0574
Comparison of ground-truth-free deep learning approaches for accelerated quantitative parameter mapping1Graduate School of Science and Technology, University of Tsukuba, Tsukuba, Japan, 2Medical Systems Research & Development Center, FUJIFILM Corporation, Minato-ku, Japan
Synopsis
Keywords: Quantitative Imaging, Image Reconstruction, Accelerated parameter mapping, Self-supervised; Zero-shot self-supervised learning
Motivation: Ground-truth-free (GT-free) deep learning (DL) approaches are expected to lower the cost of training DL models in accelerated quantitative MRI, but their performance has not been well compared to supervised approaches, and their application to quantitative MRI is still limited.
Goal(s): Evaluation of the effectiveness of GT-free approaches in quantitative MRI.
Approach: Three quantitative MRI methods (variable flip angle, multi-slice multi-echo, double echo steady state) were used to compare model-based DL architectures with three learning schemes: supervised learning, self-supervised learning, and zero-shot self-supervised learning in multiple acceleration factors.
Results: GT-free deep Learning approaches had high performance comparable to SL in many cases.
Impact: In this study, we compared GT-free approaches with SL and showed that they had high performance comparable to SL in many cases. These results indicate that GT-free approaches are applicable to a variety of sequences in accelerated quantitative MRI.
Introduction
The long acquisition time of quantitative MRI is problematic due to the need for multiple data acquisitions, and quantitative MRI has been actively studied to speed up acquisitions using data from multiple echoes.1 However, the diversity of quantitative MRI sequences makes it difficult to obtain pre-trained models for a desired quantitative MRI reconstruction. In addition, it is difficult to prepare a large amount of ground truth (GT) data at one's facility to train a model.In accelerated MRI reconstruction, GT-free approaches such as Self-Supervised Learning (SSL)2 and Zero-Shot Self-Supervised Learning (ZSSSL)3 have recently been proposed and reported to achieve performance comparable to supervised learning (SL). However, their application to quantitative MRI is still limited4,5, and few studies have compared the effectiveness of these frameworks for quantitative MRI, so the extent to which these GT-free techniques are more effective than SL remains to be extensively tested.
Here, we investigated the effectiveness of SL/SSL/ZSSSL using three quantitative MRI sequences: variable flip angle (VFA), multi-slice multi-echo (MSME), double echo steady state (DESS) based on the framework extended to quantitative MRI from Self-Supervised Learning via Data Undersampling (SSDU).2
Theory
Problem formulation for quantitative parameter mappingThe reconstruction problem was formulated as:
$$x_{rec}=argmin_x||y_{\Omega}-E_{\Omega}x||_2^2+\lambda||x-D(x;\theta)||^2_2$$
$$$x_{rec}$$$ is the reconstructed image, $$$y_{\Omega}$$$ is undersampled k-space data, $$$\Omega$$$ is the original undersampled k-space location, and $$$E_{\Omega}$$$ is the encoding operator, including coil sensitivities and partial Fourier matrix calculated specified by $$$\Omega$$$. $$$D(x;\theta)$$$ is a DL-based denoiser parameterized by $$$\theta$$$. In this study, we used ResNet with 6 layers and 64 filters. This unrolled network has 10 iterations with conjugate gradient-based data consistency. We extended SSDU2/ZS-SSDU3 to multiparametric reconstruction. The network input is a stack of multi-coil k-space data in each echo.
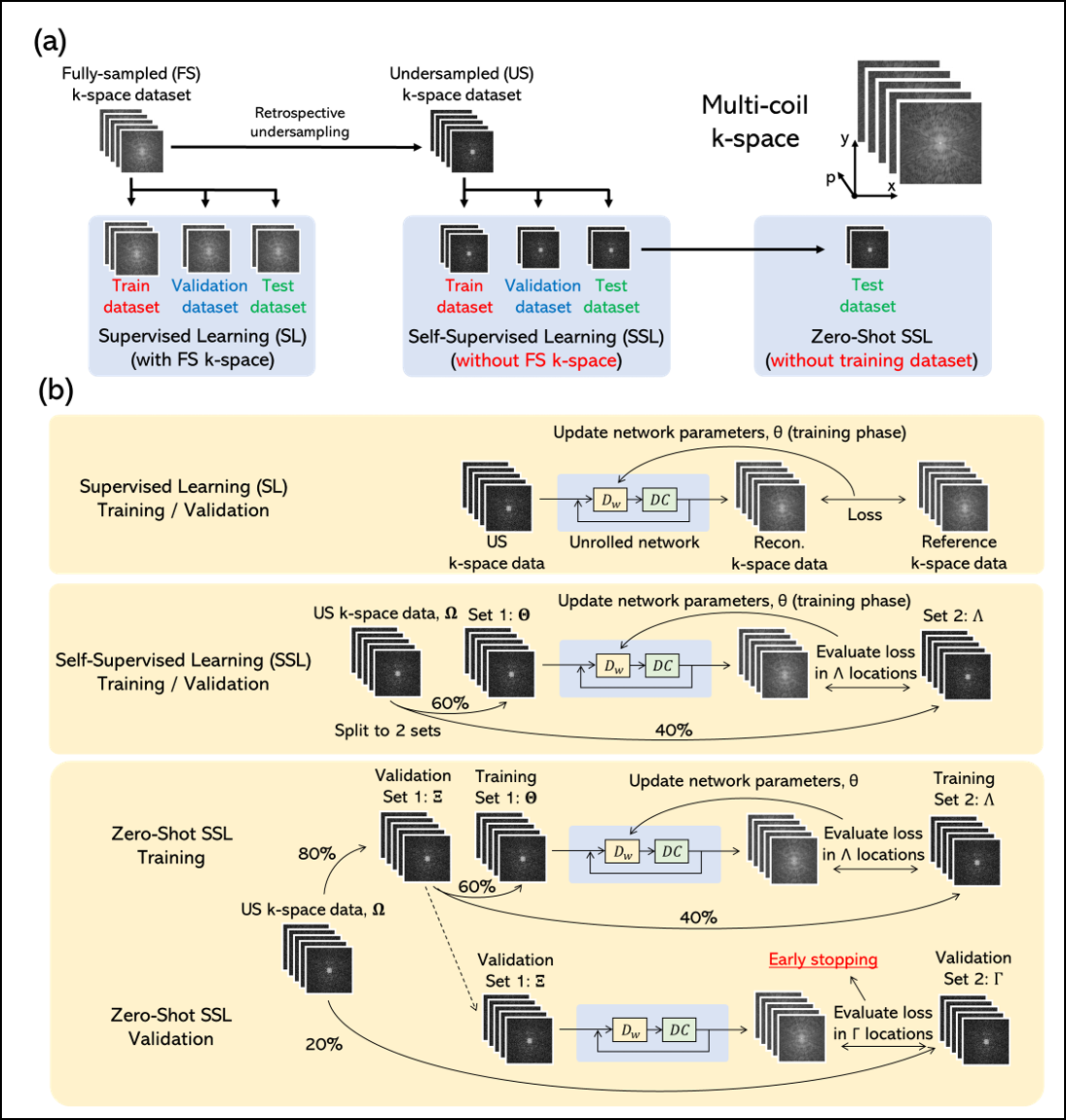
GT-free learning scheme
Only undersampled k-space data was available to the model during training and validation (Figure 1). The training loss $$$L_{train}$$$ and the validation loss $$$L_{val}$$$ are expressed as follows:
$$L_{train}=L(y_{\Lambda},E_{\Lambda}f_{UO}(y_{\Theta},E_{\Theta};{\theta}))$$
$$L_{val}=L(y_{\Gamma},E_{\Gamma}f_{UO}(y_{\Xi},E_{\Xi};{\theta}))$$
where $$$L$$$ is the loss function and $$$f_{UO}(y,E_X;\theta)$$$ ($$$X={\Theta}$$$ or $$${\Lambda}$$$) is an output of an unrolled network parameterized by $$$\theta$$$ for subsampled k-space data $$$y_{X}$$$ and corresponding encoding matrix $$${E_X}$$$ of the same subject. $$${\Theta},{\Lambda},{\Xi}$$$ ,and $$${\Gamma}$$$ are subsampled k-space locations. In SSL,$$$\Omega=\Theta\cap\Lambda,\Xi=\Theta$$$ and $$$\Gamma=\Lambda$$$, In ZS-SSL,$$$\Omega=\Xi\cap\Gamma$$$ and $$$\Xi=\Theta\cap\Lambda$$$. In this study, $$$|\Theta|/|\Lambda|=0.4, |\Gamma|/|\Xi|=0.2$$$.
Method
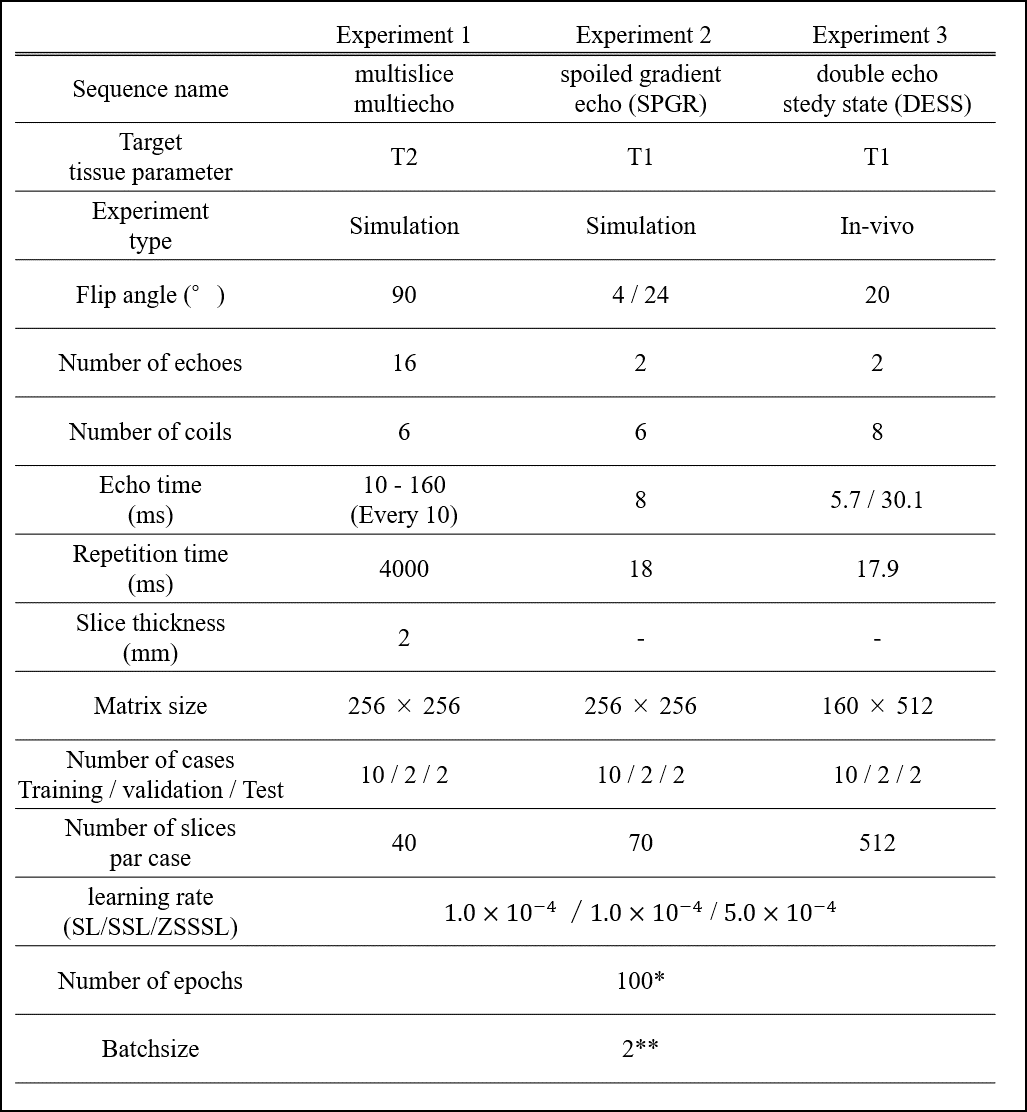
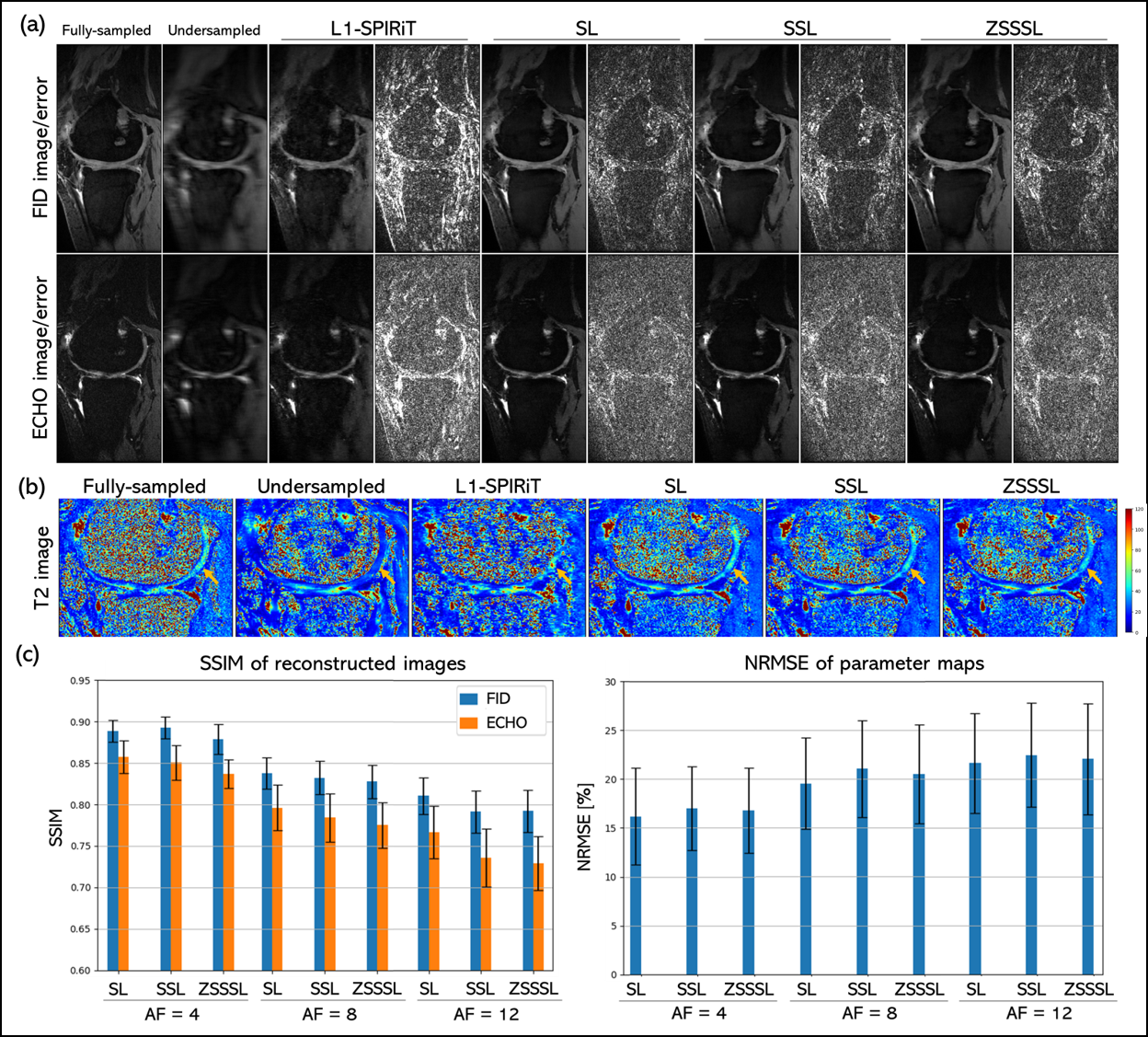
DatasetWe conducted three experiments (Table 1). In Experiment 1, synthetic images were calculated analytically from the Brainweb6 database using the SPGR signal model. Multi-coil k-space data was calculated using the Biot-Savart equation. Gaussian noise with a standard deviation of 0.01% of the maximum intensity was added to the synthetic k-space data. GT T1 maps were generated from synthetic images using the SPGR signal model. In Experiment 2, only synthetic images were generated by Bloch simulation. GT T2 maps were generated using the MSME signal model. For Experiments 1 and 2, sensitivity maps used for network inputs were regenerated from the multi-coil data using ESPIRiT7,8. In Experiment 3, the in vivo SKM-TEA9 dataset was used. GT T2 maps were generated analytically as in the method in Ref.10.
Network configuration
The training conditions are listed in Table 1. L1-SPIRiT11 was used as the non-DL reconstruction method.
Evaluation
We evaluated the reconstructed images with structural similarity (SSIM) and parameter maps with normalized root mean squared error (NRMSE).
Result & Discussion
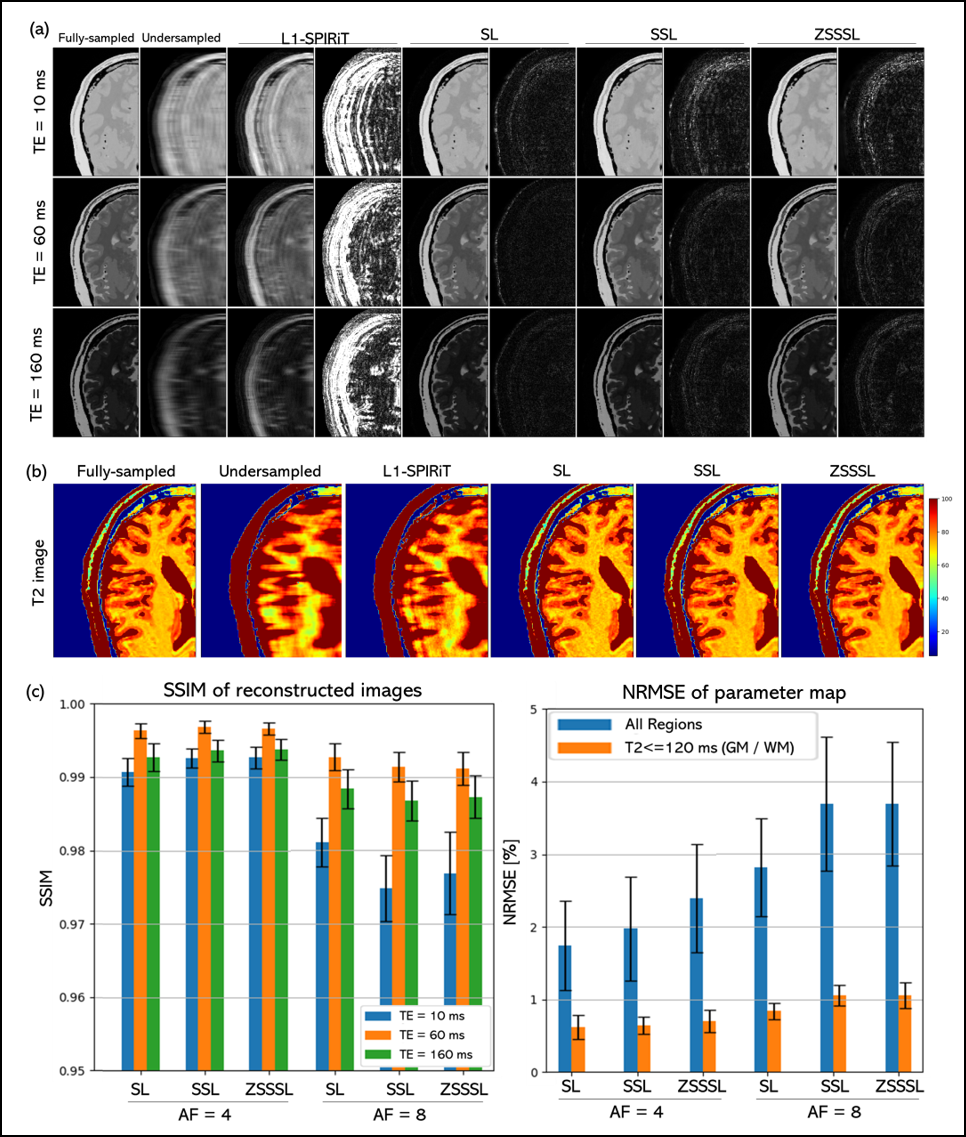
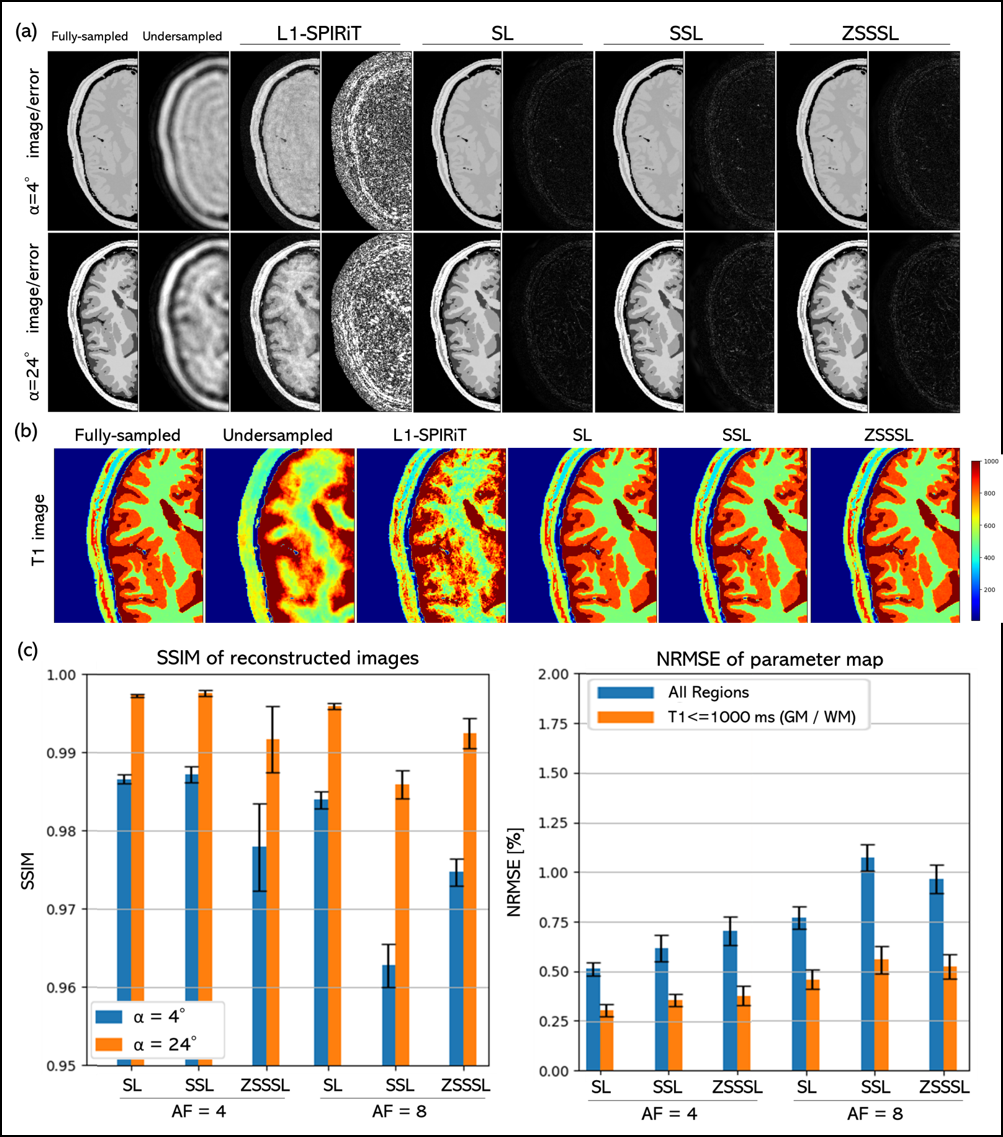
In Experiments 1 and 2, judging visually from the reconstructed images and quantitative maps (Figures 3 and 4), there was no difference in reconstruction performance between SL and GT-free DL methods, SSL and ZSSSL. SSIM values showed a similar trend at AF=4, although at AF=8, SSL and ZSSSL performed slightly inferior to SL. This may be because they split the original undersampled k-space data during training, leading to performance degradation at high AF. Note that SSL and ZSSSL showed high performance comparable to SL in clinically important tissues such as white matter and gray matter even at AF=8.In Experiment 3, the image quality of the reconstructed and quantitative images appeared to be almost equal for all DL approaches (Figure 5), as in the meniscus (indicated by the yellow arrow in Fig. 5-(b)). SSIM values showed a similar trend. SSL and ZSSSL performed highly comparable to SL even at AF=12.
Conclusion
In this study, we compared GT-free SSL and ZSSSL with SL and showed that they had high performance comparable to SL in many cases. These results indicate that the GT-free approaches are applicable to a variety of sequences in accelerated quantitative MRI. Further research is needed to improve the reconstruction performance at high AF.Acknowledgements
No acknowledgement found.References
1. Liu F, Feng L, Kijowski R. MANTIS: Model-Augmented Neural neTwork with Incoherent k-space Sampling for efficient MR parameter mapping. Magn Reson Med 2019; 82:174–188.
2. Yaman B, Hosseini SAH, Moeller S, Ellermann J, Uğurbil K, Akçakaya M. Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data. Magn Reson Med 2020; 84:3172–3191.
3. Yaman B, Hosseini SAH, Akçakaya M. Zero-Shot Self-Supervised Learning for MRI Reconstruction. 2021
4. Jun Y, Cho J, Wang X, et al. SSL-QALAS: Self-Supervised Learning for Rapid Multiparameter Estimation in Quantitative MRI Using 3D-QALAS. 2023
5. Jun Y, Arefeen Y, Cho J, et al. Zero-DeepSub: Zero-Shot Deep Subspace Reconstruction for Rapid Multiparametric Quantitative MRI Using 3D-QALAS. 2023
6. Aubert-Broche B, Griffin M, Pike GB, et al. Twenty new digital brain phantoms for creation of validation image data bases. IEEE Transactions on Medical Imaging. 2006; 25(11): 1410-1416.
7. Uecker M, Lai P, Murphy MJ, et al. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn Reson Med 2014; 71:990–1001.
8. Martin JB, Ong F, Ma J, Tamir JI, Lustig M, Grissom WA. SigPy. RF: comprehensive open-source RF pulse design tools for reproducible research. Proc. 28th Annual Meeting of ISMRM, 2020;
9. Desai AD, Schmidt AM, Rubin EB, et al. SKM-TEA: A Dataset for Accelerated MRI Reconstruction with Dense Image Labels for Quantitative Clinical Evaluation. 2022
10. Sveinsson B, Chaudhari AS, Gold GE, Hargreaves BA. A simple analytic method for estimating T2 in the knee from DESS. Magn Reson Imaging 2017; 38:63–70.
11. Murphy M, Alley M, Demmel J, Keutzer K, Vasanawala S, Lustig M. Fast ℓ1-SPIRiT Compressed Sensing Parallel Imaging MRI: Scalable Parallel Implementation and Clinically Feasible Runtime. IEEE Trans Med Imaging 2012; 31:1250–1262.
Figures