0381
Spatiotemporal Diffusion Model with Paired Sampling for Accelerated Cardiac Cine MRI1United Imaging Intelligence, Burlington, MA, United States, 2Biomedical Imaging Research Institute, Cedars-Sinai Medical Center, Los Angeles, CA, United States, 3Department of Bioengineering, UCLA, Los Angeles, CA, United States, 4Department of Radiation Oncology and Winship Cancer Institute, Emory University, Atlanta, GA, United States, 5Department of Biomedical Informatics, Emory University, Atlanta, GA, United States, 6UIH America, Inc., Houston, TX, United States
Synopsis
Keywords: AI Diffusion Models, Image Reconstruction, Heart
Motivation: Current deep learning reconstruction for accelerated cardiac cine MRI suffers from spatial and temporal blurring.
Goal(s): To improve image sharpness and motion delineation for cine MRI under high undersampling rates.
Approach: A combined non-generative reconstruction and diffusion enhancement model along with a novel paired sampling strategy was developed.
Results: The proposed combined method provided sharper tissue boundaries and clearer motion than the original reconstruction in experts’ evaluation on clinical data. The innovative paired sampling strategy substantially reduced artificial noises in the generative results.
Impact: The approach has the potential to improve reconstruction quality in highly accelerated cardiac cine imaging. The novel paired sampling for diffusion generation may be applied to other conditional tasks to reduce the artificial noises stemming from noisy training data.
Introduction
Accelerated cardiac cine imaging such as real-time cine is highly desirable given its shortened scan time and increased motion robustness, but the reconstruction is challenging due to high undersampling rates. Although deep learning (DL) methods have significantly reduced aliasing artifacts in highly-accelerated MRI reconstruction, most of them formulate the reconstruction as a non-generative (regression) problem, resulting in compromised sharpness and motion blurring.1,2 Diffusion models3,4 as generative models, however, provide results by sampling from a learned distribution and have shown promising results in narrowing the gap to fully-sampled quality in static image reconstruction but not for dynamic imaging.5-9In this study, a combined non-generative DL reconstruction and diffusion generation framework was proposed for cine CMR. The diffusion part utilized spatiotemporal architectures to handle the 2D+time data and a novel paired-sampling strategy was additionally proposed to reduce the synthetic noises in the generative results stemming from noisy training data. The approach was evaluated quantitatively and qualitatively on both retro- and pro-spectively undersampled cine imaging. To our knowledge, this is the first study to reconstruct dynamic CMR images with diffusion models.
Methods
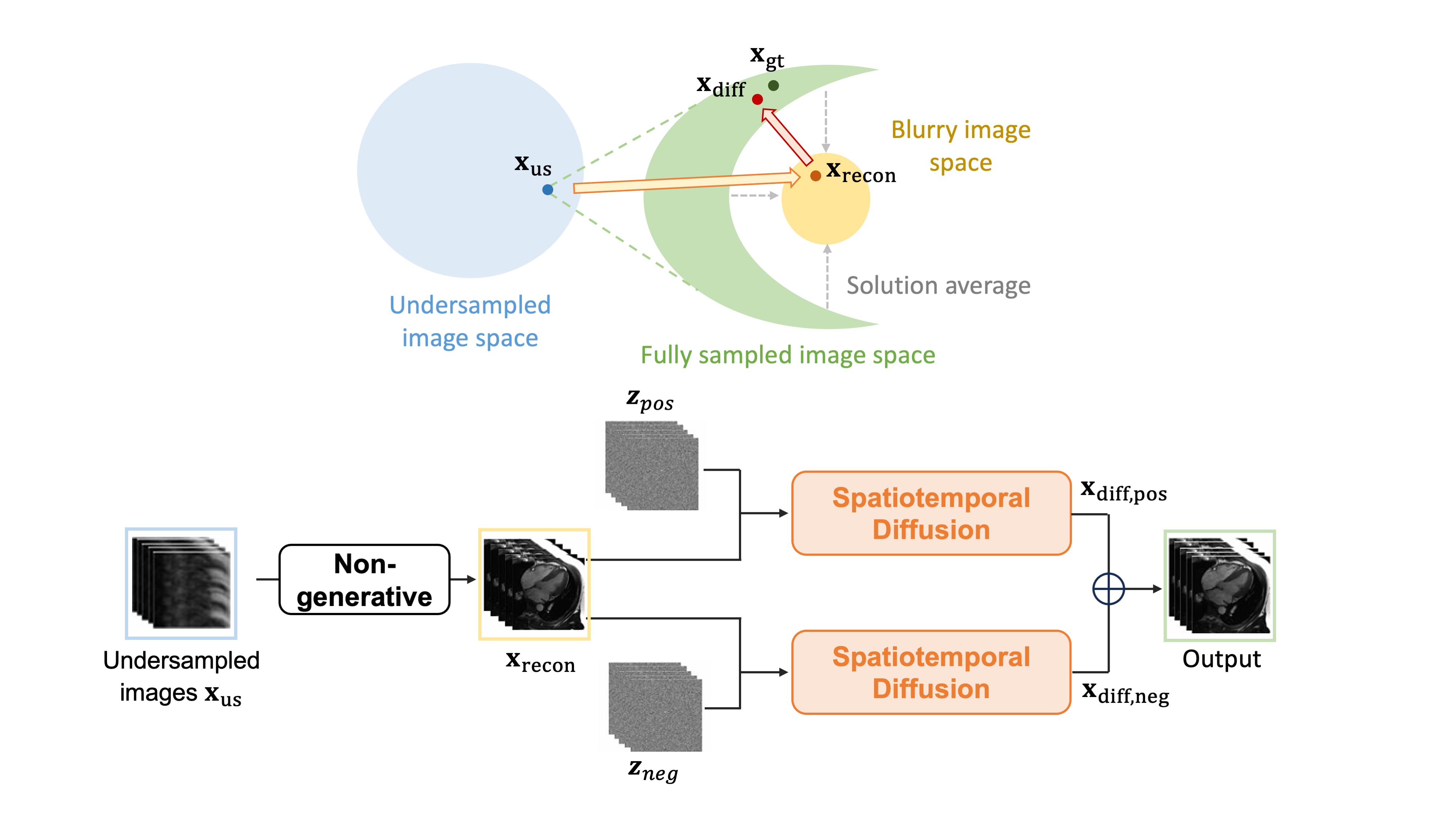
Combination of non-generative and generative modelsA residual convolutional recurrent neural network (res-CRNN)1 trained with paired under- and fully-sampled images was firstly used for initial reconstruction from undersampled raw data. The initial de-aliased result was fed to a diffusion model that was conditioned on the collected data and the de-aliased result (Figure 1). The diffusion model was trained with pairs of CRNN outputs and fully-sampled images. To handle dynamic data, a spatiotemporal network was adopted as the diffusion model to utilize the temporal information, which was constructed by adding 3D spatiotemporal convolution and temporal attention layers to a 2D U-net architecture.10
Paired sampling
In medical images, noises on reference fully sampled images are arguably inevitable which can be picked up by generative models to produce undesired artificial noises. We proposed a novel paired sampling strategy to address this issue. In a conditional generation task, the result $$$x$$$ was hypothesized to be $$$x={x_s}+{x_n}$$$, where $$${x_n}$$$ represents the noises and $$${x_s}$$$ is the desired structure. We further assumed $$${x_s}$$$ to be from an interaction between the given condition and the noises input to the diffusion system, whereas $$${x_n}$$$ mainly calculated from the noises themselves. A paired sampling was designed, where opposite noises $$${z_{pos}}$$$ and $$${z_{neg}}$$$ were inputted for two samplings. It was observed that the synthetic noises in these samplings were also largely opposite to each other, indicating that $$${x_{pos,n}}\approx-{x_{neg,n}}$$$. Additionally, $$${x_{pos,s}}\approx{x_{neg,s}}\approx{x_{s}}$$$ according to the definition. Therefore, an average of the two was output as the final result: $$${x_{pair}}=({x_{pos}}+{x_{neg}})/2$$$.
Data and experiments
The approach was first trained and evaluated on bSSFP retro-cine data collected on 3T MRI scanners (uMR790, UIH, Shanghai, China) with IRB approval, where retrospective undersampling (R=8~16) was applied to 1071 slices from 43 subjects (6/2/2 for train/validation/test splitting). Clinical real-time cine from 2 subjects were additionally acquired for testing. A spatial resolution of 1.82x1.82 mm2 and a temporal resolution of 34 ms and 42 ms for retro and real-time, respectively, were used. Quantitative metrics and qualitative blind rankings from two experienced (>10yr) experts were used for quality assessment.
Results
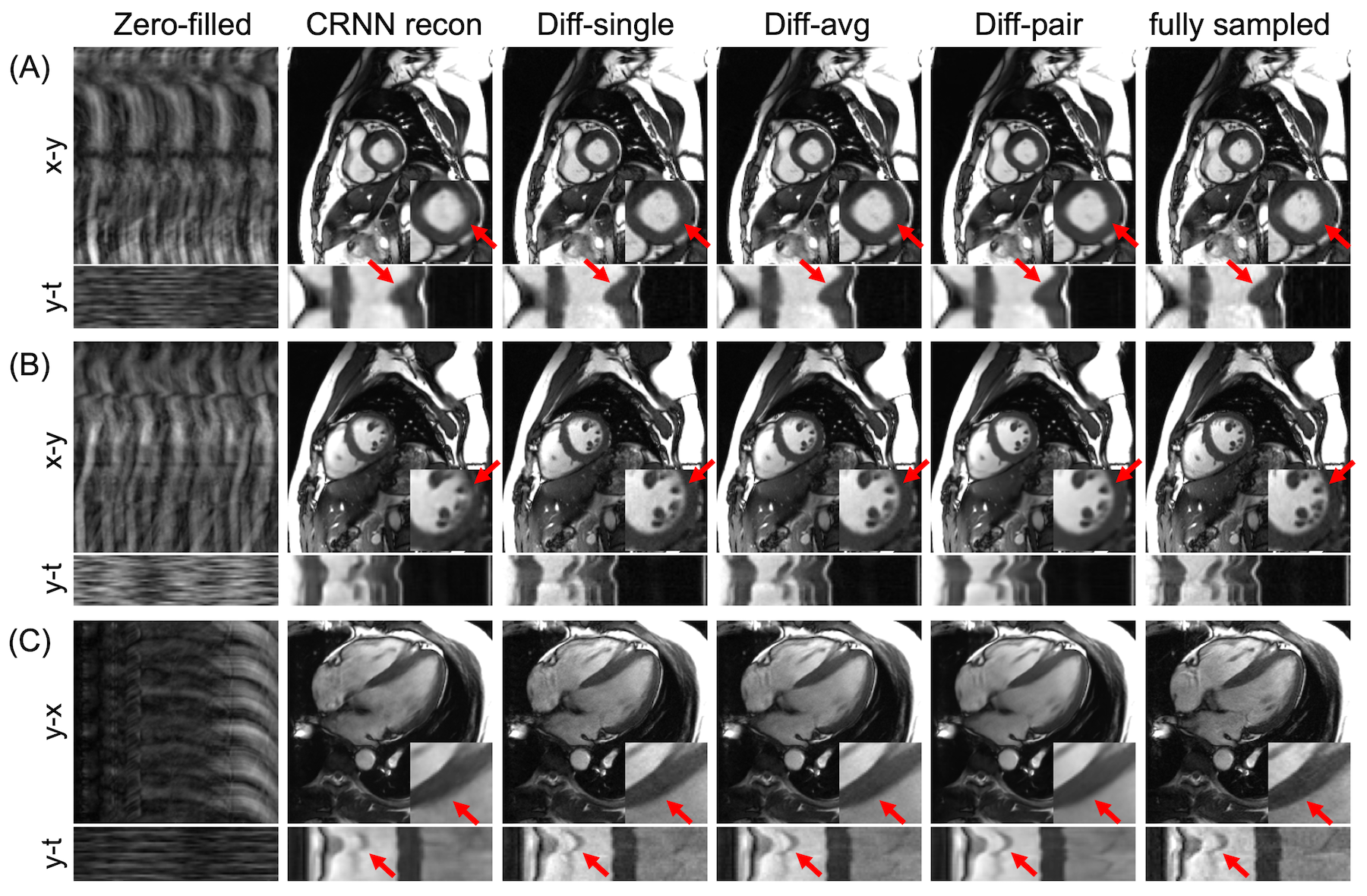
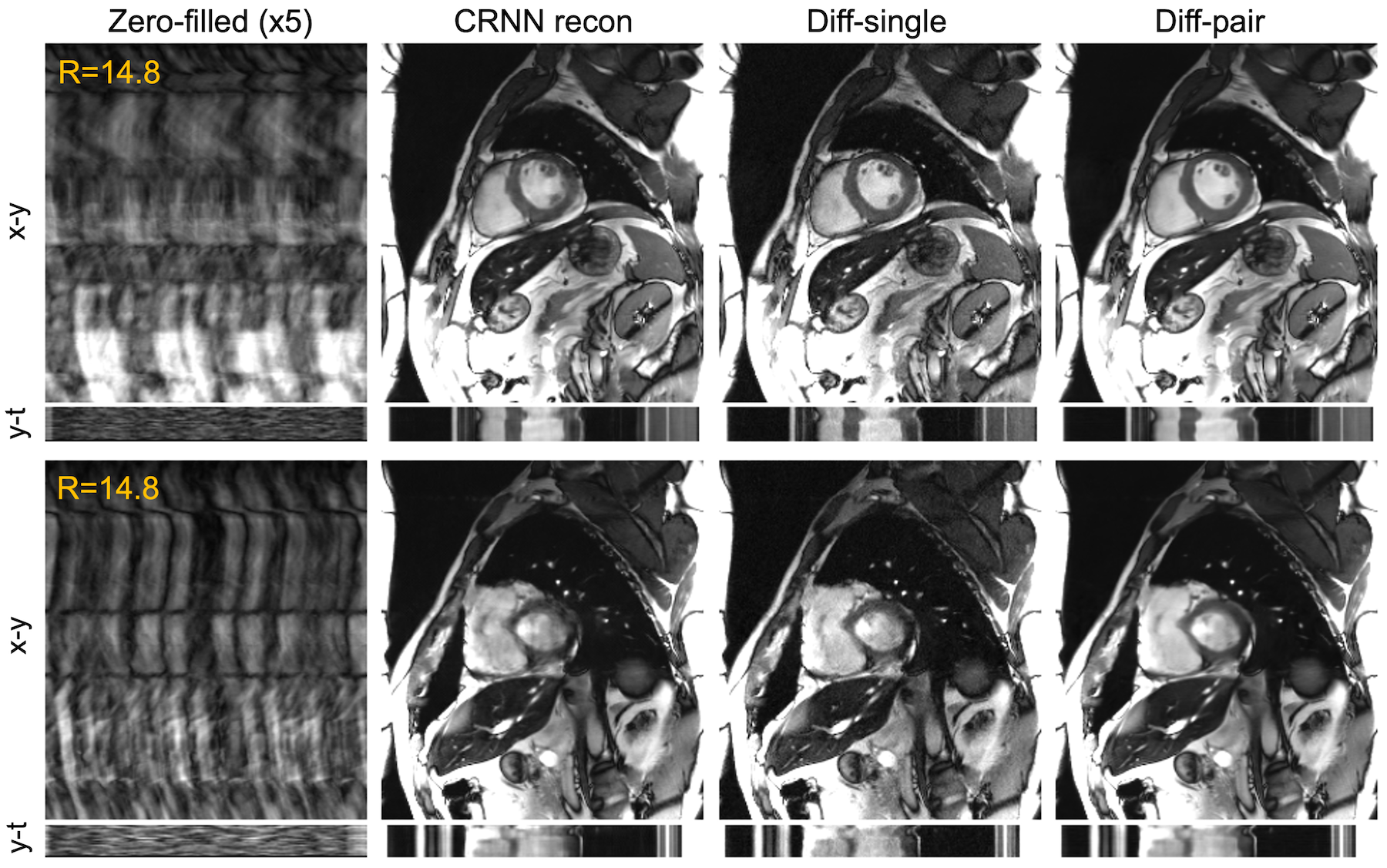
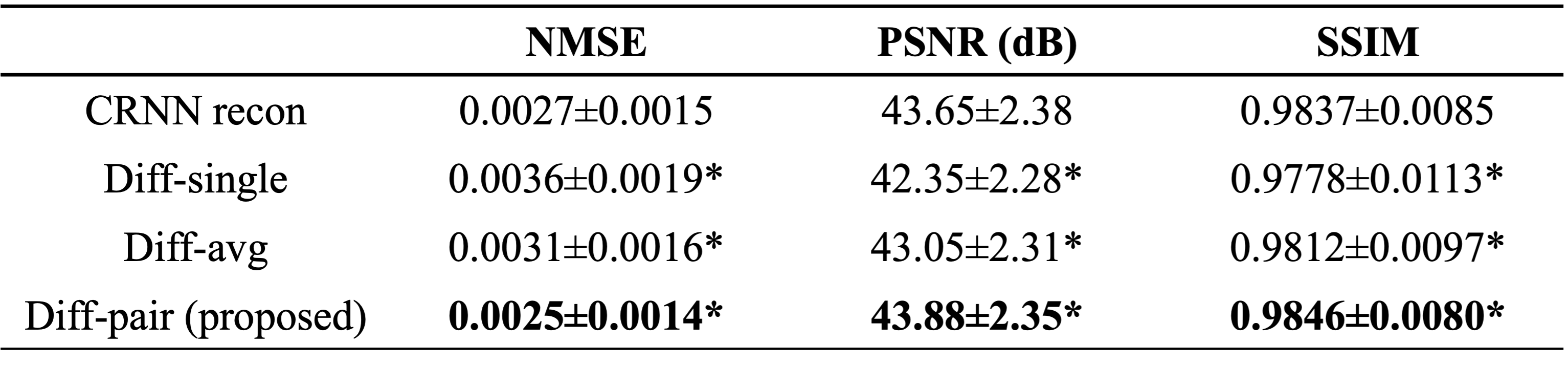
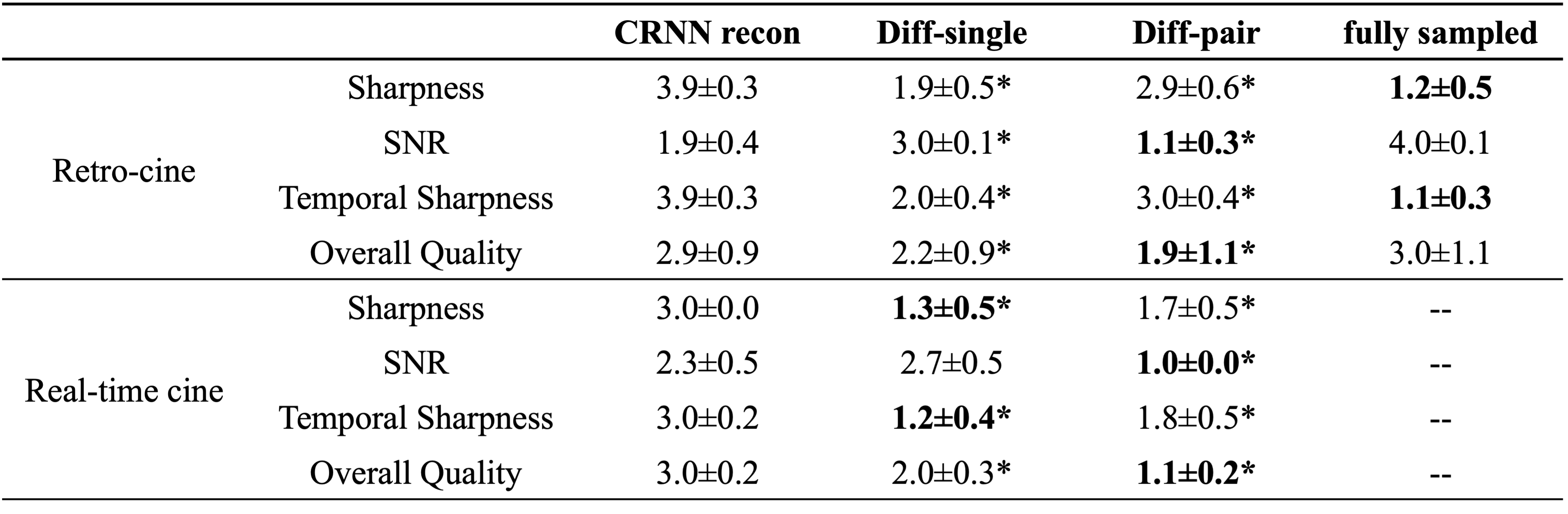
The combined res-CRNN and diffusion framework achieved a similar image appearance to fully sampled images, with sharper tissue boundaries and reduced temporal blurring than the original res-CRNN reconstruction (Figure 2). The paired sampling strategy provided much lower noises compared to single sampling even with averages. The proposed method achieved the best NMSE, PSNR, and SSIM (Table 1). In the visual evaluation, our approach achieved better performance than res-CRNN reconstruction in all aspects (Table 2). Testing on real-time cine also showed consistent performance in reducing blurring and artifacts (Figure 3 & Table 2).Discussion
The proposed method demonstrated the effectiveness of combining the synergy of non-generative reconstruction and diffusion generative models to reconstruct high-quality cine images from highly accelerated data. The paired sampling efficiently removed the undesired noise prior embedded in the training data, showing much higher PSNR, SSIM and preferred visual appearance over the conventional diffusion methods.Conclusion
A combined non-generative reconstruction and diffusion generation was developed to improve the image quality in highly accelerated cine reconstruction. The proposed model along with a paired sampling strategy provided effective enhancement of sharpness while mitigating the generation of artificial noises, resulting in high-quality cine images.Acknowledgements
No acknowledgement found.References
1. Chen EZ, Chen X, Lyu J, et al. Real-time cardiac cine MRI with residual convolutional recurrent neural network. arXiv preprint arXiv:200805044. 2020.
2. Hauptmann A, Arridge S, Lucka F, Muthurangu V, Steeden JA. Real‐time cardiovascular MR with spatio‐temporal artifact suppression using deep learning–proof of concept in congenital heart disease. Magn Reson Med. 2019;81(2):1143-1156.
3. Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. Advances in neural information processing systems. 2020;33:6840-6851.
4. Song Y, Sohl-Dickstein J, Kingma DP, Kumar A, Ermon S, Poole B. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:201113456. 2020.
5. Song Y, Shen L, Xing L, Ermon S. Solving inverse problems in medical imaging with score-based generative models. arXiv preprint arXiv:211108005. 2021.
6. Chung H, Ye JC. Score-based diffusion models for accelerated MRI. Medical image analysis. 2022;80:102479.
7. Jalal A, Arvinte M, Daras G, Price E, Dimakis AG, Tamir J. Robust compressed sensing mri with deep generative priors. Advances in Neural Information Processing Systems. 2021;34:14938-14954.
8. Peng C, Guo P, Zhou SK, Patel VM, Chellappa R. Towards performant and reliable undersampled MR reconstruction via diffusion model sampling. Paper presented at: International Conference on Medical Image Computing and Computer-Assisted Intervention2022.
9. Luo G, Blumenthal M, Heide M, Uecker M. Bayesian MRI reconstruction with joint uncertainty estimation using diffusion models. Magn Reson Med. 2023;90(1):295-311.
10. Blattmann A, Rombach R, Ling H, et al. Align your latents: High-resolution video synthesis with latent diffusion models. Paper presented at: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition2023.
Figures