0623
Accelerating Quantitative MRI using Self-supervised Deep Learning with Model Reinforcement1Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Charlestown, MA, United States, 2Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Quantitative Imaging, Quantitative Imaging, Model-based Reconstruction, Relaxometry, Brain, Self-supervised Learning
Motivation: Quantitative MRI (qMRI) is time-consuming and requires substantial efforts for acceleration to cut down the acquisition time.
Goal(s): This paper proposes a novel self-supervised learning framework that uses model reinforcement, RELAX-MORE, for accelerated qMRI reconstruction.
Approach: The proposed method uses an optimization algorithm to unroll an iterative model-based qMRI reconstruction into a deep learning framework, enabling accelerated MR parameter maps that are highly accurate and robust.
Results: The proposed method generates high quality MR parameter maps that correct for image artifacts, removes noise, and recovers image features in regions of imperfect image conditions.
Impact: This work demonstrates the feasibility of a new self-supervised learning method for rapid MR parameter mapping, that is readily adaptable to the clinical translation of qMRI.
INTRODUCTION
Despite recent advances in deep learning MRI reconstruction [1], several challenges remain, including limited training data access. Acquiring fully sampled k-space data can be time-consuming and expensive, and the data collection challenge for quantitative MRI is even more pronounced [2]. This paper proposes a new deep learning method for qMRI reconstruction by marrying self-supervised learning and an optimization algorithm to unroll the learning process. This proposed method is called REference-free LAtent map eXtraction with MOdel REinforcement (RELAX-MORE), which jointly enforces the optimization and MR physics models for rapid MR parameter mapping. RELAX-MORE aims to enable efficient, accurate, and robust MR parameter estimation while achieving subject-specific learning, featuring training on single-subject data for further addressing the data limitation.THEORY
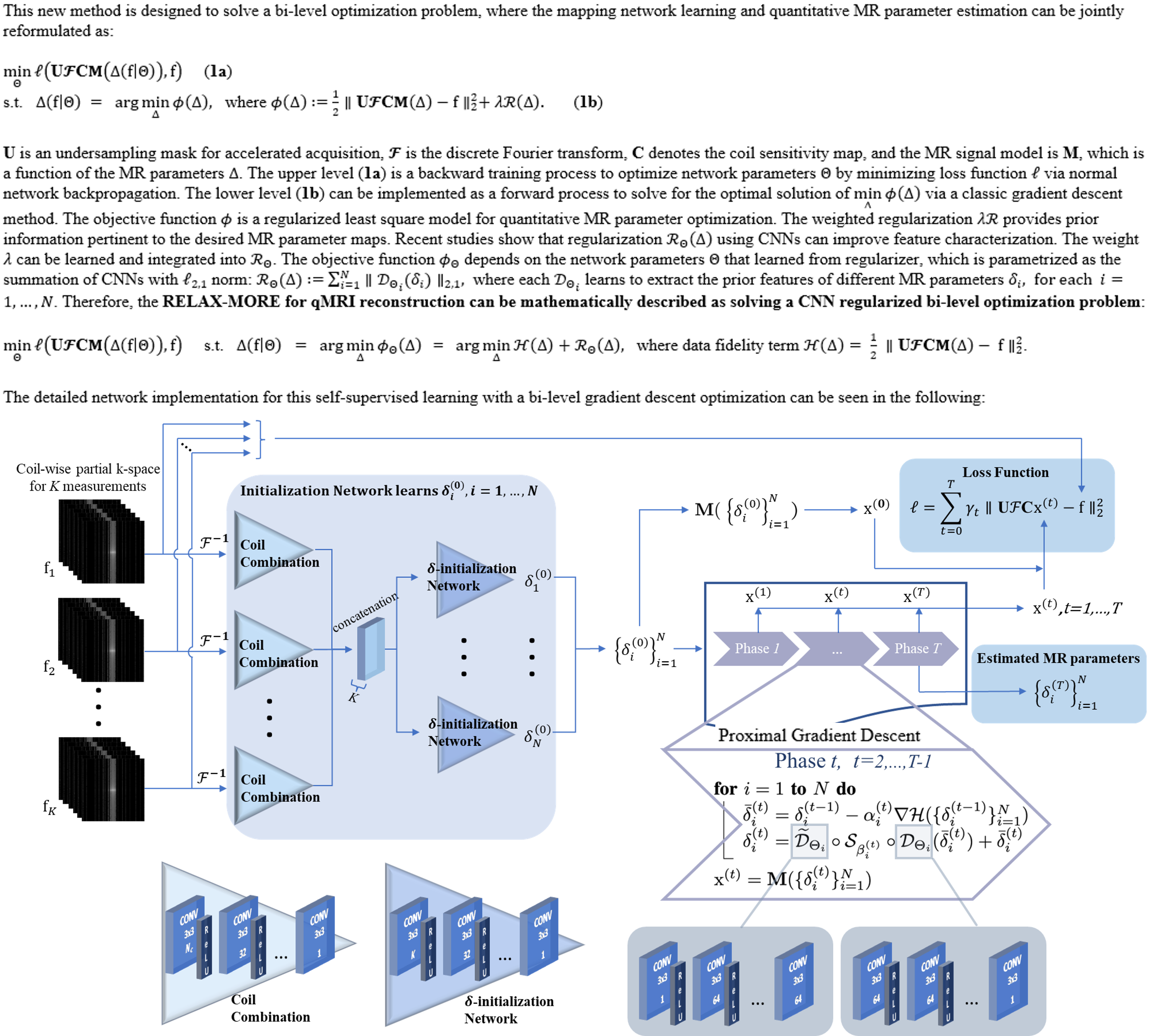
Self-supervised learning methods involve training a model to learn the properties and features of the input data through self-instruction. The proposed RELAX-More considers unrolling a self-supervised learning network using a bi-level optimization algorithm, where the network learning and quantitative MR parameter estimation can be jointly reformulated mathematically. The upper level is a backward training process to optimize network parameters $$$\Theta$$$ by minimizing loss function $$$\ell$$$ via normal network backpropagation. The lower level can be implemented as a forward process to solve for the optimal solution of $$$\min\limits_{\Delta}\phi(\Delta)$$$ via a classic gradient descent method. The detailed framework of the proposed RELAX-MORE is illustrated in Fig. 1. As a result, RELAX-More can handle complicated artifact removal, noise suppression, and contrast conversion through deep learning meanwhile maintaining subject-specific adaptation for individual datasets.METHODS
To investigate the feasibility of RELAX-MORE method for reconstructing accelerated qMRI, we used the widely studied T1 mapping through the vFA method [3] as an example. Herein, the MR signal model $$$\mathbf{M}$$$ can be expressed as: $$${\rm \mathbf{M}}(\mathbf{T_1,I_0})=\mathbf{I_0}\cdot\frac{(1-e^{-TR/\mathbf{T_1}})sin\eta_k}{1-e^{-TR/\mathbf{T_1}}cos\eta_k}$$$ where several MR images are acquired at multiple flip angles $$$\eta_k$$$ for $$$k$$$ = $$$1,…,N_k$$$. The $$$\mathbf{T_1,I_0}$$$ are the spin-lattice relaxation time map and proton density map, respectively. The set of MR parameters estimated in this model are $$$\Delta=\{\mathbf{T_1,I_0}\}$$$. Experiments: The experiments include in-vivo studies on the brain and knee of healthy volunteers and ex-vivo phantom studies, all of which were carried out on a Siemens 3T Prisma scanner. The vFA on the brain of five subjects was performed using an SPGR sequence at imaging parameters TE/TR = 12/40 ms, FA = 5, 10, 20, 40 degrees, matrix size = 176x176x48 with a dedicated 20-channel head coil. The vFA on one knee was performed using a 4-channel receiving-only flex coil with similar imaging parameters and matrix size 224x192x36. The vFA phantom data was acquired along the coronal plane with similar parameters and matrix size 128x128x12 using the 20-channel head coil. The fully acquired MRI k-space data were undersampled retrospectively using 1) 1D Cartesian variable density undersampling at acceleration factor AF= 3x and 2) 2D Poisson disk undersampling at AF= 4x. RELAX-MORE was compared with two state-of-the-art non-deep learning qMRI reconstruction methods (Locally Low Rank (LLR) [4] and Model-TGV [5]) and one self-supervised deep learning method (RELAX [6]). It should be noted that, unlike conventional deep learning reconstruction methods where training and testing are two separate steps, in RELAX-MORE with subject-specific self-supervised learning, the reconstruction has readily concluded once the training has converged for one subject.RESULTS AND DISCUSSION
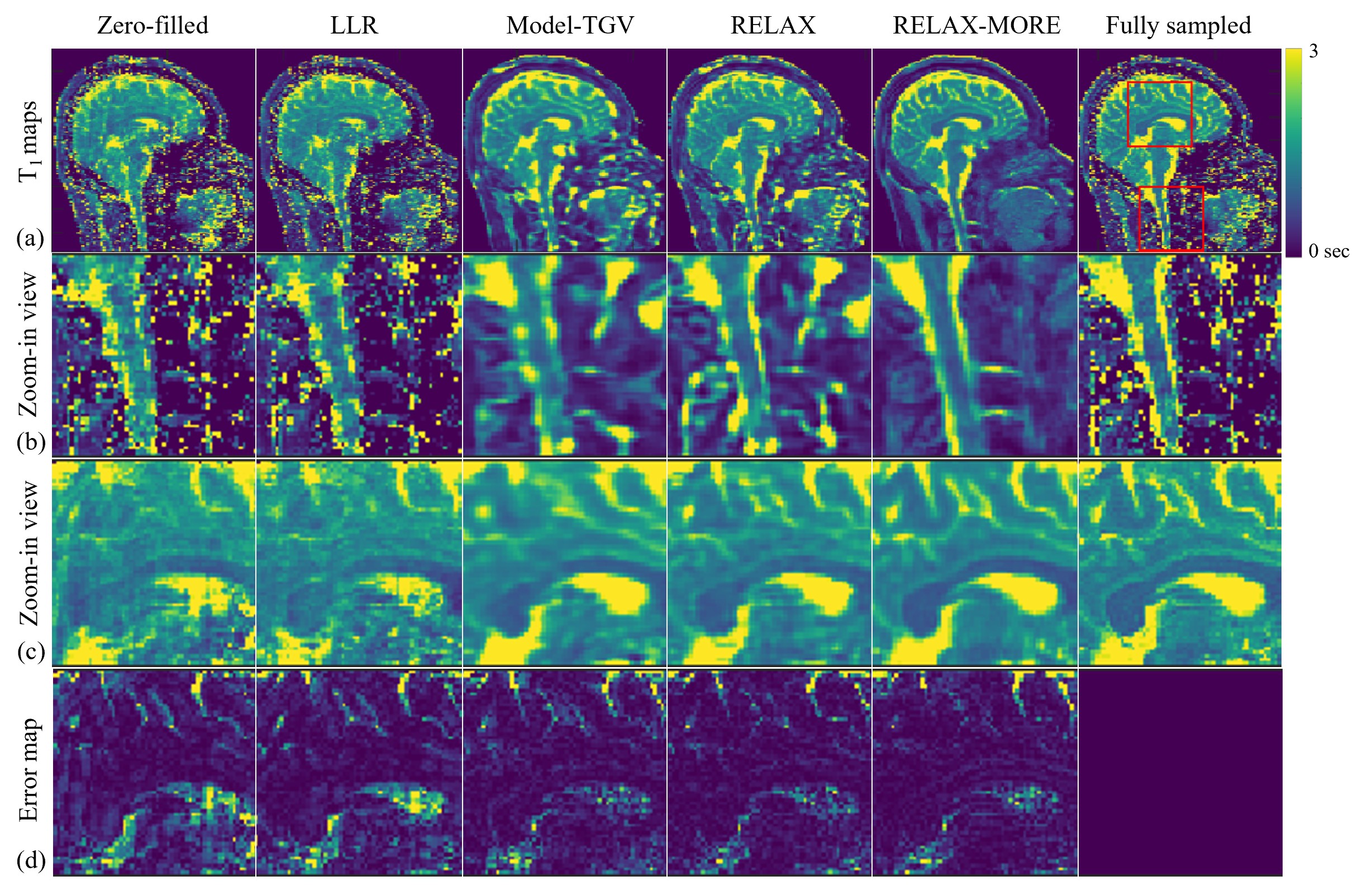
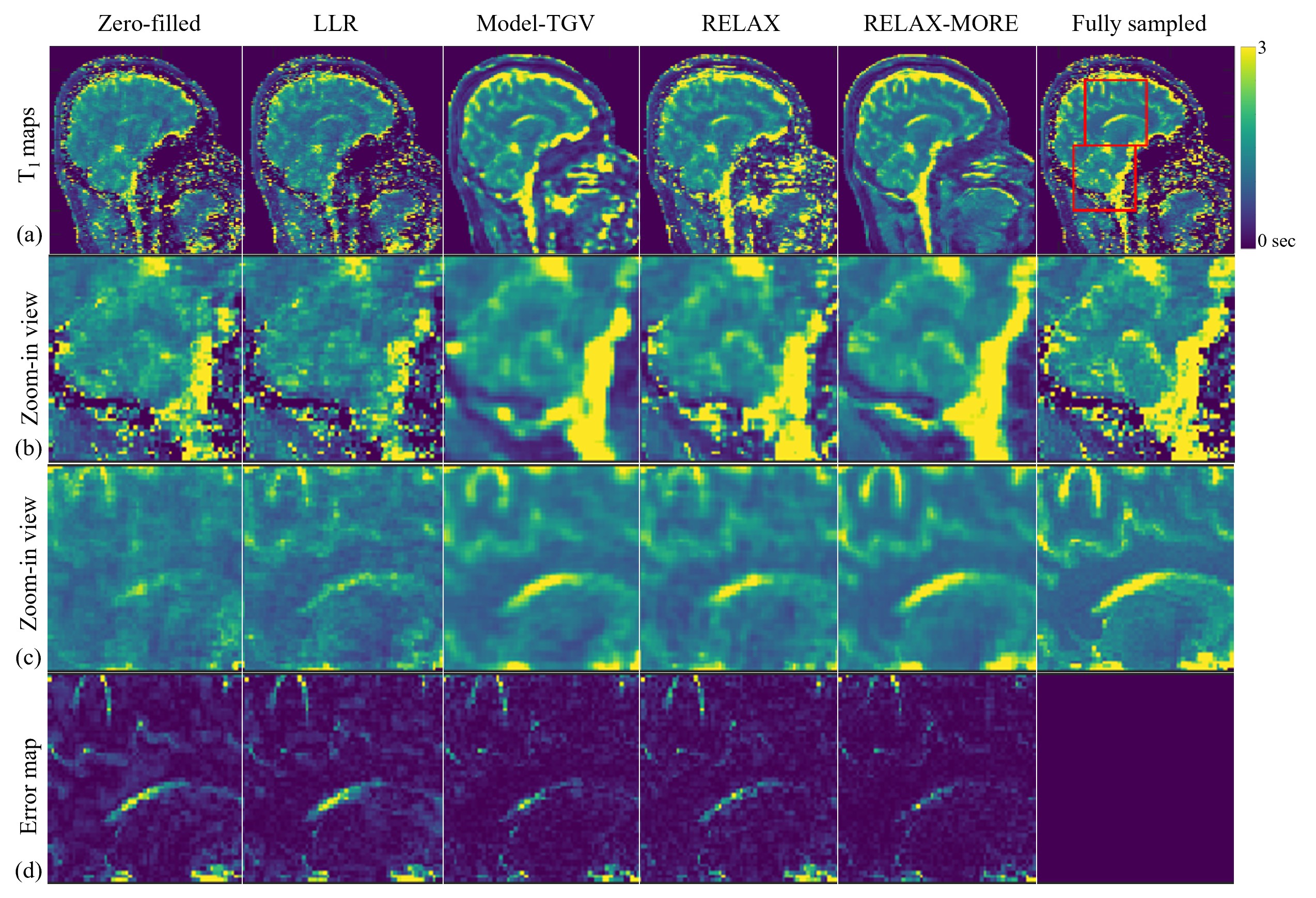
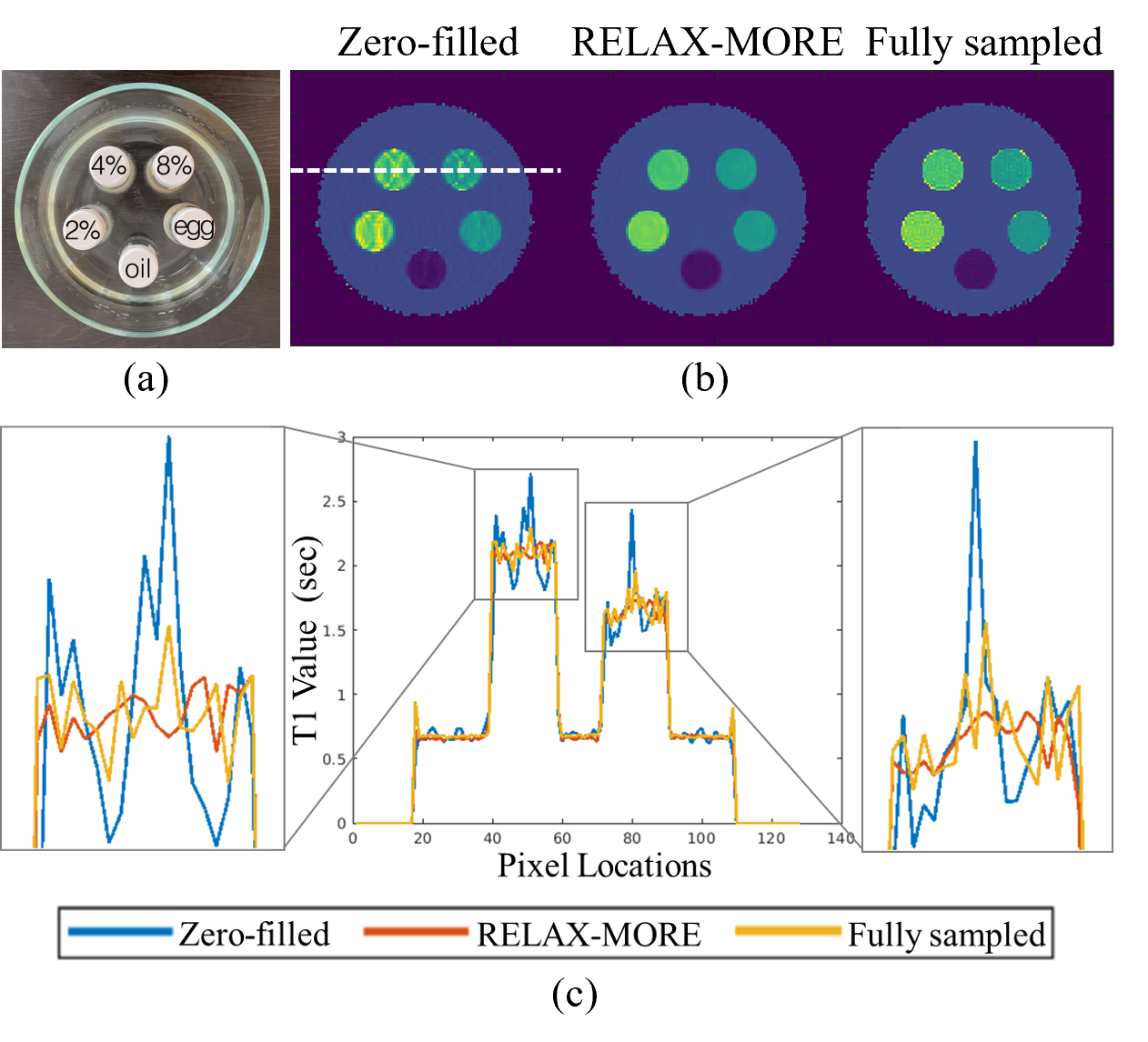
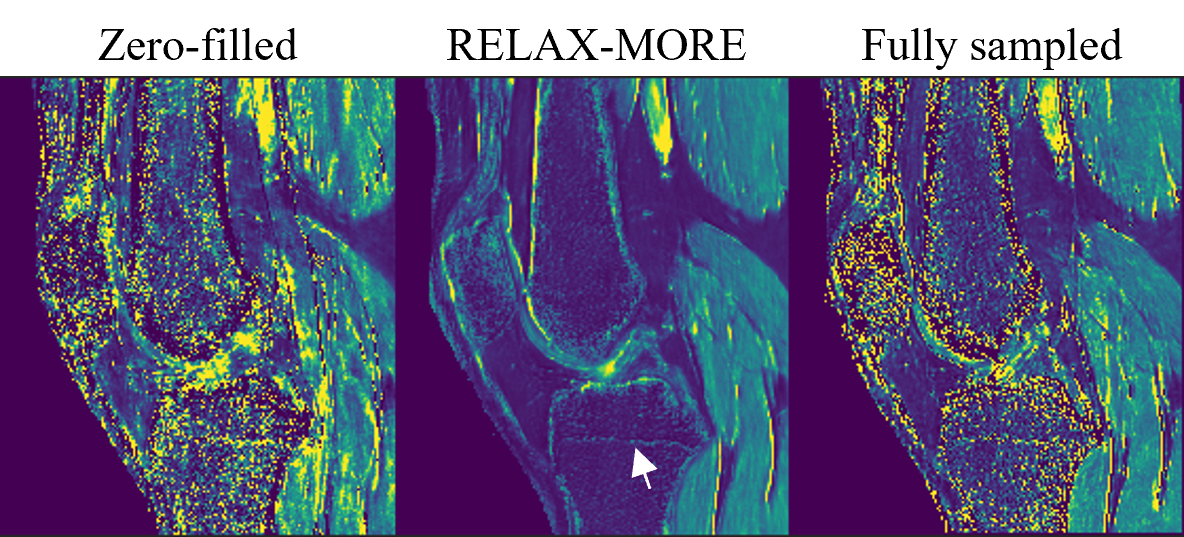
Fig. 2 shows T1 maps obtained from 3x 1D Cartesian variable density undersampling using different methods. RELAX-MORE produces artifact-free T1 maps with excellent performance for noise removal. It maintains contrast and tissue details in low SNR regions. Fig. 3 displays the T1 maps estimated from 4x 2D Poisson disk undersampling. Compared to the 3x 1D undersampling case, the overall differences are similar. RELAX-MORE can distinguish between WM and GM T1 of the cerebellum, showing the least error. The parameter estimation accuracy of the proposed method was tested using undersampled data from a phantom composed of five 20mL vials consisting of peanut oil and 2%, 4%, 8% agar dissolved in DI water and boiled egg white. The results in Fig. 4 show that RELAX-MORE eliminates ripple artifacts and averages out noise while maintaining high accuracy for parameter estimation in phantoms. The result in Fig. 5 shows that RELAX-MORE successfully removes artifacts, suppresses image noise, and provides favorable quantification of different knee joint structures.CONCLUSION
This paper presents a self-supervised learning technique called RELAX-MORE for qMRI reconstruction. It uses an optimization algorithm to unroll model-based qMRI reconstruction into a deep learning framework, allowing for high accuracy and robust MR parameter maps at imaging acceleration. Unlike traditional deep learning methods, RELAX-MORE can be trained on single-subject data and outperforms state-of-the-art methods in accuracy and efficiency.Acknowledgements
We thank the funding support from NIBIB R21EB031185, NIAMS R01AR079442, and R01AR081344.References
[1] Knoll, F., Investigative Radiology, 2020, 55(9), 632-653. [2] Zhu, Y., IEEE Signal Processing Magazine, 2023, 40(2), 116-128, [3] Fram, E. K., Magnetic resonance imaging, 1987, 5(3), 201-208. [4] Zhang, T., Magnetic resonance in medicine, 2015, 73(2), 655-661. [5] Maier, O., Magnetic resonance in medicine, 2019, 81(3), 2072-2089. [6] Liu, F., Magnetic resonance in medicine, 2021, 85(6), 3211-3226.Figures