0656
Reconstruction-free segmentation from undersampled k-space using transformers1School of Computation, Information and Technology, Technical University of Munich, Munich, Germany, 2School of Medicine, Klinikum rechts der Isar, Munich, Germany, 3Munich Center for Machine Learning, Technical University of Munich, Munich, Germany, 4Department of Computing, Imperial College London, London, United Kingdom
Synopsis
Keywords: AI/ML Image Reconstruction, Segmentation, k-space
Motivation: High acceleration factors place a limit on MRI image reconstruction. This limit is extended to segmentation models when treating these as subsequent independent processes.
Goal(s): Our goal is to produce segmentations directly from sparse k-space measurements without the need for intermediate image reconstruction.
Approach: We employ a transformer architecture to encode global k-space information into latent features. The produced latent vectors condition queried coordinates during decoding to generate segmentation class probabilities.
Results: The model is able to produce better segmentations across high acceleration factors than image-based segmentation baselines.
Impact: Cardiac segmentation directly from undersampled k-space samples circumvents the need for an intermediate image reconstruction step. This allows the potential to assess myocardial structure and function on higher acceleration factors than methods that rely on images as input.
Introduction
In cardiac magnetic resonance (CMR) imaging, an abundance of quantitative clinical metrics (such as ejection fraction, strain, etc.) are derived from segmentation-based modeling of the myocardium. Image reconstruction and segmentation are typically thought of as independent serial processes. In order to reduce acquisition time, k-space data is usually undersampled and reconstruction techniques are employed. These approaches attempt to recover the pixel-level detail lost during this process. However, accurate segmentation does not strictly benefit from this level of precision, often relying on high level information about the overall content of the image.While segmentation of cardiac images predominantly takes place on clean images1, previous works have attempted to tackle higher accelerations by performing segmentation directly on unrefined images2. Formulating the task as an end-to-end learning problem has shown further improvements3.
We hypothesize that the process of magnetic resonance (MR) image reconstruction requires larger amounts k-space samples than what theoretically would be required to extract a segmentation signal from the raw data. Under this assumption, direct segmentation from k-space has the potential to allow the quantification of relevant clinical metrics under higher acceleration factors, while further decreasing acquisition time.
Method
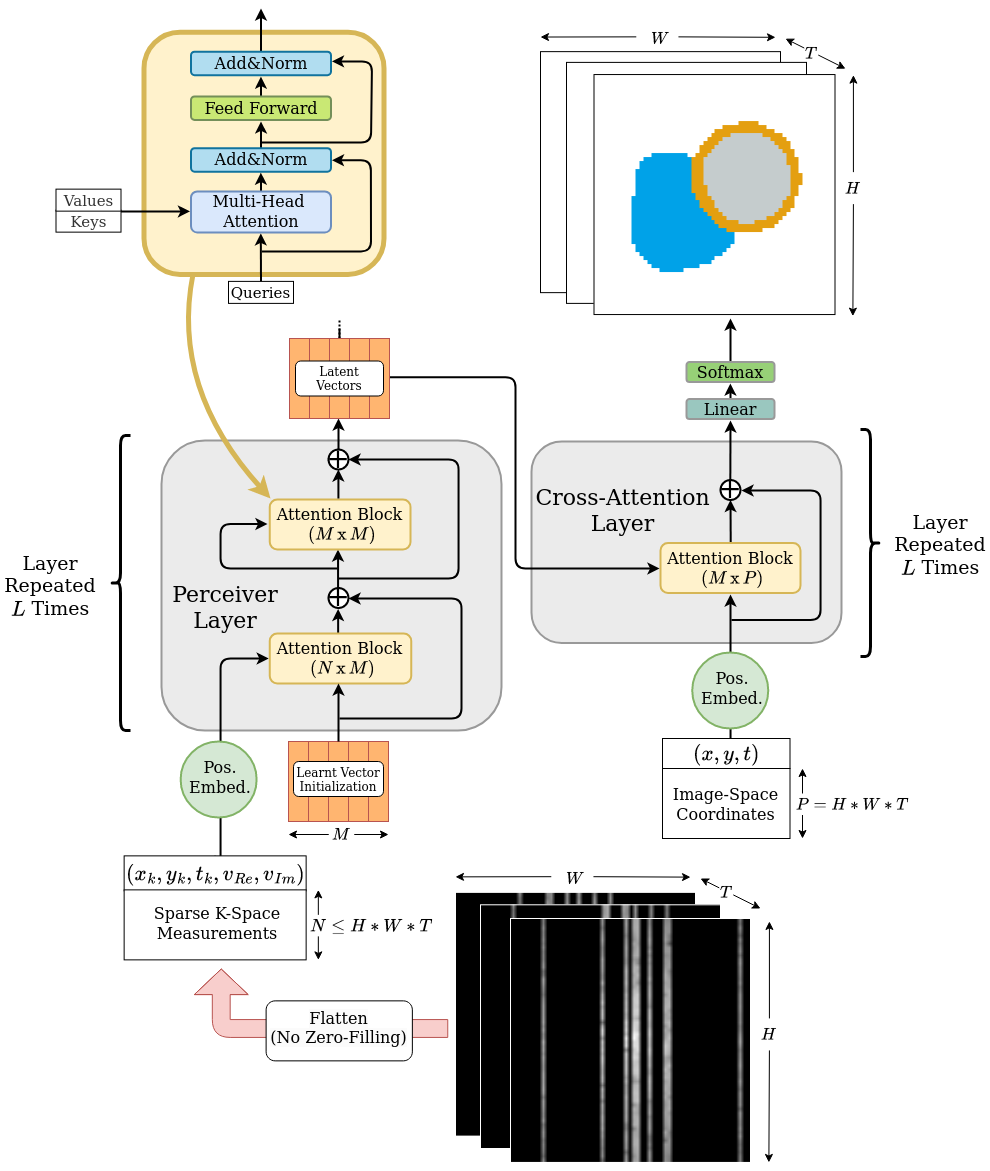
In this work, we demonstrate that Transformers4 are capable of employing global attention to leverage all available k-space measurements to predict accurate segmentation maps. The architecture is able to perform this task directly from a set of sampled k-space points, without a need for zero-filling or interpolating the k-space, and without any form of intermediate reconstruction step. We postulate that multi-headed attention, unlike convolutional approaches, offers the necessary properties to appropriately process the nature of k-space: (1) the mechanism considers global correlations, (2) feature extraction should be insensitive to the relative order in which the same samples are presented, (3) inputs of arbitrary sparsity are supported. An overview of the architecture is presented in our figures.Our architecture's encoder extracts features from the sparse input k-space samples into a latent space over the course of 4 layers. In order to efficiently handle hundreds of thousands of k-space samples while avoiding the $$$\mathcal{O}\left(N^2\right)$$$ memory complexity of naive self-attention in standard transformers, our encoder utilizes alternating cross-attention (CA) and self-attention (SA) blocks as proposed by Perceiver5. The CA blocks project global k-space information into a bottleneck of latent vectors, while the SA blocks contextualize features between latent vectors.
The decoder consists of 4 cross-attention blocks, which use the extracted latent information to condition any queried image-domain coordinate into producing segmentation class probabilities. The segmentation output is supervised on Dice and binary cross-entropy losses.
Implementation and Results
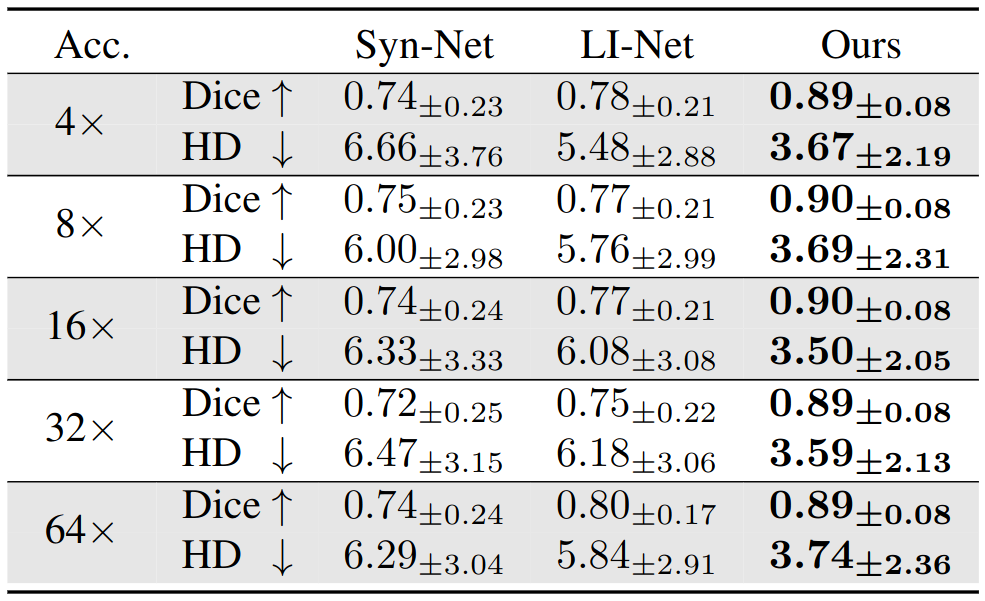
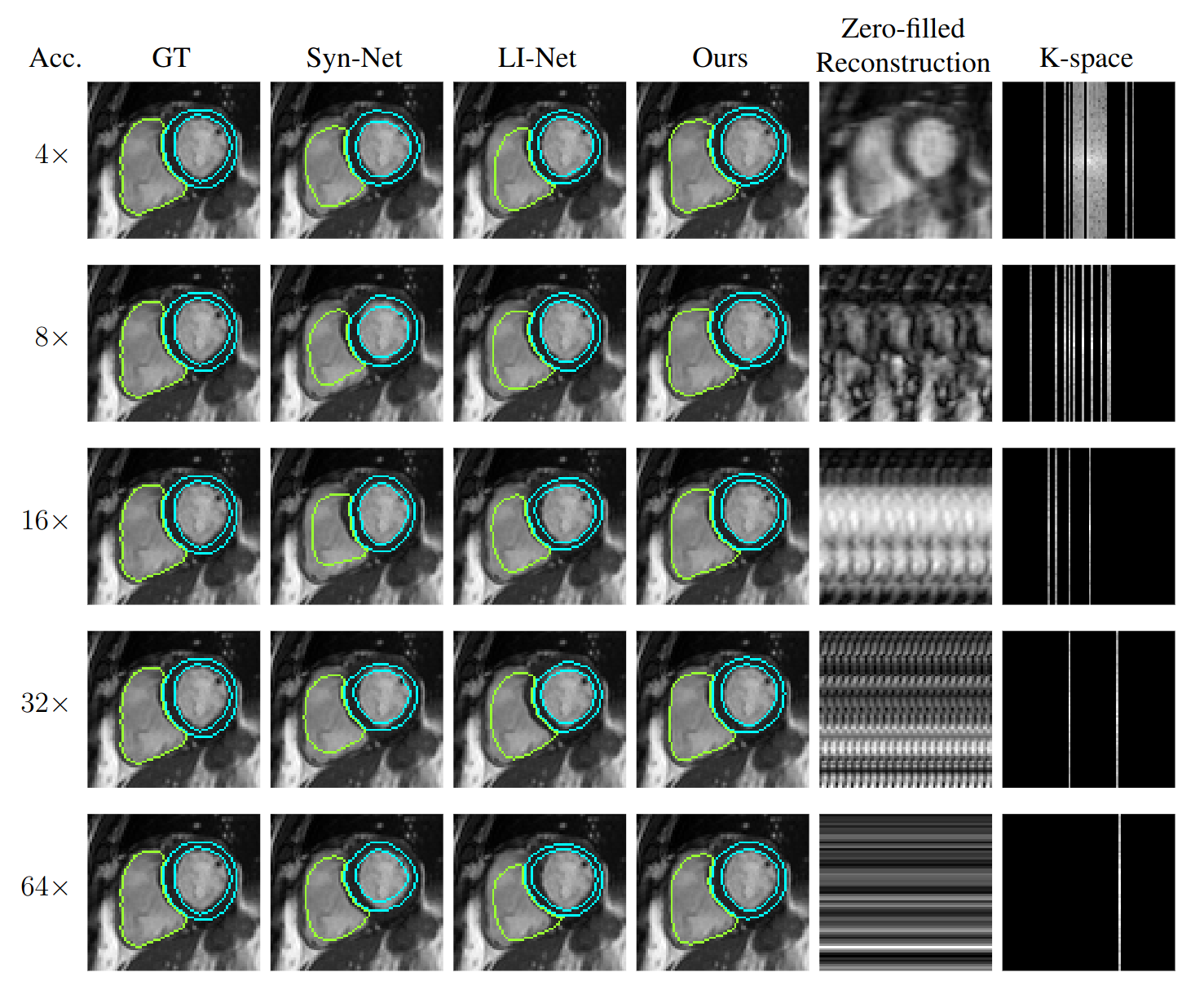
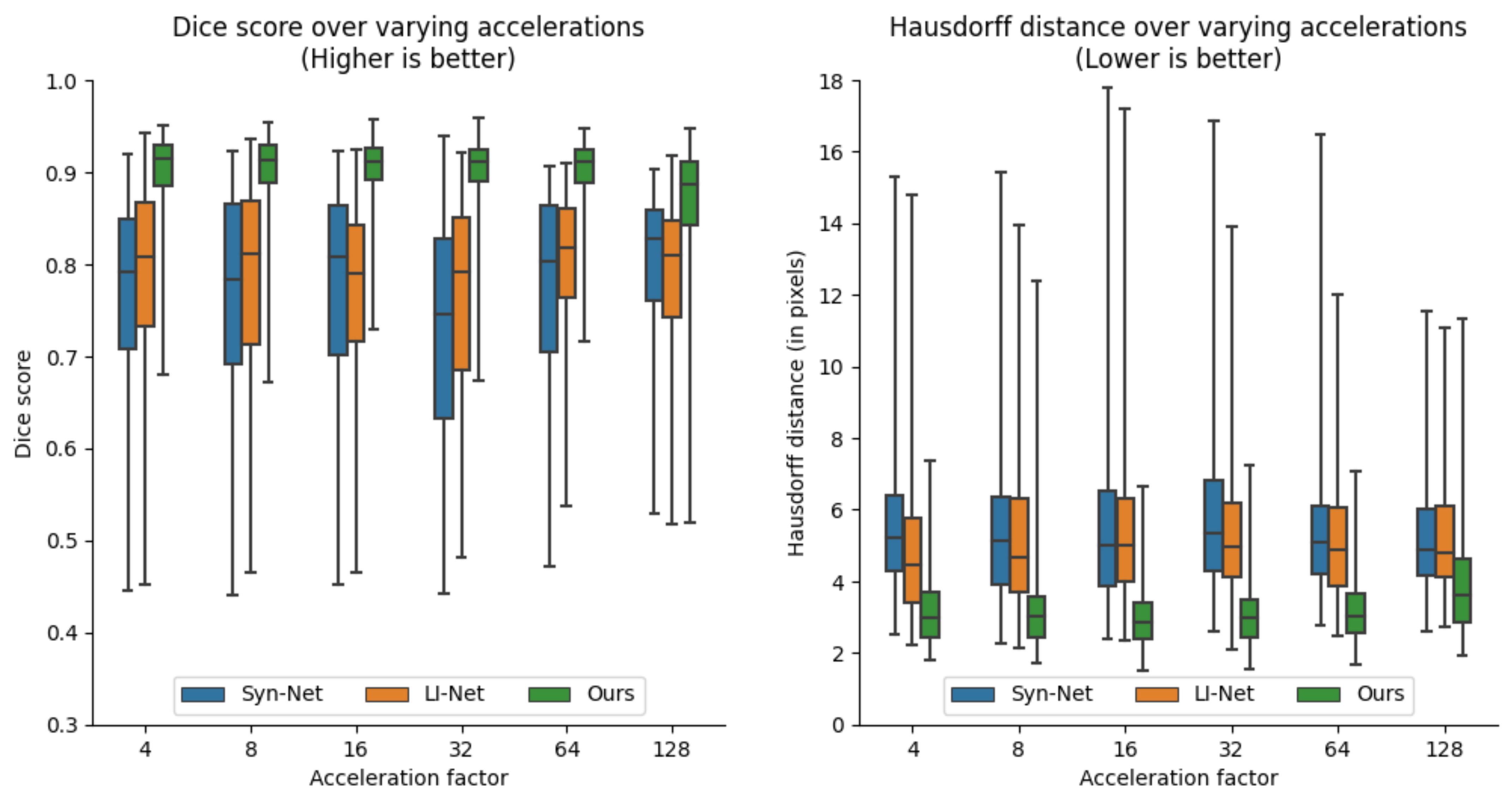
Our training dataset is comprised of 1200 mid-ventricular slices of cardiac short-axis scans from the UK-Biobank dataset6. The dataset is arranged into 1000/100/100 splits for training, validation, and testing sets. Each scan has 50 frames with an average in-plane resolution of approximately 80x80 pixels per frame. We create synthetic undersampled k-space data on-the-fly for each 2D+time scan. Each frame, we apply additional Gaussian B0 variations (in order to remove the conjugate symmetry of k-space) and generate Cartesian undersampling masks by sampling normally distributed lines centered on the DC component. Implementation and training was performed using the Pytorch library on an NVIDIA A40 GPU.We evaluate the performance of models trained on acceleration factors 4, 8, 16, 32, and 64. Our approach is compared to the performance of two image-based segmentation baselines. Following previous work2, we implement a model based on the U-Net7 architecture (Syn-Net) and an autoencoder approach (LI-Net). Their work showed these models to be capable of producing segmentations on noisy reconstructions of undersampled images. Our model obtains higher segmentation Dice scores and lower Hausdorff distances than the proposed baselines across all tested accelerations.
Discussion
Due to the nature of short-axis acquisitions, the heart is consistently on the same general location and orientation across the dataset. It is therefore easy for the models to achieve a decent performance at high accelerations by memorizing a general shape and location. Despite this, our model appears to consistently produce better approximations of the true anatomy. We suspect that our model's ability to attend globally across all time frames plays a key role.Conclusion
To the best of our knowledge, this is the first study that explores the prediction of cardiac segmentation maps directly from sparse under-sampled k-space measurements without an explicit image reconstruction step. Our results show that transformer architectures are capable of extracting global features from sparse k-space measurements and improve segmentation performance over image-based baselines at high accelerations factors.Acknowledgements
This work was supported in part by the European Research Council (Deep4MI project, Grant Agreement Nr.884622) and the Munich Center for Machine Learning and European Research Council (ERC) project Deep4MI (884622). This research has been conducted using the UK Biobank Resource under Application Number 87802.References
- Bai, W., et al. Automated cardiovascular magnetic resonance image analysis with fully convolutional networks. Journal of cardiovascular Magnetic Resonance 20(1), 1–12 (2018).
- Schlemper, J., et al. Cardiac MR segmentation from undersampled k-space using deep latent representation learning. Medical Image Computing and Computer-Assisted Intervention (2018).
- Huang, Q., et al. FR-Net: Joint reconstruction and segmentation in compressed sensing cardiac MRI. Functional Imaging and Modeling of the Heart: 10th International Conference (2019).
- Vaswani, A., et al. Attention is all you need. Advances in Neural Information Processing systems 30 (2017).
- Jaegle, A. et al. Perceiver: General Perception with Iterative Attention. International conference on machine learning (2021).
- UK Biobank. Data Showcase. https://biobank.ndph.ox.ac.uk/showcase/. Accessed: 03 Nov 2023.
- Ronneberger, O., et al. U-Net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention (2015).
Figures