0625
Rapid Pediatric Imaging with Zero-Shot Deep Subspace Reconstruction for Multiparametric Quantitative MRI1Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Boston, MA, United States, 2Department of Radiology, Harvard Medical School, Boston, MA, United States, 3Pediatric Imaging Research Center, Massachusetts General Hospital, Boston, MA, United States, 4Zhejiang University, Hangzhou, China, 5GE Healthcare, Boston, MA, United States, 6Department of Radiology, Massachusetts General Hospital, Boston, MA, United States, 7Fetal-Neonatal Neuroimaging & Developmental Science Center, Boston Children’s Hospital, Boston, MA, United States, 8Harvard/MIT Health Sciences and Technology, Cambridge, MA, United States
Synopsis
Keywords: Quantitative Imaging, Pediatric, Quantitative Imaging
Motivation: To address unmet needs for accurate, rapid, and high-fidelity quantitative MRI using a 3D-QALAS sequence.
Goal(s): To enable accurate T1 and T2 mapping with reduced biases, g-factor noise amplification, and relaxation-related blurring compared to conventional QALAS.
Approach: We employed a zero-shot self-supervised subspace reconstruction technique, Zero-DeepSub, which combines scan-specific deep-learning-based reconstruction with low-rank subspace modeling, and demonstrated the performance using ISMRM/NIST phantom and pediatric patients.
Results: Zero-DeepSub enabled a highly accelerated, 2 min acquisition at 1 mm isotropic resolution at 3T, as well as a 5 min pediatric exam at 1.2 mm isotropic resolution at 1.5T.
Impact: Zero-DeepSub enabled accurate T1 and T2 mapping with reduced biases, g-factor noise amplification, and relaxation-related blurring, showing the potential to substantially speed up pediatric brain exams, thus obviating the need for or reducing the amount of sedation and anesthesia.
Introduction
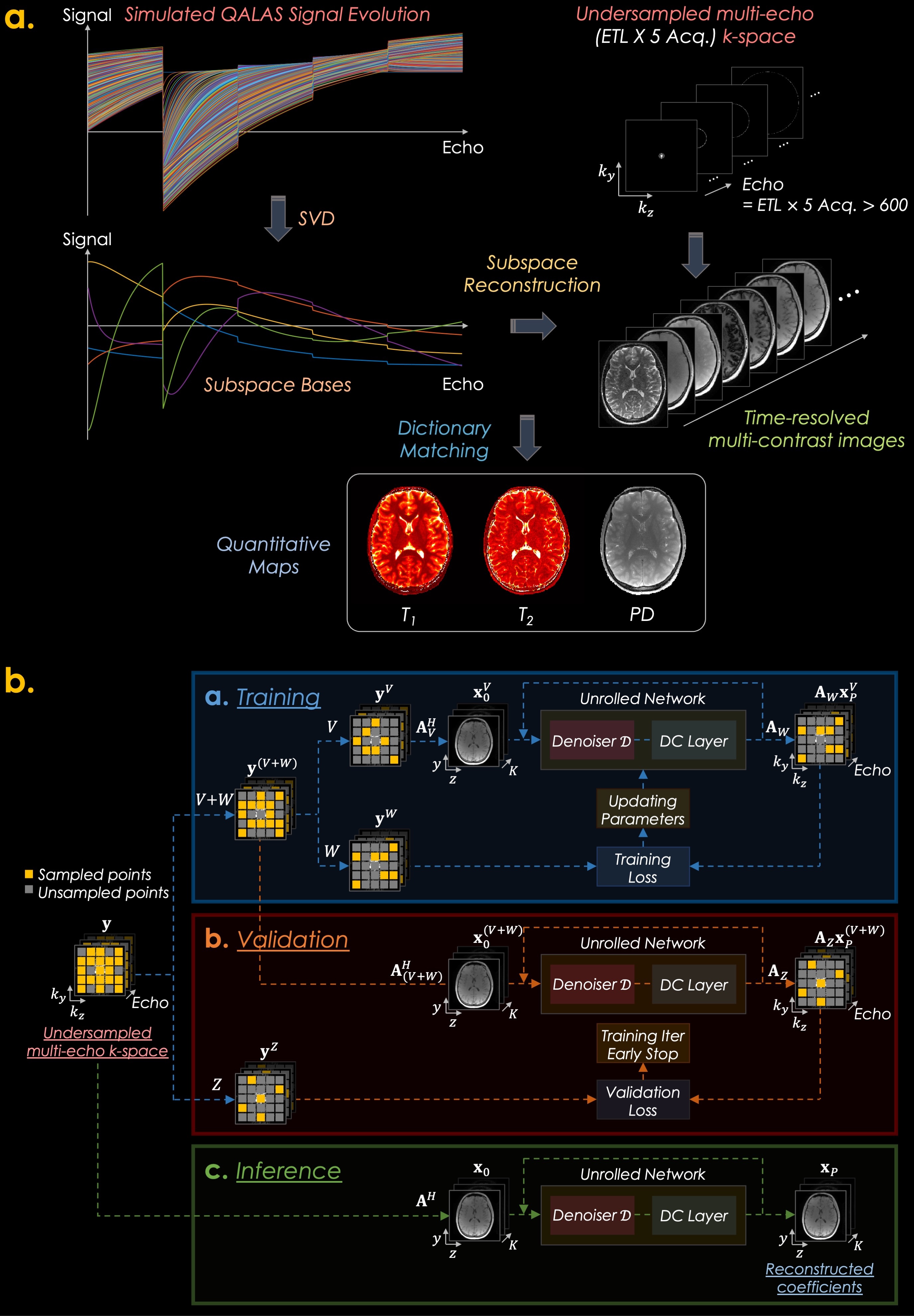
Low-rank subspace and shuffling have emerged as powerful methods for reconstructing time-resolved images and qMRI since they incorporate subspace bases calculated from Bloch equations1–4. The 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS), which has five FLASH readouts within each QALAS block, enables high-resolution T1, T2, and proton density (PD) mapping5–8. However, conventional QALAS inherently assumes that the entire k-space for each acquisition is acquired instantly at the first echo that samples the center of the k-space. This assumption neglects T1 relaxation during the lengthy FLASH echo train, which causes blurring and biases9 in the T1 and T2 maps.To address these drawbacks, we reconstruct QALAS time-series data using a low-rank subspace reconstruction (subspace QALAS) along with zero-shot self-supervised learning-based regularization10,11 (Zero-DeepSub), thus enabling accurate T1 and T2 mapping with reduced biases, g-factor noise amplification, and relaxation-related blurring compared to conventional QALAS. The overall scheme is presented in Fig. 1.
Methods
We employ zero-shot self-supervised learning10 for subspace reconstruction with deep-learning-based regularization as follows:$$\min_{\bf{x}}{\big\|{\bf{y}}-{\bf{Ax}}\big\|^2_2}+\lambda\left\|{\bf{x}}-\mathcal{D}({\bf{x}};\boldsymbol{\theta})\right\|^{2}_{2},$$
with the forward operator $$${\bf{A}}$$$:
$${\bf{A}}={\bf{M}}{\bf{F}}{\bf{C}}{\bf{\Phi}}_{K}:{\mathbb{C}}^{NK}\to{\mathbb{C}}^{NTL},$$
where $$${\bf{y}}\in{\mathbb{C}}^{NTL}$$$ is the k-space data, which has been decomposed across the echo train length (ETL) index ($$$T=\text{ETL}\times5$$$) on $$$k_{y}-k_{z}$$$ plane from the original k-space. $$${\bf{x}}\in{\mathbb{C}}^{NK}$$$ are the desired subspace coefficients, and $$$\bf{A}$$$ contains a sampling matrix $$${\bf{M}}\in{\mathbb{R}}^{{NTL}\times{NTL}}$$$, Fourier transform $$${\bf{F}}\in{\mathbb{C}}^{{NTL}\times{NTL}}$$$, sensitivity maps $$${\bf{C}}\in{\mathbb{C}}^{{NTL}\times{NT}}$$$, and subspace basis $$$\Phi_{K}\in{\mathbb{R}}^{{NT}\times{NK}}$$$. $$$N$$$ and $$$L$$$ are the matrix size and the number of coils. $$$\mathcal{D}(\cdot;\boldsymbol{\theta})$$$ is a deep-learning-based denoiser with trainable parameters $$$\boldsymbol{\theta}$$$.
Zero-DeepSub is designed based on a deep model-based framework (12), which has five convolutional neural network (CNN) blocks where each block consists of a 3x3 convolutional layers with 128 feature maps, batch normalization layer, and leaky ReLU. The $$$\lambda$$$ was initialized as 0.005. The model was implemented using TensorFlow and whole-brain training took 4h using a NVIDIA Tesla V100 GPU.
Experiments
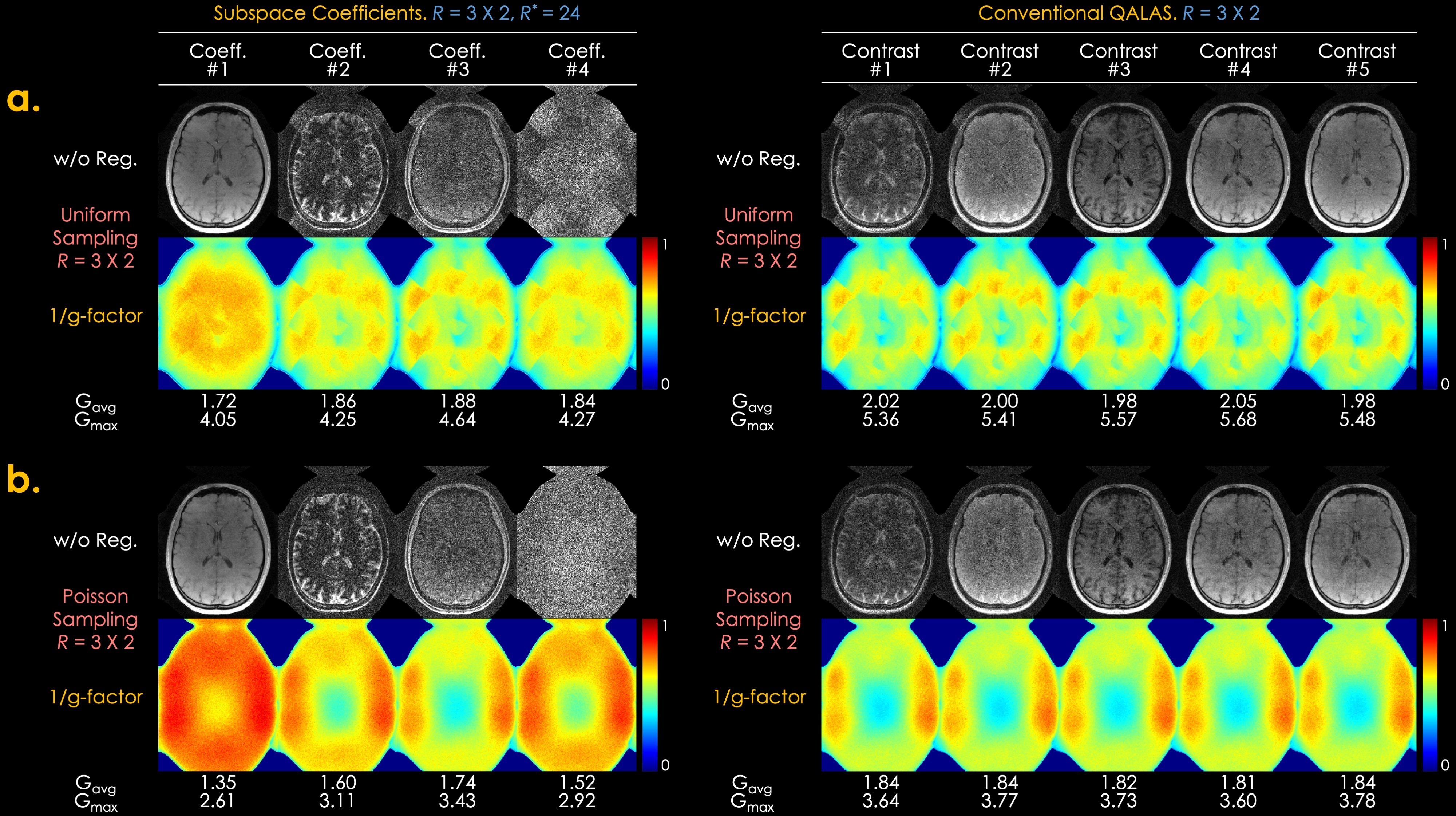
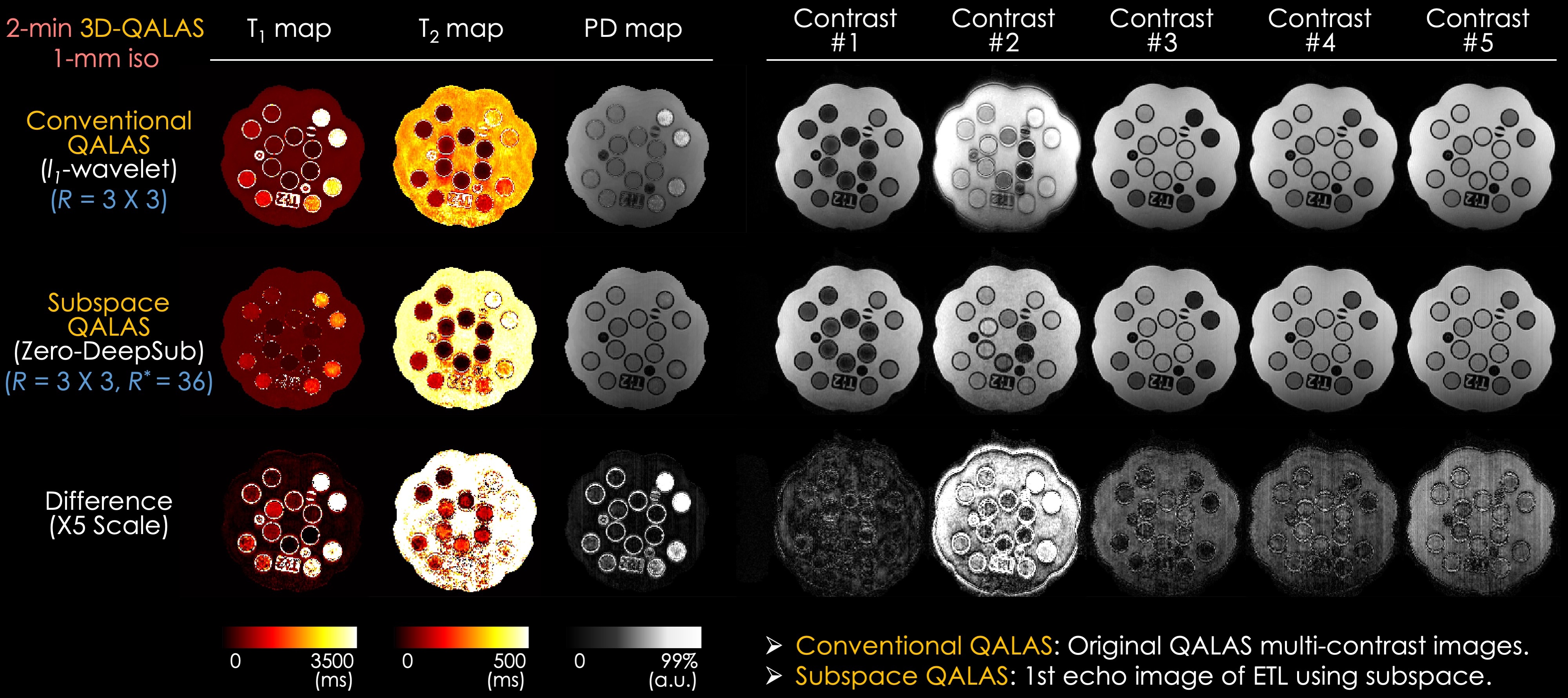
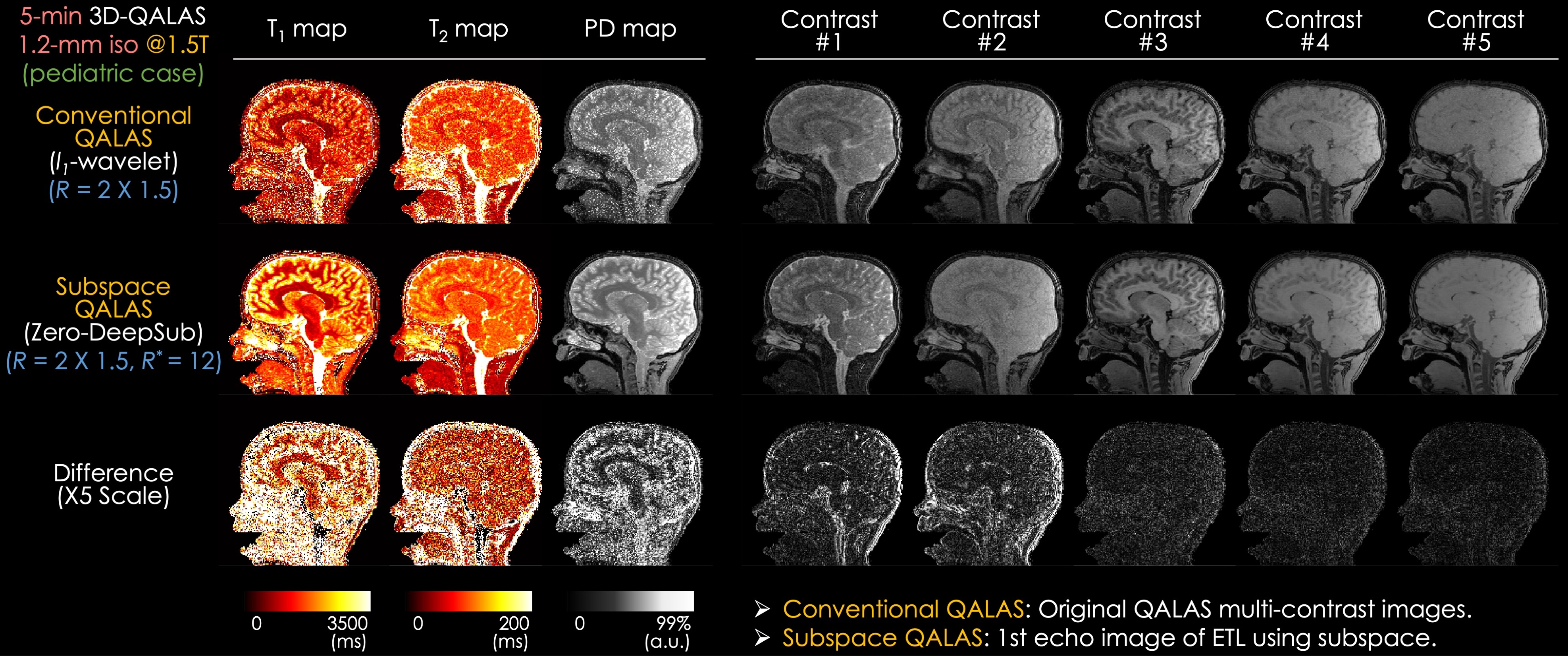
Acquisition @3T: We acquired data from a volunteer on a 3T Siemens Prisma with a 32ch head array. The parameters are: FOV=224x224x176mm3, matrix size=224x224x176, BW=330Hz/pixel, echo spacing=5.9ms, turbo factor=124, TR=4.5s, TE=2.36ms, acceleration R=3x2 using random and Poisson sampling patterns. With a similar protocol, an ISMRM/NIST system phantom was scanned at 1 mm isotropic resolution at R=3x3.Acquisition @1.5T: To demonstrate the applicability of the developed technology, five pediatric subjects were scanned on a 1.5T GE Artist with an 18ch head array. To account for the differences in intrinsic SNR, the resolution was reduced to 1.2 mm isotropic, whereas the acceleration was kept at R=2x1.5 to limit the scan time to 5 min.
Results
Fig. 2 shows a g-factor analysis of conventional and subspace 3D-QALAS. The best results are obtained using subspace reconstruction with a Poisson sampling pattern, where an average g-factor of Gavg=1.35 and maximum g-factor of Gmax=2.61 are obtained for the first subspace basis. These represent a 1.4-fold improvement in both Gavg and Gmax compared to conventional QALAS, i.e., an SNR gain of almost 2 signal averages.Fig. 3 demonstrates the results of the ISMRM/NIST phantom. The relaxation-related blurring is particularly evident in the second contrast of conventional QALAS, which has been largely mitigated in the second contrast synthesized from the subspace bases in Zero-DeepSub. The biases in the conventional reconstruction manifest as overestimation in T1 and underestimation in T2.
Fig. 4 presents in vivo results on a pediatric patient (5-year-old). Zero-DeepSub had reduced noise and relaxation-related blurring, especially in the first and second contrasts. The reconstructed maps showed that Zero-DeepSub significantly reduced noise and artifacts compared to conventional QALAS. In particular, conventional QALAS showed underestimated T1 values compared to Zero-DeepSub, where the biases may come from the imperfect assumption neglecting T1 relaxation during the lengthy FLASH echo train.
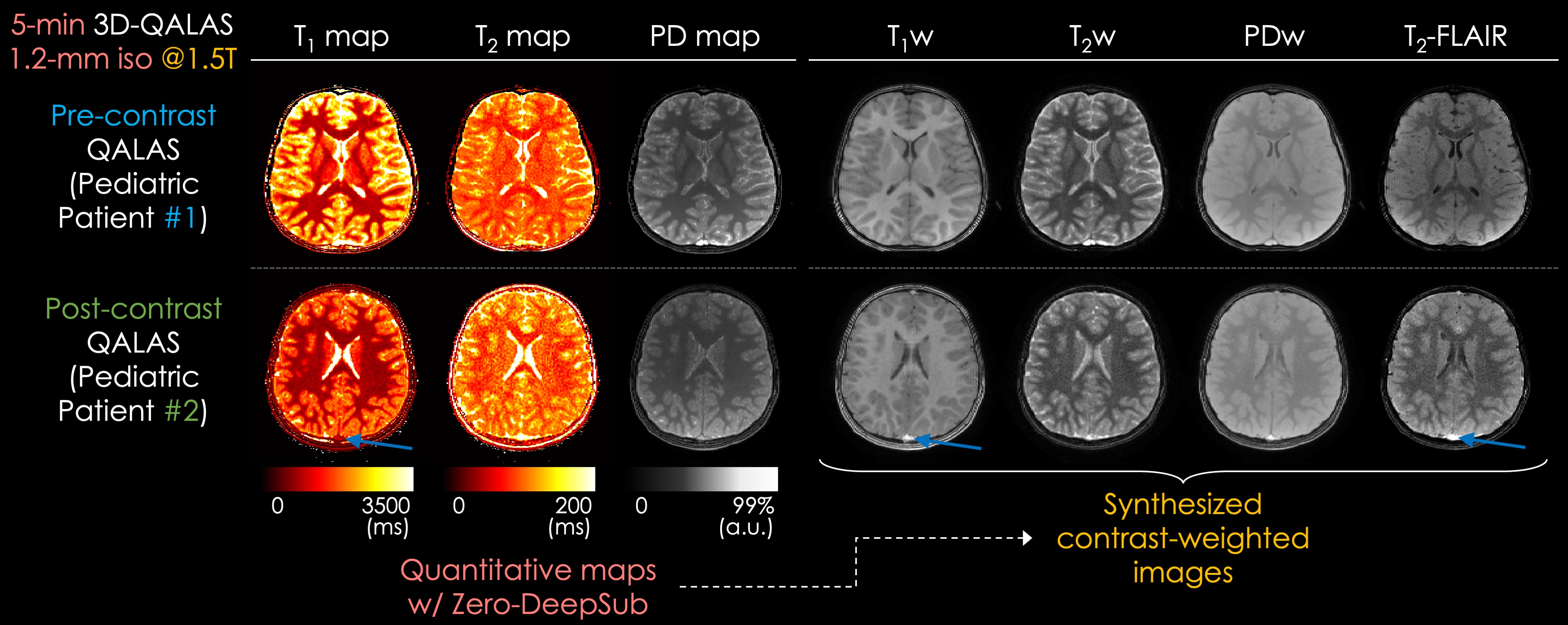
In Fig. 5, parameter maps and synthetic contrast-weighted images are depicted. High fidelity is observed in the generated contrast-weighted images from these two pediatric subjects (5-year-old and 7-year-old, respectively); however, the SNR of the T2w and FLAIR images could be further improved. A minor aliasing artifact was observed in the T1w contrast in subject #2, which may stem from the limited encoding ability of the 18ch array.
Discussion and Conclusion
We demonstrated that accurate T1 and T2 maps with reduced blurring can be obtained with 3D-QALAS using Zero-DeepSub. These maps lent themselves to the generation of contrast-weighted images with high fidelity, with the potential to substantially reduce the duration of pediatric brain exams, thus obviating the need for sedation and anesthesia. Moreover, the results demonstrated that post-contrast contrast-weighted images can be obtained from quantitative maps, showing the potential to be used in place of acquiring additional clinical post-contrast images.Acknowledgements
This work was supported by research grants NIH R01 EB032378, R01 EB028797, R03 EB031175, UG3 EB034875, P41 EB030006, U01 EB026996, U24 NS135561, R01 MH132610 and the NVIDIA Corporation for computing support.References
1. Tamir JI, Uecker M, Chen W, et al. T2 shuffling: Sharp, multicontrast, volumetric fast spin-echo imaging. Magn. Reson. Med. 2017;77:180–195.
2. Zhao B, Setsompop K, Adalsteinsson E, et al. Improved magnetic resonance fingerprinting reconstruction with low-rank and subspace modeling. Magn. Reson. Med. 2018;79:933–942.
3. Wang F, Dong Z, Reese TG, et al. Echo planar time-resolved imaging (EPTI). Magn. Reson. Med. 2019;81:3599–3615.
4. Christodoulou AG, Shaw JL, Nguyen C, et al. Magnetic resonance multitasking for motion-resolved quantitative cardiovascular imaging. Nat Biomed Eng 2018;2:215–226.
5. Kvernby S, Warntjes MJB, Haraldsson H, Carlhäll C-J, Engvall J, Ebbers T. Simultaneous three-dimensional myocardial T1 and T2 mapping in one breath hold with 3D-QALAS. J. Cardiovasc. Magn. Reson. 2014;16:102.
6. Kvernby S, Warntjes M, Engvall J, Carlhäll C-J, Ebbers T. Clinical feasibility of 3D-QALAS - Single breath-hold 3D myocardial T1- and T2-mapping. Magn. Reson. Imaging 2017;38:13–20.
7. Fujita S, Hagiwara A, Takei N, et al. Accelerated Isotropic Multiparametric Imaging by High Spatial Resolution 3D-QALAS With Compressed Sensing: A Phantom, Volunteer, and Patient Study. Invest. Radiol. 2021;56:292–300.
8. Fujita S, Hagiwara A, Hori M, et al. Three-dimensional high-resolution simultaneous quantitative mapping of the whole brain with 3D-QALAS: An accuracy and repeatability study. Magn. Reson. Imaging 2019;63:235–243.
9. Zhu D, Qin Q. A revisit of the k-space filtering effects of magnetization-prepared 3D FLASH and balanced SSFP acquisitions: Analytical characterization of the point spread functions. Magn. Reson. Imaging 2022;88:76–88.
10. Yaman B, Hosseini SAH, Akcakaya M. Zero-Shot Self-Supervised Learning for MRI Reconstruction. In: International Conference on Learning Representations. ; 2021.
11. Yaman B, Hosseini SAH, Moeller S, Ellermann J, Uğurbil K, Akçakaya M. Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data. Magn. Reson. Med. 2020;84:3172–3191.
12. Aggarwal HK, Mani MP, Jacob M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans. Med. Imaging 2019;38:394–405.
Figures