0651
Towards a Generalizable Foundation Model for Multi-Tissue Musculoskeletal MRI Segmentation1Department of Radiology and Biomedical Imaging, University of California, San Francisco, San Francisco, CA, United States, 2Department of Bioengineering, University of California, Berkeley, Berkeley, CA, United States
Synopsis
Keywords: Analysis/Processing, Bone
Motivation: To evaluate the potential of foundation models for medical imaging analysis.
Goal(s): To understand the limitations of foundation models trained for the natural imaging domain, and assess the challenges for translation to complex musculoskeletal anatomy in a rich medical image domain.
Approach: A diverse collection of musculoskeletal MRI data was used to assess the generalizability of SAM when applied to a variety of segmentation tasks common to the medical research and clinical setting.
Results: SAM performed decently on zero-shot of medical data. The ability of SAM to perform well when finetuned on a spectrum of data, is somewhat lacking and requires additional evaluation.
Impact: A foundational model for generalizable musculoskeletal MRI segmentation, such as one fine-tuned on the Segment Anything Model (SAM) has the potential to overcome challenges with generalizability for widespread usage beyond a specific task, reducing burden in medical imaging pipelines.
INTRODUCTION
In medical image processing, robust segmentation models are crucial as a typical first step in image analysis, driving imaging biomarker discovery, and prognostic tool development. While ad-hoc solutions for specific problems were proposed revolutionizing the field, lack of out of distribution generalizability make the translation of such techniques to clinical practice infeasible. Typically, segmentation models trained on a single anatomy and imaging modality perform poorly for data of additional anatomies, MRI sequences, and vendors, or derived from a suboptimal or accelerated imaging acquisition regime. In the last year, the foundation model, Segment Anything Model (SAM) [1], was proposed and showed promise in providing a general-purpose solution in natural image segmentation; however, the application of such models to medical images, particularly musculoskeletal MRI, poses unique challenges.Recent studies have investigated a range of imaging modalities such as CT and Ultrasound, as well as anatomical regions [2] but overlook the specific challenges inherent to Musculoskeletal (MSK) Magnetic Resonance Imaging and analysis. In contrast, our study stands out by offering a comprehensive evaluation of a diverse collection of segmented musculoskeletal MRI data. This dataset spans various anatomy (knee, spine, hip, thigh), MRI sequences, and quantitative maps, and encompasses data acquired with various fast-acquisition parameters. We examine the Segment Anything Model in both zero-shot and fine-tuning scenarios, aiming to evaluate its potential to increase the efficiency of research-based and clinical segmentation workflows. Our research provides valuable insights into the capabilities of a foundation model when applied to the complexity of musculoskeletal MRI.METHODS
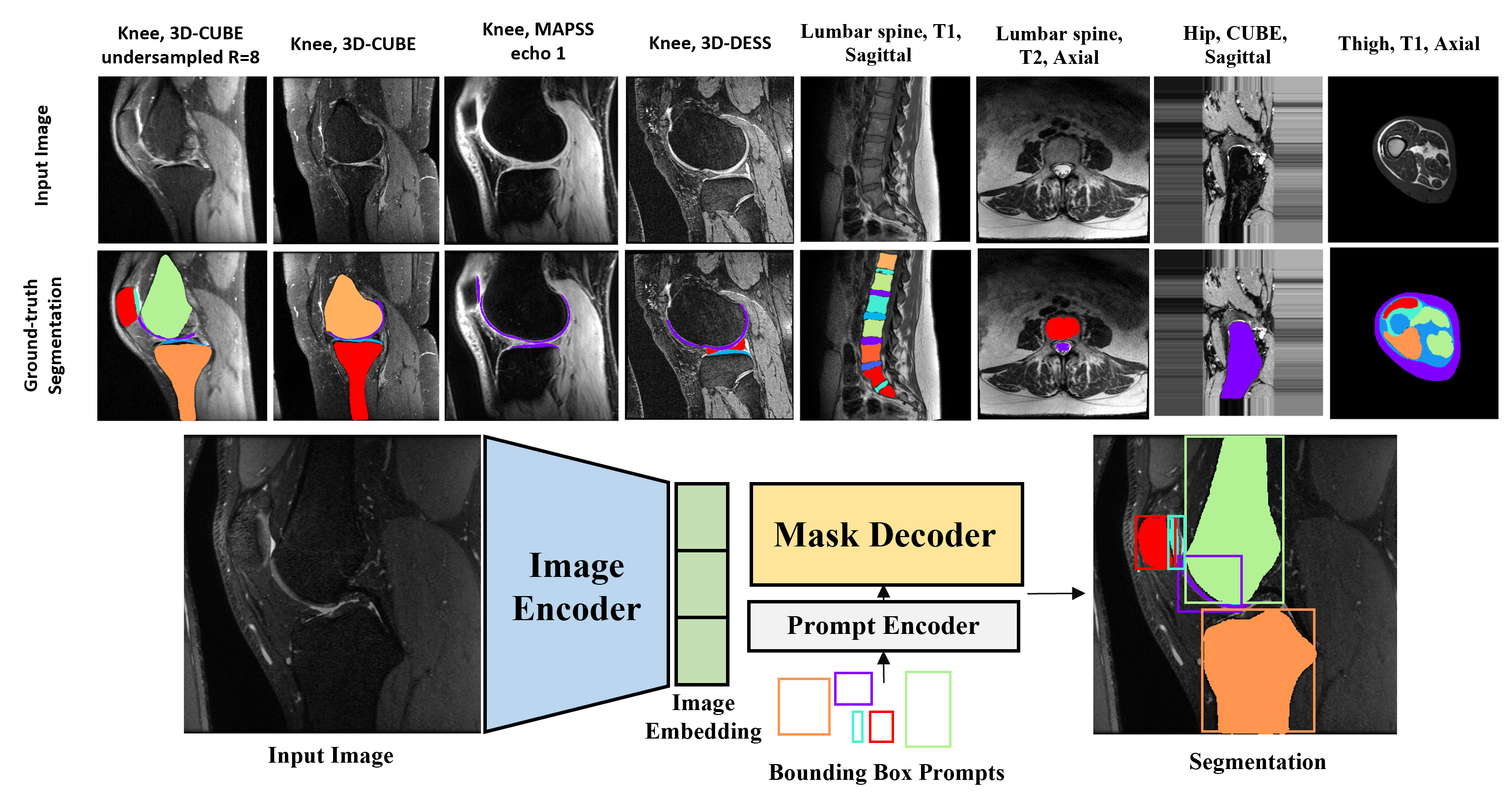
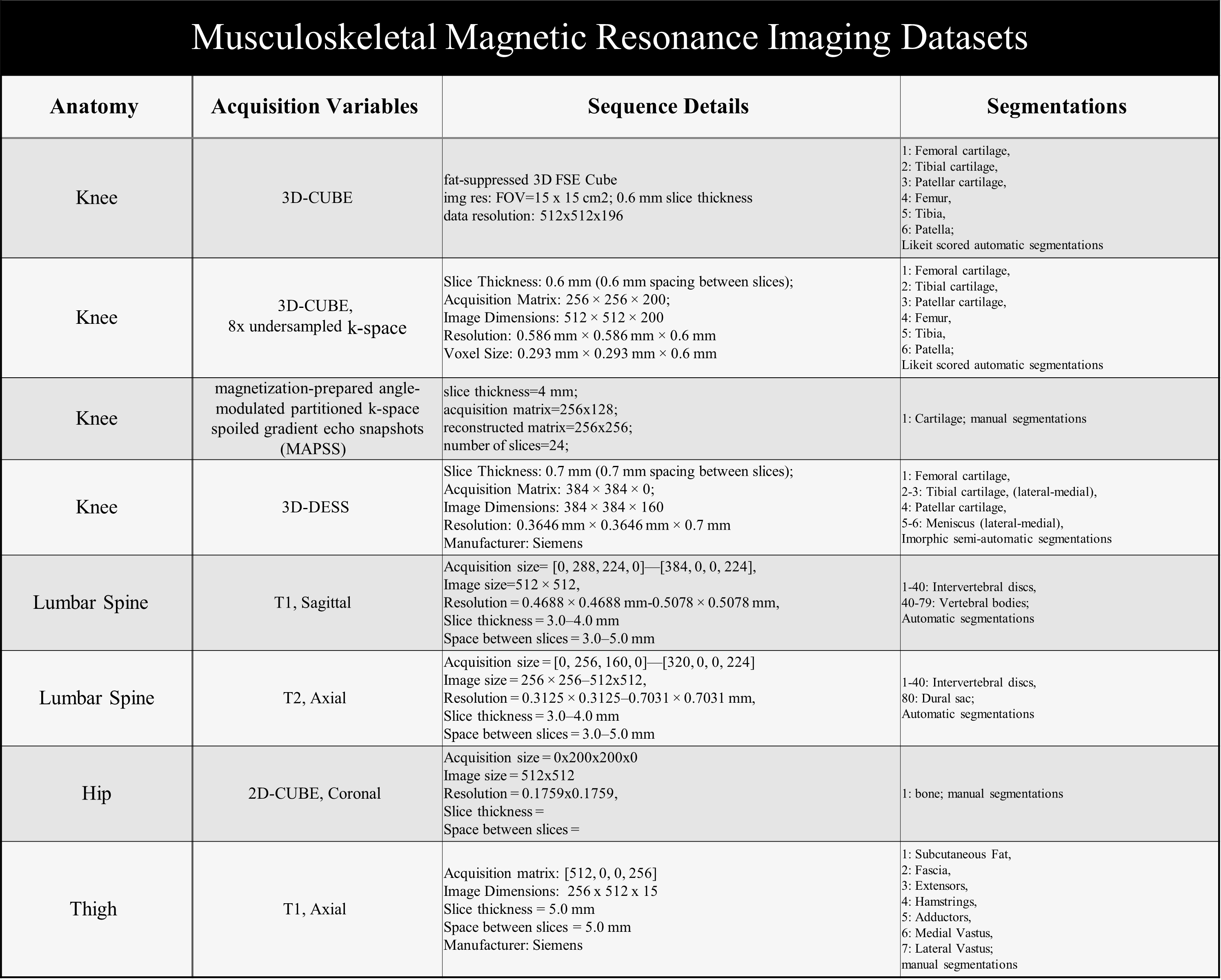
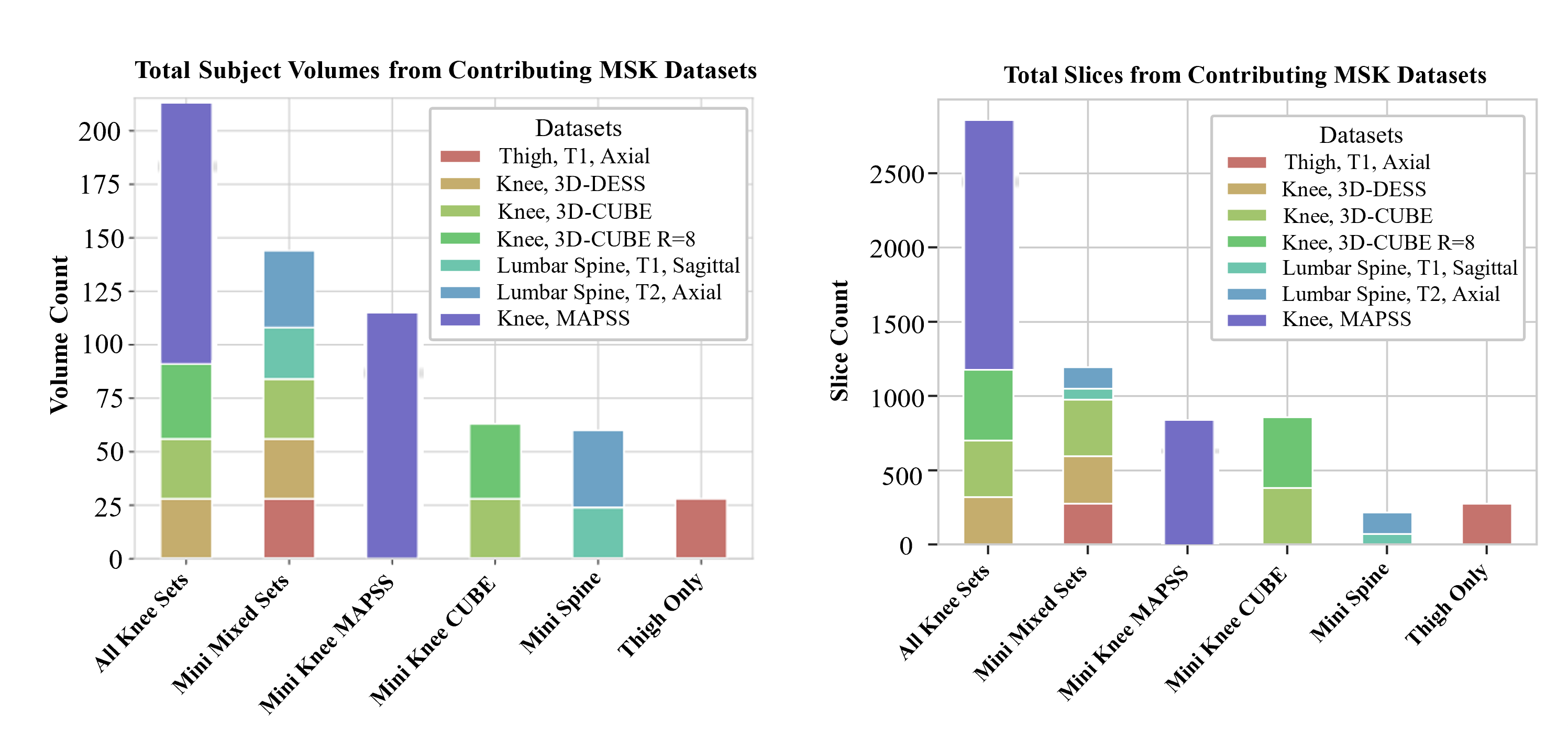
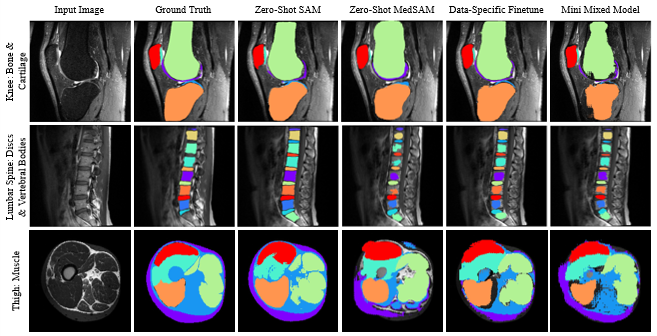
Dataset: We obtained a breadth of musculoskeletal MR images described in Table 1. Preprocessing: Subject volumes (n=40-50) obtained for each dataset, were split into train, validation, test, and inference subsets, with care taken to prevent data leakage; then standardized to 2D slice format. (Figure 3) Zero-Shot: An analysis of the zero-shot performance of baseline SAM and medical-finetuned SAM [2] was performed for each dataset; bounding boxes were calculated from the ground truth masks to focus the automatic output of the model. DICE coefficients were calculated for model evaluation. Fine-Tuning: The baseline SAM model was then fine-tuned using seven subsets of data that were selected based on criteria such as anatomy, imaging sequence, or diversity of data. In order to assess the generalizability of SAM, limited “mini” training datasets were selected to assess how quickly the model could be adopted for new tasks, and also generalize for clinical utility. Prior studies to adapt SAM for medical images consistently found bounding box prompting had the highest performance []. Similar to the zero-shot scenario, the model was prompted with bounding boxes, with positional variation introduced via random jitter. The model was optimized using a loss function, combining cross-entropy loss and DICE coefficient scores, until training saw convergence or an early stop of 35 epochs. Next, test set and inference set volumes were used to evaluate model performance; predicted segmentations were compared to ground truth using DICE coefficient scores.RESULTS:
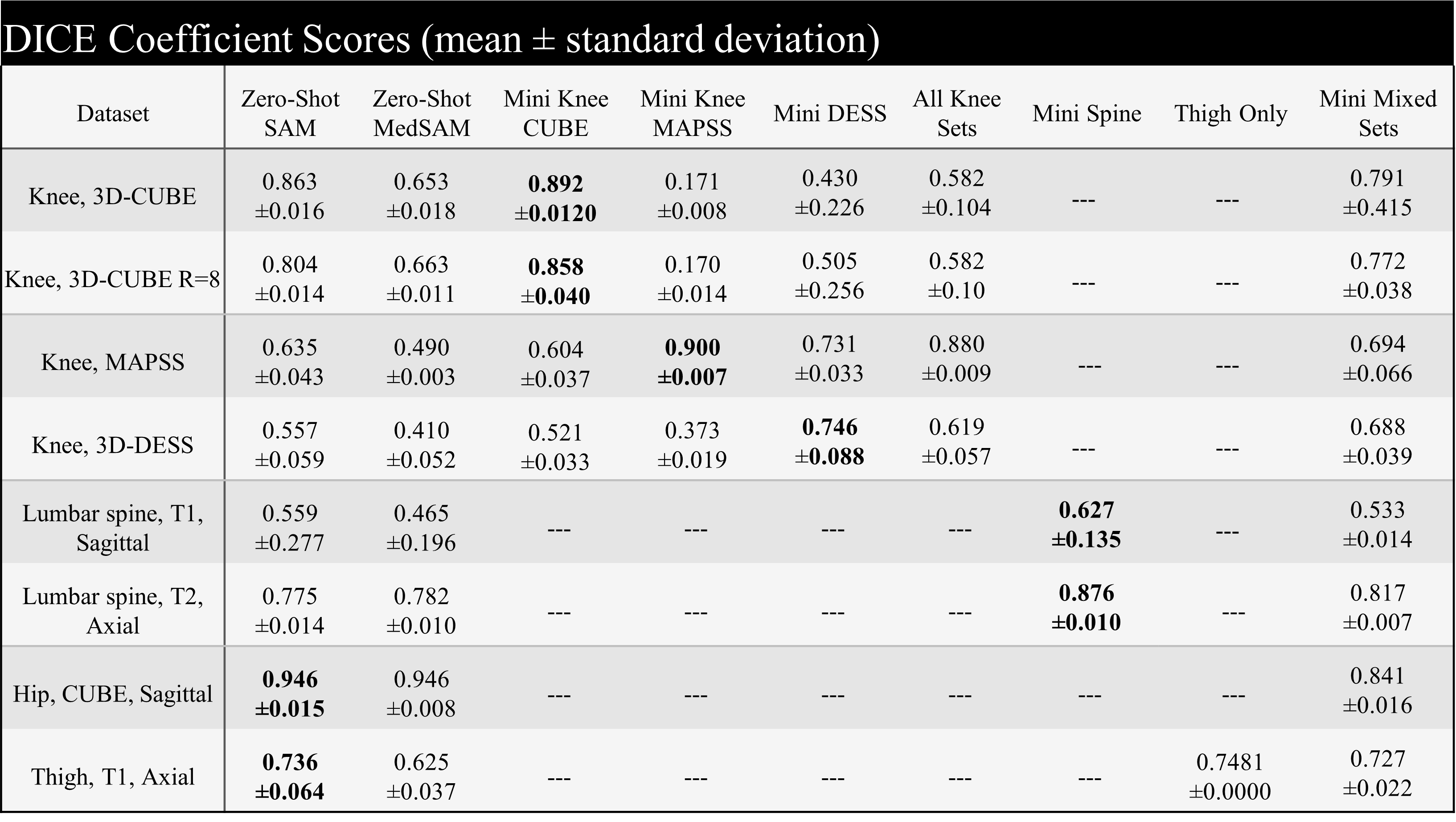
Zero-shot: Across all test datasets, SAM performed better than its medically-finetuned MedSAM by achieving higher (up to +0.210) or similar (difference of 0.007) DICE coefficients between predicted and ground truth segmentations (Table 2). SAM’s predicted segmentations were able to delineate sharp edges for tissue in the knee, spine, and thigh despite varied contrast in image intensity (Figure 2). On the other hand, MedSAM segmentations were often either overestimated presenting with smoothed edges that remove concavity in the mask as seen for the bone region of the knee. Alternatively, some masks were underestimated presenting with jagged edges as seen for intervertebral discs and vertebrae in the spine. Finetuning: Fine-tuning SAM to segment images from a given anatomy and modality improved performance by 41-3% for in-distribution data across all datasets with the exception of our thigh MRI case.DISCUSSION:
Recent advancements in deep learning, foundational models have shown greater generalizability compared to traditional, task-specific models that perform well on controlled input data. In this study, zero-shot inference with SAM had better performance of the segmentation of bone, cartilage, and other soft tissue in musculoskeletal MRI compared to MedSAM. MedSAM was pre-trained on 1 billion medical images predominantly CT, endoscopy, followed by MRI so we expected less image domain shift and higher performance. However, CT and endoscopy have higher tissue contrast and MedSAM recommends using tight bounding boxes for aided semi-automatic segmentation. MRI on the other can provide visualization of soft tissue with similar intensities.Acknowledgements
This was a lab-based efforts spanning many years.References
Kirillov, Alexander, et al. "Segment anything." arXiv preprint arXiv:2304.02643 (2023).Huang, Yuhao, et al. "Segment anything model for medical images?." arXiv preprint arXiv:2304.14660 (2023).Tolpadi, Aniket A., et al. "K2S Challenge: From Undersampled K-Space to Automatic Segmentation." Bioengineering, vol. 10, no. 2, 2023, p. 267, https://doi.org/10.3390/bioengineering10020267. Hess, Madeline, et al. "Deep Learning for Multi-Tissue Segmentation and Fully Automatic Personalized Biomechanical Models from BACPAC Clinical Lumbar Spine MRI." Pain Medicine, vol. 24, no. Supplement_1, 2023, pp. S139-S148, https://doi.org/10.1093/pm/pnac142. Accessed 8 Nov. 2023.Peake, Edward J., et al. "Ensemble learning for robust knee cartilage segmentation: data from the osteoarthritis initiative." BioRxiv (2020): 2020-09.Thahakoya R et al. Evaluating the relationship of proximal bone shape asymmetry with cartilage health and biomechanics in patients with hip OA. In Proceedings of the 31st Annual Meeting of ISMRM, Toronto, Ontario, Canada, 2023. 4373Hammernik, Kerstin, et al. "Learning a Variational Network for Reconstruction of Accelerated MRI Data." Magnetic Resonance in Medicine, vol. 79, no. 6, 2018, pp. 3055-3071, https://doi.org/10.1002/mrm.26977.Figures