0654
Imaging transformer for MRI denoising with SNR unit training: enabling generalization across field-strengths, imaging contrasts, and anatomy1National Heart, Lung, and Blood Institute, Bethesda, MD, United States, 2Barts Heart Centre at St. Bartholomew's Hospital, London, United Kingdom, 3University of California, San Francisco, San Francisco, CA, United States
Synopsis
Keywords: Other AI/ML, Machine Learning/Artificial Intelligence, imaging transformer, generalization
Motivation: MR denoising using the CNN models often requires abundant high quality data for training. In many applications, such as higher acceleration and low field, high quality data is not available. This study overcome this limitation by developing a SNR unit based training scheme and a novel imaging transformer (imformer) architecture.
Goal(s): To develop and validate a novel imformer model for MR denoising, enabling generalization across field-strengths, imaging contrasts, and anatomy.
Approach: SNR unit training scheme and imaging transformer architecture
Results: Imformer models outperformed CNNs and conventional transformer. The SNR training enables storng generalization.
Impact: Recovery high-fidelity MR signal from very low SNR inputs; Enable 0.55T MRI model training.
Introduction
Ability to recover signal from noise is key to achieve fast acquisition, accurate quantification, and good quality. Past work has shown CNNs1 can be trained with large datasets of high-SNR images. For applications where high-quality data is difficult to produce at scale (e.g. aggressive acceleration, high resolution, or low field), training can be infeasible. We overcome this limitation by a) develop a training scheme that uses complex MRIs in the SNR units (i.e., the images have a fixed noise level) and augmentation with realistic noise based on coil g-factor to allow strong generalization and b) develop a novel imaging transformer (imformer) to outperform CNNs.Methods
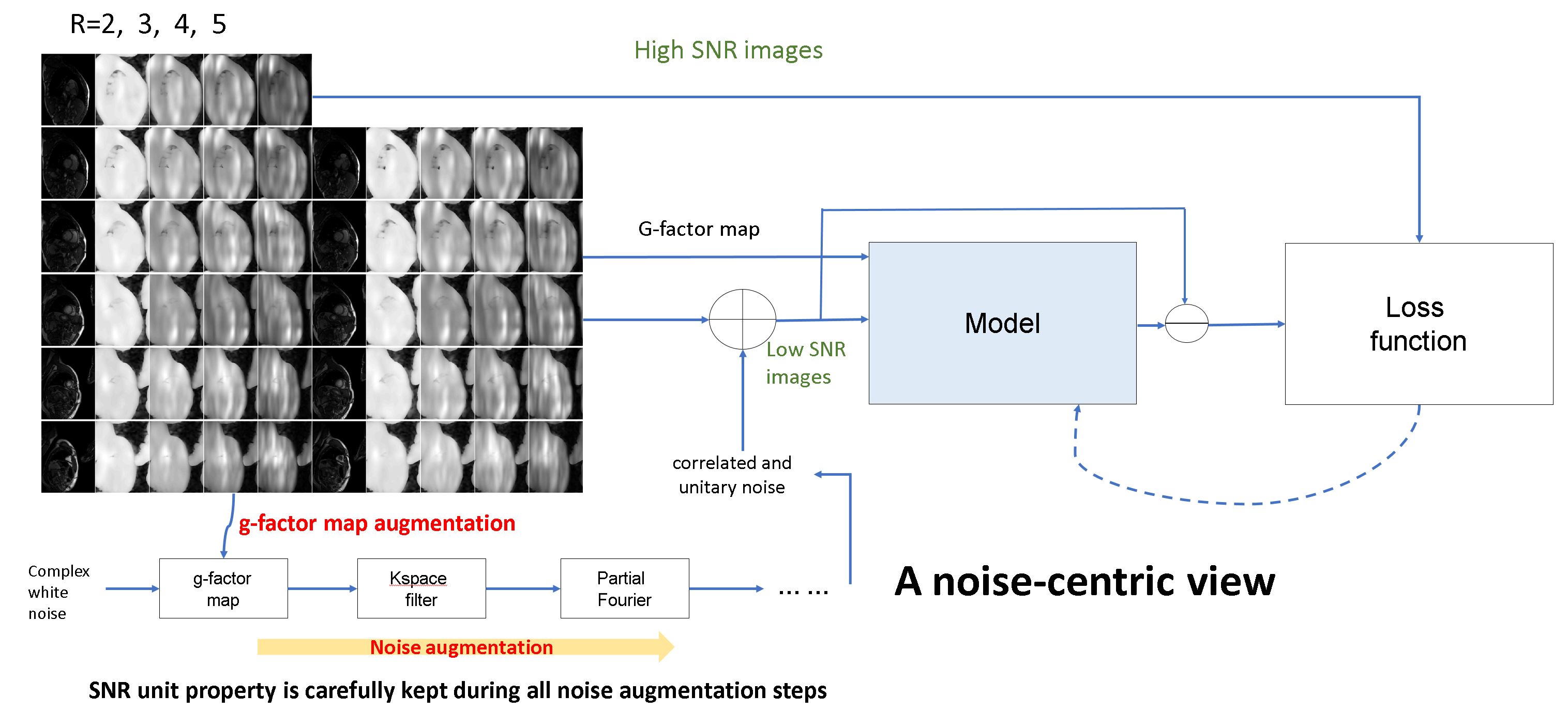
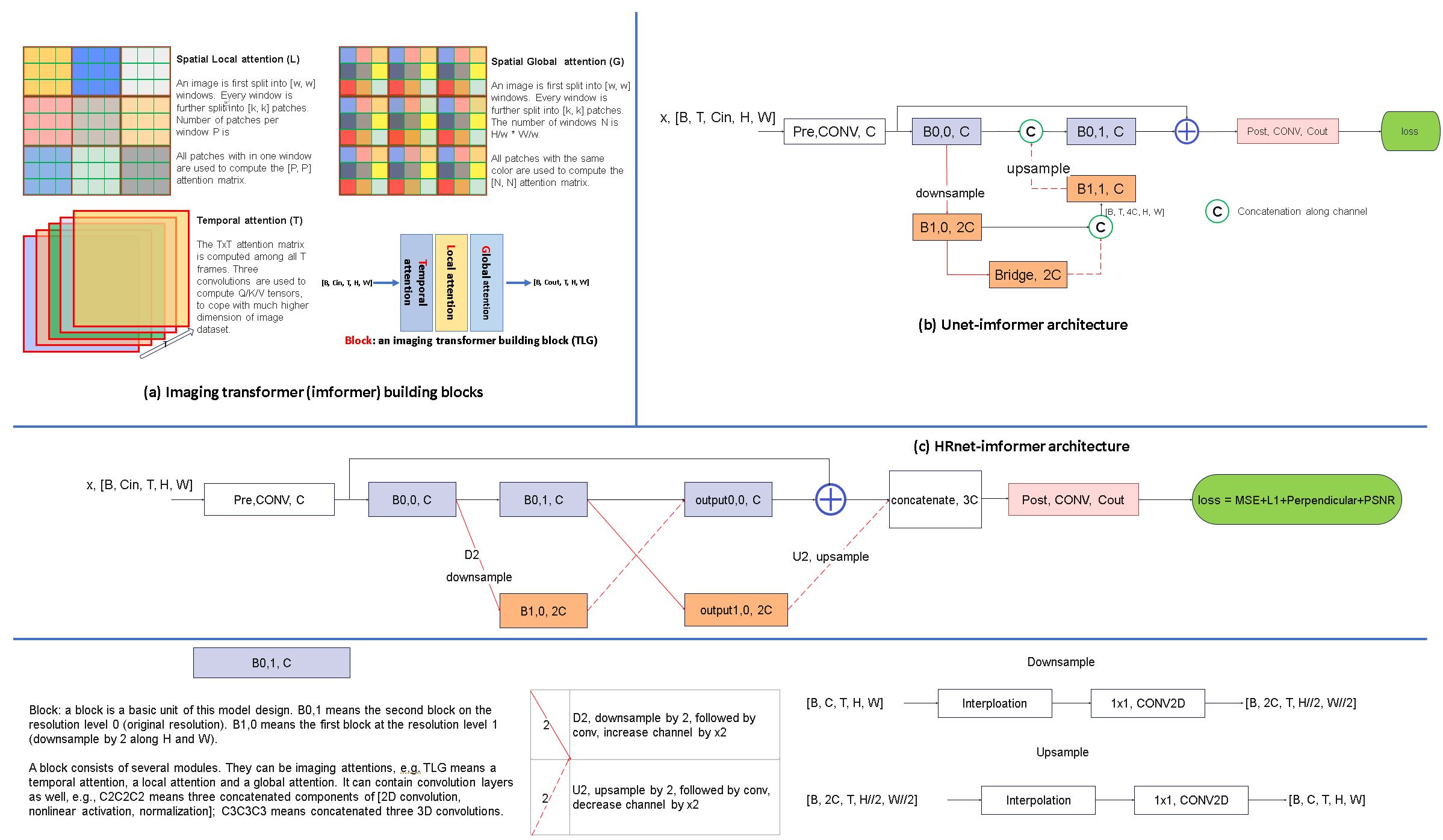
The proposed training method is shown in Fig. 1. High SNR complex images (retro-gated cine acquired solely at 3T) were degraded with realistic MR noise augmented with g-factor maps (R=2 to 6), partial Fourier and kspace filters. Unlike past approaches, which typically normalize the signal levels (e.g., to range [0, 1]), we focus on normalizing the noise level. The SNR unit 2 reconstruction was applied throughout training to keep the noise standard deviation at 1.0. The corrupted images and g-factor maps were input into the model. The model was optimized to recover high-quality images from degraded inputs.We propose a novel imaging transformer (Fig. 2), to enable the model to process 2D, 2D+T, and 3D images. The key innovation are three configurable imaging attention modules: spatial local (L), spatial global (G) and temporal (T) attention. A block allows any combination of attention modules. By stacking many blocks together, imaging transformer models are built, enabling every output pixel to be computed by nonlinearly combining all input pixels with data-specific attention coefficients. Two imaging transformer were implemented, inspired by two popular CNNs: Unet 3 and high-res net (“HRnet”) 4 (Fig. 2b and c). respectively.
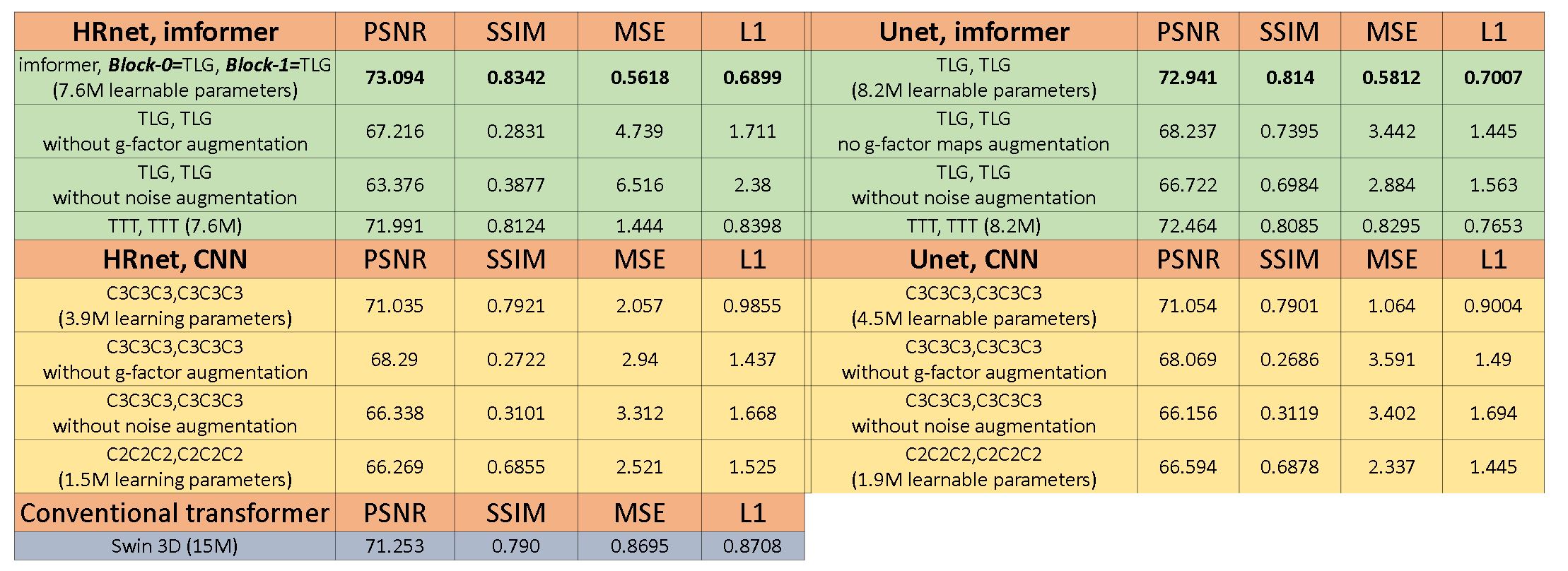
Model comparison. Five models were compared: three “standard” models – Unet, HRnet, swin3D transformer 5; two imformers – Unet-imformer and HRnet-imformer. All were trained on 309,238 3T retro-cine complex 2D+T series (MAGNETOM Prisma, Siemens Healthcare) with SNR unit and noise augmentation. For ablation, four models were additionally trained without g-factor or MR noise. Training was for 50 epochs with the Sophia optimizer 6 and tested on a held-out 560 samples containing 2D, 2D+T, and 3D images as well as different SNR levels. MSE, L1, PSNR (max intensity 2048.0) and SSIM were computed.
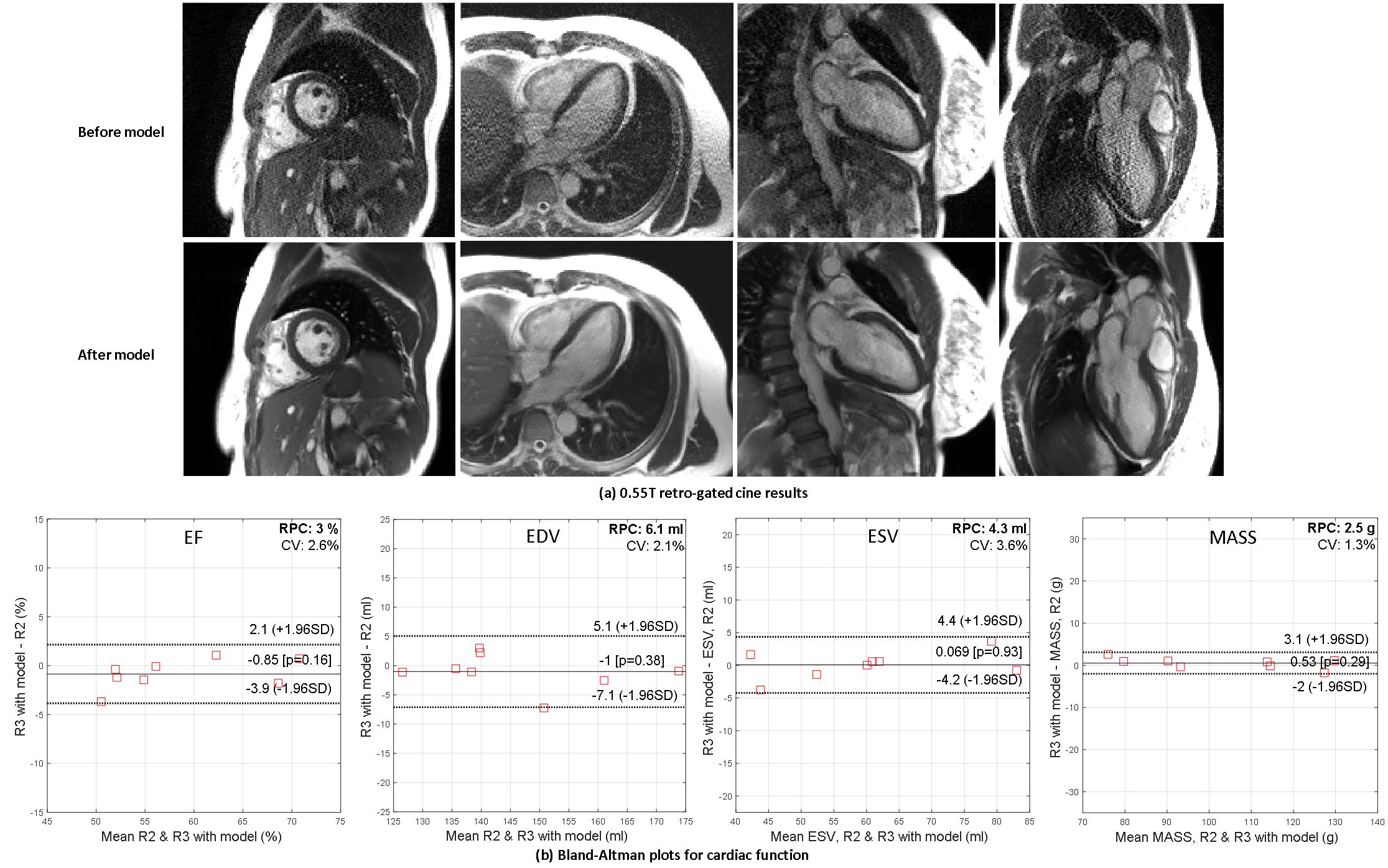
Cross field strength generalization, 0.55T MRI. 8 healthy volunteers were scanned at a 0.55T MRI (MAGNETOM FreeMax, Siemens Healthcare) for R=2 and 3 retro-gated cine, CH4, CH2, CH3 and SAX stacks. HRNet-imformer was applied to R=3 cine and ROIs were drawn in the LV and myocardium. The local point spread function 7 was measured on 452 points on the endo- and epi-cardiac boundaries to quantify resolution loss after the model. EF, ESV, EDV, MASS were measured on model outputs and compared to R=2 without model, using a validated cine AI model 8.
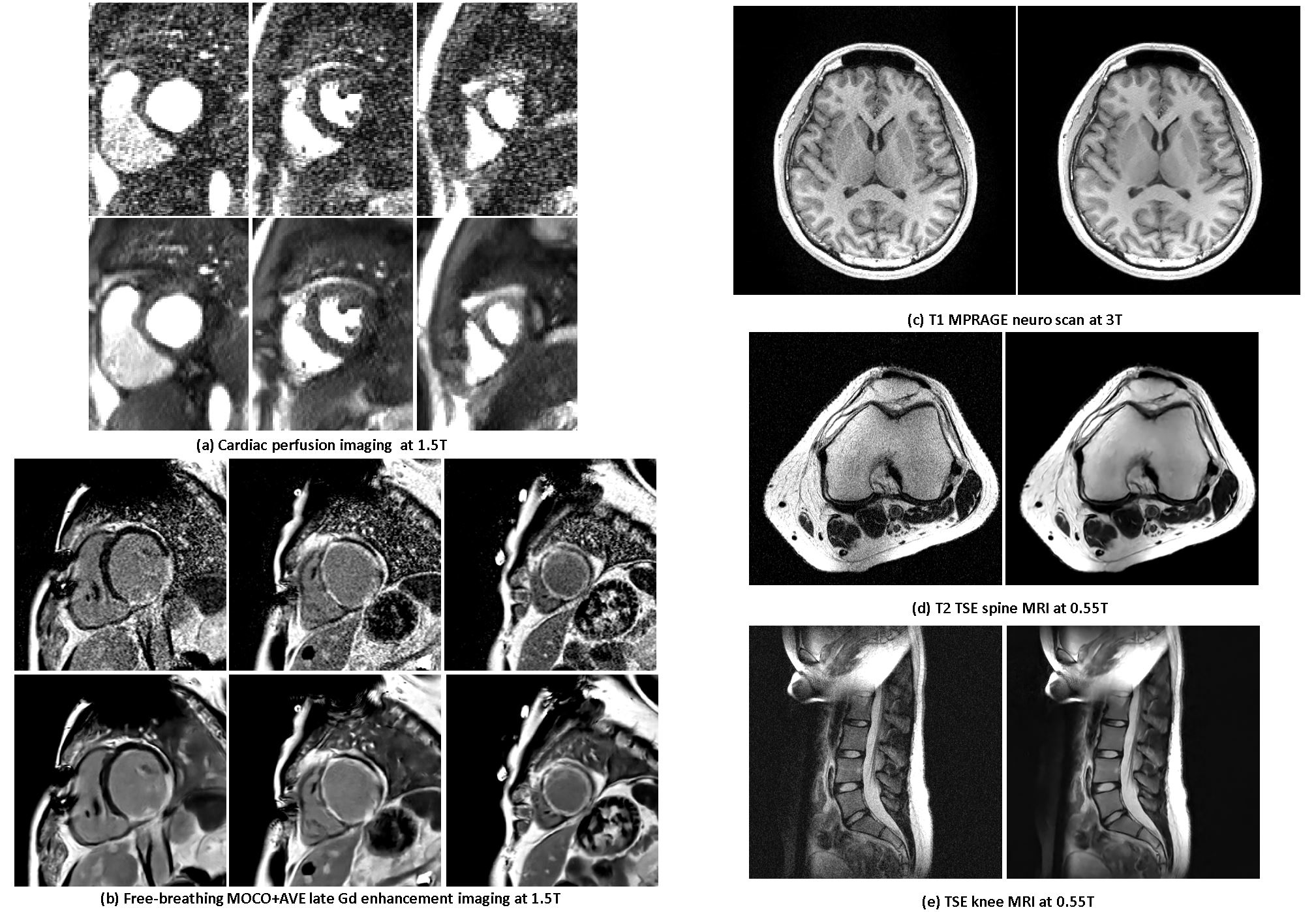
Cross imaging contrast. While training only used retro-gated cine 3T data, the model was applied to 1.5T CMR perfusion and LGE. Cross anatomy. Model was applied to three datasets (neuro 3T, spine and knee 0.55T 9) to demonstrate cross anatomy performance.
Results
Table 1 lists model comparison results. HRnet-imformer gave the best performance, but quite comparable to the Unet-imformer. Adding spatial attention and noise augmentation improved performance over using only temporal attention or not using noise augmentation. Imaging transformers outperformed CNNs. Among the convolutional models, the 3D models performed better than the 2D models.Figure 3 gives examples of 0.55T cines. Mean SNR gain for R=3 was 119-224% (90 percentiles) in the blood pool and 142-277% in the myocardium. The model was found to be locally linear (local linearity ratio7 is 0.99±0.09) and LPSF was 1.04±0.11 for readout and phase, and 1.28±0.14 for temporal direction. Due to inferior quality, the cine AI model failed at 4 subjects for the raw R=3 images but was successful after denoising using all imformer models. No significant differences were found between R=3 model outputs and R=2 images (paired t-test, P>0.15).
Figure 4 shows model generalization results on different imaging sequences (1.5T perfusion and LGE in 4a) and other anatomies (4b). While all training was performed on heart data from 3T scanners, the model generalized well.
Conclusion
We propose a denoising training scheme with SNR unit reconstruction and realistic noise augmentation, and propose novel imaging attention modules and imformers. We show their superior performance over CNNs and conventional transformers for MRI denoising tasks. Together, these contributions result in strong generalization across field-strengths, imaging sequences, contrasts, and anatomies.Acknowledgements
No acknowledgement found.References
1. Desai AD, Ozturkler BM, Sandino CM, et al. Noise2Recon: Enabling SNR-robust MRI reconstruction with semi-supervised and self-supervised learning. Magn Reson Med. 2023;90(5):2052-2070. doi:10.1002/mrm.29759
2. Kellman P, McVeigh ER. Image reconstruction in SNR units: A general method for SNR measurement. Magn Reson Med. 2005;54(6):1439-1447. doi:10.1002/mrm.20713
3. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. Lect Notes Comput Sci. 2015;9351:234-241. doi:10.1007/978-3-319-24574-4_28
4. Wang J, Sun K, Cheng T, et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans Pattern Anal Mach Intell. 2021;43(10):3349-3364. doi:10.1109/TPAMI.2020.2983686
5. Tumors B, Hatamizadeh A, Nath V, Tang Y, Yang D. Swin UNETR : Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. :1-13.
6. Liu H, Li Z, Hall D, Liang P, Ma T. Sophia : A Scalable Stochastic Second-order Optimizer for Language Model Pre-training. 2023:1-32.
7. Wech T, Stäb D, Budich JC, Köstler H. Resolution evaluation of MR images reconstructed by iterative thresholding algorithms for compressed sensing. 2012;39(7):4328-4338.
8. Davies RH, Augusto JB, Bhuva A, et al. Precision measurement of cardiac structure and function in cardiovascular magnetic resonance using machine learning. J Cardiovasc Magn Reson. 2022;24(1):1-11. doi:10.1186/s12968-022-00846-4
9. Campbell-washburn AE, Ramasawmy R, Restivo MC. Opportunities in Interventional and Diagnostic Imaging by Using High-Performance Low-Field-Strength MRI. Radiology. 2019;293(3):384-393.
10. Dosovitskiy A, Beyer L, Kolesnikov A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2020. http://arxiv.org/abs/2010.11929.
Figures