0347
Robust Deep Equilibrium Paradigms for 3D Hybrid Stack of Stars Reconstruction1Electrical and Computer Engineering, University of Wisconsin-Madison, Madison, WI, United States, 2Biomedical Engineering, University of Wisconsin-Madison, Madison, WI, United States, 3Medical Physics, University of Wisconsin-Madison, Madison, WI, United States, 4Radiology, University of Wisconsin-Madison, Madison, WI, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Image Reconstruction, Non-cartesian Reconstruction, Memory Efficient Reconstruction, Deep Learning, AI
Motivation: Exploring the stability of various memory efficient deep equilibrium architectures for non-cartesian stack of stars reconstruction.
Goal(s): Implementing memory efficient inversion-based and inversion free deep equilibrium models and assessing performance against unrolled network baselines.
Approach: Applying an implicit layer consisting of data-consistency and a 2D-UNet denoiser to find a fixed point and iteratively solving the optimization problem using proximal gradient descent with inversion free and inversion-based equilibrium backpropagation. Compare the efficacy of spectral normalization and Jacobian regularization on stability.
Results: The inversion-free deep equilibrium model exhibited performance similar to unrolled networks, achieving a significant 50% reduction in GPU memory usage.
Impact: Stable and memory-efficient training advances AI-based reconstructions by enhancing their robustness and efficiency, leading to more accurate diagnoses and treatments, ultimately improving patient care. Moreover, it renders these advanced AI solutions more accessible to resource-constrained systems.
Introduction
Deep learning (DL) based MRI reconstruction is typically rooted in formulating the reconstruction problem as regularized least squares optimization, solved by iteratively alternating between gradient-descent based updates to satisfy data consistency and a learned regularizer. In most cases, the number of iterations (unrolls) is fixed and models are trained end-to-end. Recently, deep equilibrium (DEQ) models 1,2 have emerged in the quest for memory efficient DL MRI reconstruction. DEQ aims to solve the reconstruction problem by transforming the solver block into an implicit single layer that can be run to convergence without additional memory overhead incurred in unrolled networks3. These models effectively offer infinite depth and thus aim to provide great decoupling between the regularizer and the forward encoding model. However, training DEQ models is challenging as it relies on finding an equilibrium point and implicit backpropagation through this point to find parameter gradients.4 This leads to longer training times and instabilities in optimization that can result model divergence or convergence to undesirable equilibria. Recently, inversion free backpropagation5 and multiple stabilization procedures have been introduced to improve speed and robustness over the complex Jacobian based backpropagation of the original DEQs. In this work, we explore the known training instabilities of DEQ models using these techniques with 3D stack-of-stars data. Further, we propose a cascaded optimization to improve the convergence of the fixed point solver.Methods
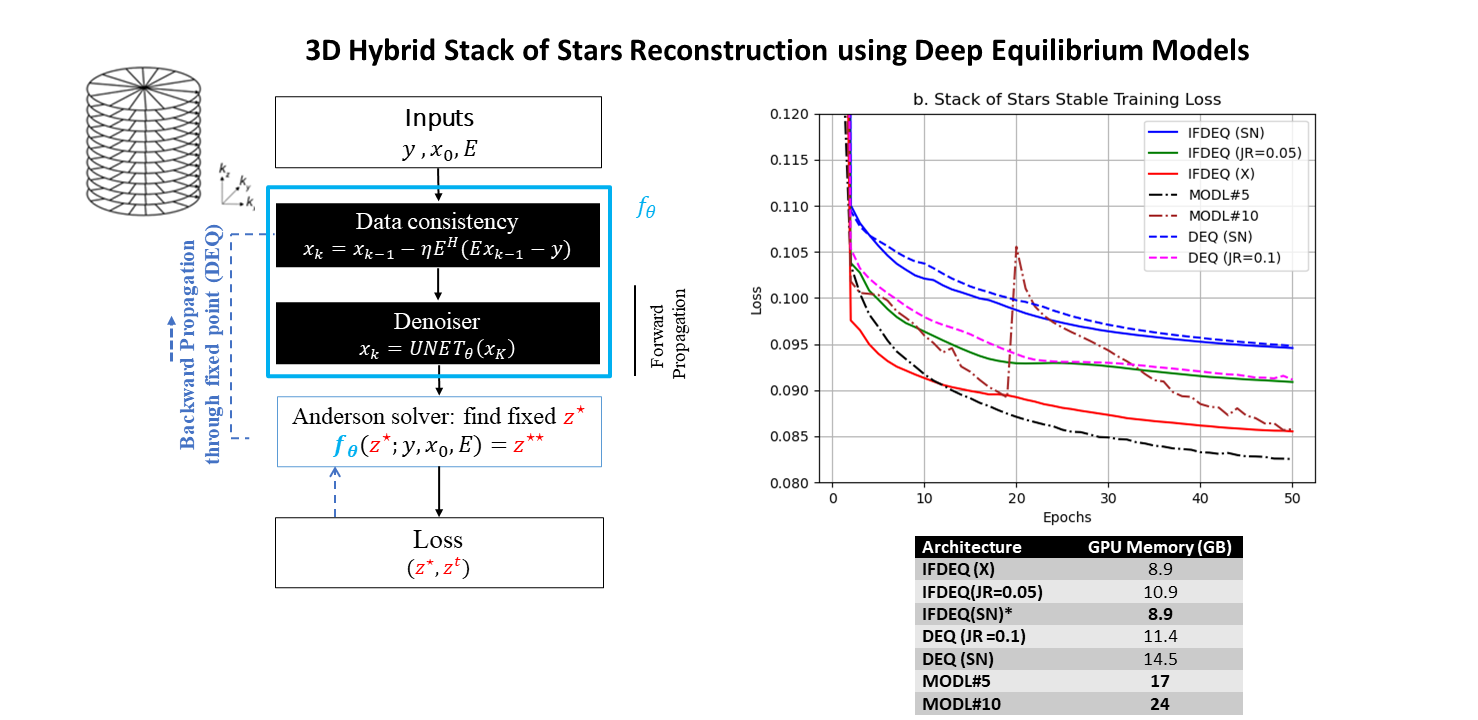
The single implicit layer of the DEQ implements a proximal gradient descent solution decoupling data-consistency and the regularizer steps (Figure-1). For all DEQ methods, the forward pass involves finding an equilibrium point, in our case using an accelerated solver (Anderson acceleration)6.Solvers:
In traditional DEQ-models, gradients are calculated using using: $$\mathcal{L}_{D E Q}\left(z^{\star}\right)=\frac{\partial \mathcal{L}\left(z^t, z^{\star}\right)}{\partial(\cdot)}=\left(I-J_\theta\right)^{-T} \cdot\left(\frac{\partial z^{\star \star}}{\partial(\cdot)}\right)^T \cdot\left(\frac{\partial \mathcal{L}\left(z^t, z^{\star}\right)}{\partial z^{\star}}\right) ;$$
$$\text { where } J_\theta=\frac{\partial z^{\star \star}}{\partial z^{\star}} \text { is the Jacobian, and } z^t, z^{\star} \text { represent the truth and the equilibrium point. }$$
This involves a second fixed point solver for gradient estimation1.
Inversion free deep equilibrium model (IFDEQ) simplifies the backpropagation by estimating the gradients without inverting the Jacobian inverse:$$\mathcal{L}_{I F D E Q}\left(z^*\right)=\frac{\partial \mathcal{L}\left(z^t, z^{\star}\right)}{\partial(\cdot)}=\left(\frac{\partial z^{\star \star}}{\partial(\cdot)}\right)^T \cdot\left(\frac{\partial \mathcal{L}\left(z^t, z^{\star}\right)}{\partial z^{\star}}\right) ;$$
Stabilization:
DEQ models are known to have instabilities5 with respect to fixed-point solver. In this work, we compared (i) Spectral-normalization7 (SN) of denoiser (ii) Jacobian Regularization5 (JR) as stabilization regimes.
Cascaded optimization:
Training time is comminated by the forward fixed-point solver which requires multiple iterations. To further accelerate training, we propose to initialize the fixed-point solver with its previous solution. In this case, the optimization cascades the prior solutions, reducing training time.
Training and Evaluation
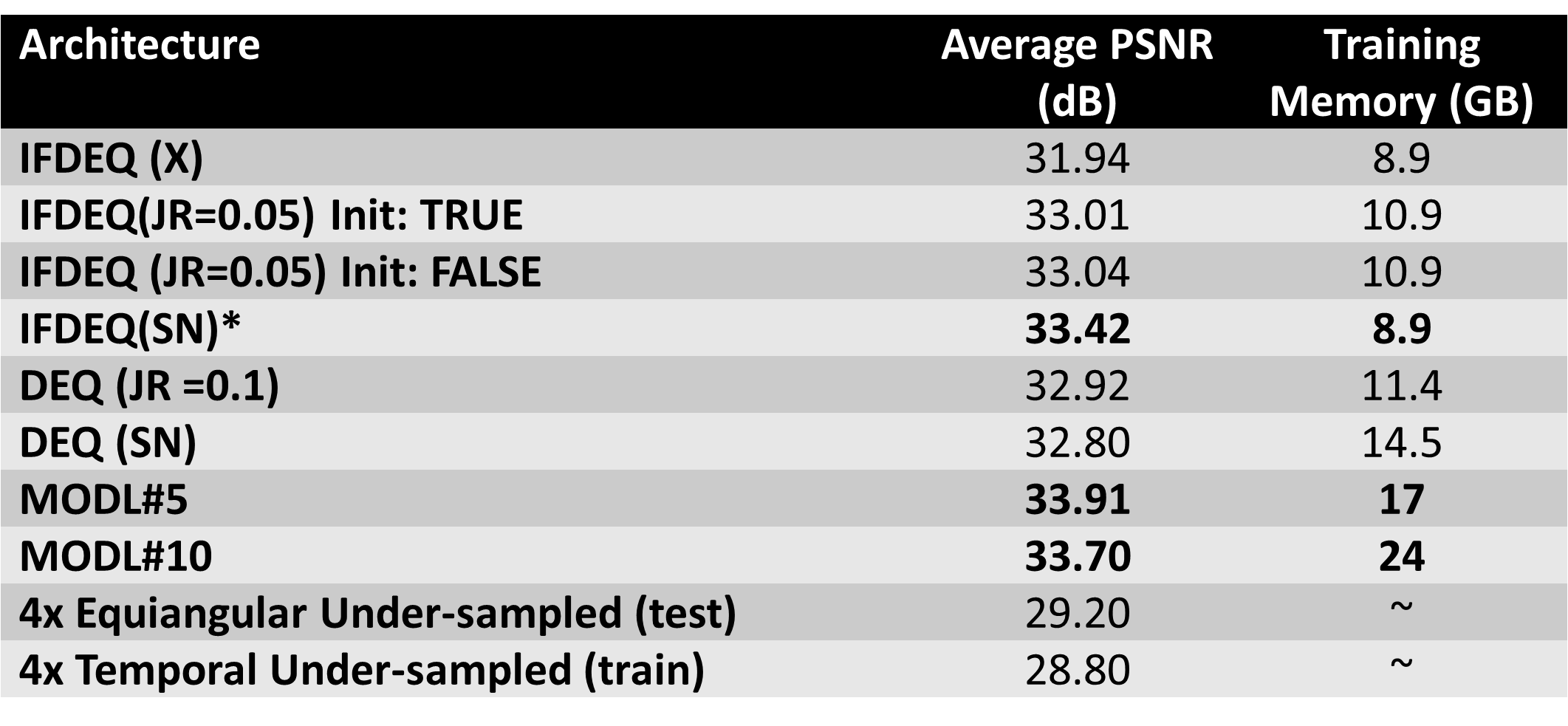
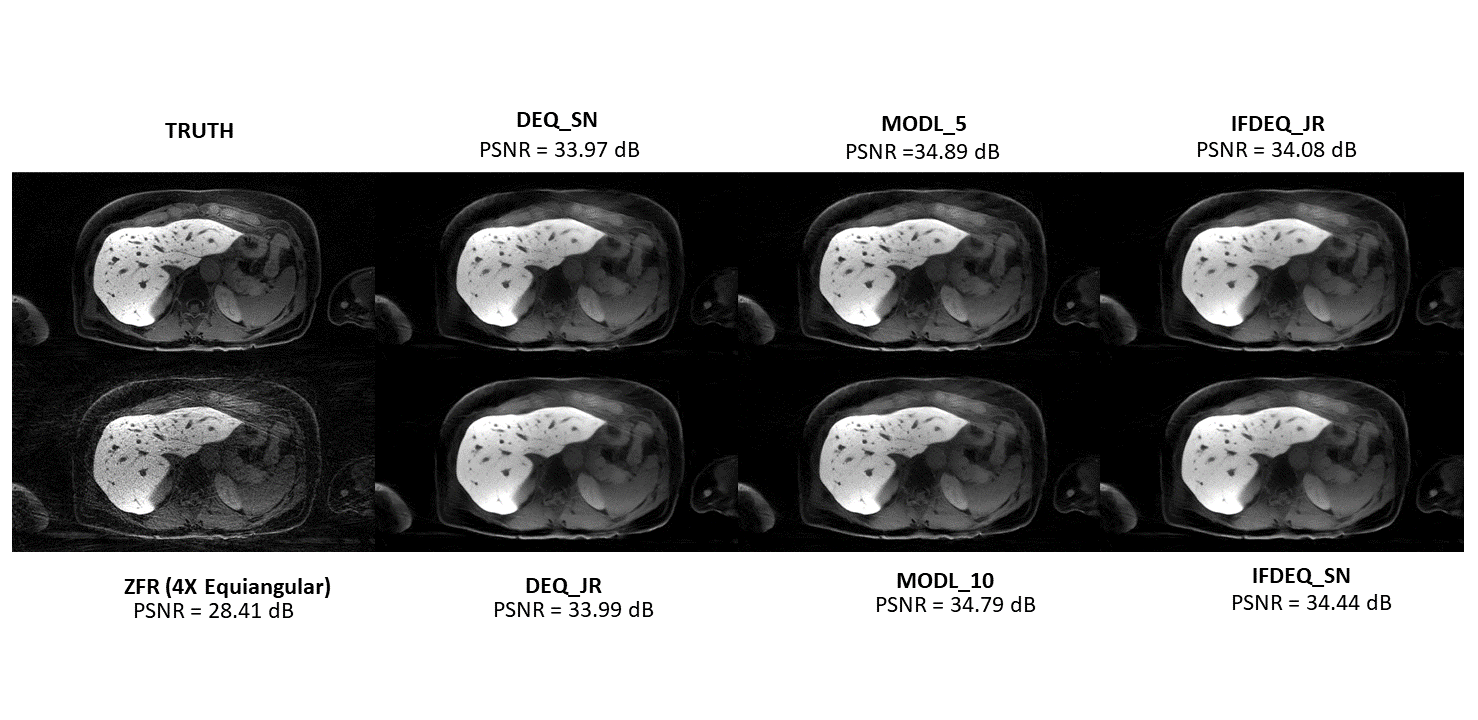
Training utilized Fat-suppressed, axial, 3D T1-weighted 32-channel stack-of-stars (GE-LAVA Star8) data collected on a 3T scanner. This acquisition combines Cartesian-sampling along z-axis with radial sampling along xy-plane. Training was based on 5 patients (500 slices) for 50 epochs and tested on 2(200 slices). Two distinct undersampling regimes were employed for training and testing respectively: (i) Temporal (every n-th projection) (ii) Equiangular retrospective projection sampling. Density compensation, k-space was normalized using the max eigenvalue of the NUFFT operator and image-space norm of the gridded undersampled reconstruction respectively. Separate coil sensitivity maps were computed using JSENSE9 and gridded undersampled images were used as input to the models. Image-space MSE supervised loss was used as the loss criterion. All methods were trained using PyTorch (Adam optimizer; learning rate: 1e-3) in Tesla V100 GPU. 50 Anderson iterations were used for finding fixed point in the forward pass. MoDL-5/MoDL-103 were used as baselines for comparison with identical 2D-U-Net10 architectures as denoiser between all methods. PSNR served as a quantitative metric, complementing visual comparisons (Figure-4).Results
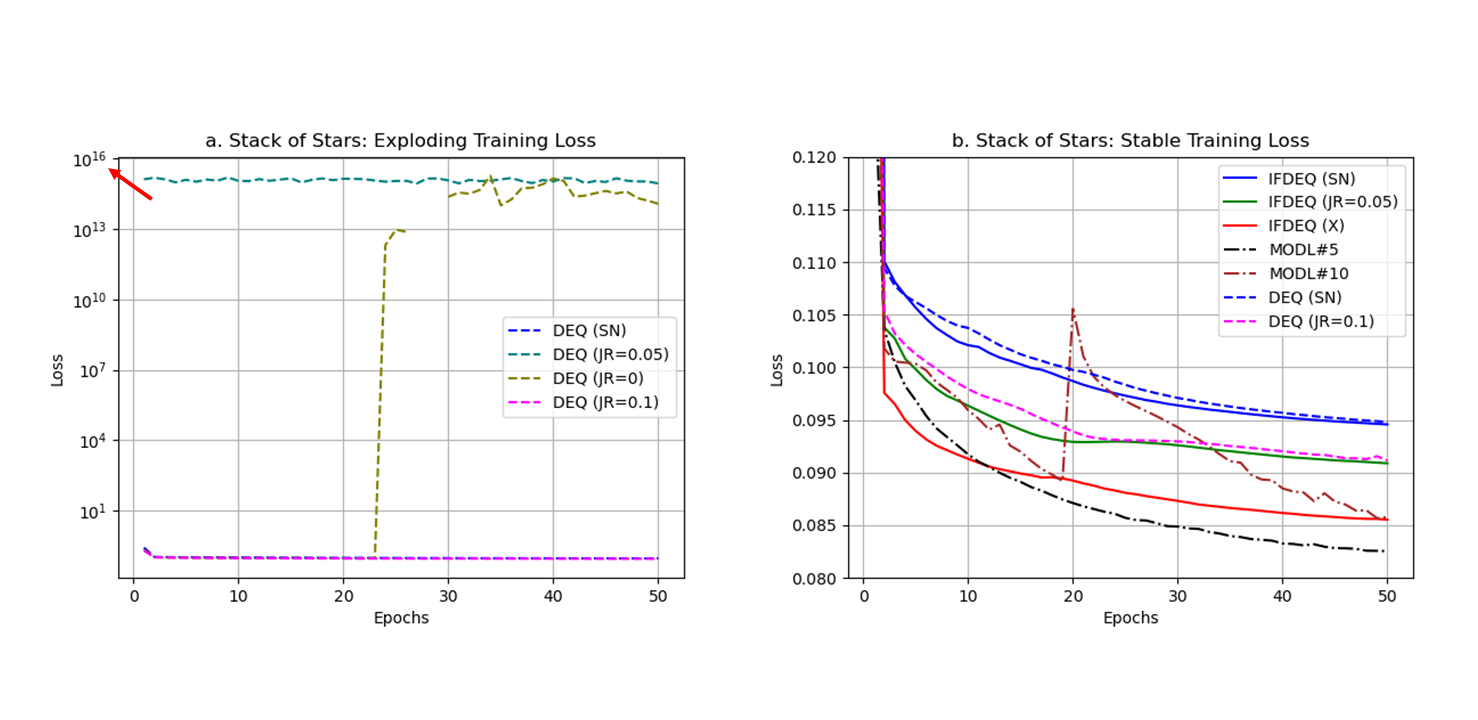
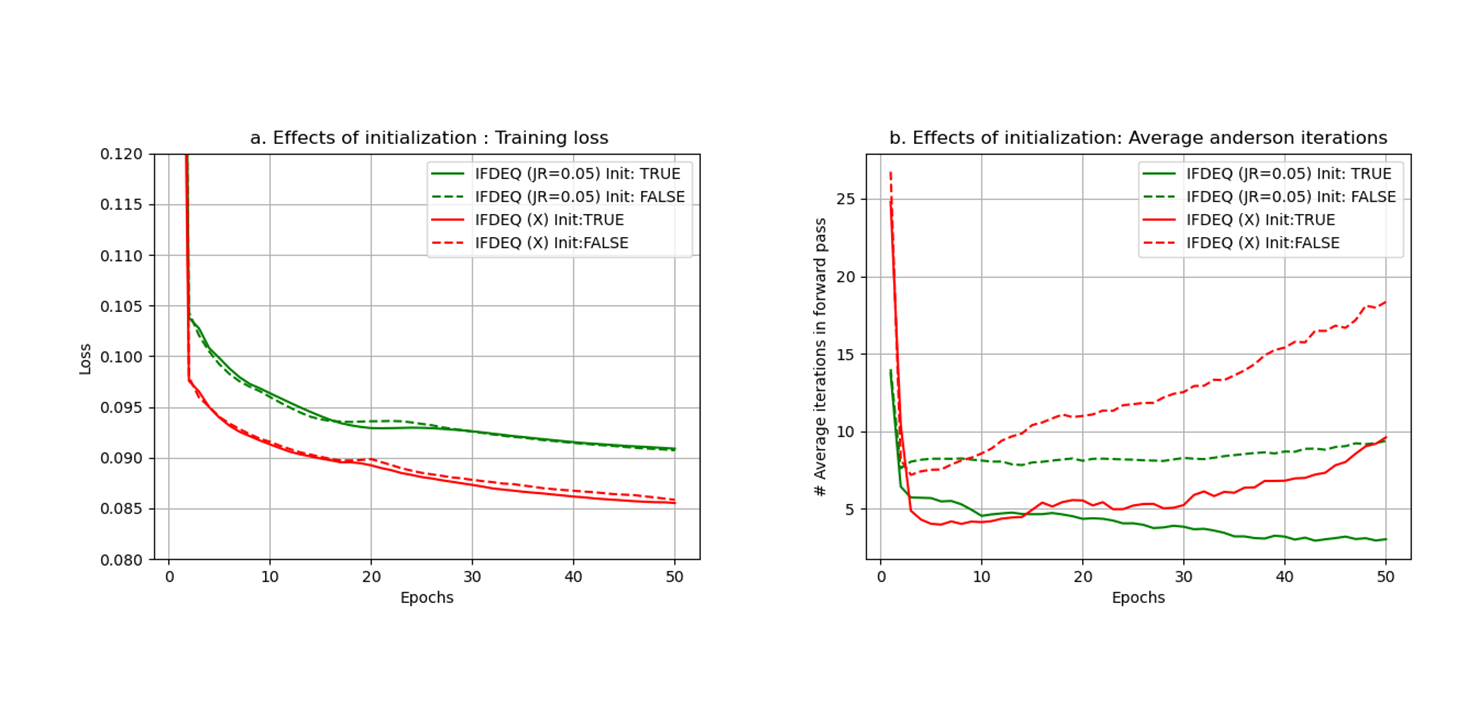
IFDEQ SN demonstrates superior generalization despite its higher training loss compared to other DEQ models (Figure-2,3). Vanilla IFDEQ-(X) exhibits a stable loss curve during training but shows limited performance during testing. IFDEQ architectures exhibit faster computation by bypassing the inversion term, offering improved performance and lower memory requirements compared to traditional DEQ models. While MoDL-5 remains stable, MoDL-10 occasionally diverges but subsequently recovers (Figure-2). Leveraging computed fixed points for initialization in later epochs accelerates training, reducing the required number of Anderson iterates for convergence (Figure-5).Discussion and Conclusions
Some DEQ models exhibit unstable behavior (Figure 2.a); however, both stabilization strategies render DEQ variants (inversion and inversion-free) stable, performing similarly to the baselines. IFDEQ with spectral normalization exhibits the best generalization with lowest memory consumption, using nearly 50% less GPU memory than the baseline MoDL-5, albeit with longer training and inference times. These approaches can not only assist in memory-constrained systems but can also enable improved performance, facilitating the utilization of deeper denoiser architectures.Acknowledgements
This research was supported by the National Institutes of Health’s grant 5R01DK125783, 5R01HL136965. We also acknowledge GE Healthcare for the research and data support.References
1. Bai S, Kolter JZ, Koltun V. Deep Equilibrium Models. In: Advances in Neural Information Processing Systems. Vol 32. Curran Associates, Inc.; 2019.
2. Gilton D, Ongie G, Willett R. Deep Equilibrium Architectures for Inverse Problems in Imaging. IEEE Trans Comput Imaging. 2021;7:1123-1133. doi:10.1109/TCI.2021.3118944
3. Aggarwal HK, Mani MP, Jacob M. MoDL: Model Based Deep Learning Architecture for Inverse Problems. IEEE Trans Med Imaging. 2019;38(2):394-405. doi:10.1109/TMI.2018.2865356
4. Bai S, Koltun V, Kolter Z. Stabilizing Equilibrium Models by Jacobian Regularization. In: Proceedings of the 38th International Conference on Machine Learning. PMLR; 2021:554-565. Accessed November 7, 2023. https://proceedings.mlr.press/v139/bai21b.html
5. Fung SW, Heaton H, Li Q, Mckenzie D, Osher S, Yin W. JFB: Jacobian-Free Backpropagation for Implicit Networks. Proc AAAI Conf Artif Intell. 2022;36(6):6648-6656. doi:10.1609/aaai.v36i6.20619
6. Walker HF, Ni P. Anderson Acceleration for Fixed-Point Iterations. SIAM J Numer Anal. 2011;49(4):1715-1735. doi:10.1137/10078356X
7. Miyato T, Kataoka T, Koyama M, Yoshida Y. Spectral Normalization for Generative Adversarial Networks. ArXiv. Published online February 15, 2018
8. (ISMRM 2019) 3D Stack-of-Stars Radial Imaging for Motion-Robust Free-Breathing Hepatobiliary Phase Imaging. Accessed November 8, 2023. https://archive.ismrm.org/2019/1772.html
9. Ying L, Sheng J. Joint image reconstruction and sensitivity estimation in SENSE (JSENSE). Magn Reson Med. 2007;57(6):1196-1202. doi:10.1002/mrm.21245
10. Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab N, Hornegger J, Wells WM, Frangi AF, eds. Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. Vol 9351. Lecture Notes in Computer Science. Springer International Publishing; 2015:234-241. doi:10.1007/978-3-319-24574-4_28
Figures