0383
Decoding Visual Information from fMRI Data: A Multimodal Approach to Image and Caption Reconstruction1Biomedicine and prevention, University of Rome Tor Vergata, Rome, Italy, 2University of Rome Tor Vergata, Rome, Italy, 3CerCo, University of Toulouse III Paul Sabatier, Toulouse, France, 4CNRS, CerCo, ANITI, TMBI, Univ. Toulouse, Toulouse, France
Synopsis
Keywords: AI Diffusion Models, fMRI, brain decoding, fMRI
Motivation: The study addresses the challenge of decoding and reconstructing visual experiences from fMRI data, an area yet to be mastered in neuroscience.
Goal(s): We propose a methodology that deciphers brain activity patterns and renders these into visual and textual representations.
Approach: We trained a linear model to map brain activity to image latent represenations. This informed a generative image-to-text transformer and a visual attribute-focused regression model, culminating in the creation of photorealistic images using a text-to-image diffusion model.
Results: The model effectively combined high-level semantic understanding and low-level visual details, producing plausible reconstruction images from fMRI data.
Impact: Our findings enhance our understanding of visual processing in the brain, with significant implications for integrating artificial intelligence (AI) with neuroscience.
Introduction
The enigma of how the human brain interprets and processes visual stimuli has long intrigued scientists. Despite advancements in neuroimaging, particularly functional MRI (fMRI), the ability to decode and reconstruct what the brain “sees” from these data remains a formidable challenge [1,2,3,4]. This study aimed to develop a method that not only deciphers the complex patterns of brain activity, but also translates them into accurate visual and textual representations. We address a critical gap in BCI by aiming to reconstruct detailed images and generate corresponding captions directly from fMRI data. This endeavor is pivotal as it could revolutionize our understanding of visual cognition and pave the way for breakthroughs in neuroprosthetics, AI, and neuroscience.Methods
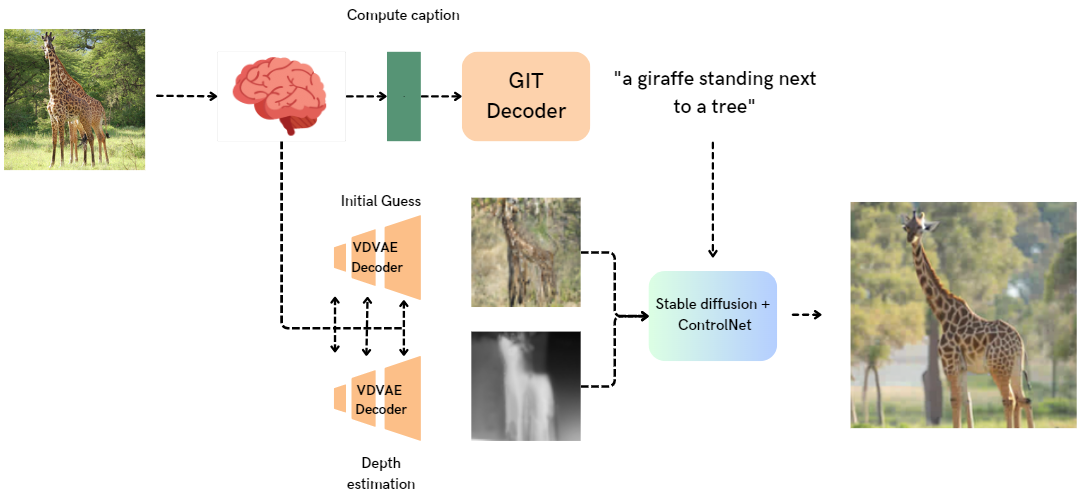
Our multimodal approach leverages deep learning and the detailed Natural Scenes fMRI dataset [6], which encompasses extensive brain activity recordings from subjects observing a vast array of COCO images. The fMRI data, acquired with 1.8mm isotropic voxels during sessions where subjects viewed ten thousand unique images, were processed using GLMsingle [7] for denoising, normalized for spatial consistency, and filtered temporally, ensuring a focus on visual processing regions within the brain. This comprehensive preprocessing yields a robust dataset capturing the full breadth of visual experiences. The first component of our approach is the Generative Image-to-text Transformer (GIT), a transformer-based model able to generate descriptive captions from images. To adapt GIT for our purposes, we trained a regularized linear regression on a subset of the fMRI dataset, where each fMRI recording was paired with the corresponding image and its textual description. This enabled the model to learn the complex mappings between neural activity patterns and the semantic content of the images, estimating the GIT latent space directly from the fMRI images. In parallel, we developed a regression model to translate the fMRI data into a latent space that represents visual and depth features. This model was trained to predict the latent representations of images as encoded by a pre-trained variational autoencoder (VDVAE). These latent representations capture essential visual attributes such as shapes, textures, and colors, which are pivotal for the subsequent image reconstruction process. The final step in our pipeline is the generation of photorealistic images using the text-to-image diffusion model, Stable Diffusion [5]. This model synthesizes images based on textual descriptions, which in our case, are the captions generated from the fMRI data. By conditioning the image generation on both the captions and the depth maps, we aimed to produce images that not only depict the correct objects and scenes but also maintain the right spatial hierarchy and perspective as perceived by the subjects.Results
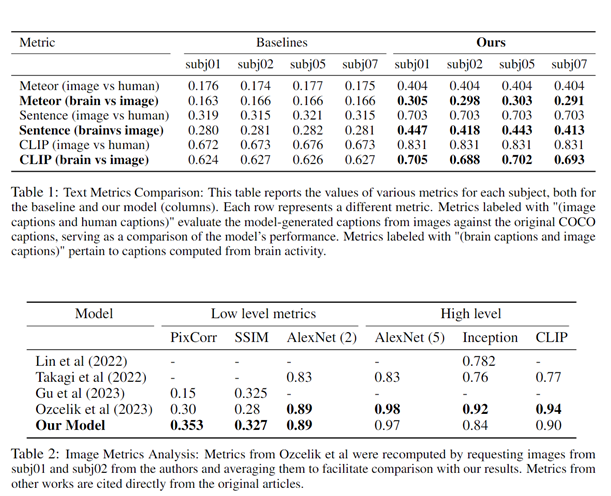
The captioning model demonstrated a marked improvement in accuracy, with METEOR scores and CLIP similarity metrics surpassing those of previous methods [1,2,3]. The image reconstruction pipeline, informed by depth estimation, produced images with significantly enhanced spatial relationships, as evidenced by improved PixCorr and SSIM metrics. Qualitatively, the model's ability to generate captions that captured the essence of the visual stimuli was evident, with the GIT decoder playing a crucial role in formulating plausible sentences and combined with visual components in generating high fidelity image reconstruction from fMRI activity.Discussion
In this work, it was observed that our model's ability to generate plausible reconstructions from fMRI was significantly enhanced by its high-level semantic component, which was guided by textual prompts, and its low-level component, which was driven by visual modules. The efficacy of the pipeline could be further augmented with the acquisition of more extensive datasets, as the current limitation lies in the necessity for vast amounts of subject-specific data to train such articulate models. This requirement for large-scale data for each individual presents a substantial challenge in the practical application and scalability of the model.Conclusions
In conclusion, this work advances the quest to decode and reconstruct visual information from brain activity, contributing to bridging the gap between neuroscience and artificial intelligence and offering novel insights into the brain's visual processing.Acknowledgements
This work was supported by NEXTGENERATIONEU (NGEU) and funded by the Italian Ministry of University and Research (MUR), National Recovery and Resilience Plan (NRRP), project MNESYS (PE0000006) (to NT)– A Multiscale integrated approach to the study of the nervous system in health and disease (DN. 1553 11.10.2022); by the MUR-PNRR M4C2I1.3 PE6 project PE00000019 Heal Italia (to NT); by the NATIONAL CENTRE FOR HPC, BIG DATA AND QUANTUM COMPUTING, within the spoke "Multiscale Modeling and Engineering Applications" (to NT); the EXPERIENCE project (European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No. 101017727); the CROSSBRAIN project (European Union’s European Innovation Council under grant agreement No. 101070908).References
[1] Chen, Z., Qing, J., Xiang, T., Yue, W.L., Zhou, J.H.: Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding (2022)
[2] Ozcelik, F., VanRullen, R.: Brain-diffuser: Natural scene reconstruction from fmri signals using generative latent diffusion (2023)
[3] Ferrante, M., Ozcelik, F., Boccato, T., VanRullen, R., Toschi, N.: Brain captioning:Decoding human brain activity into images and text (2023)
[4] Ferrante, M., Boccato, T., Toschi, N.: Semantic brain decoding: from fmri to conceptually similar image reconstruction of visual stimuli (2023)
[5] AUTOMATIC1111. (2022). Stable Diffusion WebUI. .
[6] Allen, E.J., St-Yves, G., Wu, Y., Breedlove, J.L., Prince, J.S., Dowdle, L.T., Nau, M., Caron, B., Pestilli, F., Charest, I., Hutchinson, J.B., Naselaris, T., Kay, K.: A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence. Nature Neuroscience 25(1), 116–126 (Jan 2022). https://doi.org/10.1038/s41593-021-00962-x, https://doi.org/10.1038/s41593-021-00962-x
[7] Prince, J.S., Charest, I., Kurzawski, J.W., Pyles, J.A., Tarr, M., Kay, K.N. Improving the accuracy of single-trial fMRI response estimates using GLMsingle. eLife (2022).
Figures