0807
MOST: MR reconstruction Optimization for multiple downStream Tasks via continual learning1Department of electrical and computer engineering, Seoul national university, Seoul, Korea, Republic of
Synopsis
Keywords: AI/ML Image Reconstruction, Image Reconstruction, Deep learning clinical adpatation
Motivation: This research aims to address the problem of performance degradation when a reconstruction network and a downstream network are cascaded. The proposed solution, MOST, optimizes a MR reconstruction network for multiple downstream tasks.
Goal(s): Our objective is to sequentially finetune a reconstruction network using losses from multiple downstream tasks while preventing catastrophic forgetting such that the same reconstruction network can be used for the multiple tasks.
Approach: We introduce replay-based continual learning into finetuning for multiple downstream tasks.
Results: Our method successfully circumvents catastrophic forgetting, exhibiting stable performance across all downstream tasks, enabling a single reconstruction network to be used for multiple tasks.
Impact: When k-space reconstruction and downstream tasks are performed using two separate networks (individually optimized), the cascade may introduce suboptimal results. Here, we propose a solution when multiple downsteam tasks exist, addressing challenges in realistic user environment.
Introduction
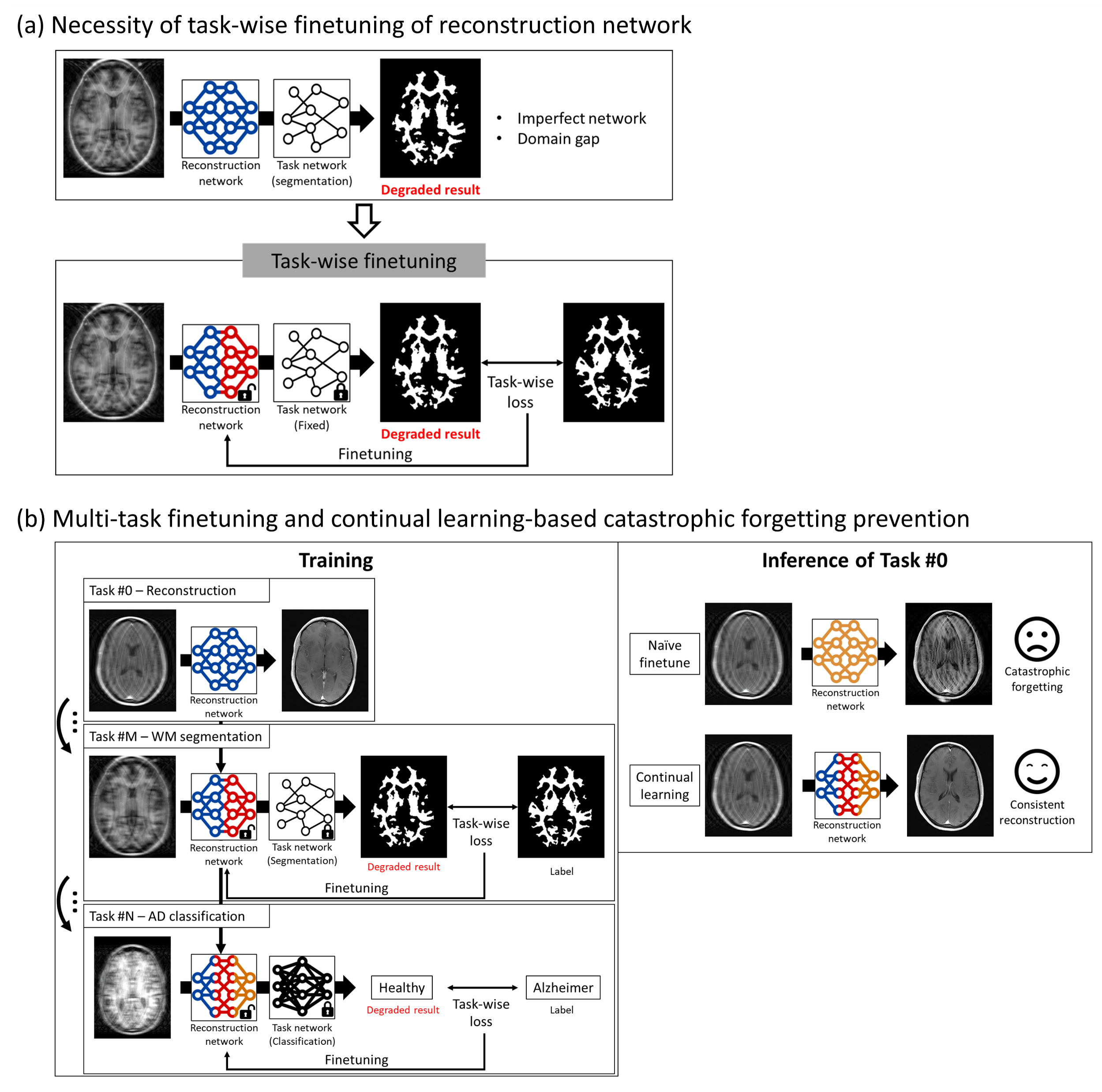
Deep learning-based accelerated MR image reconstruction has demonstrated remarkable performance in recent years.1-3 However, when a reconstruction network and a downstream network (e.g., segmentation network) are applied in sequence, the simple cascade of these networks yields suboptimal results due to network imperfections or domain gaps between training datasets. An effective solution involves finetuning the MR reconstruction network with a loss function customized for a specific downstream task (Fig. 1a). However, when multiple downstream tasks exist and they are progressively developed, there exists no clear solution. One approach is to create multiple reconstruction networks each optimized for a downstream network. However, this is not ideal nor practical because one has to run reconstruction for each task and also the idea fails to capitalize on potential improvement from inter-task correlations.4 In this study, we introduce MOST, a novel approach designed to sequentially optimize a single MR image reconstruction network for a series of multiple downstream tasks, enabling a single reconstruction network to be used for multiple tasks. To mitigate the challenge of catastrophic forgetting (Fig. 1b),5 we employ a continual learning approach.Methods
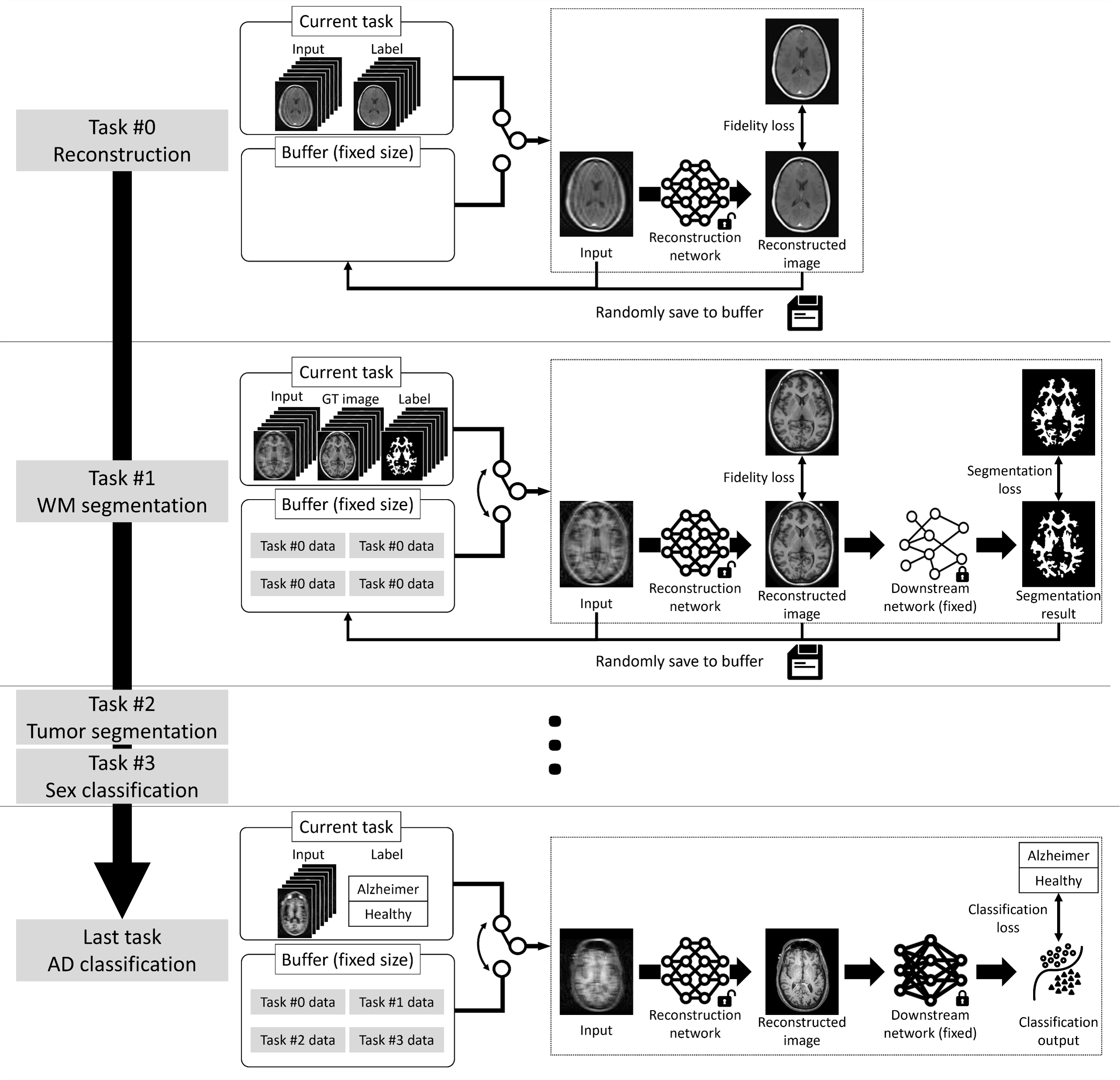
[Setting] The reconstruction network is trained with the SSIM loss. The four downstream tasks are pretrained to take a fully-sampled image as an input and generate segmentation maps or classification results. After the initial training phase, we proceed for the sequential finetuning of the reconstruction network with loss function from the downstream task. During the finetuning process for a particular downstream task, access to the complete dataset of another downstream task is restricted. It is important to note that finetuning is exclusively for the reconstruction network whereas the downstream networks are locked. The downstream tasks include two binary classifications (sex and Alzheimer's disease) as well as two segmentations (white matter and tumor).[MOST] To avoid catastrophic forgetting, we adopt a replay-based continual learning approach.6,7 In this method, we maintain a small fixed-size buffer (10 subject data) to store a subset of input-output pairs from previous tasks. Upon completing each task, randomly selected input-output pairs are added to the buffer. The buffer size remains constant with new pairs replacing old ones. The buffer data are included in the finetuning process, ensuring the network retains its performance on past tasks.
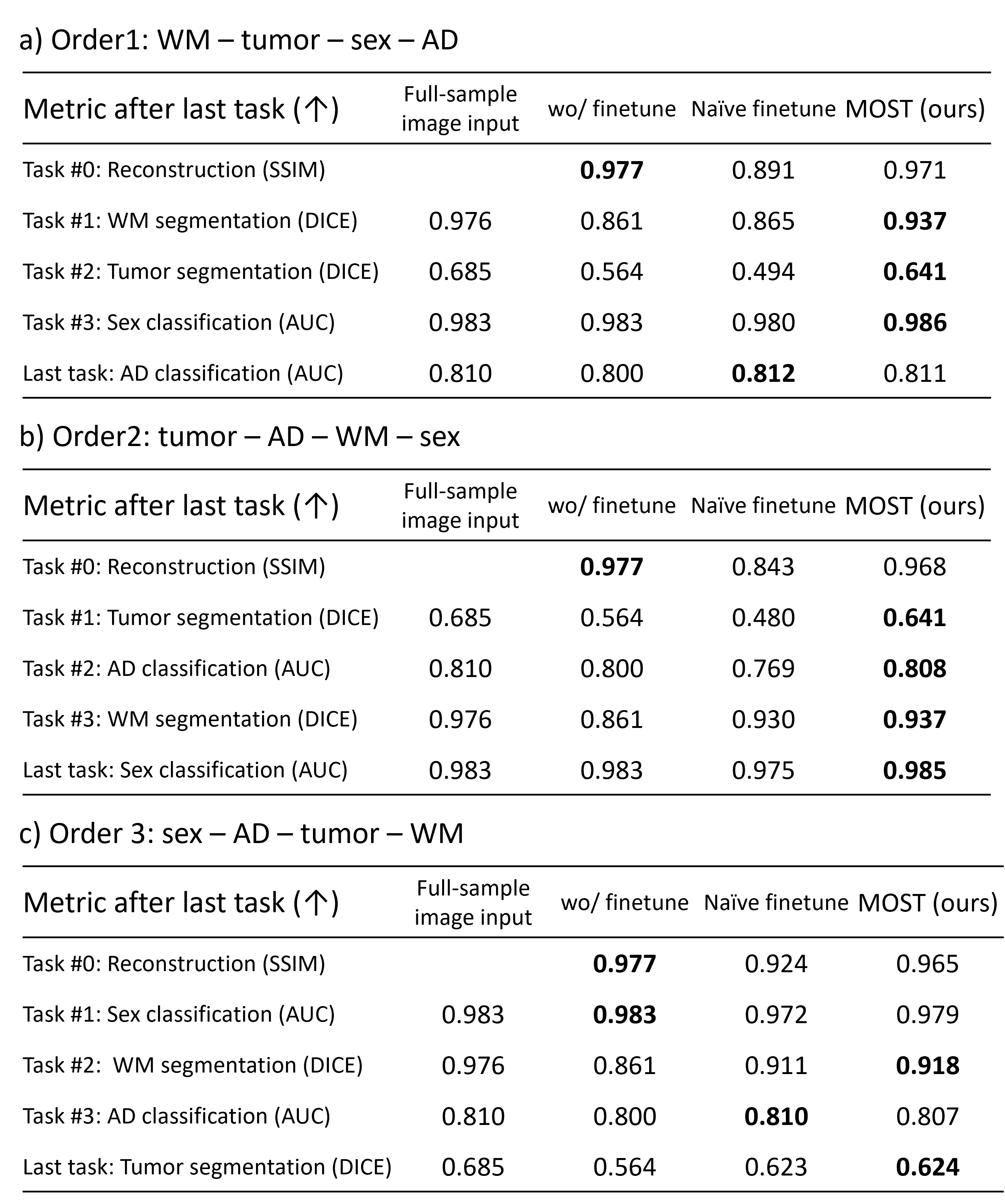
[Experiments] We utilized T1-weighted images from multiple datasets (FastMRI,3 OASIS1,8 BRaTS,9 IXI, and ADNI,10 for reconstruction, WM segmentation, tumor segmentation, sex classification, and AD classification, respectively). An end-to-end variational network (VN) is used for the network structure. To generate undersampled images, a forward model was applied with a single coil assumption (R=4). Three different task orders were evaluated: WM segmentation, tumor segmentation, sex classification, and AD classification (Order 1, default); tumor segmentation, AD classification, WM segmentation, and sex classification (Order 2); and sex classification, AD classification, tumor segmentation and WM segmentation (Order 3). The performances of MOST and naïve finetuning were compared. The evaluation metrices were SSIM for reconstruction, DICE for segmentation, and AUC for classification.
Results
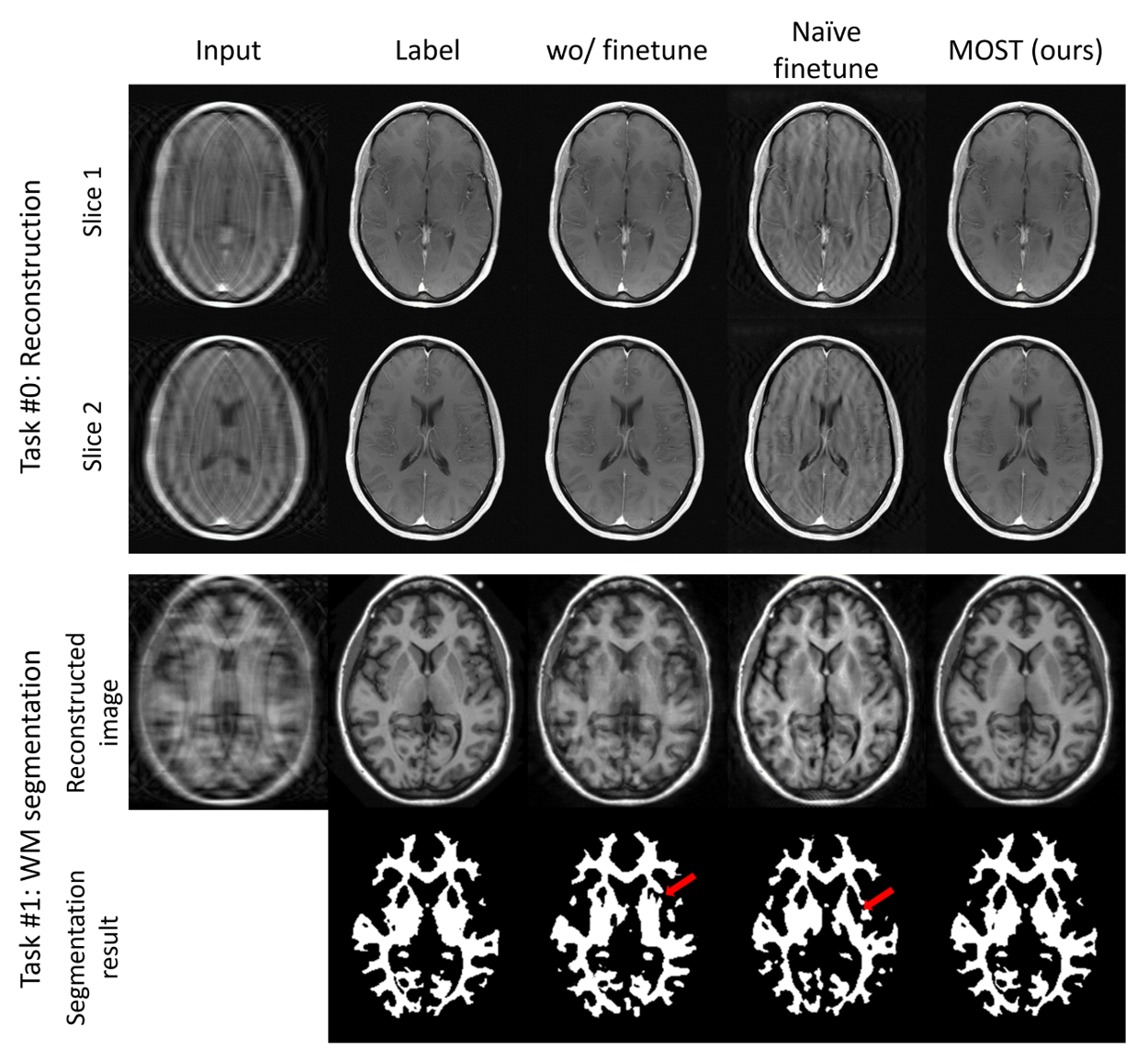
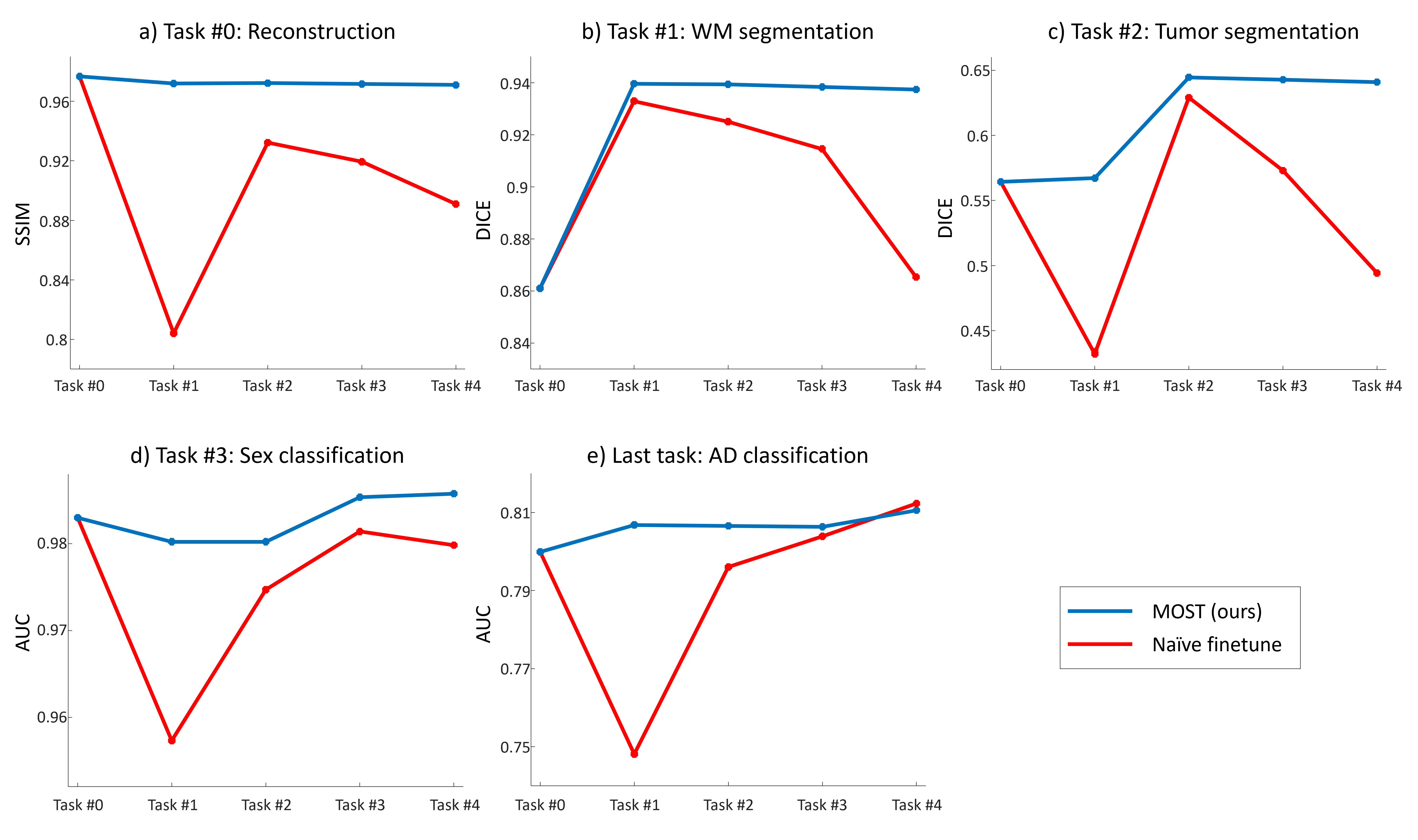
In Figure 3, we illustrate the performance dynamics of each downstream task. Each data point in the plots represents a metric for a task after finetuning for the corresponding task indicated on the x-axis. Typically, we observed an initial improvement in metrics for each task following finetuning specifically for that task. However, subsequent naïve finetuning for other downstream tasks led to a catastrophic forgetting, as indicated by the red lines in Fig. 3. For example, considering the red line in Figure 3b, the DICE score of WM segmentation reached 0.933 after training Task #1 but dropped to 0.865 after training Task #4, suggesting catastrophic forgetting in WM segmentation task in the naïve finetuning. Notably, MOST effectively mitigated this catastrophic forgetting, maintaining stable performance throughout the series of tasks (blue line). Qualitatively (Fig. 4), naïve finetuning yielded suboptimal results for reconstruction and WM segmentation. In contrast, MOST consistently produced robust results. Table 1 reports the metrics after the final finetuning for the three different task orders. For Orders 1 and 2, MOST demonstrated the best metrics, affirming its efficacy in preventing catastrophic forgetting. In Order 3, MOST displayed overall commendable performance but suboptimal metrics in sex and AD classifications, suggesting order-dependency.Conclusion and Discussion
In this study, we present MOST, an innovative approach that allows the sequential finetuning of the MR reconstruction network for a series of downstream tasks. The method is implemented by the integration of replay-based continual learning techniques, effectively addressing the challenge of catastrophic forgetting. The method enables us to utilize a single reconstruction network for multiple tasks, delivering practical importance.Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. NRF-2022R1A4A1030579 and 2021M3E5D2A01024795), the Brain Korea 21 Plus Project in 2023, and Institute of New Media and Communications (INMC), SNU.References
1. Hammernik, Kerstin, et al. "Learning a variational network for reconstruction of accelerated MRI data." Magnetic resonance in medicine 79.6 (2018): 3055-3071.
2. Aggarwal, Hemant K., Merry P. Mani, and Mathews Jacob. "MoDL: Model-based deep learning architecture for inverse problems." IEEE transactions on medical imaging 38.2 (2018): 394-405.
3. Zbontar, Jure, et al. "fastMRI: An open dataset and benchmarks for accelerated MRI." arXiv preprint arXiv:1811.08839 (2018).
4. Lopez-Paz, David, and Marc'Aurelio Ranzato. "Gradient episodic memory for continual learning." Advances in neural information processing systems 30 (2017).
5. French, Robert M. "Catastrophic forgetting in connectionist networks." Trends in cognitive sciences 3.4 (1999): 128-135.
6. Chaudhry, Arslan, et al. "On tiny episodic memories in continual learning." arXiv preprint arXiv:1902.10486 (2019).
7. Buzzega, Pietro, et al. "Dark experience for general continual learning: a strong, simple baseline." Advances in neural information processing systems 33 (2020): 15920-15930.
8. Marcus, Daniel S., et al. "Open Access Series of Imaging Studies (OASIS): cross-sectional MRI data in young, middle aged, nondemented, and demented older adults." Journal of cognitive neuroscience 19.9 (2007): 1498-1507.
9. Menze, Bjoern H., et al. "The multimodal brain tumor image segmentation benchmark (BRATS)." IEEE transactions on medical imaging 34.10 (2014): 1993-2024.
10. Jack Jr, Clifford R., et al. "The Alzheimer's disease neuroimaging initiative (ADNI): MRI methods." Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine 27.4 (2008): 685-691.
Figures