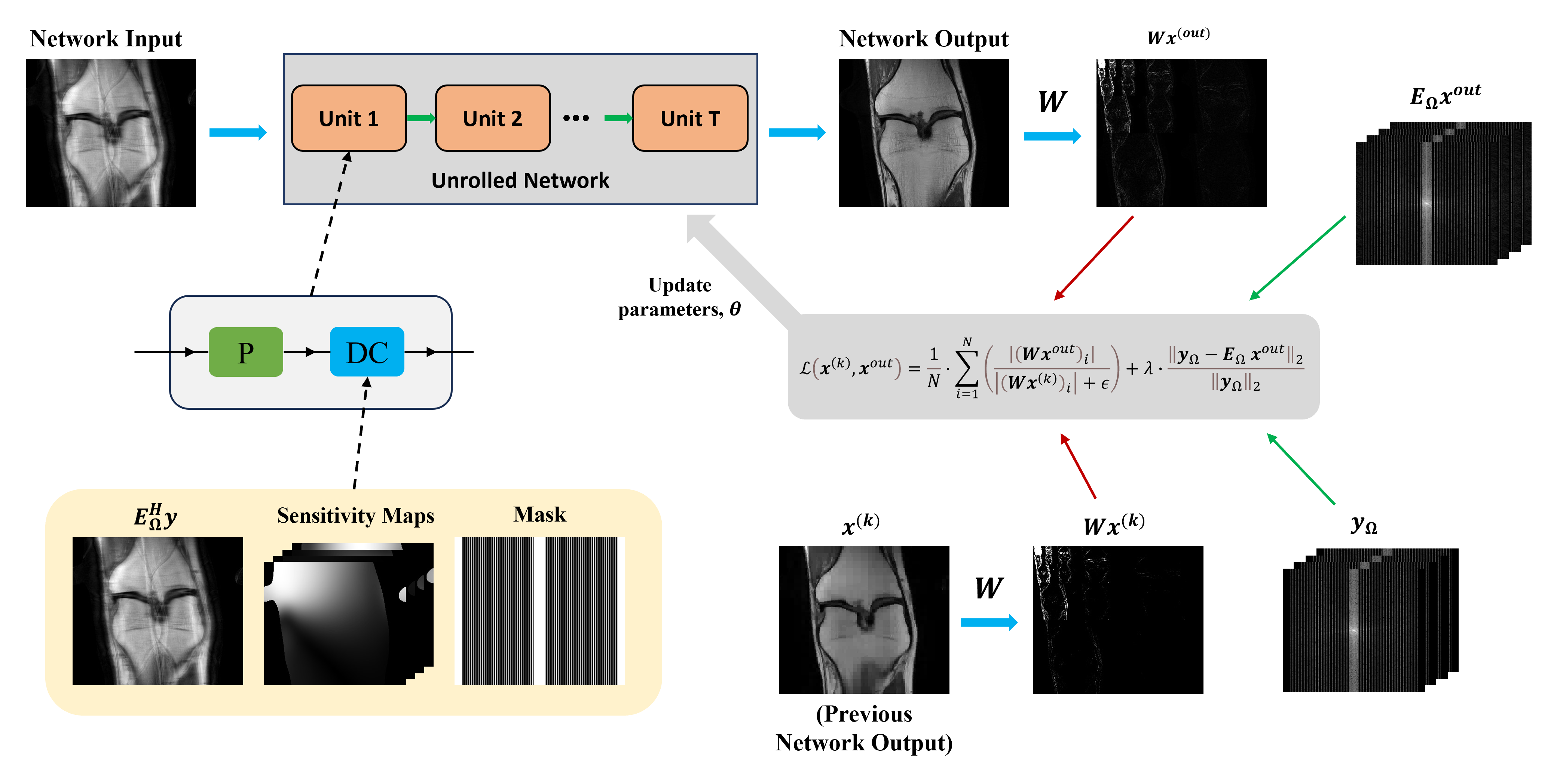
PD-DL Reconstruction:Regularized MRI reconstruction solves:$$\arg\min_{\mathbf{x}}\left\|\mathbf{y}_{\Omega}-\mathbf{E}_{\Omega}\mathbf{x}\right\|_2^2+\mathcal{R}(\mathbf{x}),$$where $$$y_\Omega$$$ is acquired k-space data at locations $$$\Omega$$$, $$$E_\Omega$$$ is the multi-coil encoding operator, and $$$x$$$ is the image of interest. A popular PD-DL approach is to unroll an iterative algorithm for solving this objective function, e.g. proximal gradient descent, for a fixed number of steps, and train the network end-to-end, learning both the proximal operator for $$$\mathcal{R(\cdot)}$$$, implemented implicitly with a neural network, and any weights used for data fidelity.
Proposed Compressibility-Inspired Loss Function:
We propose a loss function aimed at encouraging sparsity of the reconstruction in a transform domain. We first consider a supervised scenario, where the reference image is available. In this setting, we use the reweighted $$$\ell_1$$$-norm, which corresponds to the $$$\ell_0$$$-norm of a sparse signal12. Let $$$\mathbf{x}^{out}=f(\mathbf{y}_\Omega, \mathbf{E}_\Omega; \mathbf{\theta})$$$ be the output of the PD-DL network parametrized by learnable $$$\mathbf{\theta}$$$. The proposed loss is given as $$\mathcal{L}_{rew-\ell_1}\left(\mathbf{x}^{ref},\mathbf{x}^{\text{out}}\right)=\frac{1}{N}\cdot\sum_{i=1}^N\left(\frac{\left|\left(\mathbf{W}\mathbf{x}^{\text{out}}\right)_i\right|}{\left|\left(\mathbf{W}\mathbf{x}^{\text{ref}}\right)_i\right|+\epsilon}\right)+\lambda\cdot\frac{\left\|\mathbf{y}_{\Omega}-\mathbf{E}_{\Omega}\mathbf{x}^{\text{out}}\right\|_2}{\left\|\mathbf{y}_{\Omega}\right\|_2},$$where $$$\mathbf{x}^{\text{ref}}$$$ is the reference image, $$$\mathbf{W}$$$ denotes the transform under which $$$\mathbf{x}$$$ is sparsely represented, and $$$(\mathbf{Wx})_i$$$ denotes the $$$i^{th}$$$ (out of N) transform-domain coefficients, and $$$\epsilon$$$ is for numerical stability. Both terms in the loss are normalized to be unitless. We note the second term is needed to ensure that the network output is not driven to zero. Even in the presence of the data fidelity term within the PD-DL network, excluding the second term and training solely on the reweighted $$$\ell_1$$$ norm will push the regularizer output to $$$\mathbf{0}$$$, while simultaneously driving the weighting assigned to the regularizer to infinity since this combination forces the final PD-DL network output to be $$$\mathbf{0}$$$, minimizing the first term alone.
For the unsupervised setting, this motivates a reweighted $$$\ell_1$$$ approach that first starts with an initial estimate as the denominator weights, and then updates these weights progressively after each reweighting (Fig. 1). In particular, we propose:$$\mathcal{L}\left(\mathbf{x}^{(k)},\mathbf{x}^{\text{out}}\right)=\frac{1}{N}\cdot\sum_{i=1}^N\left(\frac{\left|\left(\mathbf{W}\mathbf{x}^{\text{out}}\right)_i\right|}{\left|\left(\mathbf{W}\mathbf{x}^{\text{(k)}}\right)_i\right|+\epsilon}\right)+\lambda\cdot\frac{\left\|\mathbf{y}_{\Omega}-\mathbf{E}_{\Omega}\mathbf{x}^{\text{out}}\right\|_2}{\left\|\mathbf{y}_{\Omega}\right\|_2},$$where $$$\mathbf{x}^{\text{(k)}}$$$ represents the signal estimate at the $$$k^{th}$$$ reweighting step. It is also worth noting that this method can be applied in a zero-shot manner to perform scan-specific accelerated MRI13.
Implementation Details:
Coronal proton-density knee fastMRI datasets14 were uniformly undersampled with R=4, 24 ACS. Training was performed using 300 knee slices and testing was performed on 10 distinct subjects. PD-DL network used variable splitting with data fidelity using conjugate-gradient2. The proximal operator for the regularizer was implemented with a ResNet15.
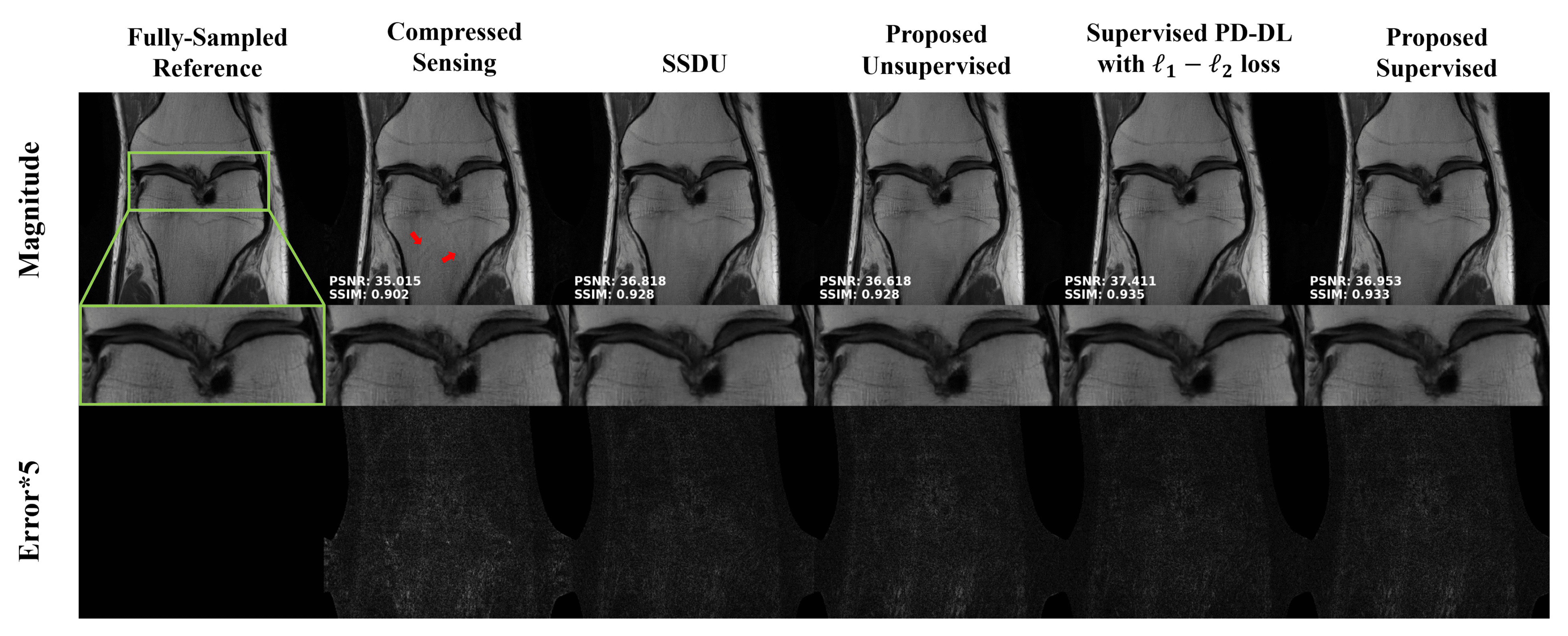
Biorthogonal 1.5 was used as $$$\mathbf{W}$$$. $$$\lambda$$$ was selected as 100 for both supervised and unsupervised proposed loss functions. 5 reweightings were used in the unsupervised case with initial $$$\mathbf{x}^{(0)}$$$ estimated using conventional $$$\ell_1$$$-wavelet-regularized least-squares minimization. Comparisons were made to supervised learning with an $$$\ell_1-\ell_2$$$ loss13, and SSDU6. Conventional CS reconstruction was also performed to highlight the differences between the use of PD-DL with the proposed loss and convex reconstruction with linear representations. Finally, proposed unsupervised loss was compared to ZS-SSDU16 for subject-specific learning. Results were quantitatively assessed using SSIM and PSNR.
Results
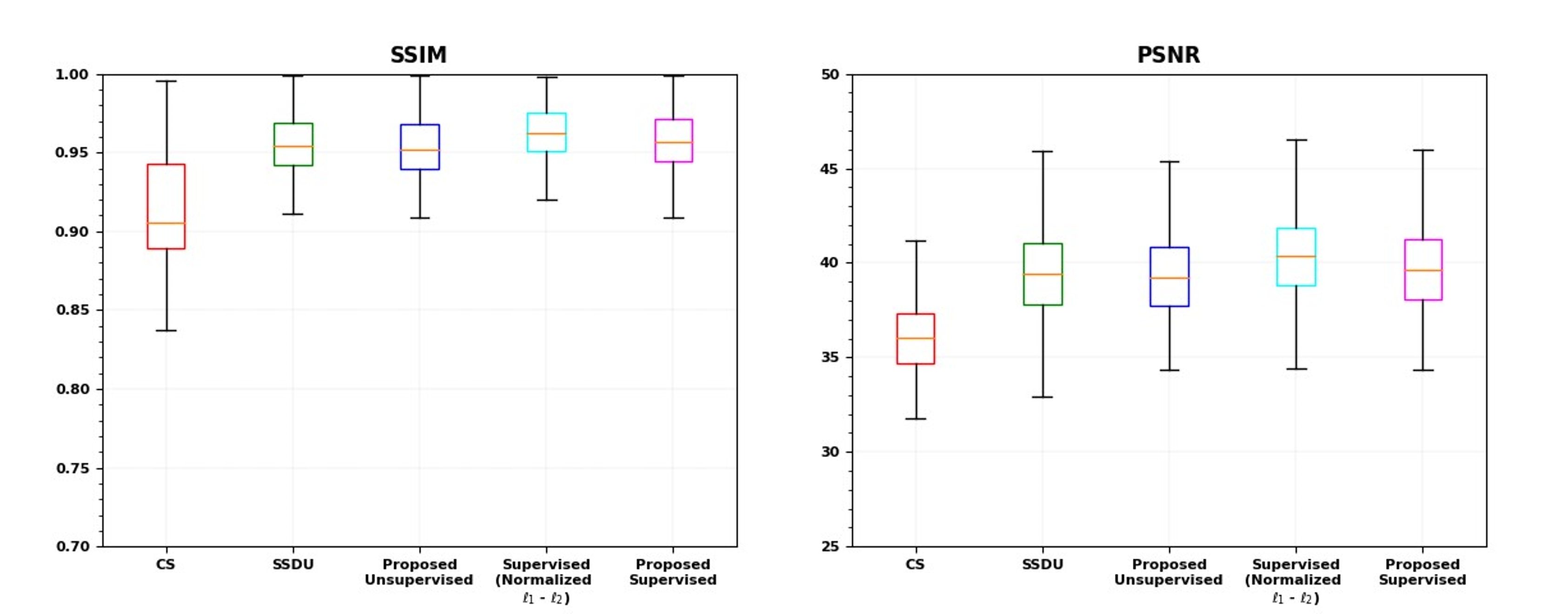
Fig. 2 shows representative reconstructions for supervised and unsupervised learning. Proposed loss formulation improves upon CS, as expected, while showing similar quality to well-established PD-DL methods.Fig. 3 summarizes the PSNR and SSIM metrics, matching these observations.
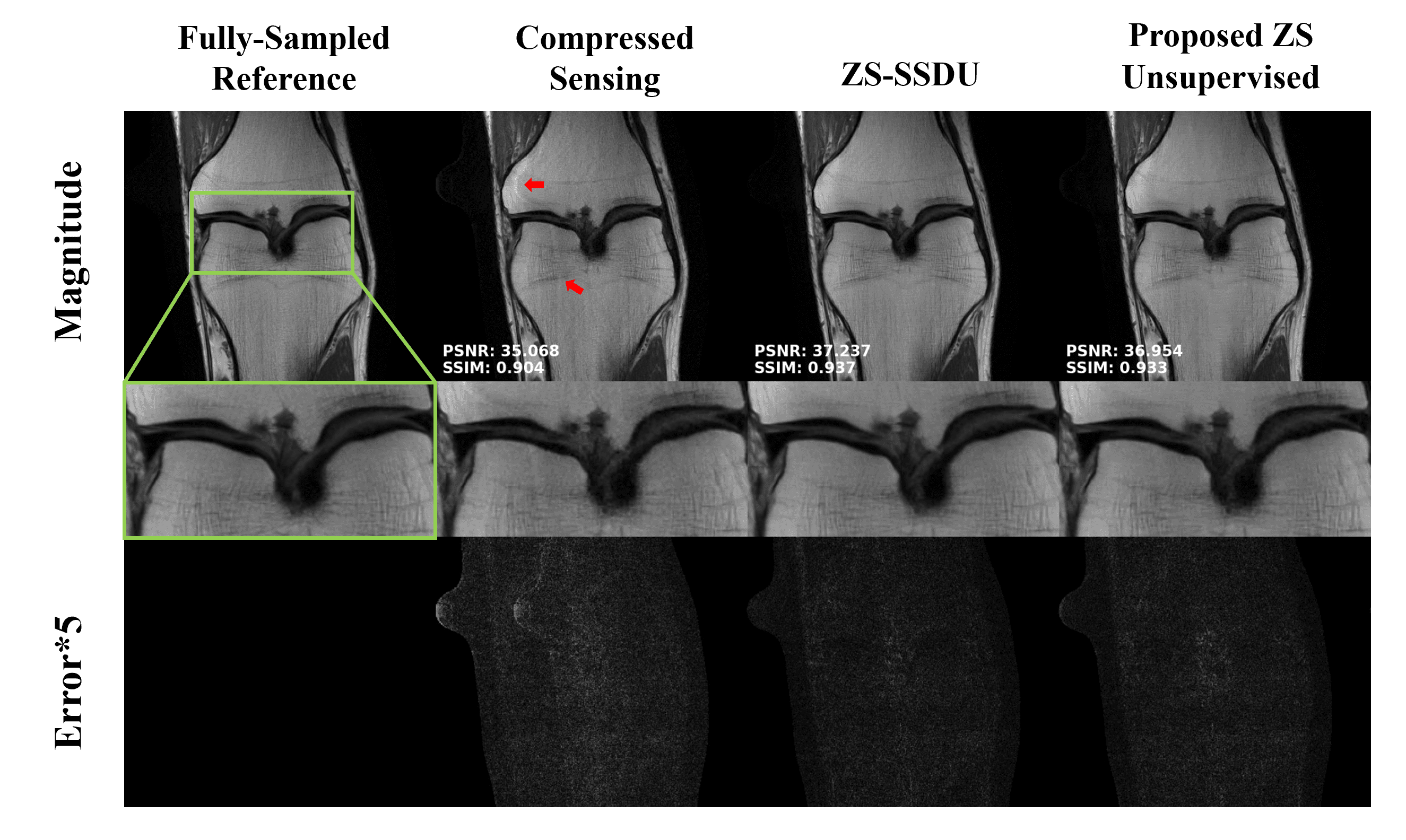
Fig. 4 showcases the zero-shot setting, where our proposed loss function performs similar to ZS-SSDU, while outperforming CS.
Discussion and Conclusions:
In this study, we proposed a new unsupervised loss formulation for PD-DL networks. Results show similar performance to self-supervised learning with SSDU. This provides an alternative approach that does not require masking of k-space, but instead focuses on compressibility of the output image.Acknowledgements
Grant support: NIH R01HL153146, NIH R01EB032830, NIH P41EB027061.References
[1] C. Qin, et al. "Convolutional recurrent neural networks for dynamic MR image reconstruction." IEEE transactions on medical imaging 38.1 (2018): 280-290.
[2] H. Aggarwal, M. P. Mani, and M. Jacob. “MoDL: Model-based deep learning architecture for inverse problems.” IEEE transactions on medical imaging 38.2 (2018): 394-405.
[3] K. Hammernik, et al. "Learning a variational network for reconstruction of accelerated MRI data." Magnetic resonance in medicine 79.6 (2018): 3055-3071.
[4] S.A.H. Hosseini, et al. "Dense recurrent neural networks for accelerated MRI: History-cognizant unrolling of optimization algorithms." IEEE Journal of Selected Topics in Signal Processing 14.6 (2020): 1280-1291.
[5] M. Akçakaya, et al. "Unsupervised deep learning methods for biological image reconstruction and enhancement: An overview from a signal processing perspective." IEEE Signal Processing Magazine 39.2 (2022): 28-44.
[6] B. Yaman, et al. "Self‐supervised learning of physics‐guided reconstruction neural networks without fully sampled reference data." Magnetic resonance in medicine 84.6 (2020): 3172-3191.
[7] D. Chen, et al. "Imaging With Equivariant Deep Learning: From unrolled network design to fully unsupervised learning." IEEE Signal Processing Magazine 40.1 (2023): 134-147.
[8] A. Jalal, et al. "Robust compressed sensing mri with deep generative priors." Advances in Neural Information Processing Systems 34 (2021): 14938-14954.
[9] H. Chung, and J. C. Ye. "Score-based diffusion models for accelerated MRI." Medical image analysis 80 (2022): 102479.
[10] M. Lustig, D. Donoho, and J. M. Pauly. "Sparse MRI: The application of compressed sensing for rapid MR imaging." Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine 58.6 (2007): 1182-1195.
[11] H. Gu, et al. "Revisiting -wavelet compressed-sensing MRI in the era of deep learning." Proceedings of the National Academy of Sciences 119.33 (2022): e2201062119.
[12] E. J. Candes, M. B. Wakin, and S. P. Boyd. "Enhancing sparsity by reweighted $$$\ell_1$$$ minimization." Journal of Fourier analysis and applications 14 (2008): 877-905.
[13] F. Knoll, et al. "Deep-learning methods for parallel magnetic resonance imaging reconstruction: A survey of the current approaches, trends, and issues." IEEE signal processing magazine 37.1 (2020): 128-140.
[14] F. Knoll, et al. "fastMRI: A publicly available raw k-space and DICOM dataset of knee images for accelerated MR image reconstruction using machine learning." Radiology: Artificial Intelligence 2.1 (2020): e190007.
[15] R. Timofte, et al. "Ntire 2017 challenge on single image super-resolution: Methods and results." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2017.
[16] B. Yaman, et al. "Zero-Shot Self-Supervised Learning for MRI Reconstruction." ICLR, 2022.
Figures